%EA%B8%B0%EA%B3%84%ED%95%99%EC%8A%B5
-
 AI 기반 화재 걱정없는 고효율 아연-공기 배터리 개발
‘제2의 반도체’로 불리는 리튬이온 전지(LIB)는 가장 높은 시장 점유율로 에너지 저장 장치 시장을 주도하고 있지만, 화재에 취약하는 약점을 가지고 있다. 한국 연구진이 화재로부터 안전하고 값이 저렴한 아연 금속과 공기중의 산소로 구동되는 고에너지 밀도를 가진 고출력 차세대 전지를 개발했다.
우리 대학 신소재공학과 강정구 교수 연구팀이 연세대 한병찬 교수 연구팀, 경북대 최상일 교수 연구팀 및 성균관대 정형모 교수 연구팀과의 공동연구를 통해, 인공지능 기반 이종기능* 전기화학 촉매를 개발 및 촉매 활성 메커니즘을 규명하고, 고효율 아연-공기 전지를 개발했다고 4일 밝혔다.
*이종기능: 충전(Charging) 동안에서의 산소 발생(OER) 기능과 방전(Discharging) 동안의 산소 환원 (ORR) 기능
최근 활발하게 연구가 진행되고 있는 아연-공기 전지 배터리의 음극에 사용되는 아연 금속과 공기극*에 필요한 공기는 자연에 풍부하다는 특성 때문에 소재 비용이 적다는 장점이 있다.
*공기극: 공기 중의 산소를 전극 반응에 활용하는 양극(+)
하지만 고효율 아연-공기 전지를 구현하기 위해서는 충·방전 시에 공기극에서 일어나는 산소 환원 및 산소 발생 반응이 잘 일어나게 하는 이종기능 촉매의 설계가 필수적이다. 하지만 기존에 알려진 상용 촉매는 백금, 이리듐 등 귀금속을 기반으로 하고 있어 가격 경쟁력이 있으면서도 높은 활성도를 지닌 촉매 물질의 개발이 필요하다.
강정구 교수 공동연구팀은 아연 금속-공기 전지에 쓰일 값이 저렴한 전이금속산화물 이종접합 촉매 물질을 개발했다. 해당 촉매 물질은 아연-공기 전지에 사용 시에 귀금속 기반 촉매보다 높은 활성도 및 안정성을 나타냈다. 이와 더불어 해당 연구팀은 인공지능을 활용하여, 기계학습 힘장*을 개발하여 계면에서의 원자구조와 촉매 활성 메커니즘을 정확히 규명하였다.
* 기계학습 힘장(Machine learning force field): 촉매의 성능을 높이려면 계면에서 반응이 원활하게 일어나야 함. 계면에 존재하는 수천만개의 원자들간의 상호 힘을 정확히 이해하기는 기존 방법으로 불가능함. 본 연구에서는 인공지능을 활용하여 양자역학 기반 기계학습 힘장을 개발하여 수천만개의 원자로 구성된 계면구조와 계면에서의 반응 메커니즘을 규명하는데 활용하였음.
연구팀은 개발된 이종기능 촉매를 활용해 아연-공기 완전셀을 구성해 고성능 에너지 저장 소자를 구현했다. 구현된 아연-공기 전지는 기존 상용화된 리튬이온 배터리를 뛰어넘는 에너지 밀도를 가짐을 확인했으며, 저렴한 원료 소재 및 안전성으로 인해 향후 전기 자동차, 웨어러블 전자기기 등에 적용할 수 있을 것으로 예상된다.
강 교수는 "이번 연구로 개발된 전이금속 산화물 기반의 차세대 촉매 소재는 가격 경쟁력과 더불어 높은 촉매 활성도로 인해 아연-금속 공기 전지의 상용화에 기여할 수 있다ˮ라며 "중·소형 전력원뿐만 아니라 향후 전기 자동차까지 활용 범위를 확대해 적용될 수 있을 것이다ˮ고 말했다.
신소재공학과 최종휘 박사과정이 주도한 이번 연구 결과는 에너지 저장 소재 분야의 국제 학술지 `에너지 스토리지 머터리얼스(Energy Storage Materials)'에 지난 1월 14일 字 게재됐다. (논문명: Zeolitic imidazolate framework-derived bifunctional CoO-Mn3O4 heterostructure cathode enhancing oxygen reduction/evolution via dynamic O-vacancy formation and healing for high-performance Zn-air batteries, https://doi.org/10.1016/j.ensm.2025.104040)
한편 이번 연구는 과학기술정보통신부와 한국연구재단의 나노 및 소재기술개발사업 미래기술연구실의 지원을 받아 수행됐다.
2025.03.04 조회수 3835
AI 기반 화재 걱정없는 고효율 아연-공기 배터리 개발
‘제2의 반도체’로 불리는 리튬이온 전지(LIB)는 가장 높은 시장 점유율로 에너지 저장 장치 시장을 주도하고 있지만, 화재에 취약하는 약점을 가지고 있다. 한국 연구진이 화재로부터 안전하고 값이 저렴한 아연 금속과 공기중의 산소로 구동되는 고에너지 밀도를 가진 고출력 차세대 전지를 개발했다.
우리 대학 신소재공학과 강정구 교수 연구팀이 연세대 한병찬 교수 연구팀, 경북대 최상일 교수 연구팀 및 성균관대 정형모 교수 연구팀과의 공동연구를 통해, 인공지능 기반 이종기능* 전기화학 촉매를 개발 및 촉매 활성 메커니즘을 규명하고, 고효율 아연-공기 전지를 개발했다고 4일 밝혔다.
*이종기능: 충전(Charging) 동안에서의 산소 발생(OER) 기능과 방전(Discharging) 동안의 산소 환원 (ORR) 기능
최근 활발하게 연구가 진행되고 있는 아연-공기 전지 배터리의 음극에 사용되는 아연 금속과 공기극*에 필요한 공기는 자연에 풍부하다는 특성 때문에 소재 비용이 적다는 장점이 있다.
*공기극: 공기 중의 산소를 전극 반응에 활용하는 양극(+)
하지만 고효율 아연-공기 전지를 구현하기 위해서는 충·방전 시에 공기극에서 일어나는 산소 환원 및 산소 발생 반응이 잘 일어나게 하는 이종기능 촉매의 설계가 필수적이다. 하지만 기존에 알려진 상용 촉매는 백금, 이리듐 등 귀금속을 기반으로 하고 있어 가격 경쟁력이 있으면서도 높은 활성도를 지닌 촉매 물질의 개발이 필요하다.
강정구 교수 공동연구팀은 아연 금속-공기 전지에 쓰일 값이 저렴한 전이금속산화물 이종접합 촉매 물질을 개발했다. 해당 촉매 물질은 아연-공기 전지에 사용 시에 귀금속 기반 촉매보다 높은 활성도 및 안정성을 나타냈다. 이와 더불어 해당 연구팀은 인공지능을 활용하여, 기계학습 힘장*을 개발하여 계면에서의 원자구조와 촉매 활성 메커니즘을 정확히 규명하였다.
* 기계학습 힘장(Machine learning force field): 촉매의 성능을 높이려면 계면에서 반응이 원활하게 일어나야 함. 계면에 존재하는 수천만개의 원자들간의 상호 힘을 정확히 이해하기는 기존 방법으로 불가능함. 본 연구에서는 인공지능을 활용하여 양자역학 기반 기계학습 힘장을 개발하여 수천만개의 원자로 구성된 계면구조와 계면에서의 반응 메커니즘을 규명하는데 활용하였음.
연구팀은 개발된 이종기능 촉매를 활용해 아연-공기 완전셀을 구성해 고성능 에너지 저장 소자를 구현했다. 구현된 아연-공기 전지는 기존 상용화된 리튬이온 배터리를 뛰어넘는 에너지 밀도를 가짐을 확인했으며, 저렴한 원료 소재 및 안전성으로 인해 향후 전기 자동차, 웨어러블 전자기기 등에 적용할 수 있을 것으로 예상된다.
강 교수는 "이번 연구로 개발된 전이금속 산화물 기반의 차세대 촉매 소재는 가격 경쟁력과 더불어 높은 촉매 활성도로 인해 아연-금속 공기 전지의 상용화에 기여할 수 있다ˮ라며 "중·소형 전력원뿐만 아니라 향후 전기 자동차까지 활용 범위를 확대해 적용될 수 있을 것이다ˮ고 말했다.
신소재공학과 최종휘 박사과정이 주도한 이번 연구 결과는 에너지 저장 소재 분야의 국제 학술지 `에너지 스토리지 머터리얼스(Energy Storage Materials)'에 지난 1월 14일 字 게재됐다. (논문명: Zeolitic imidazolate framework-derived bifunctional CoO-Mn3O4 heterostructure cathode enhancing oxygen reduction/evolution via dynamic O-vacancy formation and healing for high-performance Zn-air batteries, https://doi.org/10.1016/j.ensm.2025.104040)
한편 이번 연구는 과학기술정보통신부와 한국연구재단의 나노 및 소재기술개발사업 미래기술연구실의 지원을 받아 수행됐다.
2025.03.04 조회수 3835 -
 항암 효과 낮추는 ‘세포 간 이질성’ 극복 전략 찾았다
효과가 높은 신약 및 치료법 개발을 위한 단서가 제시됐다. 우리 대학 수리과학과 김재경 교수(기초과학연구원(IBS) 수리 및 계산 과학 연구단 의생명 수학 그룹 CI(Chief Investigator)) 연구팀은 인공지능(AI)을 이용해 동일 외부 자극에 개별 세포마다 반응하는 정도가 다른 ‘세포 간 이질성’의 근본적인 원인을 찾아내고, 이질성을 최소화할 수 있는 전략을 제시했다.
우리 몸속 세포는 약물, 삼투압 변화 등 다양한 외부 자극에 반응하는 신호 전달 체계(signaling pathway)가 있다. 신호 전달 체계는 세포가 외부 환경과 상호작용하며 생존하는 데 핵심적인 역할을 한다. 세포의 신호 전달 체계는 노벨생리의학상의 단골 주제일 정도로 중요하지만, 규명을 위해서는 수십 년에 걸친 연구가 필요하다.
신호 전달 체계는 세포 간 이질성에도 영향을 미친다. 세포 간 이질성은 똑같은 유전자를 가진 세포들이 동일 외부 자극에 다르게 반응하는 정도를 뜻한다. 하지만 복잡한 신호 전달 체계의 전 과정을 직접 관측하는 일이 현재 기술로는 어렵기 때문에 지금까지는 신호 전달 체계와 세포 간 이질성의 명확한 연결고리를 알지 못했다.
세포 간 이질성은 질병 치료에 있어 더욱 중요한 고려 요소다. 가령, 항암제를 투여했을 때 세포 간 이질성으로 인해 일부 암세포만 사멸되고, 일부는 살아남는다면 완치가 되지 않는다. 세포 간 이질성의 근본적인 원인을 찾고, 이질성을 최소화할 수 있는 전략을 도출해야 치료 효과를 높인 신약 설계가 가능해진다.
제1 저자인 홍혁표 IBS 전(前) 학생연수원(現 미국 위스콘신 메디슨대 방문조교수)은 “우리 연구진은 선행 연구(Science Advances, 2022)에서 세포 내 신호 전달 체계를 묘사한 수리 모델을 개발한 바 있다”며 “당시엔 신호 전달 체계의 중간 과정이 한 개의 경로만 있다고 가정해 얻을 수 있는 정보도 한계가 있었지만, 이번 연구에서는 AI를 활용해 중간 과정의 비밀까지 풀어냈다”고 말했다.
연구진은 기계 학습 방법론인 ‘Density-PINNs(Density Physics-Informed Neural Networks)’를 개발해 신호 전달 체계와 세포 간 이질성의 연결고리를 찾았다. 세포가 외부 자극에 노출되면 신호 전달 체계를 거쳐 반응 단백질이 생성된다. 시간에 따라 축적된 반응 단백질의 양을 이용하면 신호 전달 소요 시간의 분포를 추론할 수 있다. 이 분포는 신호 전달 체계가 몇 개의 경로로 구성됐는지를 알려준다. 즉, Density-PINNs를 이용하면 쉽게 관측할 수 있는 반응 단백질의 시계열 데이터로부터 직접 관찰하기 어려운 신호 전달 체계에 대한 정보를 추정할 수 있다는 의미다.
이어 연구진은 실제 대장균의 항생제에 대한 반응 실험 데이터에 Density-PINNs를 적용하여 세포 간 이질성의 원인도 찾았다. 신호 전달 체계가 단일 경로로 이뤄진 때(직렬)에 비해 여러 경로로 이뤄졌을 때(병렬)가 세포 간 이질성이 적다는 것을 알아냈다.
제1 저자인 조현태 연구원은 “추가 연구가 필요하지만, 신호 전달 체계가 병렬 구조일 경우 극단적인 신호가 서로 상쇄되어서 세포 간 이질성이 적어지는 것으로 보인다”며 “신호 전달 체계가 병렬 구조를 보이도록 약물이나 화학 요법 치료 전략을 세우면 치료 효과를 높일 수 있다는 의미”라고 설명했다.
연구를 이끈 김재경 교수는 “복잡한 세포 신호 전달 체계의 전 과정을 파악하려면 수십 년의 연구가 필요하지만, 우리 연구진이 제시한 방법론은 수 시간 내에 치료에 필요한 핵심 정보만 알아내 치료에 활용할 수 있다”며 “이번 연구를 실제 현장에서 사용되는 약물에 적용하여 치료 효과를 개선할 수 있기를 기대한다”고 말했다.
