-
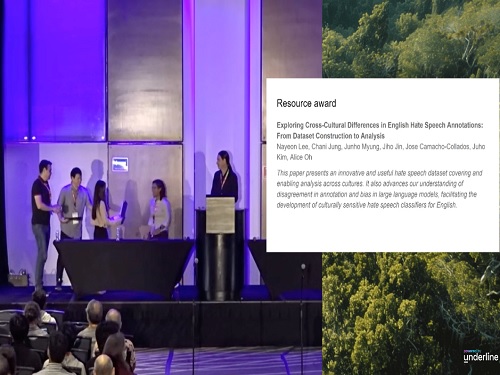 혐오 발언 탐지의 문화적 차이 해결, NAACL 2024에서 Resource Award 수상
전산학부 Users & Information Lab. 연구실의 오혜연 교수와 제1저자 석사과정 이나연(오혜연 교수 지도 학생)의 연구가 지난 6월 16일부터 21일까지 멕시코시티에서 열린 '2024 Annual Conference of the North American Chapter of the Association for Computational Linguistics' (NAACL 2024) 국제 학회에서 '교차 문화적 데이터셋 구축을 통한 영어 혐오 발언 어노테이션의 문화 간 차이와 영향 분석(Exploring Cross-Cultural Differences in English Hate Speech Annotations: From Dataset Construction to Analysis)'에 관한 논문으로 '리소스 어워드(Resource Award)'를 수상했다.
NAACL은 자연어처리 분야에서 최고 권위를 자랑하는 국제 학회로, 올해는 2,434편의 논문이 제출되었으며 그 중 565편만이 채택되었다 (채택률 23.2%).
Resource Award는 학회에서 주어지는 특별한 상 중 하나로, 제출 논문 중 혁신성, 활용 가능성, 영향력, 품질을 고려하여 선정된다.
이번 수상 연구는 교차 문화적 영어 혐오 발언 데이터셋을 구축하고, 문화 간 어노테이션 차이와 대형 언어 모델의 편향성을 분석하여 영어 혐오 발언 분류기의 문화적 민감성을 향상시키는 데 기여했다는점에서 높은 평가를 받았다.
이번 연구에는 KAIST 전산학부의 이나연, 정찬이, 명준호, 진지호 학생들과 Cardiff University의 Jose Camacho-Collados 교수, KAIST 전산학부의 김주호 교수, 오혜연 교수가 참여하였다. 본 연구는 미국, 호주, 영국, 싱가포르, 남아프리카 공화국의 5개 영어권 국가에서 수집된 데이터와 어노테이션을 기반으로 하여, 각국의 문화적 배경이 혐오 발언 어노테이션에 미치는 영향을 분석했다. 이를 통해 문화적 배경이 혐오 발언 인식에 미치는 중요한 차이를 밝혀냈으며, 특히 서구권 국가와 다른 문화적 맥락을 가진 국가 간의 어노테이션 차이가 두드러짐을 보였다.
오혜연 교수와 이나연 학생은 "이번 연구를 통해 혐오 발언 탐지에 있어 문화적 차이의 중요성을 밝힐 수 있어 기쁩니다. 연구팀의 노력 덕분에 이러한 성과를 얻을 수 있었으며, 앞으로도 자연어처리 분야에서 문화적 다양성을 고려한 연구를 지속해 나가겠습니다."라고 소감을 전했다.
이번 수상은 KAIST 연구팀의 혁신적인 접근과 자연어처리 분야에서의 문화 간 연구의 중요성을 국제적으로 인정받은 결과이다. 이는 앞으로 관련 연구 발전에 큰 기여를 할 것으로 기대된다.
연구 결과는 혐오 발언 탐지 분야뿐만 아니라, 다문화 사회에서의 인공지능 윤리와 문화적 편향성 해소 등 다양한 분야에 활용될 수 있을 것으로 기대된다.
자세한 내용은 논문 링크(https://aclanthology.org/2024.naacl-long.236)에서 확인할 수 있다.
