%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D
-
 초경량·고강도 동시 갖춘 첨단 신소재 개발
최근 자동차, 항공, 모빌리티 등 첨단 산업에서는 경량화와 동시에 우수한 기계적 성능을 갖춘 소재에 대한 수요가 증가하고 있다. 국제 공동연구진이 나노 구조를 활용한 초경량 고강도 소재를 개발하여 향후 맞춤형 설계를 통해 다양한 산업에 응용 가능성을 제시했다.
우리 대학 기계공학과 유승화 교수 연구팀이 토론토 대학(Univ. of Toronto) 토빈 필레터 교수(Prof. Tobin Filleter) 연구팀과 협력해, 높은 강성과 강도를 유지하면서도 경량성을 극대화한 나노 격자 구조를 개발했다고 18일 밝혔다.
연구팀은 이번 연구에서 격자 구조의 보(beam) 형상을 최적화해 경량성을 유지하면서도 강성과 강도를 극대화하는 방안을 모색했다.
특히, 다목적 베이지안 최적화(Multi-objective Bayesian Optimization) 알고리즘*을 활용해 인장 및 전단 강성 향상과 무게 감소를 동시에 고려하는 최적 설계를 수행했다. 기존 방식보다 훨씬 적은 데이터(약 400개)만으로도 최적의 격자 구조를 예측하고 설계할 수 있음을 입증했다.
*다목적 베이지안 최적화 알고리즘: 여러 목표를 동시에 고려해 최적의 해결책을 찾는 방법으로, 불확실도가 있는 상황에서도 효율적으로 데이터 수집과 결과 예측을 반복하며 최적화를 진행
연구팀은 더 나아가, 나노 스케일에서는 크기가 작아질수록 기계적 특성이 향상되는 효과를 극대화하기 위해 열분해 탄소(pyrolytic carbon) 소재*를 활용해 초경량·고강도·고강성 나노 격자 구조를 구현했다.
*열분해 탄소 소재: 높은 온도에서 유기물을 분해해 얻는 탄소 물질로, 내열성과 강도가 뛰어나 다양한 산업에서 사용 예를 들어, 고온에서도 변형되지 않는 코팅재로 활용되어 반도체 장비나 인공 관절 코팅에 쓰임
이를 위해 이광자 중합(two-photon polymerization, 2PP) 기술*을 적용해 복잡한 나노 격자 구조를 정밀하게 제작했으며, 기계적 성능 평가 결과 해당 구조가 강철에 버금가는 강도와 스티로폼 수준의 경량성을 동시에 갖추고 있음을 확인했다.
*이광자 중합 기술: 레이저 빔을 이용해 특정 파장의 두 개의 광자가 동시에 흡수될 때만 중합 반응이 일어나도록 하는 원리를 기반으로 하는 첨단 광학 제조 기술
또한, 멀티포커스 이광자 중합(multi-focus 2PP) 기술을 이용해 나노스케일의 정밀도를 유지하면서도 밀리미터 스케일의 구조물 제작이 가능함을 연구팀은 입증했다.
유승화 교수는 “이번 기술은 기존 설계 방식의 한계로 지적되던 응력 집중 문제를 3차원 나노 격자 구조를 통해 혁신적으로 해결함으로써, 초경량성과 고강도를 동시에 구현한 신소재 개발에 중요한 진전을 이루었다”라고 말했다.
이어 유 교수는 “데이터 기반 최적화 설계와 정밀 3D 프린팅 기술을 융합한 이 기술은 항공우주 및 자동차 산업의 경량화 수요에 부응할 뿐만 아니라, 맞춤형 설계를 통한 다양한 산업 응용 가능성을 열어갈 것으로 기대된다”라고 강조했다.
이번 연구는 피터 설레스 박사(Dr. Peter Serles)와 KAIST 여진욱 박사가 공동 제1 저자로 연구를 주도했으며, 유승화 교수와 토빈 필레터 교수가 교신 저자로 참여했다.
연구 결과는 세계적인 국제 학술지인 ‘어드밴스드 머터리얼즈(Advanced Materials)’에 2025년 1월 23일 게재됐다.(논문 제목: Ultrahigh Specific Strength by Bayesian Optimization of Lightweight Carbon Nanolattices) DOI: https://doi.org/10.1002/adma.202410651
이번 연구는 과학기술정보통신부에서 지원하는 다상소재 혁신생산공정 연구센터 과제(ERC사업)와 식품의약품안전처의 M3DT(의료기기 디지털 개발도구) 과제, KAIST 국제협력사업의 지원을 받아 수행됐다.
2025.02.18 조회수 1535
초경량·고강도 동시 갖춘 첨단 신소재 개발
최근 자동차, 항공, 모빌리티 등 첨단 산업에서는 경량화와 동시에 우수한 기계적 성능을 갖춘 소재에 대한 수요가 증가하고 있다. 국제 공동연구진이 나노 구조를 활용한 초경량 고강도 소재를 개발하여 향후 맞춤형 설계를 통해 다양한 산업에 응용 가능성을 제시했다.
우리 대학 기계공학과 유승화 교수 연구팀이 토론토 대학(Univ. of Toronto) 토빈 필레터 교수(Prof. Tobin Filleter) 연구팀과 협력해, 높은 강성과 강도를 유지하면서도 경량성을 극대화한 나노 격자 구조를 개발했다고 18일 밝혔다.
연구팀은 이번 연구에서 격자 구조의 보(beam) 형상을 최적화해 경량성을 유지하면서도 강성과 강도를 극대화하는 방안을 모색했다.
특히, 다목적 베이지안 최적화(Multi-objective Bayesian Optimization) 알고리즘*을 활용해 인장 및 전단 강성 향상과 무게 감소를 동시에 고려하는 최적 설계를 수행했다. 기존 방식보다 훨씬 적은 데이터(약 400개)만으로도 최적의 격자 구조를 예측하고 설계할 수 있음을 입증했다.
*다목적 베이지안 최적화 알고리즘: 여러 목표를 동시에 고려해 최적의 해결책을 찾는 방법으로, 불확실도가 있는 상황에서도 효율적으로 데이터 수집과 결과 예측을 반복하며 최적화를 진행
연구팀은 더 나아가, 나노 스케일에서는 크기가 작아질수록 기계적 특성이 향상되는 효과를 극대화하기 위해 열분해 탄소(pyrolytic carbon) 소재*를 활용해 초경량·고강도·고강성 나노 격자 구조를 구현했다.
*열분해 탄소 소재: 높은 온도에서 유기물을 분해해 얻는 탄소 물질로, 내열성과 강도가 뛰어나 다양한 산업에서 사용 예를 들어, 고온에서도 변형되지 않는 코팅재로 활용되어 반도체 장비나 인공 관절 코팅에 쓰임
이를 위해 이광자 중합(two-photon polymerization, 2PP) 기술*을 적용해 복잡한 나노 격자 구조를 정밀하게 제작했으며, 기계적 성능 평가 결과 해당 구조가 강철에 버금가는 강도와 스티로폼 수준의 경량성을 동시에 갖추고 있음을 확인했다.
*이광자 중합 기술: 레이저 빔을 이용해 특정 파장의 두 개의 광자가 동시에 흡수될 때만 중합 반응이 일어나도록 하는 원리를 기반으로 하는 첨단 광학 제조 기술
또한, 멀티포커스 이광자 중합(multi-focus 2PP) 기술을 이용해 나노스케일의 정밀도를 유지하면서도 밀리미터 스케일의 구조물 제작이 가능함을 연구팀은 입증했다.
유승화 교수는 “이번 기술은 기존 설계 방식의 한계로 지적되던 응력 집중 문제를 3차원 나노 격자 구조를 통해 혁신적으로 해결함으로써, 초경량성과 고강도를 동시에 구현한 신소재 개발에 중요한 진전을 이루었다”라고 말했다.
이어 유 교수는 “데이터 기반 최적화 설계와 정밀 3D 프린팅 기술을 융합한 이 기술은 항공우주 및 자동차 산업의 경량화 수요에 부응할 뿐만 아니라, 맞춤형 설계를 통한 다양한 산업 응용 가능성을 열어갈 것으로 기대된다”라고 강조했다.
이번 연구는 피터 설레스 박사(Dr. Peter Serles)와 KAIST 여진욱 박사가 공동 제1 저자로 연구를 주도했으며, 유승화 교수와 토빈 필레터 교수가 교신 저자로 참여했다.
연구 결과는 세계적인 국제 학술지인 ‘어드밴스드 머터리얼즈(Advanced Materials)’에 2025년 1월 23일 게재됐다.(논문 제목: Ultrahigh Specific Strength by Bayesian Optimization of Lightweight Carbon Nanolattices) DOI: https://doi.org/10.1002/adma.202410651
이번 연구는 과학기술정보통신부에서 지원하는 다상소재 혁신생산공정 연구센터 과제(ERC사업)와 식품의약품안전처의 M3DT(의료기기 디지털 개발도구) 과제, KAIST 국제협력사업의 지원을 받아 수행됐다.
2025.02.18 조회수 1535 -
 누구나 천연물 합성 경로 예측 가능하다
식물은 고착생활을 하면서 환경 스트레스에 대응하기 위해 진화적으로 다양하고 복잡한 천연물을 만들고 있다. 이 천연물들은 인류의 생존에도 필수적인 역할을 하고 있는데 미국식품의약국(FDA) 승인 저분자 약물의 30% 이상이 식물 천연물에 기초하고 있다는 사실이 이를 증명하고 있다. 한국 연구진이 딥러닝을 활용, 천연물의 역-생합성 경로를 예측하는 모델을 제시해 천연물 기반 의약품 대량 생산에 활용될 수 있도록 해 화제다.
우리 대학 생명과학과 김상규 교수 연구팀과 김재철AI대학원 황성주 교수 연구팀의 공동연구를 통해 천연물 생합성 경로를 예측하는 딥러닝 모델을 개발하고 부산대학교 박정빈 교수 연구팀과 협업을 통해 관심있는 누구나 모델을 활용할 수 있도록 인터넷 웹사이트(readretro.net)를 구축했다고 14일 밝혔다.
천연물 활용 및 대량 생산을 위해서는 생합성 경로를 밝히는 것이 필수적이다. 하지만 복잡한 구조를 가진 많은 약용 천연물의 생합성 경로가 잘 밝혀져 있지 않아 현재는 식물로부터 직접 추출해 사용하고 있다. 생합성 경로 연구는 도전적이지만 이를 밝히고 생합성 효소를 찾을 수 있다면 천연물의 활용 가치를 증진할 수 있다.
식물 천연물 생합성 경로 연구의 첫 단계는 식물이 어떻게 물질을 합성하는지 그 경로를 역추적(역합성 경로를 제시)하는 것으로 시작된다. 공동연구팀은 딥러닝을 활용해 천연물의 역-생합성 경로를 예측하는 모델을 제시했다. 이번 연구에서 연구팀은 발전된 역합성 모델과 생화학적 직관을 결합해 성공적으로 천연물 생합성 경로 예측을 수행하는 인공지능 모델을 개발했다.
연구팀은 개발한 인공지능의 이름을 ‘역합성을 읽어내는 모델’이라는 뜻을 담아 ‘리드레트로(READRetro)’라고 명명했다. 이 모델은 천연물 역합성을 예측하는 인공지능 모델 중 최고의 성능을 보이는 것으로 확인되었고 이를 개별 연구자들이 쉽게 활용할 수 있도록 구현했다는 데 의미를 가진다.