연구 결과는 지난해 12월 26일 국제학술지 셀(Cell)의 자매지인 ‘패턴스(Patterns)’에 실렸다.
※ 논문명: Density physics-informed neural networks reveal sources of cell heterogeneity in signal transduction
2024.01.17 조회수 6033
항암 효과 낮추는 ‘세포 간 이질성’ 극복 전략 찾았다
효과가 높은 신약 및 치료법 개발을 위한 단서가 제시됐다. 우리 대학 수리과학과 김재경 교수(기초과학연구원(IBS) 수리 및 계산 과학 연구단 의생명 수학 그룹 CI(Chief Investigator)) 연구팀은 인공지능(AI)을 이용해 동일 외부 자극에 개별 세포마다 반응하는 정도가 다른 ‘세포 간 이질성’의 근본적인 원인을 찾아내고, 이질성을 최소화할 수 있는 전략을 제시했다.
우리 몸속 세포는 약물, 삼투압 변화 등 다양한 외부 자극에 반응하는 신호 전달 체계(signaling pathway)가 있다. 신호 전달 체계는 세포가 외부 환경과 상호작용하며 생존하는 데 핵심적인 역할을 한다. 세포의 신호 전달 체계는 노벨생리의학상의 단골 주제일 정도로 중요하지만, 규명을 위해서는 수십 년에 걸친 연구가 필요하다.
신호 전달 체계는 세포 간 이질성에도 영향을 미친다. 세포 간 이질성은 똑같은 유전자를 가진 세포들이 동일 외부 자극에 다르게 반응하는 정도를 뜻한다. 하지만 복잡한 신호 전달 체계의 전 과정을 직접 관측하는 일이 현재 기술로는 어렵기 때문에 지금까지는 신호 전달 체계와 세포 간 이질성의 명확한 연결고리를 알지 못했다.
세포 간 이질성은 질병 치료에 있어 더욱 중요한 고려 요소다. 가령, 항암제를 투여했을 때 세포 간 이질성으로 인해 일부 암세포만 사멸되고, 일부는 살아남는다면 완치가 되지 않는다. 세포 간 이질성의 근본적인 원인을 찾고, 이질성을 최소화할 수 있는 전략을 도출해야 치료 효과를 높인 신약 설계가 가능해진다.
제1 저자인 홍혁표 IBS 전(前) 학생연수원(現 미국 위스콘신 메디슨대 방문조교수)은 “우리 연구진은 선행 연구(Science Advances, 2022)에서 세포 내 신호 전달 체계를 묘사한 수리 모델을 개발한 바 있다”며 “당시엔 신호 전달 체계의 중간 과정이 한 개의 경로만 있다고 가정해 얻을 수 있는 정보도 한계가 있었지만, 이번 연구에서는 AI를 활용해 중간 과정의 비밀까지 풀어냈다”고 말했다.
연구진은 기계 학습 방법론인 ‘Density-PINNs(Density Physics-Informed Neural Networks)’를 개발해 신호 전달 체계와 세포 간 이질성의 연결고리를 찾았다. 세포가 외부 자극에 노출되면 신호 전달 체계를 거쳐 반응 단백질이 생성된다. 시간에 따라 축적된 반응 단백질의 양을 이용하면 신호 전달 소요 시간의 분포를 추론할 수 있다. 이 분포는 신호 전달 체계가 몇 개의 경로로 구성됐는지를 알려준다. 즉, Density-PINNs를 이용하면 쉽게 관측할 수 있는 반응 단백질의 시계열 데이터로부터 직접 관찰하기 어려운 신호 전달 체계에 대한 정보를 추정할 수 있다는 의미다.
이어 연구진은 실제 대장균의 항생제에 대한 반응 실험 데이터에 Density-PINNs를 적용하여 세포 간 이질성의 원인도 찾았다. 신호 전달 체계가 단일 경로로 이뤄진 때(직렬)에 비해 여러 경로로 이뤄졌을 때(병렬)가 세포 간 이질성이 적다는 것을 알아냈다.
제1 저자인 조현태 연구원은 “추가 연구가 필요하지만, 신호 전달 체계가 병렬 구조일 경우 극단적인 신호가 서로 상쇄되어서 세포 간 이질성이 적어지는 것으로 보인다”며 “신호 전달 체계가 병렬 구조를 보이도록 약물이나 화학 요법 치료 전략을 세우면 치료 효과를 높일 수 있다는 의미”라고 설명했다.
연구를 이끈 김재경 교수는 “복잡한 세포 신호 전달 체계의 전 과정을 파악하려면 수십 년의 연구가 필요하지만, 우리 연구진이 제시한 방법론은 수 시간 내에 치료에 필요한 핵심 정보만 알아내 치료에 활용할 수 있다”며 “이번 연구를 실제 현장에서 사용되는 약물에 적용하여 치료 효과를 개선할 수 있기를 기대한다”고 말했다.
연구 결과는 지난해 12월 26일 국제학술지 셀(Cell)의 자매지인 ‘패턴스(Patterns)’에 실렸다.
※ 논문명: Density physics-informed neural networks reveal sources of cell heterogeneity in signal transduction
2024.01.17 조회수 6033 -
 강수 관측 오차범위 42.5% 줄인 알고리즘 개발
강수량의 정확한 파악은 지구의 물 순환을 이해하고 수자원과 재해 대응을 위해 중요하다. 강수량 추정을 위한 알고리즘에는 다양한 방법들이 제안되어 왔으며, 최근에는 기계학습을 이용한 방법들이 많이 제안되고 있다.
우리 대학 문술미래전략대학원(건설및환경공학과 및 녹색성장지속가능대학원 겸임) 김형준 교수와 도쿄대 등으로 구성된 국제 공동연구팀이 인공위성에 탑재된 마이크로파 라디오미터의 관측값을 이용해 지상 강수량을 추정하는 새로운 기계학습 방법을 제안했다고 25일 밝혔다. 연구팀은 기존의 방법과 비교해 전 강수량에 대해 오차(RMSE)를 최소 15.9%에서 최대 42.5%까지 줄이는 데 성공했다.
단순한 데이터 주도(data-driven)모델은 대량의 훈련 데이터가 필요하고 물리적인 일관성이 보장되지 않으며 결과의 원인 분석이 어렵다는 등의 문제가 있었다. 연구팀은 이번 연구에서 위성 강수량 추정에 대한 분야 지식을 명시적으로 포함함으로써 학습 모델 내의 상호 의존적인 지식 교환을 구현했다. 구체적으로, 멀티태스크 학습(multitask learning)이라는 심층 학습 기법을 사용해 강수 여부를 인식하는 분류 모델과 강수 강도를 추정하는 회귀 모델을 통합하고 동시에 학습시켰다.
이번 연구에서 제안한 기계학습 모델에는 이번에 포함된 메커니즘 외에도 다양한 물리적 메커니즘을 포함할 수 있다. 예를 들어, 비 또는 눈, 진눈깨비 등 강수 종류의 분류 및 상승 기류 또는 층상 구름 유형 등 강수를 일으키는 구름 유형의 분류를 포함함으로써 앞으로 추정의 정확도가 더욱 향상될 것으로 기대된다.
김형준 교수의 이번 연구 결과는 국제 학술지 ‘지구물리 연구 레터(Geophysical Research Letters)’에 지난 4월 16일 출판됐다. (논문명: Multi-Task Learning for Simultaneous Retrievals of Passive Microwave Precipitation Estimates and Rain/No-Rain Classification; doi:10.1029/2022GL102283)
한편 이번 연구는 한국연구재단 해외우수과학자유치사업(BP+)와 정보통신기획평가원 인공지능대학원지원(한국과학기술원)지원을 받아 수행됐다.
2023.04.25 조회수 8680
강수 관측 오차범위 42.5% 줄인 알고리즘 개발
강수량의 정확한 파악은 지구의 물 순환을 이해하고 수자원과 재해 대응을 위해 중요하다. 강수량 추정을 위한 알고리즘에는 다양한 방법들이 제안되어 왔으며, 최근에는 기계학습을 이용한 방법들이 많이 제안되고 있다.
우리 대학 문술미래전략대학원(건설및환경공학과 및 녹색성장지속가능대학원 겸임) 김형준 교수와 도쿄대 등으로 구성된 국제 공동연구팀이 인공위성에 탑재된 마이크로파 라디오미터의 관측값을 이용해 지상 강수량을 추정하는 새로운 기계학습 방법을 제안했다고 25일 밝혔다. 연구팀은 기존의 방법과 비교해 전 강수량에 대해 오차(RMSE)를 최소 15.9%에서 최대 42.5%까지 줄이는 데 성공했다.
단순한 데이터 주도(data-driven)모델은 대량의 훈련 데이터가 필요하고 물리적인 일관성이 보장되지 않으며 결과의 원인 분석이 어렵다는 등의 문제가 있었다. 연구팀은 이번 연구에서 위성 강수량 추정에 대한 분야 지식을 명시적으로 포함함으로써 학습 모델 내의 상호 의존적인 지식 교환을 구현했다. 구체적으로, 멀티태스크 학습(multitask learning)이라는 심층 학습 기법을 사용해 강수 여부를 인식하는 분류 모델과 강수 강도를 추정하는 회귀 모델을 통합하고 동시에 학습시켰다.
이번 연구에서 제안한 기계학습 모델에는 이번에 포함된 메커니즘 외에도 다양한 물리적 메커니즘을 포함할 수 있다. 예를 들어, 비 또는 눈, 진눈깨비 등 강수 종류의 분류 및 상승 기류 또는 층상 구름 유형 등 강수를 일으키는 구름 유형의 분류를 포함함으로써 앞으로 추정의 정확도가 더욱 향상될 것으로 기대된다.
김형준 교수의 이번 연구 결과는 국제 학술지 ‘지구물리 연구 레터(Geophysical Research Letters)’에 지난 4월 16일 출판됐다. (논문명: Multi-Task Learning for Simultaneous Retrievals of Passive Microwave Precipitation Estimates and Rain/No-Rain Classification; doi:10.1029/2022GL102283)
한편 이번 연구는 한국연구재단 해외우수과학자유치사업(BP+)와 정보통신기획평가원 인공지능대학원지원(한국과학기술원)지원을 받아 수행됐다.
2023.04.25 조회수 8680 -
 상상만으로 원하는 방향으로 사용가능한 로봇 팔 뇌-기계 인터페이스 개발
우리 대학 뇌인지과학과 정재승 교수 연구팀이 인간의 뇌 신호를 해독해 장기간의 훈련 없이 생각만으로 로봇 팔을 원하는 방향으로 제어하는 뇌-기계 인터페이스 시스템을 개발했다고 24일 밝혔다.
서울의대 신경외과 정천기 교수 연구팀과 공동연구로 진행된 이번 연구에서 정 교수 연구팀은 뇌전증 환자를 대상으로 팔을 뻗는 동작을 상상할 때 관측되는 대뇌 피질 신호를 분석해 환자가 의도한 팔 움직임을 예측하는 팔 동작 방향 상상 뇌 신호 디코딩 기술을 개발했다. 이러한 디코딩 기술은 실제 움직임이나 복잡한 운동 상상이 필요하지 않기 때문에 운동장애를 겪는 환자가 장기간 훈련 없이도 자연스럽고 쉽게 로봇 팔을 제어할 수 있어 앞으로 다양한 의료기기에 폭넓게 적용되리라 기대된다.
바이오및뇌공학과 장상진 박사과정이 제1 저자로 참여한 이번 연구는 뇌공학 분야의 세계적인 국제 학술지 `저널 오브 뉴럴 엔지니어링 (Journal of Neural Engineering)' 9월 19권 5호에 출판됐다. (논문명 : Decoding trajectories of imagined hand movement using electrocorticograms for brain-machine interface).
뇌-기계 인터페이스는 인간이 생각만으로 기계를 제어할 수 있는 기술로, 팔을 움직이는 데 장애가 있거나 절단된 환자가 로봇 팔을 제어해 일상에 필요한 팔 동작을 회복할 수 있는 보조기술로 크게 주목받고 있다.
로봇 팔 제어를 위한 뇌-기계 인터페이스를 구현하기 위해서는 인간이 팔을 움직일 때 뇌에서 발생하는 전기신호를 측정하고 기계학습 등 다양한 인공지능 분석기법으로 뇌 신호를 해독해 의도한 움직임을 뇌 신호로부터 예측할 수 있는 디코딩 기술이 필요하다.
그러나 상지 절단 등으로 운동장애를 겪는 환자는 팔을 실제로 움직이기 어려우므로, 상상만으로 로봇 팔의 방향을 지시할 수 있는 인터페이스가 절실히 요구된다. 뇌 신호 디코딩 기술은 팔의 실제 움직임이 아닌 상상 뇌 신호에서 어느 방향으로 사용자가 상상했는지 예측할 수 있어야 하는데, 상상 뇌 신호는 실제 움직임 뇌 신호보다 신호대잡음비(signal to noise ratio)가 현저히 낮아 팔의 정확한 방향을 예측하기 어려운 문제점이 오랫동안 난제였다. 이러한 문제점을 극복하고자 기존 연구들에서는 팔을 움직이기 위해 신호대잡음비가 더 높은 다른 신체 동작을 상상하는 방법을 시도했으나, 의도하고자 하는 팔 뻗기와 인지적 동작 간의 부자연스러운 괴리로 인해 사용자가 장기간 훈련해야 하는 불편함을 초래했다.
