%EC%9D%B8%EA%B3%B5%EC%A7%80%EB%8A%A5
-
 적층 제조된 티타늄 합금의 강도-연성 딜레마 AI 기술로 극복
우리 대학 기계공학과 이승철 교수 연구팀이 POSTECH 신소재공학과 김형섭 교수 연구팀과 함께 인공지능 기술을 활용해 Ti-6Al-4V 합금의 강도-연성 딜레마를 극복하고 고강도·고연신 금속 제품을 생산해 내는 데 성공했다고 밝혔다. 연구팀이 개발한 인공지능은 3D프린팅 공정변수에 따른 기계적 물성을 정확히 예측하는 동시에 예측의 불확실성 정보를 제공하며 이 두 정보를 활용해 실제 3D프린팅을 진행할 가치가 높은 공정변수를 추천한다.
3D프린팅 기술 중에서도 레이저 분말 베드 융합은 뛰어난 강도 및 생체 적합성으로 유명한 Ti-6Al-4V 합금을 제조하기 위한 혁신적인 기술이다. 그러나 3D프린팅으로 제작된 이 합금은 강도와 연성을 동시에 높이기 어렵다는 문제점이 있다. 3D프린팅의 공정변수와 열처리 조건을 조절해 이를 해결하고자 하는 연구들이 있었지만, 방대한 공정변수 조합들을 실험 및 시뮬레이션으로 탐색하기에는 한계가 있었다.
연구팀이 개발한 능동 학습(Active Learning) 프레임워크는 다양한 3D프린팅 공정변수 및 열처리 조건들을 빠르게 탐색하여 그 중 합금의 강도와 연성을 동시에 높일 수 있다고 예상되는 것을 추천한다. 이런 추천은 인공지능 모델이 각 공정변수 및 열처리 조건에 대해 예측한 극한 인장 강도와 전연신율을 비롯해 예측의 불확실성 정보도 활용해 진행되며 추천된 것에 대해선 3D프린팅 및 인장 실험을 통해 실제 물성값을 얻게 된다. 새롭게 얻어낸 물성값을 인공지능 모델 학습에 추가로 활용하여 반복적으로 공정변수 및 열처리 조건들을 탐색하였으며 단 5번만의 시도로 고성능 합금을 생산해 낼 수 있는 공정변수 및 열처리 조건들을 도출하였다. 이를 적용해 3D프린팅한 Ti-6Al-4V 합금은 극한 인장 강도 1190MPa, 전연신율 16.5%를 기록하며 강도-연성 딜레마를 극복해 냈다.
이승철 교수는 “이번 연구에서 3D프린팅 공정변수와 열처리 조건을 최적화하여 고강도·고연신 Ti-6Al-4V 합금을 최소한의 실험만으로 도출해 낼 수 있었으며, 기존 연구들과 비교해 비슷한 극한 인장 강도를 가지지만 더 큰 전연신율을 가진 합금을 그리고 비슷한 전연신율을 가지지만 더 큰 극한 인장 강도를 가진 합금을 제작할 수 있었다.”라고 말했다. “또한, 기계적 물성뿐만 아니라 열전도도 및 열팽창과 같은 다른 물성에 관해서도 본 연구 방법이 적용되면 3D프린팅 공정변수와 열처리 조건에 대한 효율적인 탐색이 가능할 것으로 예상된다”라고 덧붙였다.
이번 연구 결과는 국제 학술지 ‘Nature Communications’에 지난 1월 22일에 출판되었으며 (https://doi.org/10.1038/s41467-025-56267-1), 이 연구는 한국연구재단 나노·소재기술개발사업 및 선도연구센터사업의 지원을 받아 진행됐다.