김상규 교수는 “식물이 어떻게 복잡한 천연물을 만들 수 있게 되었는지 이해하는 기초 연구에서부터 천연물 기반 의약품을 대량으로 생산하기 위한 합성생물학 연구 등에 활용이 기대된다. 추후 합성 경로를 매개하는 효소를 예측하거나 거대 분자의 역합성 예측 정확도를 높이는 연구를 실시할 계획이다” 라고 말했다. 또한 김 교수는 “이번 연구는 2022년 KAIST 인공지능연구원에서 주최한 멜팅 팟(Melting pot) 세미나에서 저와 황성주 교수가 발제자와 토론자로 만난 인연으로 시작됐다. KAIST가 표방하는 융합이 생화학자와 전산학자의 힘을 합쳐 이끌어 낸 좋은 연구로 큰 의미를 갖는다고 생각한다”고 강조했다.
생명과학과 김태인 석박사통합과정과 김재철AI대학원 이슬 석박사통합과정이 공동 제1 저자로 참여한 이번 연구 결과는 국제 학술지 ‘뉴 파이톨로지스트(New Phytologist)'에 출판됐다. (논문명 : READRetro: natural product biosynthesis predicting with retrieval-augmented dual-view retrosynthesis).
한편 이번 연구는 KAIST POST-AI, 한국연구재단, 과학기술정보통신부 등의 지원을 받아 수행됐다.
2024.08.14 조회수 4298
누구나 천연물 합성 경로 예측 가능하다
식물은 고착생활을 하면서 환경 스트레스에 대응하기 위해 진화적으로 다양하고 복잡한 천연물을 만들고 있다. 이 천연물들은 인류의 생존에도 필수적인 역할을 하고 있는데 미국식품의약국(FDA) 승인 저분자 약물의 30% 이상이 식물 천연물에 기초하고 있다는 사실이 이를 증명하고 있다. 한국 연구진이 딥러닝을 활용, 천연물의 역-생합성 경로를 예측하는 모델을 제시해 천연물 기반 의약품 대량 생산에 활용될 수 있도록 해 화제다.
우리 대학 생명과학과 김상규 교수 연구팀과 김재철AI대학원 황성주 교수 연구팀의 공동연구를 통해 천연물 생합성 경로를 예측하는 딥러닝 모델을 개발하고 부산대학교 박정빈 교수 연구팀과 협업을 통해 관심있는 누구나 모델을 활용할 수 있도록 인터넷 웹사이트(readretro.net)를 구축했다고 14일 밝혔다.
천연물 활용 및 대량 생산을 위해서는 생합성 경로를 밝히는 것이 필수적이다. 하지만 복잡한 구조를 가진 많은 약용 천연물의 생합성 경로가 잘 밝혀져 있지 않아 현재는 식물로부터 직접 추출해 사용하고 있다. 생합성 경로 연구는 도전적이지만 이를 밝히고 생합성 효소를 찾을 수 있다면 천연물의 활용 가치를 증진할 수 있다.
식물 천연물 생합성 경로 연구의 첫 단계는 식물이 어떻게 물질을 합성하는지 그 경로를 역추적(역합성 경로를 제시)하는 것으로 시작된다. 공동연구팀은 딥러닝을 활용해 천연물의 역-생합성 경로를 예측하는 모델을 제시했다. 이번 연구에서 연구팀은 발전된 역합성 모델과 생화학적 직관을 결합해 성공적으로 천연물 생합성 경로 예측을 수행하는 인공지능 모델을 개발했다.
연구팀은 개발한 인공지능의 이름을 ‘역합성을 읽어내는 모델’이라는 뜻을 담아 ‘리드레트로(READRetro)’라고 명명했다. 이 모델은 천연물 역합성을 예측하는 인공지능 모델 중 최고의 성능을 보이는 것으로 확인되었고 이를 개별 연구자들이 쉽게 활용할 수 있도록 구현했다는 데 의미를 가진다.
김상규 교수는 “식물이 어떻게 복잡한 천연물을 만들 수 있게 되었는지 이해하는 기초 연구에서부터 천연물 기반 의약품을 대량으로 생산하기 위한 합성생물학 연구 등에 활용이 기대된다. 추후 합성 경로를 매개하는 효소를 예측하거나 거대 분자의 역합성 예측 정확도를 높이는 연구를 실시할 계획이다” 라고 말했다. 또한 김 교수는 “이번 연구는 2022년 KAIST 인공지능연구원에서 주최한 멜팅 팟(Melting pot) 세미나에서 저와 황성주 교수가 발제자와 토론자로 만난 인연으로 시작됐다. KAIST가 표방하는 융합이 생화학자와 전산학자의 힘을 합쳐 이끌어 낸 좋은 연구로 큰 의미를 갖는다고 생각한다”고 강조했다.
생명과학과 김태인 석박사통합과정과 김재철AI대학원 이슬 석박사통합과정이 공동 제1 저자로 참여한 이번 연구 결과는 국제 학술지 ‘뉴 파이톨로지스트(New Phytologist)'에 출판됐다. (논문명 : READRetro: natural product biosynthesis predicting with retrieval-augmented dual-view retrosynthesis).
한편 이번 연구는 KAIST POST-AI, 한국연구재단, 과학기술정보통신부 등의 지원을 받아 수행됐다.
2024.08.14 조회수 4298 -
 변화에 민감한 사용자도 맞춰주는 인공지능 기술 개발
인공지능 심층신경망 모델의 추천시스템에서 시간이 지남에 따라 사용자의 관심이 변하더라도 변화한 관심 또한 효과적으로 학습할 수 있는 인공지능 훈련 기술 개발이 요구되고 있다. 사용자의 관심이 급변하더라도 기존의 지식을 유지하며 새로운 지식을 축적하는 인공지능 연속 학습을 가능하게 하는 기술이 KAIST 연구진에 의해 개발됐다.
우리 대학 전산학부 이재길 교수 연구팀이 다양한 데이터 변화에 적응하며 새로운 지식을 학습함과 동시에 기존의 지식을 망각하지 않는 새로운 연속 학습(continual learning) 기술을 개발했다고 5일 밝혔다.
최근 연속 학습은 훈련 비용을 줄일 수 있도록 프롬프트(prompt) 기반 방식이 대세를 이루고 있다. 각 작업에 특화된 지식을 프롬프트에 저장하고, 적절한 프롬프트를 입력 데이터에 추가해 심층신경망에 전달함으로써 과거 지식을 효과적으로 활용한다.
이재길 교수팀은 기존 접근방식과 다르게 작업 간의 다양한 변화 정도에 적응할 수 있는 적응적 프롬프팅(adaptive prompting)에 기반한 연속 학습 기술을 제안했다. 현재 학습하려는 작업이 기존에 학습하였던 작업과 유사하다면 새로운 프롬프트를 생성하지 않고 그 작업에 할당된 프롬프트에 추가로 지식을 축적한다. 즉, 완전히 새로운 작업이 입력될 때만 이를 담당하기 위한 새로운 프롬프트를 생성하도록 하고 연구팀은 새로운 작업이 들어올 때마다 클러스터링이 적절한지 검사해 최적의 클러스터링 상태를 유지하도록 했다.
연구팀은 이미지 분류 문제에 대해 작업 간의 다양한 변화 정도를 가지는 실세계 데이터를 사용해 방법론을 검증했다. 이 결과 연구팀은 기존의 프롬프트 기반 연속 학습 방법론에 비해, 작업 간의 변화 정도가 항상 큰 환경에서는 최대 14%의 정확도 향상을 달성했고, 작업 간의 변화가 클 수도 있고 작을 수도 있는 환경에서는 최대 8%의 정확도 향상을 달성했다.
또한, 제안한 방법에서 유지하는 클러스터 개수가 실제 유사한 작업의 그룹 개수와 거의 같음을 확인했다. 온라인 클러스터링을 수행하는 비용이 매우 작아 대용량 데이터에도 쉽게 적용할 수 있다.
연구팀을 지도한 이재길 교수도 "연속 학습 분야의 새로운 지평을 열 만한 획기적인 방법이며 실용화 및 기술 이전이 이뤄지면 심층 학습 학계 및 산업계에 큰 파급효과를 낼 수 있을 것이다ˮ고 말했다.
전산학부 김도영 박사과정 학생이 제1 저자, 이영준 박사과정, 방지환 박사과정 학생이 제4, 제6 저자로 각각 참여한 이번 연구는 최고권위 국제학술대회 `국제머신러닝학회(ICML) 2024'에서 지난 7월 발표됐다. (논문명 : One Size Fits All for Semantic Shifts: Adaptive Prompt Tuning for Continual Learning)
한편, 이 기술은 과학기술정보통신부 재원으로 정보통신기획평가원의 지원을 받아 사람중심인공지능핵심원천기술개발사업 AI학습능력개선기술개발 과제로 개발한 연구성과 결과물(2022-0-00157, 강건하고 공정하며 확장 가능한 데이터 중심의 연속 학습)이다.
2024.08.06 조회수 3159
변화에 민감한 사용자도 맞춰주는 인공지능 기술 개발
인공지능 심층신경망 모델의 추천시스템에서 시간이 지남에 따라 사용자의 관심이 변하더라도 변화한 관심 또한 효과적으로 학습할 수 있는 인공지능 훈련 기술 개발이 요구되고 있다. 사용자의 관심이 급변하더라도 기존의 지식을 유지하며 새로운 지식을 축적하는 인공지능 연속 학습을 가능하게 하는 기술이 KAIST 연구진에 의해 개발됐다.
우리 대학 전산학부 이재길 교수 연구팀이 다양한 데이터 변화에 적응하며 새로운 지식을 학습함과 동시에 기존의 지식을 망각하지 않는 새로운 연속 학습(continual learning) 기술을 개발했다고 5일 밝혔다.
최근 연속 학습은 훈련 비용을 줄일 수 있도록 프롬프트(prompt) 기반 방식이 대세를 이루고 있다. 각 작업에 특화된 지식을 프롬프트에 저장하고, 적절한 프롬프트를 입력 데이터에 추가해 심층신경망에 전달함으로써 과거 지식을 효과적으로 활용한다.
이재길 교수팀은 기존 접근방식과 다르게 작업 간의 다양한 변화 정도에 적응할 수 있는 적응적 프롬프팅(adaptive prompting)에 기반한 연속 학습 기술을 제안했다. 현재 학습하려는 작업이 기존에 학습하였던 작업과 유사하다면 새로운 프롬프트를 생성하지 않고 그 작업에 할당된 프롬프트에 추가로 지식을 축적한다. 즉, 완전히 새로운 작업이 입력될 때만 이를 담당하기 위한 새로운 프롬프트를 생성하도록 하고 연구팀은 새로운 작업이 들어올 때마다 클러스터링이 적절한지 검사해 최적의 클러스터링 상태를 유지하도록 했다.
연구팀은 이미지 분류 문제에 대해 작업 간의 다양한 변화 정도를 가지는 실세계 데이터를 사용해 방법론을 검증했다. 이 결과 연구팀은 기존의 프롬프트 기반 연속 학습 방법론에 비해, 작업 간의 변화 정도가 항상 큰 환경에서는 최대 14%의 정확도 향상을 달성했고, 작업 간의 변화가 클 수도 있고 작을 수도 있는 환경에서는 최대 8%의 정확도 향상을 달성했다.