따라서 팔을 뻗는 상상을 할 때 어느 방향으로 뻗었는지 예측하는 디코딩 기술은 정확도가 떨어지고 환자가 사용법을 습득하기 어려운 문제점이 있다. 이 문제가 오랫동안 뇌-기계 인터페이스 분야에서 해결해야 할 난제였다.
연구팀은 문제 해결을 위해 사용자의 자연스러운 팔 동작 상상을 공간해상도가 우수한 대뇌 피질 신호(electrocorticogram)로 측정하고, 변분 베이지안 최소제곱(variational Bayesian least square) 기계학습 기법을 활용해 직접 측정이 어려운 팔 동작의 방향 정보를 계산할 수 있는 디코딩 기술을 처음으로 개발했다.
연구팀의 팔 동작 상상 신호 분석기술은 운동피질을 비롯한 특정 대뇌 영역에 국한되지 않아, 사용자마다 상이할 수 있는 상상 신호와 대뇌 영역 특성을 맞춤형으로 학습해 최적의 계산모델 파라미터 결괏값을 출력할 수 있다.
연구팀은 대뇌 피질 신호 디코딩을 통해 환자가 상상한 팔 뻗기 방향을 최대 80% 이상의 정확도로 예측할 수 있음을 확인했다.
나아가 계산모델을 분석함으로써 방향 상상에 중요한 대뇌의 시공간적 특성을 밝혔고, 상상하는 인지적 과정이 팔을 실제로 뻗는 과정에 근접할수록 방향 예측정확도가 상당히 더 높아질 수 있음을 연구팀은 확인했다.
연구팀은 지난 2월 인공지능과 유전자 알고리즘 기반 고 정확도 로봇 팔 제어 뇌-기계 인터페이스 선행 연구 결과를 세계적인 학술지 `어플라이드 소프트 컴퓨팅(Applied soft computing)'에 발표한 바 있다. 이번 후속 연구는 그에 기반해 계산 알고리즘 간소화, 로봇 팔 구동 테스트, 환자의 상상 전략 개선 등 실전에 근접한 사용환경을 조성해 실제로 로봇 팔을 구동하고 의도한 방향으로 로봇 팔이 이동하는지 테스트를 진행했고, 네 가지 방향에 대한 의도를 읽어 정확하게 목표물에 도달하는 시연에 성공했다.
연구팀이 개발한 팔 동작 방향 상상 뇌 신호 분석기술은 향후 사지마비 환자를 비롯한 운동장애를 겪는 환자를 대상으로 로봇 팔을 제어할 수 있는 뇌-기계 인터페이스 정확도 향상, 효율성 개선 등에 이바지할 수 있을 것으로 기대된다.
연구책임자 정재승 교수는 "장애인마다 상이한 뇌 신호를 맞춤형으로 분석해 장기간 훈련을 받지 않더라도 로봇 팔을 제어할 수 있는 기술은 혁신적인 결과이며, 이번 기술은 향후 의수를 대신할 로봇팔을 상용화하는 데에도 크게 기여할 것으로 기대된다ˮ고 말했다.
2022.10.24 조회수 10665
상상만으로 원하는 방향으로 사용가능한 로봇 팔 뇌-기계 인터페이스 개발
우리 대학 뇌인지과학과 정재승 교수 연구팀이 인간의 뇌 신호를 해독해 장기간의 훈련 없이 생각만으로 로봇 팔을 원하는 방향으로 제어하는 뇌-기계 인터페이스 시스템을 개발했다고 24일 밝혔다.
서울의대 신경외과 정천기 교수 연구팀과 공동연구로 진행된 이번 연구에서 정 교수 연구팀은 뇌전증 환자를 대상으로 팔을 뻗는 동작을 상상할 때 관측되는 대뇌 피질 신호를 분석해 환자가 의도한 팔 움직임을 예측하는 팔 동작 방향 상상 뇌 신호 디코딩 기술을 개발했다. 이러한 디코딩 기술은 실제 움직임이나 복잡한 운동 상상이 필요하지 않기 때문에 운동장애를 겪는 환자가 장기간 훈련 없이도 자연스럽고 쉽게 로봇 팔을 제어할 수 있어 앞으로 다양한 의료기기에 폭넓게 적용되리라 기대된다.
바이오및뇌공학과 장상진 박사과정이 제1 저자로 참여한 이번 연구는 뇌공학 분야의 세계적인 국제 학술지 `저널 오브 뉴럴 엔지니어링 (Journal of Neural Engineering)' 9월 19권 5호에 출판됐다. (논문명 : Decoding trajectories of imagined hand movement using electrocorticograms for brain-machine interface).
뇌-기계 인터페이스는 인간이 생각만으로 기계를 제어할 수 있는 기술로, 팔을 움직이는 데 장애가 있거나 절단된 환자가 로봇 팔을 제어해 일상에 필요한 팔 동작을 회복할 수 있는 보조기술로 크게 주목받고 있다.
로봇 팔 제어를 위한 뇌-기계 인터페이스를 구현하기 위해서는 인간이 팔을 움직일 때 뇌에서 발생하는 전기신호를 측정하고 기계학습 등 다양한 인공지능 분석기법으로 뇌 신호를 해독해 의도한 움직임을 뇌 신호로부터 예측할 수 있는 디코딩 기술이 필요하다.
그러나 상지 절단 등으로 운동장애를 겪는 환자는 팔을 실제로 움직이기 어려우므로, 상상만으로 로봇 팔의 방향을 지시할 수 있는 인터페이스가 절실히 요구된다. 뇌 신호 디코딩 기술은 팔의 실제 움직임이 아닌 상상 뇌 신호에서 어느 방향으로 사용자가 상상했는지 예측할 수 있어야 하는데, 상상 뇌 신호는 실제 움직임 뇌 신호보다 신호대잡음비(signal to noise ratio)가 현저히 낮아 팔의 정확한 방향을 예측하기 어려운 문제점이 오랫동안 난제였다. 이러한 문제점을 극복하고자 기존 연구들에서는 팔을 움직이기 위해 신호대잡음비가 더 높은 다른 신체 동작을 상상하는 방법을 시도했으나, 의도하고자 하는 팔 뻗기와 인지적 동작 간의 부자연스러운 괴리로 인해 사용자가 장기간 훈련해야 하는 불편함을 초래했다.
따라서 팔을 뻗는 상상을 할 때 어느 방향으로 뻗었는지 예측하는 디코딩 기술은 정확도가 떨어지고 환자가 사용법을 습득하기 어려운 문제점이 있다. 이 문제가 오랫동안 뇌-기계 인터페이스 분야에서 해결해야 할 난제였다.
연구팀은 문제 해결을 위해 사용자의 자연스러운 팔 동작 상상을 공간해상도가 우수한 대뇌 피질 신호(electrocorticogram)로 측정하고, 변분 베이지안 최소제곱(variational Bayesian least square) 기계학습 기법을 활용해 직접 측정이 어려운 팔 동작의 방향 정보를 계산할 수 있는 디코딩 기술을 처음으로 개발했다.
연구팀의 팔 동작 상상 신호 분석기술은 운동피질을 비롯한 특정 대뇌 영역에 국한되지 않아, 사용자마다 상이할 수 있는 상상 신호와 대뇌 영역 특성을 맞춤형으로 학습해 최적의 계산모델 파라미터 결괏값을 출력할 수 있다.
연구팀은 대뇌 피질 신호 디코딩을 통해 환자가 상상한 팔 뻗기 방향을 최대 80% 이상의 정확도로 예측할 수 있음을 확인했다.
나아가 계산모델을 분석함으로써 방향 상상에 중요한 대뇌의 시공간적 특성을 밝혔고, 상상하는 인지적 과정이 팔을 실제로 뻗는 과정에 근접할수록 방향 예측정확도가 상당히 더 높아질 수 있음을 연구팀은 확인했다.
연구팀은 지난 2월 인공지능과 유전자 알고리즘 기반 고 정확도 로봇 팔 제어 뇌-기계 인터페이스 선행 연구 결과를 세계적인 학술지 `어플라이드 소프트 컴퓨팅(Applied soft computing)'에 발표한 바 있다. 이번 후속 연구는 그에 기반해 계산 알고리즘 간소화, 로봇 팔 구동 테스트, 환자의 상상 전략 개선 등 실전에 근접한 사용환경을 조성해 실제로 로봇 팔을 구동하고 의도한 방향으로 로봇 팔이 이동하는지 테스트를 진행했고, 네 가지 방향에 대한 의도를 읽어 정확하게 목표물에 도달하는 시연에 성공했다.
연구팀이 개발한 팔 동작 방향 상상 뇌 신호 분석기술은 향후 사지마비 환자를 비롯한 운동장애를 겪는 환자를 대상으로 로봇 팔을 제어할 수 있는 뇌-기계 인터페이스 정확도 향상, 효율성 개선 등에 이바지할 수 있을 것으로 기대된다.
연구책임자 정재승 교수는 "장애인마다 상이한 뇌 신호를 맞춤형으로 분석해 장기간 훈련을 받지 않더라도 로봇 팔을 제어할 수 있는 기술은 혁신적인 결과이며, 이번 기술은 향후 의수를 대신할 로봇팔을 상용화하는 데에도 크게 기여할 것으로 기대된다ˮ고 말했다.
2022.10.24 조회수 10665 -
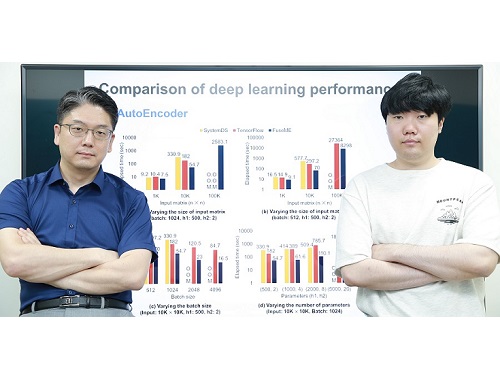 초대규모 인공지능 모델 처리하기 위한 세계 최고 성능의 기계학습 시스템 기술 개발
우리 연구진이 오늘날 인공지능 딥러닝 모델들을 처리하기 위해 필수적으로 사용되는 기계학습 시스템을 세계 최고 수준의 성능으로 끌어올렸다.
우리 대학 전산학부 김민수 교수 연구팀이 딥러닝 모델을 비롯한 기계학습 모델을 학습하거나 추론하기 위해 필수적으로 사용되는 기계학습 시스템의 성능을 대폭 높일 수 있는 세계 최고 수준의 행렬 연산자 융합 기술(일명 FuseME)을 개발했다고 20일 밝혔다.
오늘날 광범위한 산업 분야들에서 사용되고 있는 딥러닝 모델들은 대부분 구글 텐서플로우(TensorFlow)나 IBM 시스템DS와 같은 기계학습 시스템을 이용해 처리되는데, 딥러닝 모델의 규모가 점점 더 커지고, 그 모델에 사용되는 데이터의 규모가 점점 더 커짐에 따라, 이들을 원활히 처리할 수 있는 고성능 기계학습 시스템에 대한 중요성도 점점 더 커지고 있다.
일반적으로 딥러닝 모델은 행렬 곱셈, 행렬 합, 행렬 집계 등의 많은 행렬 연산자들로 구성된 방향성 비순환 그래프(Directed Acyclic Graph; 이하 DAG) 형태의 질의 계획으로 표현돼 기계학습 시스템에 의해 처리된다. 모델과 데이터의 규모가 클 때는 일반적으로 DAG 질의 계획은 수많은 컴퓨터로 구성된 클러스터에서 처리된다. 클러스터의 사양에 비해 모델과 데이터의 규모가 커지면 처리에 실패하거나 시간이 오래 걸리는 근본적인 문제가 있었다.
지금까지는 더 큰 규모의 모델이나 데이터를 처리하기 위해 단순히 컴퓨터 클러스터의 규모를 증가시키는 방식을 주로 사용했다. 그러나, 김 교수팀은 DAG 질의 계획을 구성하는 각 행렬 연산자로부터 생성되는 일종의 `중간 데이터'를 메모리에 저장하거나 네트워크 통신을 통해 다른 컴퓨터로 전송하는 것이 문제의 원인임에 착안해, 중간 데이터를 저장하지 않거나 다른 컴퓨터로 전송하지 않도록 여러 행렬 연산자들을 하나의 연산자로 융합(fusion)하는 세계 최고 성능의 융합 기술인 FuseME(Fused Matrix Engine)을 개발해 문제를 해결했다.
현재까지의 기계학습 시스템들은 낮은 수준의 연산자 융합 기술만을 사용하고 있었다. 가장 복잡한 행렬 연산자인 행렬 곱을 제외한 나머지 연산자들만 융합해 성능이 별로 개선되지 않거나, 전체 DAG 질의 계획을 단순히 하나의 연산자처럼 실행해 메모리 부족으로 처리에 실패하는 한계를 지니고 있었다.