2025.02.21 조회수 3865
적층 제조된 티타늄 합금의 강도-연성 딜레마 AI 기술로 극복
우리 대학 기계공학과 이승철 교수 연구팀이 POSTECH 신소재공학과 김형섭 교수 연구팀과 함께 인공지능 기술을 활용해 Ti-6Al-4V 합금의 강도-연성 딜레마를 극복하고 고강도·고연신 금속 제품을 생산해 내는 데 성공했다고 밝혔다. 연구팀이 개발한 인공지능은 3D프린팅 공정변수에 따른 기계적 물성을 정확히 예측하는 동시에 예측의 불확실성 정보를 제공하며 이 두 정보를 활용해 실제 3D프린팅을 진행할 가치가 높은 공정변수를 추천한다.
3D프린팅 기술 중에서도 레이저 분말 베드 융합은 뛰어난 강도 및 생체 적합성으로 유명한 Ti-6Al-4V 합금을 제조하기 위한 혁신적인 기술이다. 그러나 3D프린팅으로 제작된 이 합금은 강도와 연성을 동시에 높이기 어렵다는 문제점이 있다. 3D프린팅의 공정변수와 열처리 조건을 조절해 이를 해결하고자 하는 연구들이 있었지만, 방대한 공정변수 조합들을 실험 및 시뮬레이션으로 탐색하기에는 한계가 있었다.
연구팀이 개발한 능동 학습(Active Learning) 프레임워크는 다양한 3D프린팅 공정변수 및 열처리 조건들을 빠르게 탐색하여 그 중 합금의 강도와 연성을 동시에 높일 수 있다고 예상되는 것을 추천한다. 이런 추천은 인공지능 모델이 각 공정변수 및 열처리 조건에 대해 예측한 극한 인장 강도와 전연신율을 비롯해 예측의 불확실성 정보도 활용해 진행되며 추천된 것에 대해선 3D프린팅 및 인장 실험을 통해 실제 물성값을 얻게 된다. 새롭게 얻어낸 물성값을 인공지능 모델 학습에 추가로 활용하여 반복적으로 공정변수 및 열처리 조건들을 탐색하였으며 단 5번만의 시도로 고성능 합금을 생산해 낼 수 있는 공정변수 및 열처리 조건들을 도출하였다. 이를 적용해 3D프린팅한 Ti-6Al-4V 합금은 극한 인장 강도 1190MPa, 전연신율 16.5%를 기록하며 강도-연성 딜레마를 극복해 냈다.
이승철 교수는 “이번 연구에서 3D프린팅 공정변수와 열처리 조건을 최적화하여 고강도·고연신 Ti-6Al-4V 합금을 최소한의 실험만으로 도출해 낼 수 있었으며, 기존 연구들과 비교해 비슷한 극한 인장 강도를 가지지만 더 큰 전연신율을 가진 합금을 그리고 비슷한 전연신율을 가지지만 더 큰 극한 인장 강도를 가진 합금을 제작할 수 있었다.”라고 말했다. “또한, 기계적 물성뿐만 아니라 열전도도 및 열팽창과 같은 다른 물성에 관해서도 본 연구 방법이 적용되면 3D프린팅 공정변수와 열처리 조건에 대한 효율적인 탐색이 가능할 것으로 예상된다”라고 덧붙였다.
이번 연구 결과는 국제 학술지 ‘Nature Communications’에 지난 1월 22일에 출판되었으며 (https://doi.org/10.1038/s41467-025-56267-1), 이 연구는 한국연구재단 나노·소재기술개발사업 및 선도연구센터사업의 지원을 받아 진행됐다.
2025.02.21 조회수 3865 -
 감정노동 근로자 정신건강 살피는 AI 나왔다
감정노동이 필수적인 직무를 수행하는 상담원, 은행원 근로자들은 실제로 느끼는 감정과는 다른 감정을 표현해야 하는 상황에 자주 놓이게 된다. 이런 감정적 작업 부하에 장시간 노출되면 심각한 정신적, 심리적 문제뿐만 아니라 심혈관계 및 소화기계 질환 등 신체적 질병으로도 이어질 수 있어 이는 심각한 사회 문제로 여겨지고 있다. 한미 공동 연구진은 인공지능을 활용해서 근로자의 감정적 작업 부하를 자동으로 측정하고 실시간으로 모니터링할 수 있는 새로운 방법을 제시했다.