또한, 제안한 방법에서 유지하는 클러스터 개수가 실제 유사한 작업의 그룹 개수와 거의 같음을 확인했다. 온라인 클러스터링을 수행하는 비용이 매우 작아 대용량 데이터에도 쉽게 적용할 수 있다.
연구팀을 지도한 이재길 교수도 "연속 학습 분야의 새로운 지평을 열 만한 획기적인 방법이며 실용화 및 기술 이전이 이뤄지면 심층 학습 학계 및 산업계에 큰 파급효과를 낼 수 있을 것이다ˮ고 말했다.
전산학부 김도영 박사과정 학생이 제1 저자, 이영준 박사과정, 방지환 박사과정 학생이 제4, 제6 저자로 각각 참여한 이번 연구는 최고권위 국제학술대회 `국제머신러닝학회(ICML) 2024'에서 지난 7월 발표됐다. (논문명 : One Size Fits All for Semantic Shifts: Adaptive Prompt Tuning for Continual Learning)
한편, 이 기술은 과학기술정보통신부 재원으로 정보통신기획평가원의 지원을 받아 사람중심인공지능핵심원천기술개발사업 AI학습능력개선기술개발 과제로 개발한 연구성과 결과물(2022-0-00157, 강건하고 공정하며 확장 가능한 데이터 중심의 연속 학습)이다.
2024.08.06 조회수 3159 -
 변화된 데이터에서 인공지능 공정성 찾아내다
인공지능 기술이 사회 전반에 걸쳐 광범위하게 활용되며 인간의 삶에 많은 영향을 미치고 있다. 최근 인공지능의 긍정적인 효과 이면에 범죄자의 재범 예측을 위해 머신러닝 학습에 사용되는 콤파스(COMPAS) 시스템을 기반으로 학습된 모델이 인종 별로 서로 다른 재범 확률을 부여할 수 있다는 심각한 편향성이 관찰되었다. 이 밖에도 채용, 대출 시스템 등 사회의 중요 영역에서 인공지능의 다양한 편향성 문제가 밝혀지며, 공정성(fairness)을 고려한 머신러닝 학습의 필요성이 커지고 있다.
우리 대학 전기및전자공학부 황의종 교수 연구팀이 학습 상황과 달라진 새로운 분포의 테스트 데이터에 대해서도 편향되지 않은 판단을 내리도록 돕는 새로운 모델 훈련 기술을 개발했다고 30일 밝혔다.
최근 전 세계의 연구자들이 인공지능의 공정성을 높이기 위한 다양한 학습 방법론을 제안하고 있지만, 대부분의 연구는 인공지능 모델을 훈련시킬 때 사용되는 데이터와 실제 테스트 상황에서 사용될 데이터가 같은 분포를 갖는다고 가정한다. 하지만 실제 상황에서는 이러한 가정이 대체로 성립하지 않으며, 최근 다양한 어플리케이션에서 학습 데이터와 테스트 데이터 내의 편향 패턴이 크게 변화할 수 있음이 관측되고 있다.
이때, 테스트 환경에서 데이터의 정답 레이블과 특정 그룹 정보 간의 편향 패턴이 변경되면, 사전에 공정하게 학습되었던 인공지능 모델의 공정성이 직접적인 영향을 받고 다시금 악화된 편향성을 가질 수 있다. 일례로 과거에 특정 인종 위주로 채용하던 기관이 이제는 인종에 관계없이 채용한다면, 과거의 데이터를 기반으로 공정하게 학습된 인공지능 채용 모델이 현대의 데이터에는 오히려 불공정한 판단을 내릴 수 있다.
연구팀은 이러한 문제를 해결하기 위해, 먼저 `상관관계 변화(correlation shifts)' 개념을 도입해 기존의 공정성을 위한 학습 알고리즘들이 가지는 정확성과 공정성 성능에 대한 근본적인 한계를 이론적으로 분석했다. 예를 들어 특정 인종만 주로 채용한 과거 데이터의 경우 인종과 채용의 상관관계가 강해서 아무리 공정한 모델을 학습을 시켜도 현재의 약한 상관관계를 반영하는 정확하면서도 공정한 채용 예측을 하기가 근본적으로 어려운 것이다. 이러한 이론적인 분석을 바탕으로, 새로운 학습 데이터 샘플링 기법을 제안해 테스트 시에 데이터의 편향 패턴이 변화해도 모델을 공정하게 학습할 수 있도록 하는 새로운 학습 프레임워크를 제안했다. 이는 과거 데이터에서 우세하였던 특정 인종 데이터를 상대적으로 줄임으로써 채용과의 상관관계를 낮출 수 있다.
제안된 기법의 주요 이점은 데이터 전처리만 하기 때문에 기존에 제안된 알고리즘 기반 공정한 학습 기법을 그대로 활용하면서 개선할 수 있다는 것이다. 즉 이미 사용되고 있는 공정한 학습 알고리즘이 위에서 설명한 상관관계 변화에 취약하다면 제안된 기법을 함께 사용해서 해결할 수 있다.
제1 저자인 전기및전자공학부 노유지 박사과정 학생은 "이번 연구를 통해 인공지능 기술의 실제 적용 환경에서, 모델이 더욱 신뢰 가능하고 공정한 판단을 하도록 도울 것으로 기대한다ˮ고 밝혔다.
연구팀을 지도한 황의종 교수는 "기존 인공지능이 변화하는 데이터에 대해서도 공정성이 저하되지 않도록 하는 데 도움이 되기를 기대한다ˮ고 말했다.
이번 연구에는 노유지 박사과정이 제1 저자, 황의종 교수(KAIST)가 교신 저자, 서창호 교수(KAIST)와 이강욱 교수(위스콘신-매디슨 대학)가 공동 저자로 참여했다. 이번 연구는 지난 7월 미국 하와이에서 열린 머신러닝 최고권위 국제학술 대회인 `국제 머신러닝 학회 International Conference on Machine Learning (ICML)'에서 발표됐다. (논문명 : Improving Fair Training under Correlation Shifts)
한편, 이 기술은 정보통신기획평가원의 지원을 받은 `강건하고 공정하며 확장가능한 데이터 중심의 연속 학습' 과제 (2022-0-00157)와 한국연구재단 지원을 받은 `데이터 중심의 신뢰 가능한 인공지능' 과제의 성과다.
2023.10.30 조회수 6160
변화된 데이터에서 인공지능 공정성 찾아내다
인공지능 기술이 사회 전반에 걸쳐 광범위하게 활용되며 인간의 삶에 많은 영향을 미치고 있다. 최근 인공지능의 긍정적인 효과 이면에 범죄자의 재범 예측을 위해 머신러닝 학습에 사용되는 콤파스(COMPAS) 시스템을 기반으로 학습된 모델이 인종 별로 서로 다른 재범 확률을 부여할 수 있다는 심각한 편향성이 관찰되었다. 이 밖에도 채용, 대출 시스템 등 사회의 중요 영역에서 인공지능의 다양한 편향성 문제가 밝혀지며, 공정성(fairness)을 고려한 머신러닝 학습의 필요성이 커지고 있다.
우리 대학 전기및전자공학부 황의종 교수 연구팀이 학습 상황과 달라진 새로운 분포의 테스트 데이터에 대해서도 편향되지 않은 판단을 내리도록 돕는 새로운 모델 훈련 기술을 개발했다고 30일 밝혔다.
최근 전 세계의 연구자들이 인공지능의 공정성을 높이기 위한 다양한 학습 방법론을 제안하고 있지만, 대부분의 연구는 인공지능 모델을 훈련시킬 때 사용되는 데이터와 실제 테스트 상황에서 사용될 데이터가 같은 분포를 갖는다고 가정한다. 하지만 실제 상황에서는 이러한 가정이 대체로 성립하지 않으며, 최근 다양한 어플리케이션에서 학습 데이터와 테스트 데이터 내의 편향 패턴이 크게 변화할 수 있음이 관측되고 있다.
이때, 테스트 환경에서 데이터의 정답 레이블과 특정 그룹 정보 간의 편향 패턴이 변경되면, 사전에 공정하게 학습되었던 인공지능 모델의 공정성이 직접적인 영향을 받고 다시금 악화된 편향성을 가질 수 있다. 일례로 과거에 특정 인종 위주로 채용하던 기관이 이제는 인종에 관계없이 채용한다면, 과거의 데이터를 기반으로 공정하게 학습된 인공지능 채용 모델이 현대의 데이터에는 오히려 불공정한 판단을 내릴 수 있다.
연구팀은 이러한 문제를 해결하기 위해, 먼저 `상관관계 변화(correlation shifts)' 개념을 도입해 기존의 공정성을 위한 학습 알고리즘들이 가지는 정확성과 공정성 성능에 대한 근본적인 한계를 이론적으로 분석했다. 예를 들어 특정 인종만 주로 채용한 과거 데이터의 경우 인종과 채용의 상관관계가 강해서 아무리 공정한 모델을 학습을 시켜도 현재의 약한 상관관계를 반영하는 정확하면서도 공정한 채용 예측을 하기가 근본적으로 어려운 것이다. 이러한 이론적인 분석을 바탕으로, 새로운 학습 데이터 샘플링 기법을 제안해 테스트 시에 데이터의 편향 패턴이 변화해도 모델을 공정하게 학습할 수 있도록 하는 새로운 학습 프레임워크를 제안했다. 이는 과거 데이터에서 우세하였던 특정 인종 데이터를 상대적으로 줄임으로써 채용과의 상관관계를 낮출 수 있다.
제안된 기법의 주요 이점은 데이터 전처리만 하기 때문에 기존에 제안된 알고리즘 기반 공정한 학습 기법을 그대로 활용하면서 개선할 수 있다는 것이다. 즉 이미 사용되고 있는 공정한 학습 알고리즘이 위에서 설명한 상관관계 변화에 취약하다면 제안된 기법을 함께 사용해서 해결할 수 있다.
제1 저자인 전기및전자공학부 노유지 박사과정 학생은 "이번 연구를 통해 인공지능 기술의 실제 적용 환경에서, 모델이 더욱 신뢰 가능하고 공정한 판단을 하도록 도울 것으로 기대한다ˮ고 밝혔다.
연구팀을 지도한 황의종 교수는 "기존 인공지능이 변화하는 데이터에 대해서도 공정성이 저하되지 않도록 하는 데 도움이 되기를 기대한다ˮ고 말했다.
이번 연구에는 노유지 박사과정이 제1 저자, 황의종 교수(KAIST)가 교신 저자, 서창호 교수(KAIST)와 이강욱 교수(위스콘신-매디슨 대학)가 공동 저자로 참여했다. 이번 연구는 지난 7월 미국 하와이에서 열린 머신러닝 최고권위 국제학술 대회인 `국제 머신러닝 학회 International Conference on Machine Learning (ICML)'에서 발표됐다. (논문명 : Improving Fair Training under Correlation Shifts)
한편, 이 기술은 정보통신기획평가원의 지원을 받은 `강건하고 공정하며 확장가능한 데이터 중심의 연속 학습' 과제 (2022-0-00157)와 한국연구재단 지원을 받은 `데이터 중심의 신뢰 가능한 인공지능' 과제의 성과다.