혐오 발언 탐지의 문화적 차이 해결, NAACL 2024에서 Resource Award 수상
전산학부 Users & Information Lab. 연구실의 오혜연 교수와 제1저자 석사과정 이나연(오혜연 교수 지도 학생)의 연구가 지난 6월 16일부터 21일까지 멕시코시티에서 열린 '2024 Annual Conference of the North American Chapter of the Association for Computational Linguistics' (NAACL 2024) 국제 학회에서 '교차 문화적 데이터셋 구축을 통한 영어 혐오 발언 어노테이션의 문화 간 차이와 영향 분석(Exploring Cross-Cultural Differences in English Hate Speech Annotations: From Dataset Construction to Analysis)'에 관한 논문으로 '리소스 어워드(Resource Award)'를 수상했다.
NAACL은 자연어처리 분야에서 최고 권위를 자랑하는 국제 학회로, 올해는 2,434편의 논문이 제출되었으며 그 중 565편만이 채택되었다 (채택률 23.2%).
Resource Award는 학회에서 주어지는 특별한 상 중 하나로, 제출 논문 중 혁신성, 활용 가능성, 영향력, 품질을 고려하여 선정된다.
이번 수상 연구는 교차 문화적 영어 혐오 발언 데이터셋을 구축하고, 문화 간 어노테이션 차이와 대형 언어 모델의 편향성을 분석하여 영어 혐오 발언 분류기의 문화적 민감성을 향상시키는 데 기여했다는점에서 높은 평가를 받았다.
이번 연구에는 KAIST 전산학부의 이나연, 정찬이, 명준호, 진지호 학생들과 Cardiff University의 Jose Camacho-Collados 교수, KAIST 전산학부의 김주호 교수, 오혜연 교수가 참여하였다. 본 연구는 미국, 호주, 영국, 싱가포르, 남아프리카 공화국의 5개 영어권 국가에서 수집된 데이터와 어노테이션을 기반으로 하여, 각국의 문화적 배경이 혐오 발언 어노테이션에 미치는 영향을 분석했다. 이를 통해 문화적 배경이 혐오 발언 인식에 미치는 중요한 차이를 밝혀냈으며, 특히 서구권 국가와 다른 문화적 맥락을 가진 국가 간의 어노테이션 차이가 두드러짐을 보였다.
오혜연 교수와 이나연 학생은 "이번 연구를 통해 혐오 발언 탐지에 있어 문화적 차이의 중요성을 밝힐 수 있어 기쁩니다. 연구팀의 노력 덕분에 이러한 성과를 얻을 수 있었으며, 앞으로도 자연어처리 분야에서 문화적 다양성을 고려한 연구를 지속해 나가겠습니다."라고 소감을 전했다.
이번 수상은 KAIST 연구팀의 혁신적인 접근과 자연어처리 분야에서의 문화 간 연구의 중요성을 국제적으로 인정받은 결과이다. 이는 앞으로 관련 연구 발전에 큰 기여를 할 것으로 기대된다.
연구 결과는 혐오 발언 탐지 분야뿐만 아니라, 다문화 사회에서의 인공지능 윤리와 문화적 편향성 해소 등 다양한 분야에 활용될 수 있을 것으로 기대된다.
자세한 내용은 논문 링크(https://aclanthology.org/2024.naacl-long.236)에서 확인할 수 있다.
2024.07.16
조회수 4945
-
 기업 의사결정을 거대언어모델로 최초 해결
기업 내외의 상황에 따라 끊임없이 새롭게 결정해야 하는 기업 의사결정 문제는 지난 수십 년간 기업들이 전문적인 데이터 분석팀과 고가의 상용 데이터베이스 솔루션들을 통해 해결해 왔는데, 우리 연구진이 최초로 거대언어모델을 이용하여 풀어내어 화제다.
우리 대학 전산학부 김민수 교수 연구팀이 의사결정 문제, 기업 데이터베이스, 비즈니스 규칙 집합 세 가지가 주어졌을 때 거대언어모델을 이용해 의사결정에 필요한 정보를 데이터베이스로부터 찾고, 비즈니스 규칙에 부합하는 최적의 의사결정을 도출할 수 있는 기술(일명 계획 RAG, PlanRAG)을 개발했다고 19일 밝혔다.