우리 대학 전산학부 이의진 교수 연구팀은 중앙대학교 박은지 교수팀, 미국 애크런 대학교의 감정노동 분야 세계적인 석학인 제임스 디펜도프 교수팀과 다학제 연구팀을 구성해 근로자들의 감정적 작업 부하를 실시간으로 추정해 심각한 정신적, 신체적 질병을 예방할 수 있는 인공지능 모델을 개발했다고 11일 밝혔다.
연구팀은 이번 연구를 통해 근로자가 감정적 작업 부하가 높은 상황과 그렇지 않은 상황을 87%의 정확도로 구분해 내는데 성공했다. 이 시스템은 기존의 설문이나 인터뷰 같은 주관적인 자기 보고 방식에 의존하지 않고도 감정적 작업 부하를 실시간으로 평가할 수 있어 근로자들의 정신건강 문제를 사전에 예방하고 효과적으로 관리할 수 있다는 장점이 있다. 또한, 이 시스템은 콜센터뿐만 아니라 고객 응대가 필요한 다양한 직종에 적용될 수 있어 감정 노동자들의 장기적인 정신건강 보호에 크게 기여할 것으로 기대된다.
기존 연구는 주로 사무실에서 컴퓨터를 사용해 서류 업무를 주로 다루는 직장인의 인지적 작업 부하(정보를 처리하고 의사결정을 내리는 데 필요한 정신적 노력)를 다뤘으며, 고객을 상대하는 감정 노동자들의 작업 부하를 추정하는 연구는 전무한 상황이었다.
감정 노동자들의 감정적 작업 부하는 고용주로부터 요구되는 정서 표현 규칙과 관련이 깊다. 특히 감정노동이 요구되는 상황에서는 자신의 실제 감정을 억제하고 친절한 응대를 해야 하기 때문에 대체적으로 근로자의 감정이나 심리적 상태가 표면적으로 드러나 있지 않다.
기존의 감정-탐지 인공지능 모델들은 주로 인간의 감정이 표정이나 목소리에 명백하게 드러나는 데이터를 활용해 모델을 학습해왔기 때문에 자신의 감정을 억제하고 친절한 응대를 강요받는 감정 노동자들의 내적인 감정적 작업 부하를 측정하는 것은 어려운 일로 여겨져 왔다.
모델 개발을 위해서는 현실을 충실히 반영한 고품질의 상담 시나리오 데이터셋 구축이 필수적어서 연구팀은 현업에 종사 중인 감정 노동자들을 대상으로 고객상담 데이터셋을 구축했다. 일반적인 콜센터 고객을 응대 시나리오를 개발하여 31명의 상담사로부터 음성, 행동, 생체신호 등 다중 모달 센서 데이터를 수집했다.
연구팀은 인공지능 모델 개발을 위해 고객과 상담사의 음성 데이터로부터 총 176개의 음성특징을 추출했다. 음성 신호 처리를 통해서 시간, 주파수, 음조 등 다양한 종류의 음성특징이 추출하며, 대화 내용은 고객의 개인정보 보호를 위하여 사용하지 않았다. 정서 표현 규칙으로 인한 상담사의 억제된 감정 상태를 추정하기 위하여 상담사로부터 수집된 생체신호로부터 추가적인 특징을 추출했다.
피부의 전기적 특성을 나타내는 피부 전도도(EDA, Electrodermal activity) 13개의 특징, 뇌의 전기적 활성도를 측정하는 뇌파(EEG, Electroencephalogram) 20개의 특징, 심전도(ECG, Electrocardiogram) 7개의 특징, 그 외 몸의 움직임, 체온 데이터로부터 12개의 특징을 추출했다. 총 228개의 특징을 추출해 9종의 인공지능 모델을 학습하여 성능 비교 평가를 수행했다.