2023.10.30 조회수 6160 -
 인공지능 심층 학습(딥러닝) 서비스 구축 비용 최소화 가능한 데이터 정제 기술 개발
최근 다양한 분야에서 인공지능 심층 학습(딥러닝) 기술을 활용한 서비스가 급속히 증가하고 있다. 서비스 구축을 위해서 인공지능은 심층신경망을 훈련해야 하며, 이를 위해서는 충분한 훈련 데이터를 준비해야 한다. 특히 훈련 데이터에 정답지를 만드는 레이블링(labeling) 과정이 필요한데 (예를 들어, 고양이 사진에 `고양이'라고 정답을 적어줌), 이 과정은 일반적으로 수작업으로 진행되므로 엄청난 노동력과 시간적 비용이 소요된다. 따라서 훈련 데이터 구축 비용을 최소화하는 방법 개발이 요구되고 있다.
우리 대학 전산학부 이재길 교수 연구팀이 심층 학습 훈련 데이터 구축 비용을 최소화할 수 있는 새로운 데이터 동시 정제 및 선택 기술을 개발했다고 12일 밝혔다.
일반적으로 심층 학습용 훈련 데이터 구축 과정은 수집, 정제, 선택 및 레이블링 단계로 이뤄진다. 수집 단계에서는 웹, 카메라, 센서 등으로부터 대용량의 데이터가 정제되지 않은 채로 수집된다. 따라서 수집된 데이터에는 목표 서비스와 관련이 없어서 주어진 레이블에 해당하지 않는 분포 외(out-of-distribution) 데이터가 포함된다 (예를 들어, 동물 사진을 수집할 때 재규어 `자동차'가 포함됨). 이러한 분포 외 데이터는 데이터 정제 단계에서 정제돼야 한다. 모든 정제된 데이터에 정답지를 만들기 위해서는 막대한 비용이 소모되는데, 이를 최소화하기 위해 심층 학습 성능 향상에 가장 도움이 되는 훈련 데이터를 먼저 선택해 레이블링하는 능동 학습(active learning)이 큰 주목을 받고 있다. 그러나 정제와 레이블링을 별도로 진행하는 것은 데이터 검사 측면에서 중복적인 비용을 초래한다. 또한 아직 정제되지 않고 남아 있는 분포 외 데이터가 레이블링 단계에서 선택된다면 레이블링 노력을 낭비할 수 있다.
이재길 교수팀이 개발한 기술은 훈련 데이터 구축 단계에서 데이터의 정제 및 선택을 동시에 수행해 심층 학습용 훈련 데이터 구축 비용을 최소화할 수 있도록 해준다.
우리 대학 데이터사이언스대학원에 재학 중인 박동민 박사과정 학생이 제1 저자, 신유주 박사과정, 이영준 박사과정 학생이 제2, 제4 저자로 각각 참여한 이번 연구는 최고권위 국제학술대회 `신경정보처리시스템학회(NeurIPS) 2022'에서 올 12월 발표될 예정이다. (논문명 : Meta-Query-Net: Resolving Purity-Informativeness Dilemma in Open-set Active Learning)
데이터의 정제 및 선택을 동시에 고려하기 위해서 구체적으로 가장 분포 외 데이터가 아닐 것 같은 데이터 중에서 가장 심층 학습 성능 향상에 도움이 될 데이터를 선택한다. 즉, 주어진 훈련 데이터 구축 비용 내에서 최고의 효과를 내도록 데이터의 순도(purity) 지표와 정보도(informativeness) 지표의 최적 균형(trade-off)을 찾는다. 순도와 정보도는 일반적으로 서로 상충하므로 최적 균형을 찾는 것이 간단하지 않다. 이 교수팀은 이러한 최적 균형이 정제 전 데이터의 분포 외 데이터 비율과 현재 심층신경망 훈련 정도에 따라 달라진다는 점을 발견했다.
이 교수팀은 이러한 최적 균형을 찾아내기 위해 추가적인 작은 신경망 모델을 도입했다. 연구팀은 추가된 모델을 훈련하기 위해 능동 학습에서 여러 단계에 걸쳐 데이터를 선별하는 과정을 활용했다. 즉, 새롭게 선택돼 레이블링 된 데이터를 순도-정보도 최적 균형을 찾기 위한 훈련 데이터로 활용했고, 레이블이 추가될 때마다 최적 균형을 갱신했다. 이러한 방법은 목표 심층신경망의 성능 향상을 위해 추가적인 상위 레벨의 신경망을 사용하였다는 점에서 메타학습(meta-learning)의 일종이라 볼 수 있다.
연구팀은 이 메타학습 방법론을 `메타 질의 네트워크'라고 이름 붙이고 이미지 분류 문제에 대해 다양한 데이터와 광범위한 분포 외 데이터 비율에 걸쳐 방법론을 검증했다. 그 결과, 기존 최신 방법론과 비교했을 때 최대 20% 향상된 최종 예측 정확도를 향상했고, 모든 범위의 분포 외 데이터 비율에서 일관되게 최고 성능을 보였다. 또한, `메타 질의 네트워크'의 최적 균형 분석을 통해, 분포 외 데이터의 비율이 낮고 현재 심층신경망의 성능이 높을수록 정보도에 높은 가중치를 둬야 함을 연구팀은 밝혀냈다.
제1 저자인 박동민 박사과정 학생은 "이번 기술은 실세계 능동 학습에서의 순도-정보도 딜레마를 발견하고 해결한 획기적인 방법ˮ 이라면서 "다양한 데이터 분포 상황에서의 강건성이 검증됐기 때문에, 실생활의 기계 학습 문제에 폭넓게 적용될 수 있어 전반적인 심층 학습의 훈련 데이터 준비 비용 절감에 기여할 것ˮ 이라고 밝혔다.
연구팀을 지도한 이재길 교수도 "이 기술이 텐서플로우(TensorFlow) 혹은 파이토치(PyTorch)와 같은 기존의 심층 학습 라이브러리에 추가되면 기계 학습 및 심층 학습 학계에 큰 파급효과를 낼 수 있을 것이다ˮ고 말했다.
한편, 이 기술은 과학기술정보통신부 재원으로 정보통신기획평가원의 지원을 받아 SW컴퓨팅산업원천기술개발사업 SW스타랩 과제로 개발한 연구성과 결과물(2020-0-00862, DB4DL: 딥러닝 지원 고사용성 및 고성능 분산 인메모리 DBMS 개발)이다.
2022.10.12 조회수 8166
인공지능 심층 학습(딥러닝) 서비스 구축 비용 최소화 가능한 데이터 정제 기술 개발
최근 다양한 분야에서 인공지능 심층 학습(딥러닝) 기술을 활용한 서비스가 급속히 증가하고 있다. 서비스 구축을 위해서 인공지능은 심층신경망을 훈련해야 하며, 이를 위해서는 충분한 훈련 데이터를 준비해야 한다. 특히 훈련 데이터에 정답지를 만드는 레이블링(labeling) 과정이 필요한데 (예를 들어, 고양이 사진에 `고양이'라고 정답을 적어줌), 이 과정은 일반적으로 수작업으로 진행되므로 엄청난 노동력과 시간적 비용이 소요된다. 따라서 훈련 데이터 구축 비용을 최소화하는 방법 개발이 요구되고 있다.
우리 대학 전산학부 이재길 교수 연구팀이 심층 학습 훈련 데이터 구축 비용을 최소화할 수 있는 새로운 데이터 동시 정제 및 선택 기술을 개발했다고 12일 밝혔다.
일반적으로 심층 학습용 훈련 데이터 구축 과정은 수집, 정제, 선택 및 레이블링 단계로 이뤄진다. 수집 단계에서는 웹, 카메라, 센서 등으로부터 대용량의 데이터가 정제되지 않은 채로 수집된다. 따라서 수집된 데이터에는 목표 서비스와 관련이 없어서 주어진 레이블에 해당하지 않는 분포 외(out-of-distribution) 데이터가 포함된다 (예를 들어, 동물 사진을 수집할 때 재규어 `자동차'가 포함됨). 이러한 분포 외 데이터는 데이터 정제 단계에서 정제돼야 한다. 모든 정제된 데이터에 정답지를 만들기 위해서는 막대한 비용이 소모되는데, 이를 최소화하기 위해 심층 학습 성능 향상에 가장 도움이 되는 훈련 데이터를 먼저 선택해 레이블링하는 능동 학습(active learning)이 큰 주목을 받고 있다. 그러나 정제와 레이블링을 별도로 진행하는 것은 데이터 검사 측면에서 중복적인 비용을 초래한다. 또한 아직 정제되지 않고 남아 있는 분포 외 데이터가 레이블링 단계에서 선택된다면 레이블링 노력을 낭비할 수 있다.
이재길 교수팀이 개발한 기술은 훈련 데이터 구축 단계에서 데이터의 정제 및 선택을 동시에 수행해 심층 학습용 훈련 데이터 구축 비용을 최소화할 수 있도록 해준다.
우리 대학 데이터사이언스대학원에 재학 중인 박동민 박사과정 학생이 제1 저자, 신유주 박사과정, 이영준 박사과정 학생이 제2, 제4 저자로 각각 참여한 이번 연구는 최고권위 국제학술대회 `신경정보처리시스템학회(NeurIPS) 2022'에서 올 12월 발표될 예정이다. (논문명 : Meta-Query-Net: Resolving Purity-Informativeness Dilemma in Open-set Active Learning)
데이터의 정제 및 선택을 동시에 고려하기 위해서 구체적으로 가장 분포 외 데이터가 아닐 것 같은 데이터 중에서 가장 심층 학습 성능 향상에 도움이 될 데이터를 선택한다. 즉, 주어진 훈련 데이터 구축 비용 내에서 최고의 효과를 내도록 데이터의 순도(purity) 지표와 정보도(informativeness) 지표의 최적 균형(trade-off)을 찾는다. 순도와 정보도는 일반적으로 서로 상충하므로 최적 균형을 찾는 것이 간단하지 않다. 이 교수팀은 이러한 최적 균형이 정제 전 데이터의 분포 외 데이터 비율과 현재 심층신경망 훈련 정도에 따라 달라진다는 점을 발견했다.
이 교수팀은 이러한 최적 균형을 찾아내기 위해 추가적인 작은 신경망 모델을 도입했다. 연구팀은 추가된 모델을 훈련하기 위해 능동 학습에서 여러 단계에 걸쳐 데이터를 선별하는 과정을 활용했다. 즉, 새롭게 선택돼 레이블링 된 데이터를 순도-정보도 최적 균형을 찾기 위한 훈련 데이터로 활용했고, 레이블이 추가될 때마다 최적 균형을 갱신했다. 이러한 방법은 목표 심층신경망의 성능 향상을 위해 추가적인 상위 레벨의 신경망을 사용하였다는 점에서 메타학습(meta-learning)의 일종이라 볼 수 있다.
연구팀은 이 메타학습 방법론을 `메타 질의 네트워크'라고 이름 붙이고 이미지 분류 문제에 대해 다양한 데이터와 광범위한 분포 외 데이터 비율에 걸쳐 방법론을 검증했다. 그 결과, 기존 최신 방법론과 비교했을 때 최대 20% 향상된 최종 예측 정확도를 향상했고, 모든 범위의 분포 외 데이터 비율에서 일관되게 최고 성능을 보였다. 또한, `메타 질의 네트워크'의 최적 균형 분석을 통해, 분포 외 데이터의 비율이 낮고 현재 심층신경망의 성능이 높을수록 정보도에 높은 가중치를 둬야 함을 연구팀은 밝혀냈다.
제1 저자인 박동민 박사과정 학생은 "이번 기술은 실세계 능동 학습에서의 순도-정보도 딜레마를 발견하고 해결한 획기적인 방법ˮ 이라면서 "다양한 데이터 분포 상황에서의 강건성이 검증됐기 때문에, 실생활의 기계 학습 문제에 폭넓게 적용될 수 있어 전반적인 심층 학습의 훈련 데이터 준비 비용 절감에 기여할 것ˮ 이라고 밝혔다.