김 교수팀이 개발한 FuseME 기술은 수십 개 이상의 행렬 연산자들로 구성되는 DAG 질의 계획에서 어떤 연산자들끼리 서로 융합하는 것이 더 우수한 성능을 내는지 비용 기반으로 판별해 그룹으로 묶고, 클러스터의 사양, 네트워크 통신 속도, 입력 데이터 크기 등을 모두 고려해 각 융합 연산자 그룹을 메모리 부족으로 처리에 실패하지 않으면서 이론적으로 최적 성능을 낼 수 있는 CFO(Cuboid-based Fused Operator)라 불리는 연산자로 융합함으로써 한계를 극복했다. 이때, 행렬 곱 연산자까지 포함해 연산자들을 융합하는 것이 핵심이다.
김민수 교수 연구팀은 FuseME 기술을 종래 최고 기술로 알려진 구글의 텐서플로우나 IBM의 시스템DS와 비교 평가한 결과, 딥러닝 모델의 처리 속도를 최대 8.8배 향상하고, 텐서플로우나 시스템DS가 처리할 수 없는 훨씬 더 큰 규모의 모델 및 데이터를 처리하는 데 성공함을 보였다. 또한, FuseME의 CFO 융합 연산자는 종래의 최고 수준 융합 연산자와 비교해 처리 속도를 최대 238배 향상시키고, 네트워크 통신 비용을 최대 64배 감소시키는 사실을 확인했다.
김 교수팀은 이미 지난 2019년에 초대규모 행렬 곱 연산에 대해 종래 세계 최고 기술이었던 IBM 시스템ML과 슈퍼컴퓨팅 분야의 스칼라팩(ScaLAPACK) 대비 성능과 처리 규모를 훨씬 향상시킨 DistME라는 기술을 개발해 데이터베이스 분야 최고 국제학술대회 중 하나인 ACM SIGMOD에서 발표한 바 있다. 이번 FuseME 기술은 연산자 융합이 가능하도록 DistME를 한층 더 발전시킨 것으로, 해당 분야를 세계 최고 수준의 기술력을 바탕으로 지속적으로 선도하는 쾌거를 보여준 것이다.
교신저자로 참여한 김민수 교수는 "연구팀이 개발한 새로운 기술은 딥러닝 등 기계학습 모델의 처리 규모와 성능을 획기적으로 높일 수 있어 산업적 측면에서 파급 효과가 매우 클 것으로 기대한다ˮ 라고 말했다.
이번 연구에는 김 교수의 제자이자 현재 GraphAI(그래파이) 스타트업의 공동 창업자인 한동형 박사가 제1 저자로, 김 교수가 교신저자로 참여했으며 지난 16일 미국 필라델피아에서 열린 데이터베이스 분야 최고 국제학술대회 중 하나인 ACM SIGMOD에서 발표됐다. (논문명 : FuseME: Distributed Matrix Computation Engine based on Cuboid-based Fused Operator and Plan Generation).
한편, 이번 연구는 한국연구재단 선도연구센터 사업 및 중견연구자 지원사업, 과기정통부 IITP SW스타랩 사업의 지원을 받아 수행됐다.
2022.06.20 조회수 8842
초대규모 인공지능 모델 처리하기 위한 세계 최고 성능의 기계학습 시스템 기술 개발
우리 연구진이 오늘날 인공지능 딥러닝 모델들을 처리하기 위해 필수적으로 사용되는 기계학습 시스템을 세계 최고 수준의 성능으로 끌어올렸다.
우리 대학 전산학부 김민수 교수 연구팀이 딥러닝 모델을 비롯한 기계학습 모델을 학습하거나 추론하기 위해 필수적으로 사용되는 기계학습 시스템의 성능을 대폭 높일 수 있는 세계 최고 수준의 행렬 연산자 융합 기술(일명 FuseME)을 개발했다고 20일 밝혔다.
오늘날 광범위한 산업 분야들에서 사용되고 있는 딥러닝 모델들은 대부분 구글 텐서플로우(TensorFlow)나 IBM 시스템DS와 같은 기계학습 시스템을 이용해 처리되는데, 딥러닝 모델의 규모가 점점 더 커지고, 그 모델에 사용되는 데이터의 규모가 점점 더 커짐에 따라, 이들을 원활히 처리할 수 있는 고성능 기계학습 시스템에 대한 중요성도 점점 더 커지고 있다.
일반적으로 딥러닝 모델은 행렬 곱셈, 행렬 합, 행렬 집계 등의 많은 행렬 연산자들로 구성된 방향성 비순환 그래프(Directed Acyclic Graph; 이하 DAG) 형태의 질의 계획으로 표현돼 기계학습 시스템에 의해 처리된다. 모델과 데이터의 규모가 클 때는 일반적으로 DAG 질의 계획은 수많은 컴퓨터로 구성된 클러스터에서 처리된다. 클러스터의 사양에 비해 모델과 데이터의 규모가 커지면 처리에 실패하거나 시간이 오래 걸리는 근본적인 문제가 있었다.
지금까지는 더 큰 규모의 모델이나 데이터를 처리하기 위해 단순히 컴퓨터 클러스터의 규모를 증가시키는 방식을 주로 사용했다. 그러나, 김 교수팀은 DAG 질의 계획을 구성하는 각 행렬 연산자로부터 생성되는 일종의 `중간 데이터'를 메모리에 저장하거나 네트워크 통신을 통해 다른 컴퓨터로 전송하는 것이 문제의 원인임에 착안해, 중간 데이터를 저장하지 않거나 다른 컴퓨터로 전송하지 않도록 여러 행렬 연산자들을 하나의 연산자로 융합(fusion)하는 세계 최고 성능의 융합 기술인 FuseME(Fused Matrix Engine)을 개발해 문제를 해결했다.
현재까지의 기계학습 시스템들은 낮은 수준의 연산자 융합 기술만을 사용하고 있었다. 가장 복잡한 행렬 연산자인 행렬 곱을 제외한 나머지 연산자들만 융합해 성능이 별로 개선되지 않거나, 전체 DAG 질의 계획을 단순히 하나의 연산자처럼 실행해 메모리 부족으로 처리에 실패하는 한계를 지니고 있었다.
김 교수팀이 개발한 FuseME 기술은 수십 개 이상의 행렬 연산자들로 구성되는 DAG 질의 계획에서 어떤 연산자들끼리 서로 융합하는 것이 더 우수한 성능을 내는지 비용 기반으로 판별해 그룹으로 묶고, 클러스터의 사양, 네트워크 통신 속도, 입력 데이터 크기 등을 모두 고려해 각 융합 연산자 그룹을 메모리 부족으로 처리에 실패하지 않으면서 이론적으로 최적 성능을 낼 수 있는 CFO(Cuboid-based Fused Operator)라 불리는 연산자로 융합함으로써 한계를 극복했다. 이때, 행렬 곱 연산자까지 포함해 연산자들을 융합하는 것이 핵심이다.
김민수 교수 연구팀은 FuseME 기술을 종래 최고 기술로 알려진 구글의 텐서플로우나 IBM의 시스템DS와 비교 평가한 결과, 딥러닝 모델의 처리 속도를 최대 8.8배 향상하고, 텐서플로우나 시스템DS가 처리할 수 없는 훨씬 더 큰 규모의 모델 및 데이터를 처리하는 데 성공함을 보였다. 또한, FuseME의 CFO 융합 연산자는 종래의 최고 수준 융합 연산자와 비교해 처리 속도를 최대 238배 향상시키고, 네트워크 통신 비용을 최대 64배 감소시키는 사실을 확인했다.
김 교수팀은 이미 지난 2019년에 초대규모 행렬 곱 연산에 대해 종래 세계 최고 기술이었던 IBM 시스템ML과 슈퍼컴퓨팅 분야의 스칼라팩(ScaLAPACK) 대비 성능과 처리 규모를 훨씬 향상시킨 DistME라는 기술을 개발해 데이터베이스 분야 최고 국제학술대회 중 하나인 ACM SIGMOD에서 발표한 바 있다. 이번 FuseME 기술은 연산자 융합이 가능하도록 DistME를 한층 더 발전시킨 것으로, 해당 분야를 세계 최고 수준의 기술력을 바탕으로 지속적으로 선도하는 쾌거를 보여준 것이다.
교신저자로 참여한 김민수 교수는 "연구팀이 개발한 새로운 기술은 딥러닝 등 기계학습 모델의 처리 규모와 성능을 획기적으로 높일 수 있어 산업적 측면에서 파급 효과가 매우 클 것으로 기대한다ˮ 라고 말했다.
이번 연구에는 김 교수의 제자이자 현재 GraphAI(그래파이) 스타트업의 공동 창업자인 한동형 박사가 제1 저자로, 김 교수가 교신저자로 참여했으며 지난 16일 미국 필라델피아에서 열린 데이터베이스 분야 최고 국제학술대회 중 하나인 ACM SIGMOD에서 발표됐다. (논문명 : FuseME: Distributed Matrix Computation Engine based on Cuboid-based Fused Operator and Plan Generation).
한편, 이번 연구는 한국연구재단 선도연구센터 사업 및 중견연구자 지원사업, 과기정통부 IITP SW스타랩 사업의 지원을 받아 수행됐다.
2022.06.20 조회수 8842 -
 최초 머신러닝 기반 유전체 정렬 소프트웨어 개발
우리 대학 전기및전자공학부 한동수 교수 연구팀이 머신러닝(기계학습)에 기반한 *유전체 정렬 소프트웨어를 개발했다고 12일 밝혔다.
☞ 유전체(genome): 생명체가 가지고 있는 염기서열 정보의 총합이며, 유전자는 생물학적 특징을 발현하는 염기서열들을 지칭한다. 유전체를 한 권의 책이라고 비유하면 유전자는 공백을 제외한 모든 글자라고 비유할 수 있다.
차세대 염기서열 분석은 유전체 정보를 해독하는 방법으로 유전체를 무수히 많은 조각으로 잘라낸 후 각 조각을 참조 유전체(reference genome)에 기반해 조립하는 과정을 거친다. 조립된 유전체 정보는 암을 포함한 여러 질병의 예측과 맞춤형 치료, 백신 개발 등 다양한 분야에서 사용된다.
유전체 정렬 소프트웨어는 차세대 염기서열 분석 방법으로 생성한 유전체 조각 데이터를 온전한 유전체 정보로 조립하기 위해 사용되는 소프트웨어다. 유전체 정렬 작업에는 많은 연산이 들어가며, 속도를 높이고 비용을 낮추는 방법에 관한 관심이 계속해서 증가하고 있다. 머신러닝(기계학습) 기반의 인덱싱(색인) 기법(Learned-index)을 유전체 정렬 소프트웨어에 적용한 사례는 이번이 최초다.
전기및전자공학부 정영목 박사과정이 제1 저자로 참여한 이번 연구는 국제 학술지 `옥스포드 바이오인포메틱스(Oxford Bioinformatics)' 2022년 3월에 공개됐다. (논문명 : BWA-MEME: BWA-MEM emulated with a machine learning approach)
유전체 정렬 작업은 정렬해야 하는 유전체 조각의 양이 많고 참조 유전체의 길이도 길어 많은 연산량이 요구되는 작업이다. 또한, 유전체 정렬 소프트웨어에서 정렬 결과의 정확도에 따라 추후의 유전체 분석의 정확도가 영향을 받는다. 이러한 특성 때문에 유전체 정렬 소프트웨어는 높은 정확성을 유지하며 빠르게 연산하는 것이 중요하다.
일반적으로 유전체 분석에는 하버드 브로드 연구소(Broad Institute)에서 개발한 유전체 분석 도구 키트(Genome Analysis Tool Kit, 이하 GATK)를 이용한 데이터 처리 방법을 표준으로 사용한다. 이들 키트 중 BWA-MEM은 GATK에서 표준으로 채택한 유전체 정렬 소프트웨어이며, 2019년에 하버드 대학과 인텔(Intel)의 공동 연구로 BWA-MEM2가 개발됐다.
연구팀이 개발한 머신러닝 기반의 유전체 정렬 소프트웨어는 연산량을 대폭 줄이면서도 표준 유전체 정렬 소프트웨어 BWA-MEM2과 동일한 결과를 만들어 정확도를 유지했다. 사용한 머신러닝 기반의 인덱싱 기법은 주어진 데이터의 분포를 머신러닝 모델이 학습해, 데이터 분포에 최적화된 인덱싱을 찾는 방법론이다. 데이터에 적합하다고 생각되는 인덱싱 방법을 사람이 정하던 기존의 방법과 대비된다.
BWA-MEM과 BWA-MEM2에서 사용하는 인덱싱 기법(FM-index)은 유전자 조각의 위치를 찾기 위해 유전자 조각 길이만큼의 연산이 필요하지만, 연구팀이 제안한 알고리즘은 머신러닝 기반의 인덱싱 기법(Learned-index)을 활용해, 유전자 조각 길이와 상관없이 적은 연산량으로도 유전자 조각의 위치를 찾을 수 있다. 연구팀이 제안한 인덱싱 기법은 기존 인덱싱 기법과 비교해 3.4배 정도 가속화됐고, 이로 인해 유전체 정렬 소프트웨어는 1.4 배 가속화됐다.
연구팀이 이번 연구에서 개발한 유전체 정렬 소프트웨어는 오픈소스 (https://github.com/kaist-ina/BWA-MEME)로 공개돼 많은 분야에 사용될 것으로 기대되며, 유전체 분석에서 사용되는 다양한 소프트웨어를 머신러닝 기술로 가속화하는 연구들의 초석이 될 것으로 기대된다.