결과적으로, 학습된 모델은 상담사가 감정적 작업 부하가 높은 상황과 그렇지 않은 상황을 87%의 정확도로 구분해 냈다. 흥미로운 점은 기존 감정-탐지 모델에서 대상의 목소리가 성능 향상에 기여하는 주요한 요인이었지만 본인의 감정을 억누르고 친절함을 유지해야 하는 감정노동의 상황에서는 상담사의 목소리가 포함될 경우 오히려 모델의 성능이 떨어지는 현상을 보였다는 것이다. 그 외에 고객의 목소리, 상담사의 피부 전도도 및 체온이 모델 성능 향상에 중요한 영향을 미치는 특징으로 밝혀졌다.
이의진 교수는 "감정적 작업 부하를 실시간으로 측정할 수 있는 기술을 통해 감정노동의 직무 환경 개선과 정신건강을 보호할 수 있다”며 "개발된 기술을 감정 노동자의 정신건강을 관리할 수 있는 모바일 앱과 연계하여 실증할 예정이다”고 말했다.
중앙대학교 박은지 교수(KAIST 전산학부 박사 졸업)가 제1 저자이며 유비쿼터스 컴퓨팅 분야 국제 최우수 학술지인 「Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies」 2024년 9월호에 게재됐다. 또한, 이 연구는 인간-컴퓨터 상호작용 분야의 최우수 학술대회인 ACM UbiComp 2024에서 발표됐다. (논문제목: Hide-and-seek: Detecting Workers’ Emotional Workload in Emotional Labor Contexts Using Multimodal Sensing, https://doi.org/10.1145/3678593)
이번 연구는 과학기술정보통신부 정보통신기획평가원 ICT융합산업혁신기술개발사업의 지원을 받아 수행됐다.
2025.02.11 조회수 4830
감정노동 근로자 정신건강 살피는 AI 나왔다
감정노동이 필수적인 직무를 수행하는 상담원, 은행원 근로자들은 실제로 느끼는 감정과는 다른 감정을 표현해야 하는 상황에 자주 놓이게 된다. 이런 감정적 작업 부하에 장시간 노출되면 심각한 정신적, 심리적 문제뿐만 아니라 심혈관계 및 소화기계 질환 등 신체적 질병으로도 이어질 수 있어 이는 심각한 사회 문제로 여겨지고 있다. 한미 공동 연구진은 인공지능을 활용해서 근로자의 감정적 작업 부하를 자동으로 측정하고 실시간으로 모니터링할 수 있는 새로운 방법을 제시했다.
우리 대학 전산학부 이의진 교수 연구팀은 중앙대학교 박은지 교수팀, 미국 애크런 대학교의 감정노동 분야 세계적인 석학인 제임스 디펜도프 교수팀과 다학제 연구팀을 구성해 근로자들의 감정적 작업 부하를 실시간으로 추정해 심각한 정신적, 신체적 질병을 예방할 수 있는 인공지능 모델을 개발했다고 11일 밝혔다.
연구팀은 이번 연구를 통해 근로자가 감정적 작업 부하가 높은 상황과 그렇지 않은 상황을 87%의 정확도로 구분해 내는데 성공했다. 이 시스템은 기존의 설문이나 인터뷰 같은 주관적인 자기 보고 방식에 의존하지 않고도 감정적 작업 부하를 실시간으로 평가할 수 있어 근로자들의 정신건강 문제를 사전에 예방하고 효과적으로 관리할 수 있다는 장점이 있다. 또한, 이 시스템은 콜센터뿐만 아니라 고객 응대가 필요한 다양한 직종에 적용될 수 있어 감정 노동자들의 장기적인 정신건강 보호에 크게 기여할 것으로 기대된다.
기존 연구는 주로 사무실에서 컴퓨터를 사용해 서류 업무를 주로 다루는 직장인의 인지적 작업 부하(정보를 처리하고 의사결정을 내리는 데 필요한 정신적 노력)를 다뤘으며, 고객을 상대하는 감정 노동자들의 작업 부하를 추정하는 연구는 전무한 상황이었다.