연구팀을 지도한 이재길 교수도 "이 기술이 텐서플로우(TensorFlow) 혹은 파이토치(PyTorch)와 같은 기존의 심층 학습 라이브러리에 추가되면 기계 학습 및 심층 학습 학계에 큰 파급효과를 낼 수 있을 것이다ˮ고 말했다.
한편, 이 기술은 과학기술정보통신부 재원으로 정보통신기획평가원의 지원을 받아 SW컴퓨팅산업원천기술개발사업 SW스타랩 과제로 개발한 연구성과 결과물(2020-0-00862, DB4DL: 딥러닝 지원 고사용성 및 고성능 분산 인메모리 DBMS 개발)이다.
2022.10.12 조회수 8166 -
 최초 머신러닝 기반 유전체 정렬 소프트웨어 개발
우리 대학 전기및전자공학부 한동수 교수 연구팀이 머신러닝(기계학습)에 기반한 *유전체 정렬 소프트웨어를 개발했다고 12일 밝혔다.
☞ 유전체(genome): 생명체가 가지고 있는 염기서열 정보의 총합이며, 유전자는 생물학적 특징을 발현하는 염기서열들을 지칭한다. 유전체를 한 권의 책이라고 비유하면 유전자는 공백을 제외한 모든 글자라고 비유할 수 있다.
차세대 염기서열 분석은 유전체 정보를 해독하는 방법으로 유전체를 무수히 많은 조각으로 잘라낸 후 각 조각을 참조 유전체(reference genome)에 기반해 조립하는 과정을 거친다. 조립된 유전체 정보는 암을 포함한 여러 질병의 예측과 맞춤형 치료, 백신 개발 등 다양한 분야에서 사용된다.
유전체 정렬 소프트웨어는 차세대 염기서열 분석 방법으로 생성한 유전체 조각 데이터를 온전한 유전체 정보로 조립하기 위해 사용되는 소프트웨어다. 유전체 정렬 작업에는 많은 연산이 들어가며, 속도를 높이고 비용을 낮추는 방법에 관한 관심이 계속해서 증가하고 있다. 머신러닝(기계학습) 기반의 인덱싱(색인) 기법(Learned-index)을 유전체 정렬 소프트웨어에 적용한 사례는 이번이 최초다.
전기및전자공학부 정영목 박사과정이 제1 저자로 참여한 이번 연구는 국제 학술지 `옥스포드 바이오인포메틱스(Oxford Bioinformatics)' 2022년 3월에 공개됐다. (논문명 : BWA-MEME: BWA-MEM emulated with a machine learning approach)
유전체 정렬 작업은 정렬해야 하는 유전체 조각의 양이 많고 참조 유전체의 길이도 길어 많은 연산량이 요구되는 작업이다. 또한, 유전체 정렬 소프트웨어에서 정렬 결과의 정확도에 따라 추후의 유전체 분석의 정확도가 영향을 받는다. 이러한 특성 때문에 유전체 정렬 소프트웨어는 높은 정확성을 유지하며 빠르게 연산하는 것이 중요하다.
일반적으로 유전체 분석에는 하버드 브로드 연구소(Broad Institute)에서 개발한 유전체 분석 도구 키트(Genome Analysis Tool Kit, 이하 GATK)를 이용한 데이터 처리 방법을 표준으로 사용한다. 이들 키트 중 BWA-MEM은 GATK에서 표준으로 채택한 유전체 정렬 소프트웨어이며, 2019년에 하버드 대학과 인텔(Intel)의 공동 연구로 BWA-MEM2가 개발됐다.
연구팀이 개발한 머신러닝 기반의 유전체 정렬 소프트웨어는 연산량을 대폭 줄이면서도 표준 유전체 정렬 소프트웨어 BWA-MEM2과 동일한 결과를 만들어 정확도를 유지했다. 사용한 머신러닝 기반의 인덱싱 기법은 주어진 데이터의 분포를 머신러닝 모델이 학습해, 데이터 분포에 최적화된 인덱싱을 찾는 방법론이다. 데이터에 적합하다고 생각되는 인덱싱 방법을 사람이 정하던 기존의 방법과 대비된다.
BWA-MEM과 BWA-MEM2에서 사용하는 인덱싱 기법(FM-index)은 유전자 조각의 위치를 찾기 위해 유전자 조각 길이만큼의 연산이 필요하지만, 연구팀이 제안한 알고리즘은 머신러닝 기반의 인덱싱 기법(Learned-index)을 활용해, 유전자 조각 길이와 상관없이 적은 연산량으로도 유전자 조각의 위치를 찾을 수 있다. 연구팀이 제안한 인덱싱 기법은 기존 인덱싱 기법과 비교해 3.4배 정도 가속화됐고, 이로 인해 유전체 정렬 소프트웨어는 1.4 배 가속화됐다.
연구팀이 이번 연구에서 개발한 유전체 정렬 소프트웨어는 오픈소스 (https://github.com/kaist-ina/BWA-MEME)로 공개돼 많은 분야에 사용될 것으로 기대되며, 유전체 분석에서 사용되는 다양한 소프트웨어를 머신러닝 기술로 가속화하는 연구들의 초석이 될 것으로 기대된다.
한동수 교수는 "이번 연구를 통해 기계학습 기술을 접목해 전장 유전체 빅데이터 분석을 기존 방식보다 빠르고 적은 비용으로 할 수 있다는 것을 보여줬으며, 앞으로 인공지능 기술을 활용해 전장 유전체 빅데이터 분석을 효율화, 고도화할 수 있을 것이라 기대된다ˮ고 말했다.
한편 이번 연구는 과학기술정보통신부의 재원으로 한국연구재단의 지원을 받아 데이터 스테이션 구축·운영 사업으로서 수행됐다.
2022.04.17 조회수 10290
최초 머신러닝 기반 유전체 정렬 소프트웨어 개발
우리 대학 전기및전자공학부 한동수 교수 연구팀이 머신러닝(기계학습)에 기반한 *유전체 정렬 소프트웨어를 개발했다고 12일 밝혔다.
☞ 유전체(genome): 생명체가 가지고 있는 염기서열 정보의 총합이며, 유전자는 생물학적 특징을 발현하는 염기서열들을 지칭한다. 유전체를 한 권의 책이라고 비유하면 유전자는 공백을 제외한 모든 글자라고 비유할 수 있다.
차세대 염기서열 분석은 유전체 정보를 해독하는 방법으로 유전체를 무수히 많은 조각으로 잘라낸 후 각 조각을 참조 유전체(reference genome)에 기반해 조립하는 과정을 거친다. 조립된 유전체 정보는 암을 포함한 여러 질병의 예측과 맞춤형 치료, 백신 개발 등 다양한 분야에서 사용된다.
유전체 정렬 소프트웨어는 차세대 염기서열 분석 방법으로 생성한 유전체 조각 데이터를 온전한 유전체 정보로 조립하기 위해 사용되는 소프트웨어다. 유전체 정렬 작업에는 많은 연산이 들어가며, 속도를 높이고 비용을 낮추는 방법에 관한 관심이 계속해서 증가하고 있다. 머신러닝(기계학습) 기반의 인덱싱(색인) 기법(Learned-index)을 유전체 정렬 소프트웨어에 적용한 사례는 이번이 최초다.
전기및전자공학부 정영목 박사과정이 제1 저자로 참여한 이번 연구는 국제 학술지 `옥스포드 바이오인포메틱스(Oxford Bioinformatics)' 2022년 3월에 공개됐다. (논문명 : BWA-MEME: BWA-MEM emulated with a machine learning approach)
유전체 정렬 작업은 정렬해야 하는 유전체 조각의 양이 많고 참조 유전체의 길이도 길어 많은 연산량이 요구되는 작업이다. 또한, 유전체 정렬 소프트웨어에서 정렬 결과의 정확도에 따라 추후의 유전체 분석의 정확도가 영향을 받는다. 이러한 특성 때문에 유전체 정렬 소프트웨어는 높은 정확성을 유지하며 빠르게 연산하는 것이 중요하다.
일반적으로 유전체 분석에는 하버드 브로드 연구소(Broad Institute)에서 개발한 유전체 분석 도구 키트(Genome Analysis Tool Kit, 이하 GATK)를 이용한 데이터 처리 방법을 표준으로 사용한다. 이들 키트 중 BWA-MEM은 GATK에서 표준으로 채택한 유전체 정렬 소프트웨어이며, 2019년에 하버드 대학과 인텔(Intel)의 공동 연구로 BWA-MEM2가 개발됐다.
연구팀이 개발한 머신러닝 기반의 유전체 정렬 소프트웨어는 연산량을 대폭 줄이면서도 표준 유전체 정렬 소프트웨어 BWA-MEM2과 동일한 결과를 만들어 정확도를 유지했다. 사용한 머신러닝 기반의 인덱싱 기법은 주어진 데이터의 분포를 머신러닝 모델이 학습해, 데이터 분포에 최적화된 인덱싱을 찾는 방법론이다. 데이터에 적합하다고 생각되는 인덱싱 방법을 사람이 정하던 기존의 방법과 대비된다.
BWA-MEM과 BWA-MEM2에서 사용하는 인덱싱 기법(FM-index)은 유전자 조각의 위치를 찾기 위해 유전자 조각 길이만큼의 연산이 필요하지만, 연구팀이 제안한 알고리즘은 머신러닝 기반의 인덱싱 기법(Learned-index)을 활용해, 유전자 조각 길이와 상관없이 적은 연산량으로도 유전자 조각의 위치를 찾을 수 있다. 연구팀이 제안한 인덱싱 기법은 기존 인덱싱 기법과 비교해 3.4배 정도 가속화됐고, 이로 인해 유전체 정렬 소프트웨어는 1.4 배 가속화됐다.
연구팀이 이번 연구에서 개발한 유전체 정렬 소프트웨어는 오픈소스 (https://github.com/kaist-ina/BWA-MEME)로 공개돼 많은 분야에 사용될 것으로 기대되며, 유전체 분석에서 사용되는 다양한 소프트웨어를 머신러닝 기술로 가속화하는 연구들의 초석이 될 것으로 기대된다.
한동수 교수는 "이번 연구를 통해 기계학습 기술을 접목해 전장 유전체 빅데이터 분석을 기존 방식보다 빠르고 적은 비용으로 할 수 있다는 것을 보여줬으며, 앞으로 인공지능 기술을 활용해 전장 유전체 빅데이터 분석을 효율화, 고도화할 수 있을 것이라 기대된다ˮ고 말했다.
한편 이번 연구는 과학기술정보통신부의 재원으로 한국연구재단의 지원을 받아 데이터 스테이션 구축·운영 사업으로서 수행됐다.
2022.04.17 조회수 10290 -
 신소재 영상화 및 머신러닝을 활용한 미래 개척
우리 대학 신소재공학과 홍승범 교수 연구팀이 KAIST 10대 플래그쉽 분야이자, 글로벌 특이점 과제인 `KAIST 신소재 혁명: M3I3 이니셔티브' 과제의 배경, 역사, 진행 상황 그리고 미래 방향을 제시했다고 31일 밝혔다.