거대언어모델은 매우 방대한 데이터를 학습했기 때문에 학습에 사용된 바 없는 데이터를 바탕으로 답변할 때나 오래전 데이터를 바탕으로 답변하는 등 문제점들이 지적되었다. 이런 문제들을 해결하기 위해 거대언어모델이 학습된 내용만으로 답변하는 것 대신, 데이터베이스를 검색해 답변을 생성하는 검색 증강 생성(Retrieval-Augmented Generation; 이하 RAG) 기술이 최근 각광받고 있다.
그러나, 사용자의 질문이 복잡할 경우 다양한 검색 결과를 바탕으로 추가 정보를 다시 검색하여 적절한 답변을 생성할 때까지 반복하는 반복적 RAG(IterativeRAG)라는 기술이 개발됐으며, 이는 현재까지 개발된 가장 최신의 기술이다.
연구팀은 기업 의사결정 문제가 GPT-3.5 터보에서 반복적 RAG 기술을 사용하더라도 정답률이 10% 미만에 이르는 고난도 문제임을 보이고, 이를 해결하기 위해 반복적 RAG 기술을 한층 더 발전시킨 계획 RAG(PlanRAG)라는 기술을 개발했다.
계획 RAG(PlanRAG)는 기존의 RAG 기술들과 다르게 주어진 의사결정 문제, 데이터베이스, 비즈니스 규칙을 바탕으로 어떤 데이터 분석이 필요한지에 대한 거시적 차원의 계획(plan)을 먼저 생성한 후, 그 계획에 따라 반복적 RAG를 이용해 미시적 차원의 분석을 수행한다.
이는 마치 기업의 의사결정권자가 어떤 데이터 분석이 필요한지 계획을 세우면, 그 계획에 따라 데이터 분석팀이 데이터베이스 솔루션들을 이용해 분석하는 형태와 유사하며, 다만 이러한 과정을 모두 사람이 아닌 거대언어모델이 수행하는 것이 커다란 차이점이다. 계획 RAG 기술은 계획에 따른 데이터 분석 결과로 적절한 답변을 도출하지 못하면, 다시 계획을 수립하고 데이터 분석을 수행하는 과정을 반복한다.
김민수 교수는 “지금까지 거대언어모델 기반으로 의사결정 문제를 푼 연구가 없었던 관계로, 기업 의사결정 성능을 평가할 수 있는 의사결정 질의응답(DQA) 벤치마크를 새롭게 만들었다. 그리고 해당 벤치마크에서 GPT-4.0을 사용할 때 종래의 반복적 RAG에 비해 계획 RAG가 의사결정 정답률을 최대 32.5% 개선함을 보였다. 이를 통해 기업들이 복잡한 비즈니스 상황에서 최적의 의사결정을 사람이 아닌 거대언어모델을 이용하여 내리는데 적용되기를 기대한다”고 말했다.
이번 연구에는 김 교수의 제자인 이명화 박사과정과 안선호 석사과정이 공동 제1 저자로, 김 교수가 교신 저자로 참여했으며, 연구 결과는 자연어처리 분야 최고 학회(top conference)인 ‘NAACL’ 에 지난 6월 17일 발표됐다. (논문 제목: PlanRAG: A Plan-then-Retrieval Augmented Generation for Generative Large Language Models as Decision Makers)
한편, 이번 연구는 과기정통부 IITP SW스타랩 및 ITRC 사업, 한국연구재단 선도연구센터인 암흑데이터 극한 활용 연구센터의 지원을 받아 수행됐다.
기업 의사결정을 거대언어모델로 최초 해결
기업 내외의 상황에 따라 끊임없이 새롭게 결정해야 하는 기업 의사결정 문제는 지난 수십 년간 기업들이 전문적인 데이터 분석팀과 고가의 상용 데이터베이스 솔루션들을 통해 해결해 왔는데, 우리 연구진이 최초로 거대언어모델을 이용하여 풀어내어 화제다.