감정 노동자들의 감정적 작업 부하는 고용주로부터 요구되는 정서 표현 규칙과 관련이 깊다. 특히 감정노동이 요구되는 상황에서는 자신의 실제 감정을 억제하고 친절한 응대를 해야 하기 때문에 대체적으로 근로자의 감정이나 심리적 상태가 표면적으로 드러나 있지 않다.
기존의 감정-탐지 인공지능 모델들은 주로 인간의 감정이 표정이나 목소리에 명백하게 드러나는 데이터를 활용해 모델을 학습해왔기 때문에 자신의 감정을 억제하고 친절한 응대를 강요받는 감정 노동자들의 내적인 감정적 작업 부하를 측정하는 것은 어려운 일로 여겨져 왔다.
모델 개발을 위해서는 현실을 충실히 반영한 고품질의 상담 시나리오 데이터셋 구축이 필수적어서 연구팀은 현업에 종사 중인 감정 노동자들을 대상으로 고객상담 데이터셋을 구축했다. 일반적인 콜센터 고객을 응대 시나리오를 개발하여 31명의 상담사로부터 음성, 행동, 생체신호 등 다중 모달 센서 데이터를 수집했다.
연구팀은 인공지능 모델 개발을 위해 고객과 상담사의 음성 데이터로부터 총 176개의 음성특징을 추출했다. 음성 신호 처리를 통해서 시간, 주파수, 음조 등 다양한 종류의 음성특징이 추출하며, 대화 내용은 고객의 개인정보 보호를 위하여 사용하지 않았다. 정서 표현 규칙으로 인한 상담사의 억제된 감정 상태를 추정하기 위하여 상담사로부터 수집된 생체신호로부터 추가적인 특징을 추출했다.
피부의 전기적 특성을 나타내는 피부 전도도(EDA, Electrodermal activity) 13개의 특징, 뇌의 전기적 활성도를 측정하는 뇌파(EEG, Electroencephalogram) 20개의 특징, 심전도(ECG, Electrocardiogram) 7개의 특징, 그 외 몸의 움직임, 체온 데이터로부터 12개의 특징을 추출했다. 총 228개의 특징을 추출해 9종의 인공지능 모델을 학습하여 성능 비교 평가를 수행했다.
결과적으로, 학습된 모델은 상담사가 감정적 작업 부하가 높은 상황과 그렇지 않은 상황을 87%의 정확도로 구분해 냈다. 흥미로운 점은 기존 감정-탐지 모델에서 대상의 목소리가 성능 향상에 기여하는 주요한 요인이었지만 본인의 감정을 억누르고 친절함을 유지해야 하는 감정노동의 상황에서는 상담사의 목소리가 포함될 경우 오히려 모델의 성능이 떨어지는 현상을 보였다는 것이다. 그 외에 고객의 목소리, 상담사의 피부 전도도 및 체온이 모델 성능 향상에 중요한 영향을 미치는 특징으로 밝혀졌다.
이의진 교수는 "감정적 작업 부하를 실시간으로 측정할 수 있는 기술을 통해 감정노동의 직무 환경 개선과 정신건강을 보호할 수 있다”며 "개발된 기술을 감정 노동자의 정신건강을 관리할 수 있는 모바일 앱과 연계하여 실증할 예정이다”고 말했다.
중앙대학교 박은지 교수(KAIST 전산학부 박사 졸업)가 제1 저자이며 유비쿼터스 컴퓨팅 분야 국제 최우수 학술지인 「Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies」 2024년 9월호에 게재됐다. 또한, 이 연구는 인간-컴퓨터 상호작용 분야의 최우수 학술대회인 ACM UbiComp 2024에서 발표됐다. (논문제목: Hide-and-seek: Detecting Workers’ Emotional Workload in Emotional Labor Contexts Using Multimodal Sensing, https://doi.org/10.1145/3678593)
이번 연구는 과학기술정보통신부 정보통신기획평가원 ICT융합산업혁신기술개발사업의 지원을 받아 수행됐다.