홍 교수 연구팀은 다중스케일 다중모드 영상화 기술과 머신러닝(기계학습) 기법을 융합해서 고차원의 구조-물성 및 공정-구조 상관관계를 도출했다. 그리고 이를 인공지능과 3차원 다중 스케일 프린팅 기술을 활용해서 신소재 디자인부터 시장 진입까지의 기간을 획기적으로 단축할 수 있는 비전과 실행 플랫폼을 제안했다. M3I3 플랫폼은 고용량 에너지 소재 디자인에서 시작해서, 고밀도 메모리 소재, 고성능 자동차/항공 소재에도 응용 가능할 것으로 기대된다.
우리 대학 신소재공학과 홍승범 교수가 제1 저자로, 리오치하오 박사가 제2 저자로 참여하고, 육종민 교수, 변혜령 교수, 양용수 교수, 조은애 교수, 최벽파 교수, 이혁모 교수가 공동 저자로 참여한 이번 연구는 국제 학술지 `에이씨에스 나노(ACS Nano)' 2월 12일 字 온라인 출판됐다. (논문명 : Reducing Time to Discovery: Materials and Molecular Modeling, Imaging, Informatics, and Integration)
역사의 큰 흐름을 결정한 신소재는 시행착오와 도제식의 비결 전수를 통해서 발견 및 개발돼왔다. 각종 무기와 그릇, 그리고 장신구들이 좋은 예다. 광학현미경이 발명되면서 검의 미세구조와 검의 강도 혹은 경도 간의 상관관계를 이해하기 시작했고, 투과전자현미경과 원자간력 현미경의 발명으로 원자 수준의 분해능으로 신소재를 영상화하기 시작했다.
고려청자를 현재 재현하지 못하는 것은 고려 시대의 장인들이 그 비결을 남기지 않았기 때문이라고 우리는 가르치고 있다. 그러나, 미래에는 고려청자의 다중 스케일 구조를 영상화해서 데이터화 하고, 구조를 구현할 수 있는 공정 과정을 머신러닝의 힘을 빌려 역설계한다면, 고려청자를 재현하는 일은 가능할 것으로 보인다.
우리 대학 M3I3 플랫폼은 이처럼 다중 스케일 및 다중 모드 영상화 기술, 데이터 마이닝과 머신러닝, 그리고 다중 스케일 제조 기술을 접목해 미래에 필요한 신소재를 역설계해서 빠르게 공정 레시피를 확보할 수 있게 만들어준다.
이번 논문에서는 M3I3 플랫폼의 유효성을 확인하기 위해 배터리 소재에 적용하는 연구를 진행했다. 고용량 배터리 소재의 개발 기간을 단축할 수 있다는 것을 검증하기 위해서 20년간의 논문 자료를 50여 명의 학생이 읽고 데이터를 추출해 양극재의 에너지 밀도와 소재 조성 간의 상관관계를 도출했다. 그리고 논문에 나와 있는 공정, 측정 및 구조 변수들을 머신러닝 기법을 활용해 모델을 수립한 후, 무작위 조건에서 합성해 모델의 정확도를 측정함으로써 데이터 마이닝과 머신러닝의 우수성을 입증했다.
또한 투과전자현미경(TEM), 주사투과전자현미경(STEM), 원자간력현미경(AFM), 광학현미경 등의 다양한 현미경과 엑스레이(X-ray), 라만(Raman), UV/Visible/IR 등 다양한 분광 장비들을 통해 얻은 영상과 스펙트럼 데이터를 기반으로 다중 스케일 구조↔물성 상관관계를 도출하고, 여러 가지 공정변수 데이터를 수집해, 공정↔구조 상관관계를 수립하는 것이 M3I3 플랫폼의 중요한 핵심이다. 특히, 실험데이터와 시뮬레이션 데이터를 융합하고, 머신러닝으로 생성한 가상의 데이터를 과학적인 기준에 맞춰 유의미한 빅데이터로 만들면, 머신러닝을 활용해 물성→구조→공정으로 연결되는 역설계 알고리즘을 개발하는 것이 가능해지며, 이를 통해 미래에 필요한 물성을 갖는 신소재 공정 레시피를 신속하게 확보할 수 있게 된다.
제1 저자인 홍승범 교수는 "과학은 날카로운 관찰과 정량적 측정에서 시작한 학문이며, 기술의 발전으로 현재는 눈에 보이는 소재의 모양과 구조뿐만 아니라 눈에 보이지 않는 소재의 구조를 볼 수 있는 시대가 왔고, 물성마저 공간과 시간의 함수로 영상화할 수 있는 시대가 도래했다ˮ라며 "신소재 영상화 기술과 머신러닝 기술을 융합하고 3D 프린팅 기술을 다중 스케일 자동 합성 기술로 승화시키게 되면 20년 걸리던 신소재 개발 기간을 5년 이내로 단축할 수 있을 것이다ˮ 라고 말했다.
한편, 이번 연구는 글로벌 특이점 사업의 지원을 받아 수행됐다.
2021.04.01 조회수 91199
신소재 영상화 및 머신러닝을 활용한 미래 개척
우리 대학 신소재공학과 홍승범 교수 연구팀이 KAIST 10대 플래그쉽 분야이자, 글로벌 특이점 과제인 `KAIST 신소재 혁명: M3I3 이니셔티브' 과제의 배경, 역사, 진행 상황 그리고 미래 방향을 제시했다고 31일 밝혔다.
홍 교수 연구팀은 다중스케일 다중모드 영상화 기술과 머신러닝(기계학습) 기법을 융합해서 고차원의 구조-물성 및 공정-구조 상관관계를 도출했다. 그리고 이를 인공지능과 3차원 다중 스케일 프린팅 기술을 활용해서 신소재 디자인부터 시장 진입까지의 기간을 획기적으로 단축할 수 있는 비전과 실행 플랫폼을 제안했다. M3I3 플랫폼은 고용량 에너지 소재 디자인에서 시작해서, 고밀도 메모리 소재, 고성능 자동차/항공 소재에도 응용 가능할 것으로 기대된다.
우리 대학 신소재공학과 홍승범 교수가 제1 저자로, 리오치하오 박사가 제2 저자로 참여하고, 육종민 교수, 변혜령 교수, 양용수 교수, 조은애 교수, 최벽파 교수, 이혁모 교수가 공동 저자로 참여한 이번 연구는 국제 학술지 `에이씨에스 나노(ACS Nano)' 2월 12일 字 온라인 출판됐다. (논문명 : Reducing Time to Discovery: Materials and Molecular Modeling, Imaging, Informatics, and Integration)
역사의 큰 흐름을 결정한 신소재는 시행착오와 도제식의 비결 전수를 통해서 발견 및 개발돼왔다. 각종 무기와 그릇, 그리고 장신구들이 좋은 예다. 광학현미경이 발명되면서 검의 미세구조와 검의 강도 혹은 경도 간의 상관관계를 이해하기 시작했고, 투과전자현미경과 원자간력 현미경의 발명으로 원자 수준의 분해능으로 신소재를 영상화하기 시작했다.
고려청자를 현재 재현하지 못하는 것은 고려 시대의 장인들이 그 비결을 남기지 않았기 때문이라고 우리는 가르치고 있다. 그러나, 미래에는 고려청자의 다중 스케일 구조를 영상화해서 데이터화 하고, 구조를 구현할 수 있는 공정 과정을 머신러닝의 힘을 빌려 역설계한다면, 고려청자를 재현하는 일은 가능할 것으로 보인다.
우리 대학 M3I3 플랫폼은 이처럼 다중 스케일 및 다중 모드 영상화 기술, 데이터 마이닝과 머신러닝, 그리고 다중 스케일 제조 기술을 접목해 미래에 필요한 신소재를 역설계해서 빠르게 공정 레시피를 확보할 수 있게 만들어준다.
이번 논문에서는 M3I3 플랫폼의 유효성을 확인하기 위해 배터리 소재에 적용하는 연구를 진행했다. 고용량 배터리 소재의 개발 기간을 단축할 수 있다는 것을 검증하기 위해서 20년간의 논문 자료를 50여 명의 학생이 읽고 데이터를 추출해 양극재의 에너지 밀도와 소재 조성 간의 상관관계를 도출했다. 그리고 논문에 나와 있는 공정, 측정 및 구조 변수들을 머신러닝 기법을 활용해 모델을 수립한 후, 무작위 조건에서 합성해 모델의 정확도를 측정함으로써 데이터 마이닝과 머신러닝의 우수성을 입증했다.
또한 투과전자현미경(TEM), 주사투과전자현미경(STEM), 원자간력현미경(AFM), 광학현미경 등의 다양한 현미경과 엑스레이(X-ray), 라만(Raman), UV/Visible/IR 등 다양한 분광 장비들을 통해 얻은 영상과 스펙트럼 데이터를 기반으로 다중 스케일 구조↔물성 상관관계를 도출하고, 여러 가지 공정변수 데이터를 수집해, 공정↔구조 상관관계를 수립하는 것이 M3I3 플랫폼의 중요한 핵심이다. 특히, 실험데이터와 시뮬레이션 데이터를 융합하고, 머신러닝으로 생성한 가상의 데이터를 과학적인 기준에 맞춰 유의미한 빅데이터로 만들면, 머신러닝을 활용해 물성→구조→공정으로 연결되는 역설계 알고리즘을 개발하는 것이 가능해지며, 이를 통해 미래에 필요한 물성을 갖는 신소재 공정 레시피를 신속하게 확보할 수 있게 된다.
제1 저자인 홍승범 교수는 "과학은 날카로운 관찰과 정량적 측정에서 시작한 학문이며, 기술의 발전으로 현재는 눈에 보이는 소재의 모양과 구조뿐만 아니라 눈에 보이지 않는 소재의 구조를 볼 수 있는 시대가 왔고, 물성마저 공간과 시간의 함수로 영상화할 수 있는 시대가 도래했다ˮ라며 "신소재 영상화 기술과 머신러닝 기술을 융합하고 3D 프린팅 기술을 다중 스케일 자동 합성 기술로 승화시키게 되면 20년 걸리던 신소재 개발 기간을 5년 이내로 단축할 수 있을 것이다ˮ 라고 말했다.
한편, 이번 연구는 글로벌 특이점 사업의 지원을 받아 수행됐다.
2021.04.01 조회수 91199 -
 반도체 다층 소자의 개별 층 두께를 옹스트롬 정확도로 비파괴 검사하는 기술 개발
우리 대학 기계공학과 김정원 교수 연구팀이 삼차원 낸드플래시 메모리(이하 3D-NAND)의 비파괴적인 검사를 위해 광학 측정법과 머신러닝을 사용한 다층 두께 측정기술을 개발했다. 이 기술은 200층 이상의 초고밀도 3D-NAND 소자 공정 과정에서 전수검사 방법으로 사용돼 공정의 효율을 극대화할 수 있을 것으로 기대된다.
3D-NAND 메모리는 수백층의 메모리 셀이 적층되어 있는 메모리 반도체로, 기존의 평면형 플래시 메모리와 비교하여 저장용량과 에너지 효율이 매우 우수하여 개인용 USB부터 서버 시스템까지 다양하게 사용되고 있다.
기존에는 수직으로 적층된 반도체 셀들의 두께를 측정하기 위하여 전자현미경을 사용하였다. 하지만 전자현미경을 사용한 방법은 샘플의 단면을 이미징하기 위하여 샘플을 절단해야 하고 비용도 많이 들기 때문에, 전수검사로서는 적합하지 않은 문제가 있었다.