한동수 교수는 "이번 연구를 통해 기계학습 기술을 접목해 전장 유전체 빅데이터 분석을 기존 방식보다 빠르고 적은 비용으로 할 수 있다는 것을 보여줬으며, 앞으로 인공지능 기술을 활용해 전장 유전체 빅데이터 분석을 효율화, 고도화할 수 있을 것이라 기대된다ˮ고 말했다.
한편 이번 연구는 과학기술정보통신부의 재원으로 한국연구재단의 지원을 받아 데이터 스테이션 구축·운영 사업으로서 수행됐다.
2022.04.17 조회수 12141
최초 머신러닝 기반 유전체 정렬 소프트웨어 개발
우리 대학 전기및전자공학부 한동수 교수 연구팀이 머신러닝(기계학습)에 기반한 *유전체 정렬 소프트웨어를 개발했다고 12일 밝혔다.
☞ 유전체(genome): 생명체가 가지고 있는 염기서열 정보의 총합이며, 유전자는 생물학적 특징을 발현하는 염기서열들을 지칭한다. 유전체를 한 권의 책이라고 비유하면 유전자는 공백을 제외한 모든 글자라고 비유할 수 있다.
차세대 염기서열 분석은 유전체 정보를 해독하는 방법으로 유전체를 무수히 많은 조각으로 잘라낸 후 각 조각을 참조 유전체(reference genome)에 기반해 조립하는 과정을 거친다. 조립된 유전체 정보는 암을 포함한 여러 질병의 예측과 맞춤형 치료, 백신 개발 등 다양한 분야에서 사용된다.
유전체 정렬 소프트웨어는 차세대 염기서열 분석 방법으로 생성한 유전체 조각 데이터를 온전한 유전체 정보로 조립하기 위해 사용되는 소프트웨어다. 유전체 정렬 작업에는 많은 연산이 들어가며, 속도를 높이고 비용을 낮추는 방법에 관한 관심이 계속해서 증가하고 있다. 머신러닝(기계학습) 기반의 인덱싱(색인) 기법(Learned-index)을 유전체 정렬 소프트웨어에 적용한 사례는 이번이 최초다.
전기및전자공학부 정영목 박사과정이 제1 저자로 참여한 이번 연구는 국제 학술지 `옥스포드 바이오인포메틱스(Oxford Bioinformatics)' 2022년 3월에 공개됐다. (논문명 : BWA-MEME: BWA-MEM emulated with a machine learning approach)
유전체 정렬 작업은 정렬해야 하는 유전체 조각의 양이 많고 참조 유전체의 길이도 길어 많은 연산량이 요구되는 작업이다. 또한, 유전체 정렬 소프트웨어에서 정렬 결과의 정확도에 따라 추후의 유전체 분석의 정확도가 영향을 받는다. 이러한 특성 때문에 유전체 정렬 소프트웨어는 높은 정확성을 유지하며 빠르게 연산하는 것이 중요하다.
일반적으로 유전체 분석에는 하버드 브로드 연구소(Broad Institute)에서 개발한 유전체 분석 도구 키트(Genome Analysis Tool Kit, 이하 GATK)를 이용한 데이터 처리 방법을 표준으로 사용한다. 이들 키트 중 BWA-MEM은 GATK에서 표준으로 채택한 유전체 정렬 소프트웨어이며, 2019년에 하버드 대학과 인텔(Intel)의 공동 연구로 BWA-MEM2가 개발됐다.
연구팀이 개발한 머신러닝 기반의 유전체 정렬 소프트웨어는 연산량을 대폭 줄이면서도 표준 유전체 정렬 소프트웨어 BWA-MEM2과 동일한 결과를 만들어 정확도를 유지했다. 사용한 머신러닝 기반의 인덱싱 기법은 주어진 데이터의 분포를 머신러닝 모델이 학습해, 데이터 분포에 최적화된 인덱싱을 찾는 방법론이다. 데이터에 적합하다고 생각되는 인덱싱 방법을 사람이 정하던 기존의 방법과 대비된다.
BWA-MEM과 BWA-MEM2에서 사용하는 인덱싱 기법(FM-index)은 유전자 조각의 위치를 찾기 위해 유전자 조각 길이만큼의 연산이 필요하지만, 연구팀이 제안한 알고리즘은 머신러닝 기반의 인덱싱 기법(Learned-index)을 활용해, 유전자 조각 길이와 상관없이 적은 연산량으로도 유전자 조각의 위치를 찾을 수 있다. 연구팀이 제안한 인덱싱 기법은 기존 인덱싱 기법과 비교해 3.4배 정도 가속화됐고, 이로 인해 유전체 정렬 소프트웨어는 1.4 배 가속화됐다.
연구팀이 이번 연구에서 개발한 유전체 정렬 소프트웨어는 오픈소스 (https://github.com/kaist-ina/BWA-MEME)로 공개돼 많은 분야에 사용될 것으로 기대되며, 유전체 분석에서 사용되는 다양한 소프트웨어를 머신러닝 기술로 가속화하는 연구들의 초석이 될 것으로 기대된다.
한동수 교수는 "이번 연구를 통해 기계학습 기술을 접목해 전장 유전체 빅데이터 분석을 기존 방식보다 빠르고 적은 비용으로 할 수 있다는 것을 보여줬으며, 앞으로 인공지능 기술을 활용해 전장 유전체 빅데이터 분석을 효율화, 고도화할 수 있을 것이라 기대된다ˮ고 말했다.
한편 이번 연구는 과학기술정보통신부의 재원으로 한국연구재단의 지원을 받아 데이터 스테이션 구축·운영 사업으로서 수행됐다.
2022.04.17 조회수 12141 -
 세계 최초 그래프 기반 인공지능 추론 가능한 SSD 개발
우리 대학 전기및전자공학부 정명수 교수 연구팀(컴퓨터 아키텍처 및 메모리 시스템 연구실)이 세계 최초로 그래프 기계학습 추론의 그래프처리, 그래프 샘플링 그리고 신경망 가속을 스토리지/SSD 장치 근처에서 수행하는 `전체론적 그래프 기반 신경망 기계학습 기술(이하 홀리스틱 GNN)'을 개발하는데 성공했다고 10일 밝혔다.
연구팀은 자체 제작한 프로그래밍 가능 반도체(FPGA)를 동반한 새로운 형태의 계산형 스토리지/SSD 시스템에 기계학습 전용 신경망 가속 하드웨어와 그래프 전용 처리 컨트롤러/소프트웨어를 시제작했다. 이는 이상적 상황에서 최신 고성능 엔비디아 GPU를 이용한 기계학습 가속 컴퓨팅 대비 7배의 속도 향상과 33배의 에너지 절약을 가져올 수 있다고 밝혔다.
그래프 자료구조가 적용된 새로운 기계학습 모델은 기존 신경망 기반 기계학습 기법들과 달리, 데이터 사이의 연관 관계를 표현할 수 있어 페이스북, 구글, 링크드인, 우버 등, 대규모 소셜 네트워크 서비스(SNS)부터, 내비게이션, 신약개발 등 광범위한 분야와 응용에서 사용된다. 예를 들면 그래프 구조로 저장된 사용자 네트워크를 분석하는 경우 일반적인 기계학습으로는 불가능했던 현실적인 상품 및 아이템 추천, 사람이 추론한 것 같은 친구 추천 등이 가능하다. 이러한 신흥 그래프 기반 신경망 기계학습은 그간 GPU와 같은 일반 기계학습의 가속 시스템을 재이용해 연산 되어왔는데, 이는 그래프 데이터를 스토리지로부터 메모리로 적재하고 샘플링하는 등의 데이터 전처리 과정에서 심각한 성능 병목현상과 함께 장치 메모리 부족 현상으로 실제 시스템 적용에 한계를 보여 왔다.
정명수 교수 연구팀이 개발한 홀리스틱 GNN 기술은 그래프 데이터 자체가 저장된 스토리지 근처에서 사용자 요청에 따른 추론의 모든 과정을 직접 가속한다. 구체적으로는 프로그래밍 가능한 반도체를 스토리지 근처에 배치한 새로운 계산형 스토리지(Computational SSD) 구조를 활용해 대규모 그래프 데이터의 이동을 제거하고 데이터 근처(Near Storage)에서 그래프처리 및 그래프 샘플링 등을 가속해 그래프 기계학습 전처리 과정에서의 병목현상을 해결했다.
일반적인 계산형 스토리지는 장치 내 고정된 펌웨어와 하드웨어 구성을 통해서 데이터를 처리해야 했기 때문에 그 사용에 제한이 있었다. 그래프처리 및 그래프샘플링 외에도, 연구팀의 홀리스틱 GNN 기술은 인공지능 추론 가속에 필요한 다양한 하드웨어 구조, 그리고 소프트웨어를 후원할 수 있도록 다수 그래프 기계학습 모델을 프로그래밍할 수 있는 장치수준의 소프트웨어와 사용자가 자유롭게 변경할 수 있는 신경망 가속 하드웨어 프레임워크 구조를 제공한다.
연구팀은 홀리스틱 GNN 기술의 실효성을 검증하기 위해 계산형 스토리지의 프로토타입을 자체 제작한 후, 그 위에 개발된 그래프 기계학습용 하드웨어 *RTL과 소프트웨어 프레임워크를 구현해 탑재했다. 그래프 기계학습 추론 성능을 제작된 계산형 스토리지 가속기 프로토타입과 최신 고성능 엔비디아 GPU 가속 시스템(RTX 3090)에서 평가한 결과, 홀리스틱 GNN 기술이 이상적인 상황에서 기존 엔비디아 GPU를 이용해 그래프 기계학습을 가속하는 시스템의 경우에 비해 평균 7배 빠르고 33배 에너지를 감소시킴을 확인했다. 특히, 그래프 규모가 점차 커질수록 전처리 병목현상 완화 효과가 증가해 기존 GPU 대비 최대 201배 향상된 속도와 453배 에너지를 감소할 수 있었다.
☞ RTL (Registor Transistor Logic): 저항과 트랜지스터로 구성한 컴퓨터에 사용되는 회로
정명수 교수는 "대규모 그래프에 대해 스토리지 근처에서 그래프 기계학습을 고속으로 추론할 뿐만 아니라 에너지 절약에 최적화된 계산형 스토리지 가속 시스템을 확보했다ˮ며 "기존 고성능 가속 시스템을 대체해 초대형 추천시스템, 교통 예측 시스템, 신약 개발 등의 광범위한 실제 응용에 적용될 수 있을 것ˮ이라고 말했다.
한편 이번 연구는 미국 산호세에서 오는 2월에 열릴 스토리지 시스템 분야 최우수 학술대회인 `유즈닉스 패스트(USENIX Conference on File and Storage Technologies, FAST), 2022'에 관련 논문(논문명: Hardware/Software Co-Programmable Framework for Computational SSDs to Accelerate Deep Learning Service on Large-Scale Graphs)으로 발표될 예정이다.
해당 연구는 삼성미래기술육성사업 지원을 받아 진행됐고 자세한 내용은 연구실 웹사이트(http://camelab.org)에서 확인할 수 있다.
2022.01.10 조회수 11340
세계 최초 그래프 기반 인공지능 추론 가능한 SSD 개발
우리 대학 전기및전자공학부 정명수 교수 연구팀(컴퓨터 아키텍처 및 메모리 시스템 연구실)이 세계 최초로 그래프 기계학습 추론의 그래프처리, 그래프 샘플링 그리고 신경망 가속을 스토리지/SSD 장치 근처에서 수행하는 `전체론적 그래프 기반 신경망 기계학습 기술(이하 홀리스틱 GNN)'을 개발하는데 성공했다고 10일 밝혔다.
연구팀은 자체 제작한 프로그래밍 가능 반도체(FPGA)를 동반한 새로운 형태의 계산형 스토리지/SSD 시스템에 기계학습 전용 신경망 가속 하드웨어와 그래프 전용 처리 컨트롤러/소프트웨어를 시제작했다. 이는 이상적 상황에서 최신 고성능 엔비디아 GPU를 이용한 기계학습 가속 컴퓨팅 대비 7배의 속도 향상과 33배의 에너지 절약을 가져올 수 있다고 밝혔다.
그래프 자료구조가 적용된 새로운 기계학습 모델은 기존 신경망 기반 기계학습 기법들과 달리, 데이터 사이의 연관 관계를 표현할 수 있어 페이스북, 구글, 링크드인, 우버 등, 대규모 소셜 네트워크 서비스(SNS)부터, 내비게이션, 신약개발 등 광범위한 분야와 응용에서 사용된다. 예를 들면 그래프 구조로 저장된 사용자 네트워크를 분석하는 경우 일반적인 기계학습으로는 불가능했던 현실적인 상품 및 아이템 추천, 사람이 추론한 것 같은 친구 추천 등이 가능하다. 이러한 신흥 그래프 기반 신경망 기계학습은 그간 GPU와 같은 일반 기계학습의 가속 시스템을 재이용해 연산 되어왔는데, 이는 그래프 데이터를 스토리지로부터 메모리로 적재하고 샘플링하는 등의 데이터 전처리 과정에서 심각한 성능 병목현상과 함께 장치 메모리 부족 현상으로 실제 시스템 적용에 한계를 보여 왔다.