2025.02.11 조회수 4830 -
 AI로 우주용 전기추력기 개발·고성능 예측
홀추력기는 스페이스X의 스타링크(Starlink) 군집위성이나 NASA의 사이키(Psyche) 소행성 탐사선 등과 같은 여러 고난이도 우주 임무에 활용되는, 플라즈마*를 이용한 고효율 추진 장치로, 핵심적인 우주기술 중 하나다. KAIST 연구진이 인공지능 기법을 사용해 개발한 큐브위성용 홀추력기를 올해 11월에 예정된 누리호 4차 발사에서 큐브위성인 K-HERO에 탑재돼 우주에서 성능 검증을 진행할 예정이라고 밝혔다.
*플라즈마(plasma)는 기체가 높은 에너지로 가열되어 전하를 띄는 이온과 전자로 분리된 물질의 네 가지 상태 중 하나로 우주 전기추진 뿐만 아니라 반도체 및 디스플레이 제조공정과 살균장치 등에 널리 활용되고 있다.
우리 대학 원자력및양자공학과 최원호 교수 연구팀이 인공위성이나 우주탐사선의 엔진인 홀 전기 추력기(홀추력기, Hall thruster)의 추력 성능을 높은 정확도로 예측할 수 있는 인공지능 기법을 개발했다고 3일 밝혔다.
홀추력기는 연비가 높아 적은 추진제(연료)를 사용하고도 위성이나 우주선을 크게 가속할 수 있으며, 소모 전력 대비 큰 추력을 발생시킬 수 있다. 이러한 장점을 바탕으로, 추진제 절약이 중요한 우주 환경에서 군집위성의 편대비행 유지, 우주쓰레기 감축을 위한 궤도이탈 기동, 혜성이나 화성 탐사와 같은 심우주 탐사를 위한 추진력 제공 등 다양한 임무에 폭넓게 활용되고 있다.
최근 뉴스페이스 시대에 접어들어 우주산업이 확장됨에 따라 우주 임무가 다양해지고 있고 이에 맞는 홀추력기 수요가 증가하고 있다. 각각의 고유한 임무에 최적화된 고효율 홀추력기를 신속하게 개발하기 위해서는 설계단계에서부터 추력기의 성능을 정확하게 예측하는 기법이 필수적이다.
그러나 기존의 방식들은 홀추력기 내에서 복잡하게 일어나는 플라즈마 현상을 정밀하게 다루지 못하거나, 특정 조건에 한정돼, 성능 예측 정확도가 낮은 한계가 있었다.
연구팀은 홀추력기의 설계, 제작, 시험의 반복 작업에 걸리는 시간과 비용을 획기적으로 줄이는 인공지능을 기반으로 한 정확도가 높은 추력기 성능 예측기법을 개발했다.
2003년부터 국내에서 전기추력기 개발 연구를 처음으로 시작해 관련 연구개발을 주도하고 있는 최원호 교수팀은 자체적으로 개발한 전기추력기 전산 해석 도구를 활용해 생성한 18,000개의 홀추력기 학습데이터를 기반으로 인공신경망 앙상블 구조를 도입해 추력 성능 예측에 적용했다.
양질의 학습데이터를 확보하기 위해 개발된 전산 해석 도구는 플라즈마 물리 현상과 추력 성능을 모델링한다. 전산 해석 도구의 정확성은, 연구팀이 국내 최초로 개발한 10개의 홀추력기로 수행된 100여 개의 실험 데이터와 비교해 평균오차가 10% 이내로 정확도가 높은 것으로 검증됐다.
학습된 인공신경망 앙상블 모델은 홀추력기의 설계 변수에 따라 높은 정확도로 단지 수초 내로 짧은 시간 안에 추력기 성능을 예측할 수 있는 디지털트윈 모델로 작동한다.