우리 대학 전산학부 김민수 교수 연구팀이 의사결정 문제, 기업 데이터베이스, 비즈니스 규칙 집합 세 가지가 주어졌을 때 거대언어모델을 이용해 의사결정에 필요한 정보를 데이터베이스로부터 찾고, 비즈니스 규칙에 부합하는 최적의 의사결정을 도출할 수 있는 기술(일명 계획 RAG, PlanRAG)을 개발했다고 19일 밝혔다.
거대언어모델은 매우 방대한 데이터를 학습했기 때문에 학습에 사용된 바 없는 데이터를 바탕으로 답변할 때나 오래전 데이터를 바탕으로 답변하는 등 문제점들이 지적되었다. 이런 문제들을 해결하기 위해 거대언어모델이 학습된 내용만으로 답변하는 것 대신, 데이터베이스를 검색해 답변을 생성하는 검색 증강 생성(Retrieval-Augmented Generation; 이하 RAG) 기술이 최근 각광받고 있다.
그러나, 사용자의 질문이 복잡할 경우 다양한 검색 결과를 바탕으로 추가 정보를 다시 검색하여 적절한 답변을 생성할 때까지 반복하는 반복적 RAG(IterativeRAG)라는 기술이 개발됐으며, 이는 현재까지 개발된 가장 최신의 기술이다.
연구팀은 기업 의사결정 문제가 GPT-3.5 터보에서 반복적 RAG 기술을 사용하더라도 정답률이 10% 미만에 이르는 고난도 문제임을 보이고, 이를 해결하기 위해 반복적 RAG 기술을 한층 더 발전시킨 계획 RAG(PlanRAG)라는 기술을 개발했다.
계획 RAG(PlanRAG)는 기존의 RAG 기술들과 다르게 주어진 의사결정 문제, 데이터베이스, 비즈니스 규칙을 바탕으로 어떤 데이터 분석이 필요한지에 대한 거시적 차원의 계획(plan)을 먼저 생성한 후, 그 계획에 따라 반복적 RAG를 이용해 미시적 차원의 분석을 수행한다.
이는 마치 기업의 의사결정권자가 어떤 데이터 분석이 필요한지 계획을 세우면, 그 계획에 따라 데이터 분석팀이 데이터베이스 솔루션들을 이용해 분석하는 형태와 유사하며, 다만 이러한 과정을 모두 사람이 아닌 거대언어모델이 수행하는 것이 커다란 차이점이다. 계획 RAG 기술은 계획에 따른 데이터 분석 결과로 적절한 답변을 도출하지 못하면, 다시 계획을 수립하고 데이터 분석을 수행하는 과정을 반복한다.
김민수 교수는 “지금까지 거대언어모델 기반으로 의사결정 문제를 푼 연구가 없었던 관계로, 기업 의사결정 성능을 평가할 수 있는 의사결정 질의응답(DQA) 벤치마크를 새롭게 만들었다. 그리고 해당 벤치마크에서 GPT-4.0을 사용할 때 종래의 반복적 RAG에 비해 계획 RAG가 의사결정 정답률을 최대 32.5% 개선함을 보였다. 이를 통해 기업들이 복잡한 비즈니스 상황에서 최적의 의사결정을 사람이 아닌 거대언어모델을 이용하여 내리는데 적용되기를 기대한다”고 말했다.
이번 연구에는 김 교수의 제자인 이명화 박사과정과 안선호 석사과정이 공동 제1 저자로, 김 교수가 교신 저자로 참여했으며, 연구 결과는 자연어처리 분야 최고 학회(top conference)인 ‘NAACL’ 에 지난 6월 17일 발표됐다. (논문 제목: PlanRAG: A Plan-then-Retrieval Augmented Generation for Generative Large Language Models as Decision Makers)
한편, 이번 연구는 과기정통부 IITP SW스타랩 및 ITRC 사업, 한국연구재단 선도연구센터인 암흑데이터 극한 활용 연구센터의 지원을 받아 수행됐다.
2024.06.19
조회수 5689