연구팀은 반도체 다층 구조가 초고속 광학 시스템에 자주 사용되는 유전체 거울의 구조와 유사하다는 점에 착안하여, 유전체 거울의 분석에 활용되는 광학 스펙트럼 측정법을 반도체 다층 구조에도 적용했다.
연구팀은 엘립소미터(ellipsometer)와 스펙트로포토미터(spectrophotometer)를 이용한 반도체 다층 샘플의 스펙트럼 측정과 머신러닝 알고리즘을 활용하여 200층이 넘는 반도체 물질의 각 층 두께를 1.6 옹스트롬 (1Å = 1미터의 100억 분의 1)의 평균제곱근오차로 예측할 수 있는 방법을 개발했다. 이 기술은 삼차원 반도체 소자의 검수 공정, 적층 공정, 그리고 식각 공정의 정확도를 크게 향상시킬 수 있을 것으로 기대된다.
연구팀은 또한 시뮬레이션 스펙트럼 데이터를 생성해 개별 층의 두께 불량을 검출할 수 있는 머신러닝 학습법도 개발했다. 그 결과 반도체 물질 적층 시 목표로 설정한 두께보다 약 50Å만큼 얇게 제작된 샘플들을 정상 범주의 샘플들로부터 성공적으로 분리할 수 있었다. 연구팀이 개발한 불량샘플 검출법은 시뮬레이션 데이터를 활용하기 때문에 큰 비용이 들지 않으며, 공정의 초기에 발견될 수 있는 불량 샘플들을 효과적으로 검출할 수 있을 것으로 기대된다.
최근 글로벌 IT 기업들의 서버 시스템에 대한 수요가 늘어나고 높은 저장용량을 가진 스마트 기기들이 개발됨에 따라, 초고밀도, 초고효율을 갖는 3D-NAND 메모리가 반도체 시장에서 각광받고 있다. 이번 연구 결과는 다양한 삼차원 반도체 소자들의 비파괴적인 검수를 위해 활용될 수 있다.
김 교수는 “비파괴적인 광학 측정법과 머신러닝을 결합한 방법은 다양한 반도체 검수 공정에도 적용할 수 있다”고 밝히며, “다양한 반도체 소자들의 형상이나 공정 조건 모니터링에도 광학측정법과 머신러닝을 결합한 접근방식을 활용할 것”이라고 말했다.
기계공학과 곽현수 박사과정 학생이 제1저자로 참여하고 삼성전자 메모리 계측기술팀과의 산학협력연구로 수행된 이번 연구는 국제학술지 ‘라이트: 어드밴스드 매뉴팩처링(Light: Advanced Manufacturing)’ 창간호에 1월 12일 게재됐다. (논문명: Non-destructive thickness characterisation of 3D multilayer semiconductor devices using optical spectral measurements and machine learning)
이번 연구는 삼성전자 산학연구과제의 지원을 받아 수행됐다.
2021.01.13 조회수 65859
반도체 다층 소자의 개별 층 두께를 옹스트롬 정확도로 비파괴 검사하는 기술 개발
우리 대학 기계공학과 김정원 교수 연구팀이 삼차원 낸드플래시 메모리(이하 3D-NAND)의 비파괴적인 검사를 위해 광학 측정법과 머신러닝을 사용한 다층 두께 측정기술을 개발했다. 이 기술은 200층 이상의 초고밀도 3D-NAND 소자 공정 과정에서 전수검사 방법으로 사용돼 공정의 효율을 극대화할 수 있을 것으로 기대된다.
3D-NAND 메모리는 수백층의 메모리 셀이 적층되어 있는 메모리 반도체로, 기존의 평면형 플래시 메모리와 비교하여 저장용량과 에너지 효율이 매우 우수하여 개인용 USB부터 서버 시스템까지 다양하게 사용되고 있다.
기존에는 수직으로 적층된 반도체 셀들의 두께를 측정하기 위하여 전자현미경을 사용하였다. 하지만 전자현미경을 사용한 방법은 샘플의 단면을 이미징하기 위하여 샘플을 절단해야 하고 비용도 많이 들기 때문에, 전수검사로서는 적합하지 않은 문제가 있었다.
연구팀은 반도체 다층 구조가 초고속 광학 시스템에 자주 사용되는 유전체 거울의 구조와 유사하다는 점에 착안하여, 유전체 거울의 분석에 활용되는 광학 스펙트럼 측정법을 반도체 다층 구조에도 적용했다.
연구팀은 엘립소미터(ellipsometer)와 스펙트로포토미터(spectrophotometer)를 이용한 반도체 다층 샘플의 스펙트럼 측정과 머신러닝 알고리즘을 활용하여 200층이 넘는 반도체 물질의 각 층 두께를 1.6 옹스트롬 (1Å = 1미터의 100억 분의 1)의 평균제곱근오차로 예측할 수 있는 방법을 개발했다. 이 기술은 삼차원 반도체 소자의 검수 공정, 적층 공정, 그리고 식각 공정의 정확도를 크게 향상시킬 수 있을 것으로 기대된다.
연구팀은 또한 시뮬레이션 스펙트럼 데이터를 생성해 개별 층의 두께 불량을 검출할 수 있는 머신러닝 학습법도 개발했다. 그 결과 반도체 물질 적층 시 목표로 설정한 두께보다 약 50Å만큼 얇게 제작된 샘플들을 정상 범주의 샘플들로부터 성공적으로 분리할 수 있었다. 연구팀이 개발한 불량샘플 검출법은 시뮬레이션 데이터를 활용하기 때문에 큰 비용이 들지 않으며, 공정의 초기에 발견될 수 있는 불량 샘플들을 효과적으로 검출할 수 있을 것으로 기대된다.
최근 글로벌 IT 기업들의 서버 시스템에 대한 수요가 늘어나고 높은 저장용량을 가진 스마트 기기들이 개발됨에 따라, 초고밀도, 초고효율을 갖는 3D-NAND 메모리가 반도체 시장에서 각광받고 있다. 이번 연구 결과는 다양한 삼차원 반도체 소자들의 비파괴적인 검수를 위해 활용될 수 있다.
김 교수는 “비파괴적인 광학 측정법과 머신러닝을 결합한 방법은 다양한 반도체 검수 공정에도 적용할 수 있다”고 밝히며, “다양한 반도체 소자들의 형상이나 공정 조건 모니터링에도 광학측정법과 머신러닝을 결합한 접근방식을 활용할 것”이라고 말했다.
기계공학과 곽현수 박사과정 학생이 제1저자로 참여하고 삼성전자 메모리 계측기술팀과의 산학협력연구로 수행된 이번 연구는 국제학술지 ‘라이트: 어드밴스드 매뉴팩처링(Light: Advanced Manufacturing)’ 창간호에 1월 12일 게재됐다. (논문명: Non-destructive thickness characterisation of 3D multilayer semiconductor devices using optical spectral measurements and machine learning)
이번 연구는 삼성전자 산학연구과제의 지원을 받아 수행됐다.
2021.01.13 조회수 65859 -
 학습되지 않은 환경에서 스스로 학습하는 모바일 센싱 기술 개발
우리 대학 전산학부 이성주 교수 연구팀이 학습되지 않은 환경에 적은 양의 데이터로 스스로 적응하는 모바일 센싱 학습 기술 <메타센스(MetaSense)>를 개발했다.
모바일 센싱이란 스마트폰과 같은 모바일 기기의 다양한 센서를 이용하여 서비스(예: 수면의 질 평가, 걸음 수 추적 등)를 제공하는 기술이다. 최근 학계에서는 기계학습 기술의 발전과 더불어 우울증 진단, 운동 자세 관리 등 진보된 모바일 센싱의 가능성을 보여줌으로써 모바일 센싱의 범위를 더욱 확장하고 있다.
하지만 이러한 센싱 기술은 아직 널리 쓰이지 못하고 있다. 사용자 개인마다 가지고 있는 모바일 센싱의 환경이 다르기 때문이다. 사람마다 가지고 있는 고유한 생활패턴과 행동방식, 서로 다른 모바일 기기와 그 사양은 센서의 값에 큰 영향을 미친다. 다른 센서 값은 사람마다 고유한 센싱 환경을 만들고, 이는 센싱 모델이 미리 학습되지 않은 새로운 환경에서 작동할 때 사용이 어려울 만큼 성능 저하를 일으킨다.
연구팀은 이런 학습되지 않는 환경에서 적은 양의 데이터 (최소 1-2 샘플)만 가지고 적응할 수 있는 '메타러닝 프레임워크'를 제시했다. 메타러닝 (meta learning) 이란 적은 양의 데이터를 가지고도 새로운 지식을 학습할 수 있도록 하는 기계학습 원리다. 연구팀이 제시한 기술은 최신 전이학습 (transfer learning) 기술과 비교하여 18%, 메타러닝 기술과 비교하여 15%의 정확도 성능향상을 보였다.
이성주 교수는 ”최근 활발히 제안되고 있는 다양한 모바일 센싱 서비스가 특정 환경에 의존하지 않고 수많은 실제 사용 환경에서 우수한 성능을 보일 수 있게 해주는 연구다. 모바일 센싱 서비스가 연구에 그치지 않고 실제 많은 사람들에게 사용될 수 있는 가능성을 제시해 의미가 있다“라고 했다. 또한 신진우 교수는 “최근 메타러닝 방법론들이 기계학습 분야에서 크게 각광을 받고 있는데 주로 영상 데이터에 국한되어 왔었다. 본 연구에서 비영상 데이터에도 범용적으로 동작하는 메터러닝 기술을 개발하여 성공한 것은 앞으로도 관련 분야 연구에 큰 영향을 주리라 기대한다“라고 덧붙였다.
연구에 대한 설명이 담긴 비디오를 다음 링크에서 확인할 수 있고, (https://youtu.be/-6y0I1pd6XI) 자세한 정보는 프로젝트 웹사이트에서 볼 수 있다.
(https://nmsl.kaist.ac.kr/projects/metasense/)
이성주 교수, 신진우 AI대학원 교수, 공태식 박사과정, 김연수 학사과정이 참여한 이번 연구 결과는 2019년 11월 11일 센싱 컴퓨팅 분야 국제 최우수학회 ACM SenSys에서 발표됐다. (논문명: MetaSense: Few-Shot Adaptation to Untrained Conditions in Deep Mobile Sensing). 이 연구는 정부(과학기술정보통신부)의 재원으로 한국연구재단과 정보통신기술진흥센터, 한국연구재단 차세대 정보 컴퓨팅 기술개발사업의 지원을 받아 수행됐다.
2020.06.09 조회수 17007
학습되지 않은 환경에서 스스로 학습하는 모바일 센싱 기술 개발
우리 대학 전산학부 이성주 교수 연구팀이 학습되지 않은 환경에 적은 양의 데이터로 스스로 적응하는 모바일 센싱 학습 기술 <메타센스(MetaSense)>를 개발했다.
모바일 센싱이란 스마트폰과 같은 모바일 기기의 다양한 센서를 이용하여 서비스(예: 수면의 질 평가, 걸음 수 추적 등)를 제공하는 기술이다. 최근 학계에서는 기계학습 기술의 발전과 더불어 우울증 진단, 운동 자세 관리 등 진보된 모바일 센싱의 가능성을 보여줌으로써 모바일 센싱의 범위를 더욱 확장하고 있다.