정명수 교수 연구팀이 개발한 홀리스틱 GNN 기술은 그래프 데이터 자체가 저장된 스토리지 근처에서 사용자 요청에 따른 추론의 모든 과정을 직접 가속한다. 구체적으로는 프로그래밍 가능한 반도체를 스토리지 근처에 배치한 새로운 계산형 스토리지(Computational SSD) 구조를 활용해 대규모 그래프 데이터의 이동을 제거하고 데이터 근처(Near Storage)에서 그래프처리 및 그래프 샘플링 등을 가속해 그래프 기계학습 전처리 과정에서의 병목현상을 해결했다.
일반적인 계산형 스토리지는 장치 내 고정된 펌웨어와 하드웨어 구성을 통해서 데이터를 처리해야 했기 때문에 그 사용에 제한이 있었다. 그래프처리 및 그래프샘플링 외에도, 연구팀의 홀리스틱 GNN 기술은 인공지능 추론 가속에 필요한 다양한 하드웨어 구조, 그리고 소프트웨어를 후원할 수 있도록 다수 그래프 기계학습 모델을 프로그래밍할 수 있는 장치수준의 소프트웨어와 사용자가 자유롭게 변경할 수 있는 신경망 가속 하드웨어 프레임워크 구조를 제공한다.
연구팀은 홀리스틱 GNN 기술의 실효성을 검증하기 위해 계산형 스토리지의 프로토타입을 자체 제작한 후, 그 위에 개발된 그래프 기계학습용 하드웨어 *RTL과 소프트웨어 프레임워크를 구현해 탑재했다. 그래프 기계학습 추론 성능을 제작된 계산형 스토리지 가속기 프로토타입과 최신 고성능 엔비디아 GPU 가속 시스템(RTX 3090)에서 평가한 결과, 홀리스틱 GNN 기술이 이상적인 상황에서 기존 엔비디아 GPU를 이용해 그래프 기계학습을 가속하는 시스템의 경우에 비해 평균 7배 빠르고 33배 에너지를 감소시킴을 확인했다. 특히, 그래프 규모가 점차 커질수록 전처리 병목현상 완화 효과가 증가해 기존 GPU 대비 최대 201배 향상된 속도와 453배 에너지를 감소할 수 있었다.
☞ RTL (Registor Transistor Logic): 저항과 트랜지스터로 구성한 컴퓨터에 사용되는 회로
정명수 교수는 "대규모 그래프에 대해 스토리지 근처에서 그래프 기계학습을 고속으로 추론할 뿐만 아니라 에너지 절약에 최적화된 계산형 스토리지 가속 시스템을 확보했다ˮ며 "기존 고성능 가속 시스템을 대체해 초대형 추천시스템, 교통 예측 시스템, 신약 개발 등의 광범위한 실제 응용에 적용될 수 있을 것ˮ이라고 말했다.
한편 이번 연구는 미국 산호세에서 오는 2월에 열릴 스토리지 시스템 분야 최우수 학술대회인 `유즈닉스 패스트(USENIX Conference on File and Storage Technologies, FAST), 2022'에 관련 논문(논문명: Hardware/Software Co-Programmable Framework for Computational SSDs to Accelerate Deep Learning Service on Large-Scale Graphs)으로 발표될 예정이다.
해당 연구는 삼성미래기술육성사업 지원을 받아 진행됐고 자세한 내용은 연구실 웹사이트(http://camelab.org)에서 확인할 수 있다.
2022.01.10 조회수 11340 -
 기존 인공지능 기술을 뛰어넘는 양자 인공지능 알고리즘 개발
우리 대학 전기및전자공학부 및 AI 양자컴퓨팅 IT 인력양성연구센터장 이준구 교수 연구팀이 독일 및 남아공 연구팀과의 협력 연구를 통해 비선형 양자 기계학습 인공지능 알고리즘을 개발했다고 7일 밝혔다.
양자 인공지능은 양자컴퓨터의 발전과 함께 현재의 인공지능을 앞설 것으로 크게 기대되고 있으나 연산 방법이 전혀 달라 새로운 양자 알고리즘의 개발이 절실하다. 특히 양자컴퓨터는 본질적으로 일차방정식을 잘 푸는 선형적 성질을 가지고 있어 복잡한 데이터를 다루는 비선형적 기계학습에 어려움이 존재했다. 하지만 이번 연구를 통해 비선형 커널이 고안되어 복잡한 데이터에 대한 양자 기계학습이 가능하게 됐다. 특히 이준구 교수팀이 개발한 양자 지도학습 알고리즘은 학습에 있어 매우 적은 계산량으로 연산이 가능하다. 따라서 대규모 계산량이 필요한 현재의 인공지능 기술을 추월할 가능성을 제시한 것으로 평가를 받고 있다.
이준구 교수팀은 학습데이터와 테스트데이터를 양자 정보로 생성한 후 양자 정보의 병렬연산을 가능하게 하는 양자포킹 기술과 간단한 양자 측정기술을 조합해 양자 데이터 간의 유사성을 효율적으로 계산하는 비선형 커널 기반의 지도학습을 구현하는 양자 알고리즘 체계를 만들었다. 이후 IBM 클라우드 서비스를 통해 실제 양자컴퓨터에서 양자 지도학습을 실제 시연하는 데 성공했다.
KAIST 박경덕 연구교수가 공동 제1 저자로 참여한 이번 연구결과는 국제 학술지 네이처 자매지인 `npj Quantum Information' 誌 2020년 5월 6권에 게재됐다. (논문명: Quantum classifier with tailored quantum kernel).
기계학습에 있어 중요한 문제 중 하나는 주어진 데이터의 특징(feature)을 구분해 분류하는 것이다. 간단한 예로 동물 이미지 학습데이터에서 입, 귀 등의 특징을 바탕으로 분류하기 위한 결정 경계(decision boundary)를 학습하고 새로운 이미지가 입력되었을 때 개 또는 고양이로 분류하는 작업을 생각해볼 수 있다. 데이터의 특징들이 잘 나타나는 경우에는 선형적 결정 경계만으로 분류할 수 있다. 그러나 입과 귀 모양의 특징으로만 개와 고양이를 분류하기 쉽지 않다면 새로운 결정 경계를 찾기 위해 특징에 관한 정보 공간의 차원을 확장해야 하는데 이러한 과정에서 비선형 커널 기술이 필요하다.
양자컴퓨팅은 고전 컴퓨팅과는 달리 큐비트(quantum bit, 양자컴퓨팅 정보처리의 기본 단위)의 개수에 따라 정보 공간의 차원이 기하급수적으로 증가하기 때문에 이론적으로 고차원 정보처리에 있어 기하급수적으로 뛰어난 성능을 낼 수 있다.
연구팀은 이러한 양자컴퓨팅의 장점을 활용해 데이터 특징 대비 기하급수적인 계산 효율성을 달성하는 양자 기계학습 알고리즘을 개발했다. 이 교수 연구팀이 개발한 이 알고리즘은 저차원 입력 공간에 존재하는 데이터들을 큐비트로 표현되는 고차원 데이터 특징 공간(feature space)으로 옮긴 후, 양자화된 모든 학습데이터와 테스트데이터 간의 커널 함수를 양자 중첩을 활용해 동시에 계산하고 테스트데이터의 분류를 효율적으로 결정한다. 이때 사용되는 양자 회로의 계산 복잡도는 학습 데이터양에 대해서는 선형적으로 증가하나, 데이터 특징 개수에 대해서는 불과 로그(log)함수로 매우 천천히 증가하는 장점이 있다.
연구팀은 이와 함께 양자 회로의 체계적 설계를 통해 다양한 양자 커널 구현이 가능함을 이론적으로 증명했다. 커널 기반 기계학습에서는 주어진 입력 데이터에 따라 최적 커널이 달라질 수 있으므로, 다양한 양자 커널을 효율적으로 구현할 수 있게 된 점은 양자 커널 기반 기계학습의 실제 응용에 있어 매우 중요한 성과다.
연구팀은 IBM이 클라우드 서비스로 제공하는 다섯 개의 큐비트로 구성된 초전도 기반 양자 컴퓨터에서 이번에 개발에 성공한 양자 기계학습 알고리즘을 실험적으로 구현해 양자 커널 기반 기계학습의 성능을 실제 시연을 통해 이를 입증하는 데 성공했다.
이 연구에 참여한 박경덕 연구교수는 "연구팀이 개발한 커널 기반 양자 기계학습 알고리즘은 수년 안에 상용화될 것으로 예측되는 수백 큐비트의 NISQ(Noisy Intermediate-Scale Quantum) 컴퓨팅의 시대가 되면 기존의 고전 커널 기반 지도학습을 뛰어넘을 것ˮ이라면서 "복잡한 비선형 데이터의 패턴 인식 등을 위한 양자 기계학습 알고리즘으로 활발히 사용될 것ˮ이라고 말했다.
한편 이번 연구는 각각 한국연구재단의 창의 도전 연구기반 지원 사업과 한국연구재단의 한-아프리카 협력기반 조성 사업, 정보통신기획평가원의 정보통신기술인력 양성사업(ITRC)의 지원을 받아 수행됐다.
관련 논문: https://www.nature.com/articles/s41534-020-0272-6
2020.07.07 조회수 24229
기존 인공지능 기술을 뛰어넘는 양자 인공지능 알고리즘 개발
우리 대학 전기및전자공학부 및 AI 양자컴퓨팅 IT 인력양성연구센터장 이준구 교수 연구팀이 독일 및 남아공 연구팀과의 협력 연구를 통해 비선형 양자 기계학습 인공지능 알고리즘을 개발했다고 7일 밝혔다.
양자 인공지능은 양자컴퓨터의 발전과 함께 현재의 인공지능을 앞설 것으로 크게 기대되고 있으나 연산 방법이 전혀 달라 새로운 양자 알고리즘의 개발이 절실하다. 특히 양자컴퓨터는 본질적으로 일차방정식을 잘 푸는 선형적 성질을 가지고 있어 복잡한 데이터를 다루는 비선형적 기계학습에 어려움이 존재했다. 하지만 이번 연구를 통해 비선형 커널이 고안되어 복잡한 데이터에 대한 양자 기계학습이 가능하게 됐다. 특히 이준구 교수팀이 개발한 양자 지도학습 알고리즘은 학습에 있어 매우 적은 계산량으로 연산이 가능하다. 따라서 대규모 계산량이 필요한 현재의 인공지능 기술을 추월할 가능성을 제시한 것으로 평가를 받고 있다.
이준구 교수팀은 학습데이터와 테스트데이터를 양자 정보로 생성한 후 양자 정보의 병렬연산을 가능하게 하는 양자포킹 기술과 간단한 양자 측정기술을 조합해 양자 데이터 간의 유사성을 효율적으로 계산하는 비선형 커널 기반의 지도학습을 구현하는 양자 알고리즘 체계를 만들었다. 이후 IBM 클라우드 서비스를 통해 실제 양자컴퓨터에서 양자 지도학습을 실제 시연하는 데 성공했다.
KAIST 박경덕 연구교수가 공동 제1 저자로 참여한 이번 연구결과는 국제 학술지 네이처 자매지인 `npj Quantum Information' 誌 2020년 5월 6권에 게재됐다. (논문명: Quantum classifier with tailored quantum kernel).
기계학습에 있어 중요한 문제 중 하나는 주어진 데이터의 특징(feature)을 구분해 분류하는 것이다. 간단한 예로 동물 이미지 학습데이터에서 입, 귀 등의 특징을 바탕으로 분류하기 위한 결정 경계(decision boundary)를 학습하고 새로운 이미지가 입력되었을 때 개 또는 고양이로 분류하는 작업을 생각해볼 수 있다. 데이터의 특징들이 잘 나타나는 경우에는 선형적 결정 경계만으로 분류할 수 있다. 그러나 입과 귀 모양의 특징으로만 개와 고양이를 분류하기 쉽지 않다면 새로운 결정 경계를 찾기 위해 특징에 관한 정보 공간의 차원을 확장해야 하는데 이러한 과정에서 비선형 커널 기술이 필요하다.
양자컴퓨팅은 고전 컴퓨팅과는 달리 큐비트(quantum bit, 양자컴퓨팅 정보처리의 기본 단위)의 개수에 따라 정보 공간의 차원이 기하급수적으로 증가하기 때문에 이론적으로 고차원 정보처리에 있어 기하급수적으로 뛰어난 성능을 낼 수 있다.
연구팀은 이러한 양자컴퓨팅의 장점을 활용해 데이터 특징 대비 기하급수적인 계산 효율성을 달성하는 양자 기계학습 알고리즘을 개발했다. 이 교수 연구팀이 개발한 이 알고리즘은 저차원 입력 공간에 존재하는 데이터들을 큐비트로 표현되는 고차원 데이터 특징 공간(feature space)으로 옮긴 후, 양자화된 모든 학습데이터와 테스트데이터 간의 커널 함수를 양자 중첩을 활용해 동시에 계산하고 테스트데이터의 분류를 효율적으로 결정한다. 이때 사용되는 양자 회로의 계산 복잡도는 학습 데이터양에 대해서는 선형적으로 증가하나, 데이터 특징 개수에 대해서는 불과 로그(log)함수로 매우 천천히 증가하는 장점이 있다.
연구팀은 이와 함께 양자 회로의 체계적 설계를 통해 다양한 양자 커널 구현이 가능함을 이론적으로 증명했다. 커널 기반 기계학습에서는 주어진 입력 데이터에 따라 최적 커널이 달라질 수 있으므로, 다양한 양자 커널을 효율적으로 구현할 수 있게 된 점은 양자 커널 기반 기계학습의 실제 응용에 있어 매우 중요한 성과다.
연구팀은 IBM이 클라우드 서비스로 제공하는 다섯 개의 큐비트로 구성된 초전도 기반 양자 컴퓨터에서 이번에 개발에 성공한 양자 기계학습 알고리즘을 실험적으로 구현해 양자 커널 기반 기계학습의 성능을 실제 시연을 통해 이를 입증하는 데 성공했다.
이 연구에 참여한 박경덕 연구교수는 "연구팀이 개발한 커널 기반 양자 기계학습 알고리즘은 수년 안에 상용화될 것으로 예측되는 수백 큐비트의 NISQ(Noisy Intermediate-Scale Quantum) 컴퓨팅의 시대가 되면 기존의 고전 커널 기반 지도학습을 뛰어넘을 것ˮ이라면서 "복잡한 비선형 데이터의 패턴 인식 등을 위한 양자 기계학습 알고리즘으로 활발히 사용될 것ˮ이라고 말했다.
한편 이번 연구는 각각 한국연구재단의 창의 도전 연구기반 지원 사업과 한국연구재단의 한-아프리카 협력기반 조성 사업, 정보통신기획평가원의 정보통신기술인력 양성사업(ITRC)의 지원을 받아 수행됐다.
관련 논문: https://www.nature.com/articles/s41534-020-0272-6
2020.07.07 조회수 24229 -
 학습되지 않은 환경에서 스스로 학습하는 모바일 센싱 기술 개발
우리 대학 전산학부 이성주 교수 연구팀이 학습되지 않은 환경에 적은 양의 데이터로 스스로 적응하는 모바일 센싱 학습 기술 <메타센스(MetaSense)>를 개발했다.
모바일 센싱이란 스마트폰과 같은 모바일 기기의 다양한 센서를 이용하여 서비스(예: 수면의 질 평가, 걸음 수 추적 등)를 제공하는 기술이다. 최근 학계에서는 기계학습 기술의 발전과 더불어 우울증 진단, 운동 자세 관리 등 진보된 모바일 센싱의 가능성을 보여줌으로써 모바일 센싱의 범위를 더욱 확장하고 있다.
하지만 이러한 센싱 기술은 아직 널리 쓰이지 못하고 있다. 사용자 개인마다 가지고 있는 모바일 센싱의 환경이 다르기 때문이다. 사람마다 가지고 있는 고유한 생활패턴과 행동방식, 서로 다른 모바일 기기와 그 사양은 센서의 값에 큰 영향을 미친다. 다른 센서 값은 사람마다 고유한 센싱 환경을 만들고, 이는 센싱 모델이 미리 학습되지 않은 새로운 환경에서 작동할 때 사용이 어려울 만큼 성능 저하를 일으킨다.
연구팀은 이런 학습되지 않는 환경에서 적은 양의 데이터 (최소 1-2 샘플)만 가지고 적응할 수 있는 '메타러닝 프레임워크'를 제시했다. 메타러닝 (meta learning) 이란 적은 양의 데이터를 가지고도 새로운 지식을 학습할 수 있도록 하는 기계학습 원리다. 연구팀이 제시한 기술은 최신 전이학습 (transfer learning) 기술과 비교하여 18%, 메타러닝 기술과 비교하여 15%의 정확도 성능향상을 보였다.
이성주 교수는 ”최근 활발히 제안되고 있는 다양한 모바일 센싱 서비스가 특정 환경에 의존하지 않고 수많은 실제 사용 환경에서 우수한 성능을 보일 수 있게 해주는 연구다. 모바일 센싱 서비스가 연구에 그치지 않고 실제 많은 사람들에게 사용될 수 있는 가능성을 제시해 의미가 있다“라고 했다. 또한 신진우 교수는 “최근 메타러닝 방법론들이 기계학습 분야에서 크게 각광을 받고 있는데 주로 영상 데이터에 국한되어 왔었다. 본 연구에서 비영상 데이터에도 범용적으로 동작하는 메터러닝 기술을 개발하여 성공한 것은 앞으로도 관련 분야 연구에 큰 영향을 주리라 기대한다“라고 덧붙였다.
연구에 대한 설명이 담긴 비디오를 다음 링크에서 확인할 수 있고, (https://youtu.be/-6y0I1pd6XI) 자세한 정보는 프로젝트 웹사이트에서 볼 수 있다.
(https://nmsl.kaist.ac.kr/projects/metasense/)
이성주 교수, 신진우 AI대학원 교수, 공태식 박사과정, 김연수 학사과정이 참여한 이번 연구 결과는 2019년 11월 11일 센싱 컴퓨팅 분야 국제 최우수학회 ACM SenSys에서 발표됐다. (논문명: MetaSense: Few-Shot Adaptation to Untrained Conditions in Deep Mobile Sensing). 이 연구는 정부(과학기술정보통신부)의 재원으로 한국연구재단과 정보통신기술진흥센터, 한국연구재단 차세대 정보 컴퓨팅 기술개발사업의 지원을 받아 수행됐다.
2020.06.09 조회수 18209
학습되지 않은 환경에서 스스로 학습하는 모바일 센싱 기술 개발
우리 대학 전산학부 이성주 교수 연구팀이 학습되지 않은 환경에 적은 양의 데이터로 스스로 적응하는 모바일 센싱 학습 기술 <메타센스(MetaSense)>를 개발했다.
모바일 센싱이란 스마트폰과 같은 모바일 기기의 다양한 센서를 이용하여 서비스(예: 수면의 질 평가, 걸음 수 추적 등)를 제공하는 기술이다. 최근 학계에서는 기계학습 기술의 발전과 더불어 우울증 진단, 운동 자세 관리 등 진보된 모바일 센싱의 가능성을 보여줌으로써 모바일 센싱의 범위를 더욱 확장하고 있다.
하지만 이러한 센싱 기술은 아직 널리 쓰이지 못하고 있다. 사용자 개인마다 가지고 있는 모바일 센싱의 환경이 다르기 때문이다. 사람마다 가지고 있는 고유한 생활패턴과 행동방식, 서로 다른 모바일 기기와 그 사양은 센서의 값에 큰 영향을 미친다. 다른 센서 값은 사람마다 고유한 센싱 환경을 만들고, 이는 센싱 모델이 미리 학습되지 않은 새로운 환경에서 작동할 때 사용이 어려울 만큼 성능 저하를 일으킨다.
연구팀은 이런 학습되지 않는 환경에서 적은 양의 데이터 (최소 1-2 샘플)만 가지고 적응할 수 있는 '메타러닝 프레임워크'를 제시했다. 메타러닝 (meta learning) 이란 적은 양의 데이터를 가지고도 새로운 지식을 학습할 수 있도록 하는 기계학습 원리다. 연구팀이 제시한 기술은 최신 전이학습 (transfer learning) 기술과 비교하여 18%, 메타러닝 기술과 비교하여 15%의 정확도 성능향상을 보였다.
이성주 교수는 ”최근 활발히 제안되고 있는 다양한 모바일 센싱 서비스가 특정 환경에 의존하지 않고 수많은 실제 사용 환경에서 우수한 성능을 보일 수 있게 해주는 연구다. 모바일 센싱 서비스가 연구에 그치지 않고 실제 많은 사람들에게 사용될 수 있는 가능성을 제시해 의미가 있다“라고 했다. 또한 신진우 교수는 “최근 메타러닝 방법론들이 기계학습 분야에서 크게 각광을 받고 있는데 주로 영상 데이터에 국한되어 왔었다. 본 연구에서 비영상 데이터에도 범용적으로 동작하는 메터러닝 기술을 개발하여 성공한 것은 앞으로도 관련 분야 연구에 큰 영향을 주리라 기대한다“라고 덧붙였다.
연구에 대한 설명이 담긴 비디오를 다음 링크에서 확인할 수 있고, (https://youtu.be/-6y0I1pd6XI) 자세한 정보는 프로젝트 웹사이트에서 볼 수 있다.
(https://nmsl.kaist.ac.kr/projects/metasense/)
이성주 교수, 신진우 AI대학원 교수, 공태식 박사과정, 김연수 학사과정이 참여한 이번 연구 결과는 2019년 11월 11일 센싱 컴퓨팅 분야 국제 최우수학회 ACM SenSys에서 발표됐다. (논문명: MetaSense: Few-Shot Adaptation to Untrained Conditions in Deep Mobile Sensing). 이 연구는 정부(과학기술정보통신부)의 재원으로 한국연구재단과 정보통신기술진흥센터, 한국연구재단 차세대 정보 컴퓨팅 기술개발사업의 지원을 받아 수행됐다.
2020.06.09 조회수 18209 -
 이성주 교수, 스마트폰으로 사물 두드려 인식하는 노커(Knocker) 기술 개발
〈 왼쪽부터 공태식 박사과정, 조현성 석사과정, 이성주 교수 〉
우리 대학 전산학부 이성주 교수 연구팀이 스마트폰을 사물에 두드리는 것만으로 사물을 인식할 수 있는 ‘노커(Knocker)’ 기술을 개발했다.
이번 연구 결과는 기존 방식과 달리 카메라나 외부 장치를 사용하지 않아 어두운 곳에서도 식별에 전혀 지장이 없고, 추가 장비 없이 스마트폰만으로 사물 인식을 할 수 있어 기존 사물 인식 기술의 문제를 해결할 수 있을 것으로 기대된다.
공태식 박사과정, 조현성 석사과정, 인하대학교 이보원 교수가 참여한 이번 연구 결과는 9월 13일 유비쿼터스 컴퓨팅 분야 국제 최우수학회 ‘ACM 유비콤(ACM UbiComp)’에서 발표됐다. (논문명 : Knocker: Vibroacoustic-based Object Recognition with Smartphones)
기존의 사물 인식 기법은 일반적으로 두 종류로 나뉜다. 첫째는 촬영된 사진을 이용하는 방법으로 카메라를 이용해 사진을 찍어야 한다는 번거로움과 어두운 환경에서는 사용하지 못한다는 단점이 있다. 둘째는 RFID 등의 전자 태그를 부착해 전자신호로 구분하는 방법으로 태그의 가격 부담과 인식하고자 하는 모든 사물에 태그를 부착해야 한다는 비현실성 때문에 상용화에 어려움을 겪었다.
연구팀이 개발한 노커 기술은 카메라와 별도의 기기를 쓰지 않아도 사물을 인식할 수 있다. 노커 기술은 물체에 ‘노크’를 해서 생긴 반응을 스마트폰의 마이크, 가속도계, 자이로스코프로 감지하고, 이 데이터를 기계학습 기술을 통해 분석해 사물을 인식한다.
연구팀은 책, 노트북, 물병, 자전거 등 일상생활에서 흔히 접할 수 있는 23종의 사물로 실험한 결과 혼잡한 도로, 식당 등 잡음이 많은 공간에서는 83%의 사물 인식 정확도를 보였고, 가정 등 실내 공간에서의 사물 인식 정확도는 98%에 달하는 것을 확인했다.
연구팀의 노커 기술은 스마트폰 사용의 새로운 패러다임을 제시했다. 예를 들어 빈 물통을 스마트폰으로 노크하면 자동으로 물을 주문할 수 있고, IoT 기기를 활용하여 취침 전 침대를 노크하면 불을 끄고 알람을 자동 설정하는 등 총 15개의 구체적인 활용 방안을 선보였다.
이성주 교수는 “특별한 센서나 하드웨어 개발 없이 기존 스마트폰의 센서 조합과 기계학습을 활용해 개발한 소프트웨어 기술로, 스마트폰 사용자라면 보편적으로 사용할 수 있어 의미가 있다”라며 “사용자가 자주 이용하는 사물과의 상호 작용을 보다 쉽고 편하게 만들어 주는 기술이다”라고 말했다.
이 연구는 한국연구재단 차세대정보컴퓨팅기술개발사업과 정보통신기획평가원 정보통신․방송 기술개발사업 및 표준화 사업의 지원을 통해 수행됐다.
연구에 대한 설명과 시연은 링크에서 확인할 수 있고, ( https://www.youtube.com/watch?v=SyQn1vr_HeQ&feature=youtu.be ) 자세한 정보는 프로젝트 웹사이트에서 볼 수 있다. ( https://nmsl.kaist.ac.kr/projects/knocker/ )
□ 그림 설명
그림1. 물병에 노크 했을 때의 '노커' 기술 예시
그림2. 23개 사물에 대해 스마트폰 센서로 추출한 노크 고유 반응 시각화
2019.10.01 조회수 15363
이성주 교수, 스마트폰으로 사물 두드려 인식하는 노커(Knocker) 기술 개발
〈 왼쪽부터 공태식 박사과정, 조현성 석사과정, 이성주 교수 〉
우리 대학 전산학부 이성주 교수 연구팀이 스마트폰을 사물에 두드리는 것만으로 사물을 인식할 수 있는 ‘노커(Knocker)’ 기술을 개발했다.
이번 연구 결과는 기존 방식과 달리 카메라나 외부 장치를 사용하지 않아 어두운 곳에서도 식별에 전혀 지장이 없고, 추가 장비 없이 스마트폰만으로 사물 인식을 할 수 있어 기존 사물 인식 기술의 문제를 해결할 수 있을 것으로 기대된다.