하지만 이러한 센싱 기술은 아직 널리 쓰이지 못하고 있다. 사용자 개인마다 가지고 있는 모바일 센싱의 환경이 다르기 때문이다. 사람마다 가지고 있는 고유한 생활패턴과 행동방식, 서로 다른 모바일 기기와 그 사양은 센서의 값에 큰 영향을 미친다. 다른 센서 값은 사람마다 고유한 센싱 환경을 만들고, 이는 센싱 모델이 미리 학습되지 않은 새로운 환경에서 작동할 때 사용이 어려울 만큼 성능 저하를 일으킨다.
연구팀은 이런 학습되지 않는 환경에서 적은 양의 데이터 (최소 1-2 샘플)만 가지고 적응할 수 있는 '메타러닝 프레임워크'를 제시했다. 메타러닝 (meta learning) 이란 적은 양의 데이터를 가지고도 새로운 지식을 학습할 수 있도록 하는 기계학습 원리다. 연구팀이 제시한 기술은 최신 전이학습 (transfer learning) 기술과 비교하여 18%, 메타러닝 기술과 비교하여 15%의 정확도 성능향상을 보였다.
이성주 교수는 ”최근 활발히 제안되고 있는 다양한 모바일 센싱 서비스가 특정 환경에 의존하지 않고 수많은 실제 사용 환경에서 우수한 성능을 보일 수 있게 해주는 연구다. 모바일 센싱 서비스가 연구에 그치지 않고 실제 많은 사람들에게 사용될 수 있는 가능성을 제시해 의미가 있다“라고 했다. 또한 신진우 교수는 “최근 메타러닝 방법론들이 기계학습 분야에서 크게 각광을 받고 있는데 주로 영상 데이터에 국한되어 왔었다. 본 연구에서 비영상 데이터에도 범용적으로 동작하는 메터러닝 기술을 개발하여 성공한 것은 앞으로도 관련 분야 연구에 큰 영향을 주리라 기대한다“라고 덧붙였다.
연구에 대한 설명이 담긴 비디오를 다음 링크에서 확인할 수 있고, (https://youtu.be/-6y0I1pd6XI) 자세한 정보는 프로젝트 웹사이트에서 볼 수 있다.
(https://nmsl.kaist.ac.kr/projects/metasense/)
이성주 교수, 신진우 AI대학원 교수, 공태식 박사과정, 김연수 학사과정이 참여한 이번 연구 결과는 2019년 11월 11일 센싱 컴퓨팅 분야 국제 최우수학회 ACM SenSys에서 발표됐다. (논문명: MetaSense: Few-Shot Adaptation to Untrained Conditions in Deep Mobile Sensing). 이 연구는 정부(과학기술정보통신부)의 재원으로 한국연구재단과 정보통신기술진흥센터, 한국연구재단 차세대 정보 컴퓨팅 기술개발사업의 지원을 받아 수행됐다.
2020.06.09 조회수 17007 -
 박현욱 교수, 머신러닝 통해 MRI 영상촬영시간 단축기술 개발
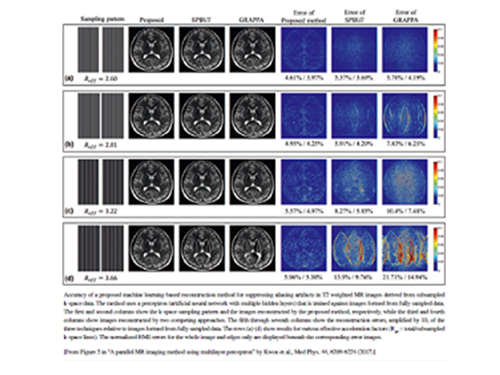
우리 대학 전기및전자공학부 박현욱 교수 연구팀이 머신러닝 기반의 영상복원법을 이용해 자기공명영상장치(이하 MRI)의 영상 획득시간을 6배 이상 단축시킬 수 있는 기술을 개발했다.
이번 연구를 통해 MRI의 영상획득시간을 대폭 줄임으로써 환자의 편의성을 높일 뿐 아니라 의료비용 절감 효과를 기대할 수 있을 것으로 보인다.
권기남 박사과정이 1저자로 참여한 이번 연구는 국제 학술지 ‘메디컬 피직스(Medical Physics)’ 12월 13일자에 게재됐고 그 우수성을 인정받아 표지 논문에 선정됐다.
MRI는 방사능 없이 연조직의 다양한 대조도를 촬영할 수 있는 영상기기이다. 다양한 해부학적 구조 뿐 아니라 기능적, 생리학적 정보 또한 영상화 할 수 있기 때문에 의료 진단을 위해 매우 높은 빈도로 사용되고 있다.
하지만 MRI는 다른 의료영상기기에 비해 영상획득시간이 오래 걸린다는 단점이 있다. 따라서 환자들은 MRI를 찍기 위해 긴 시간을 대기해야 하고 촬영 과정에서도 자세를 움직이지 않아야 하는 등의 불편함을 감수해야 한다.
특히 길게 소요되는 영상획득시간은 MRI의 비싼 촬영 비용과 직접적인 연관이 있다.
박 교수 연구팀은 MRI의 영상획득시간을 줄이기 위해 데이터를 적게 수집하고 대신 부족한 데이터를 기계학습(Machine Learning)을 이용해 복원하는 방법을 개발했다.
기존의 MRI는 주파수 영역에서 여러 위상 인코딩을 하면서 순차적으로 한 줄씩 얻기 때문에 영상획득시간이 오래 걸린다. 획득 시간을 단축시키기 위해 저주파 영역에서만 데이터를 얻으면 저해상도 영상을 얻게 되고 듬성듬성 데이터를 얻으면 영상에서 인공물이 생기는 에일리어싱 아티팩트 현상이 발생한다.
이러한 에일리어싱 아티팩트를 해결하기 위해 다른 민감도를 갖는 여러 수신 코일을 활용한 병렬 영상법과 신호의 희소성을 이용한 압축 센싱 기법이 주로 활용됐다.
그러나 병렬 영상법은 수신 코일들의 설계에 영향을 받기 때문에 시간을 많이 단축할 수 없고 영상 복원에도 시간이 많이 걸린다.
연구팀은 MRI의 가속화에 의해 발생하는 에일리어싱 아티팩트 현상을 없애기 위해 라인 전체를 고려한 인공 신경망(Deep Neural Networks)을 개발했다.
연구팀은 위 기술과 함께 기존 병렬 영상법에서 이용했던 복수 수신 코일의 정보를 활용했고, 이 방식을 통해 직접적으로 영향을 주는 부분만을 연결해 네트워크의 효율성을 높였다.
기존 방법들의 경우 서브 샘플링 패턴에 많은 영향을 받았지만 박 교수 연구팀의 기술은 다양한 서브샘플링 패턴에 적용 가능하며 기존 방법대비 복원 영상의 우수함을 보였고 실시간 복원 또한 가능하다.
박 교수는 “MRI는 환자 진단에 필요한 필수 장비가 됐지만 영상 획득 시간이 오래 걸려 비용이 비싸고 불편함이 많았다”며 “기계학습을 활용한 방법이 MRI의 영상 획득 시간을 크게 단축할 것으로 기대한다”고 말했다.
이번 연구는 과학기술정보통신부의 인공지능 국가전략프로젝트와 뇌과학원천기술개발사업의 지원을 받아 수행됐다.
□ 그림 설명
그림1. 국제 학술지 ‘메디컬 피직스 (Medical Physics)’12월호 표지
그림2. 제안하는 네트워크의 모식도
그림3. MRI의 일반적인 영상 획득 및 가속 영상 획득 모식도
2017.12.29 조회수 19980
박현욱 교수, 머신러닝 통해 MRI 영상촬영시간 단축기술 개발
우리 대학 전기및전자공학부 박현욱 교수 연구팀이 머신러닝 기반의 영상복원법을 이용해 자기공명영상장치(이하 MRI)의 영상 획득시간을 6배 이상 단축시킬 수 있는 기술을 개발했다.
이번 연구를 통해 MRI의 영상획득시간을 대폭 줄임으로써 환자의 편의성을 높일 뿐 아니라 의료비용 절감 효과를 기대할 수 있을 것으로 보인다.
권기남 박사과정이 1저자로 참여한 이번 연구는 국제 학술지 ‘메디컬 피직스(Medical Physics)’ 12월 13일자에 게재됐고 그 우수성을 인정받아 표지 논문에 선정됐다.
MRI는 방사능 없이 연조직의 다양한 대조도를 촬영할 수 있는 영상기기이다. 다양한 해부학적 구조 뿐 아니라 기능적, 생리학적 정보 또한 영상화 할 수 있기 때문에 의료 진단을 위해 매우 높은 빈도로 사용되고 있다.
하지만 MRI는 다른 의료영상기기에 비해 영상획득시간이 오래 걸린다는 단점이 있다. 따라서 환자들은 MRI를 찍기 위해 긴 시간을 대기해야 하고 촬영 과정에서도 자세를 움직이지 않아야 하는 등의 불편함을 감수해야 한다.
특히 길게 소요되는 영상획득시간은 MRI의 비싼 촬영 비용과 직접적인 연관이 있다.
박 교수 연구팀은 MRI의 영상획득시간을 줄이기 위해 데이터를 적게 수집하고 대신 부족한 데이터를 기계학습(Machine Learning)을 이용해 복원하는 방법을 개발했다.
기존의 MRI는 주파수 영역에서 여러 위상 인코딩을 하면서 순차적으로 한 줄씩 얻기 때문에 영상획득시간이 오래 걸린다. 획득 시간을 단축시키기 위해 저주파 영역에서만 데이터를 얻으면 저해상도 영상을 얻게 되고 듬성듬성 데이터를 얻으면 영상에서 인공물이 생기는 에일리어싱 아티팩트 현상이 발생한다.
이러한 에일리어싱 아티팩트를 해결하기 위해 다른 민감도를 갖는 여러 수신 코일을 활용한 병렬 영상법과 신호의 희소성을 이용한 압축 센싱 기법이 주로 활용됐다.
그러나 병렬 영상법은 수신 코일들의 설계에 영향을 받기 때문에 시간을 많이 단축할 수 없고 영상 복원에도 시간이 많이 걸린다.
연구팀은 MRI의 가속화에 의해 발생하는 에일리어싱 아티팩트 현상을 없애기 위해 라인 전체를 고려한 인공 신경망(Deep Neural Networks)을 개발했다.
연구팀은 위 기술과 함께 기존 병렬 영상법에서 이용했던 복수 수신 코일의 정보를 활용했고, 이 방식을 통해 직접적으로 영향을 주는 부분만을 연결해 네트워크의 효율성을 높였다.
기존 방법들의 경우 서브 샘플링 패턴에 많은 영향을 받았지만 박 교수 연구팀의 기술은 다양한 서브샘플링 패턴에 적용 가능하며 기존 방법대비 복원 영상의 우수함을 보였고 실시간 복원 또한 가능하다.
박 교수는 “MRI는 환자 진단에 필요한 필수 장비가 됐지만 영상 획득 시간이 오래 걸려 비용이 비싸고 불편함이 많았다”며 “기계학습을 활용한 방법이 MRI의 영상 획득 시간을 크게 단축할 것으로 기대한다”고 말했다.
이번 연구는 과학기술정보통신부의 인공지능 국가전략프로젝트와 뇌과학원천기술개발사업의 지원을 받아 수행됐다.
□ 그림 설명
그림1. 국제 학술지 ‘메디컬 피직스 (Medical Physics)’12월호 표지
그림2. 제안하는 네트워크의 모식도
그림3. MRI의 일반적인 영상 획득 및 가속 영상 획득 모식도
2017.12.29 조회수 19980