공태식 박사과정, 조현성 석사과정, 인하대학교 이보원 교수가 참여한 이번 연구 결과는 9월 13일 유비쿼터스 컴퓨팅 분야 국제 최우수학회 ‘ACM 유비콤(ACM UbiComp)’에서 발표됐다. (논문명 : Knocker: Vibroacoustic-based Object Recognition with Smartphones)
기존의 사물 인식 기법은 일반적으로 두 종류로 나뉜다. 첫째는 촬영된 사진을 이용하는 방법으로 카메라를 이용해 사진을 찍어야 한다는 번거로움과 어두운 환경에서는 사용하지 못한다는 단점이 있다. 둘째는 RFID 등의 전자 태그를 부착해 전자신호로 구분하는 방법으로 태그의 가격 부담과 인식하고자 하는 모든 사물에 태그를 부착해야 한다는 비현실성 때문에 상용화에 어려움을 겪었다.
연구팀이 개발한 노커 기술은 카메라와 별도의 기기를 쓰지 않아도 사물을 인식할 수 있다. 노커 기술은 물체에 ‘노크’를 해서 생긴 반응을 스마트폰의 마이크, 가속도계, 자이로스코프로 감지하고, 이 데이터를 기계학습 기술을 통해 분석해 사물을 인식한다.
연구팀은 책, 노트북, 물병, 자전거 등 일상생활에서 흔히 접할 수 있는 23종의 사물로 실험한 결과 혼잡한 도로, 식당 등 잡음이 많은 공간에서는 83%의 사물 인식 정확도를 보였고, 가정 등 실내 공간에서의 사물 인식 정확도는 98%에 달하는 것을 확인했다.
연구팀의 노커 기술은 스마트폰 사용의 새로운 패러다임을 제시했다. 예를 들어 빈 물통을 스마트폰으로 노크하면 자동으로 물을 주문할 수 있고, IoT 기기를 활용하여 취침 전 침대를 노크하면 불을 끄고 알람을 자동 설정하는 등 총 15개의 구체적인 활용 방안을 선보였다.
이성주 교수는 “특별한 센서나 하드웨어 개발 없이 기존 스마트폰의 센서 조합과 기계학습을 활용해 개발한 소프트웨어 기술로, 스마트폰 사용자라면 보편적으로 사용할 수 있어 의미가 있다”라며 “사용자가 자주 이용하는 사물과의 상호 작용을 보다 쉽고 편하게 만들어 주는 기술이다”라고 말했다.
이 연구는 한국연구재단 차세대정보컴퓨팅기술개발사업과 정보통신기획평가원 정보통신․방송 기술개발사업 및 표준화 사업의 지원을 통해 수행됐다.
연구에 대한 설명과 시연은 링크에서 확인할 수 있고, ( https://www.youtube.com/watch?v=SyQn1vr_HeQ&feature=youtu.be ) 자세한 정보는 프로젝트 웹사이트에서 볼 수 있다. ( https://nmsl.kaist.ac.kr/projects/knocker/ )
□ 그림 설명
그림1. 물병에 노크 했을 때의 '노커' 기술 예시
그림2. 23개 사물에 대해 스마트폰 센서로 추출한 노크 고유 반응 시각화
2019.10.01 조회수 15363 -
 이의진 교수, 스마트폰으로 문서 촬영 시 발생하는 회전 오류 문제 해결
〈 이의진 교수(좌)와 오정민 박사과정(우) 〉
우리 대학 산업및시스템공학과 이의진 교수 연구팀이 스마트폰 카메라로 문서를 촬영할 때 자동으로 발생하는 불규칙적인 회전 오류 현상의 원인을 밝히고 해결책을 개발했다.
연구팀은 스마트폰의 방위 추적 알고리즘의 한계가 회전 오류의 원인임을 규명했다.
이번 연구 결과는 인간-컴퓨터 상호작용 학회의 국제 학술지인 ‘인터내셔널 저널 오브 휴먼 컴퓨터 스터디(International Journal of Human-Computer Studies)’ 4월 4일자 온라인 판에 게재됐고 8월호 저널에 게재될 예정이다.
스마트폰을 통해 책자, 문서 등을 촬영해 업무에 활용하는 것은 자연스러운 일상이 됐다. 하지만 촬영한 문서가 자동으로 90도 회전하는 현상으로 인해 불편을 겪는 사람들이 많다.
특히 여러 장의 사진을 찍었을 때 각기 다른 방향으로 회전돼 일일이 스마트폰을 돌리거나 파일을 편집해야 하는 현상이 발생한다.
스마트폰으로 문서를 촬영할 때는 대부분 스마트폰과 책상 위 문서가 평행 상태이다.
이 때 스마트폰을 회전시키면 스마트폰의 방위 추적 알고리즘이 작동하지 않는다. 방위 추적 알고리즘은 기본적으로 사용자가 스마트폰을 세워서 사용한다는 가정 하에 한 방향으로 가해지는 중력가속도를 측정해 현재 방위를 추정하는 방식으로 설계됐기 때문이다.
연구팀은 실험을 통해 오류 발생 수치를 측정했다. 실험 결과 문서를 가로로 촬영 시 방위 추적 오류가 93%의 높은 확률로 발생함을 확인했다.
일반 사용자는 오류의 원인을 파악하기 어렵다. 대부분의 카메라 앱은 셔터 버튼에 있는 카메라 모양의 아이콘 방향을 통해 실시간 방위를 표시하고 있지만 이러한 기능에 대해서도 사용자들은 인지하지 못한 것으로 파악됐다.
연구팀은 스마트폰의 모션센서 데이터를 활용해 문서 촬영 중에 방위를 정확하게 추적해 문제를 해결했다.
모션센서 데이터의 핵심 기술은 두 가지로 구분할 수 있다. 일반적으로 스마트폰으로 문서를 촬영할 때는 스마트폰이 지면과 평행을 이루기 때문에 스마트폰에 장착된 중력 가속도 센서를 관측해 이러한 문서 촬영 의도를 쉽게 알 수 있다.
두 번째로 문서 촬영 중에 발생하는 스마트폰 회전은 회전 각속도를 측정하는 센서를 활용해 추적할 수 있다. 카메라 앱 실행 후에 문서 촬영을 위해 스마트폰을 회전시키기 때문에 이를 측정해 회전각이 일정 임계치를 넘으면 방위를 변경하는 것으로 파악할 수 있고 이를 통해 방향을 알 수 있는 것이다.
또한 연구팀은 문서 촬영 시 촬영자 쪽으로 스마트폰이 미세하게 기울어지는 마이크로 틸트(micro-tilt) 현상을 발견했다.
이 현상으로 인해 스마트폰으로 가해지는 중력가속도가 스마트폰 측면으로 분산된다. 눈에는 잘 보이지 않을 정도로 작은 기울기지만 모션센서 데이터를 활용해 마이크로 틸트 행동 패턴의 기계학습 알고리즘을 훈련시킬 수 있다. 이를 통해 정확한 방위 추적이 가능하다.
연구 팀의 실험 결과에 따르면 모션센서 데이터를 활용한 방위 추적 방식의 정확도는 93%로 매우 높아 안드로이드 및 iOS등 상용 스마트폰에도 적용 가능하다.
이 기술들은 기존 방위 추적 알고리즘의 사각지대였던 수평 촬영 상황에서 작동하기 때문에 기존 방위 추적 알고리즘과 겹치는 부분 없이 상호 보완적으로 작동할 수 있다.
이 교수는 “스마트폰을 활용한 문서 촬영은 필수가 됐지만 회전 오류의 원인 규명과 해결책이 어려워 불편함이 많았다”며 “모션센서 데이터를 통해 촬영의 의도를 파악하고 자동으로 오류를 바로잡는 기술은 사용자의 불편을 해결하고 문서 촬영에 특화된 다양한 응용서비스 개발의 기초가 될 것이다”고 말했다.
미래창조과학부의 지원을 통해 수행된 이번 기술 중 국내 특허 2건이 등록이 완료됐고 미국 특허가 3월 1일에 수락됐다.
□ 그림 설명
그림1. 방위 오류 발생으로 인해 생기는 불편함
그림2. 평면촬영시 발생하는 방위 오류 상태
그림3. 자이로스코프를 활용한 스마트폰 회전 추적 모식도
그림4. 마이크로틸트현상
2017.06.27 조회수 16946
이의진 교수, 스마트폰으로 문서 촬영 시 발생하는 회전 오류 문제 해결
〈 이의진 교수(좌)와 오정민 박사과정(우) 〉
우리 대학 산업및시스템공학과 이의진 교수 연구팀이 스마트폰 카메라로 문서를 촬영할 때 자동으로 발생하는 불규칙적인 회전 오류 현상의 원인을 밝히고 해결책을 개발했다.
연구팀은 스마트폰의 방위 추적 알고리즘의 한계가 회전 오류의 원인임을 규명했다.
이번 연구 결과는 인간-컴퓨터 상호작용 학회의 국제 학술지인 ‘인터내셔널 저널 오브 휴먼 컴퓨터 스터디(International Journal of Human-Computer Studies)’ 4월 4일자 온라인 판에 게재됐고 8월호 저널에 게재될 예정이다.
스마트폰을 통해 책자, 문서 등을 촬영해 업무에 활용하는 것은 자연스러운 일상이 됐다. 하지만 촬영한 문서가 자동으로 90도 회전하는 현상으로 인해 불편을 겪는 사람들이 많다.
특히 여러 장의 사진을 찍었을 때 각기 다른 방향으로 회전돼 일일이 스마트폰을 돌리거나 파일을 편집해야 하는 현상이 발생한다.
스마트폰으로 문서를 촬영할 때는 대부분 스마트폰과 책상 위 문서가 평행 상태이다.
이 때 스마트폰을 회전시키면 스마트폰의 방위 추적 알고리즘이 작동하지 않는다. 방위 추적 알고리즘은 기본적으로 사용자가 스마트폰을 세워서 사용한다는 가정 하에 한 방향으로 가해지는 중력가속도를 측정해 현재 방위를 추정하는 방식으로 설계됐기 때문이다.
연구팀은 실험을 통해 오류 발생 수치를 측정했다. 실험 결과 문서를 가로로 촬영 시 방위 추적 오류가 93%의 높은 확률로 발생함을 확인했다.
일반 사용자는 오류의 원인을 파악하기 어렵다. 대부분의 카메라 앱은 셔터 버튼에 있는 카메라 모양의 아이콘 방향을 통해 실시간 방위를 표시하고 있지만 이러한 기능에 대해서도 사용자들은 인지하지 못한 것으로 파악됐다.
연구팀은 스마트폰의 모션센서 데이터를 활용해 문서 촬영 중에 방위를 정확하게 추적해 문제를 해결했다.
모션센서 데이터의 핵심 기술은 두 가지로 구분할 수 있다. 일반적으로 스마트폰으로 문서를 촬영할 때는 스마트폰이 지면과 평행을 이루기 때문에 스마트폰에 장착된 중력 가속도 센서를 관측해 이러한 문서 촬영 의도를 쉽게 알 수 있다.
두 번째로 문서 촬영 중에 발생하는 스마트폰 회전은 회전 각속도를 측정하는 센서를 활용해 추적할 수 있다. 카메라 앱 실행 후에 문서 촬영을 위해 스마트폰을 회전시키기 때문에 이를 측정해 회전각이 일정 임계치를 넘으면 방위를 변경하는 것으로 파악할 수 있고 이를 통해 방향을 알 수 있는 것이다.
또한 연구팀은 문서 촬영 시 촬영자 쪽으로 스마트폰이 미세하게 기울어지는 마이크로 틸트(micro-tilt) 현상을 발견했다.
이 현상으로 인해 스마트폰으로 가해지는 중력가속도가 스마트폰 측면으로 분산된다. 눈에는 잘 보이지 않을 정도로 작은 기울기지만 모션센서 데이터를 활용해 마이크로 틸트 행동 패턴의 기계학습 알고리즘을 훈련시킬 수 있다. 이를 통해 정확한 방위 추적이 가능하다.
연구 팀의 실험 결과에 따르면 모션센서 데이터를 활용한 방위 추적 방식의 정확도는 93%로 매우 높아 안드로이드 및 iOS등 상용 스마트폰에도 적용 가능하다.
이 기술들은 기존 방위 추적 알고리즘의 사각지대였던 수평 촬영 상황에서 작동하기 때문에 기존 방위 추적 알고리즘과 겹치는 부분 없이 상호 보완적으로 작동할 수 있다.
이 교수는 “스마트폰을 활용한 문서 촬영은 필수가 됐지만 회전 오류의 원인 규명과 해결책이 어려워 불편함이 많았다”며 “모션센서 데이터를 통해 촬영의 의도를 파악하고 자동으로 오류를 바로잡는 기술은 사용자의 불편을 해결하고 문서 촬영에 특화된 다양한 응용서비스 개발의 기초가 될 것이다”고 말했다.
미래창조과학부의 지원을 통해 수행된 이번 기술 중 국내 특허 2건이 등록이 완료됐고 미국 특허가 3월 1일에 수락됐다.
□ 그림 설명
그림1. 방위 오류 발생으로 인해 생기는 불편함
그림2. 평면촬영시 발생하는 방위 오류 상태
그림3. 자이로스코프를 활용한 스마트폰 회전 추적 모식도
그림4. 마이크로틸트현상
2017.06.27 조회수 16946