특히 기존에 알려진 스케일링 법칙으로는 분석하기 어려웠던 연료 유량이나 자기장과 같은 설계 변수에 따른 추력과 방전전류와 같은 성능지표 변화를 상세히 분석할 수 있다.
연구팀은 이번에 개발한 인공신경망 모델이 자체 개발한 700W급 및 1kW급 홀추력기에서 평균오차 5% 이내, 미 공군연구소에서 개발한 5kW급 고전력 홀추력기에 대해 평균오차 9% 이내의 정확도를 보여주었다. 이번 연구로 개발한 인공지능 예측기법이 다양한 전력 크기의 홀추력기에 폭넓게 적용할 수 있는 것을 입증했다.
최원호 교수는 “연구팀에서 개발한 인공지능 기반 성능 예측기법은 정확도가 높아 인공위성과 우주선의 엔진인 홀추력기의 추력성능 분석과 고효율 저전력 홀추력기 개발에 이미 활용되고 있다. 이 인공지능 기법은 홀추력기 뿐만 아니라 반도체, 표면 처리 및 코팅 등 다양한 산업에서 활용되는 이온빔 소스의 연구개발에도 접목될 수 있다”라고 밝혔다.
또한, 최교수는 “연구팀의 실험실 창업기업으로 전기추진 전문기업인 코스모비㈜와 함께 인공지능 기법을 사용해 개발한 큐브위성용 홀추력기는 올해 11월에 예정된 누리호 4차 발사에서 3U(30x10x10 cm) 큐브위성인 K-HERO에 탑재돼 우주에서 성능 검증을 진행할 예정”이라고 설명했다.
원자력및양자공학과(우주탐사공학학제전공) 박재홍 박사과정 학생이 제1 저자로 참여한 이번 연구 결과는 국제적으로 저명한 인공지능 다학제 학술지인 ‘어드밴스드 인텔리전트 시스템(Advanced Intelligent Systems)’에 2024년 12월 25일에 온라인 게재됐으며, 저널 표지논문(front cover)으로 채택돼 혁신성을 인정받았다.
이번 연구는 한국연구재단 스페이스파이오니어사업(200mN급 고추력 전기추진시스템 개발)의 지원을 받아 수행됐다.
(논문 제목: Predicting Performance of Hall Effect Ion Source Using Machine Learning, DOI: https://doi.org/10.1002/aisy.202400555)
2025.02.03 조회수 4675
AI로 우주용 전기추력기 개발·고성능 예측
홀추력기는 스페이스X의 스타링크(Starlink) 군집위성이나 NASA의 사이키(Psyche) 소행성 탐사선 등과 같은 여러 고난이도 우주 임무에 활용되는, 플라즈마*를 이용한 고효율 추진 장치로, 핵심적인 우주기술 중 하나다. KAIST 연구진이 인공지능 기법을 사용해 개발한 큐브위성용 홀추력기를 올해 11월에 예정된 누리호 4차 발사에서 큐브위성인 K-HERO에 탑재돼 우주에서 성능 검증을 진행할 예정이라고 밝혔다.
*플라즈마(plasma)는 기체가 높은 에너지로 가열되어 전하를 띄는 이온과 전자로 분리된 물질의 네 가지 상태 중 하나로 우주 전기추진 뿐만 아니라 반도체 및 디스플레이 제조공정과 살균장치 등에 널리 활용되고 있다.
우리 대학 원자력및양자공학과 최원호 교수 연구팀이 인공위성이나 우주탐사선의 엔진인 홀 전기 추력기(홀추력기, Hall thruster)의 추력 성능을 높은 정확도로 예측할 수 있는 인공지능 기법을 개발했다고 3일 밝혔다.
홀추력기는 연비가 높아 적은 추진제(연료)를 사용하고도 위성이나 우주선을 크게 가속할 수 있으며, 소모 전력 대비 큰 추력을 발생시킬 수 있다. 이러한 장점을 바탕으로, 추진제 절약이 중요한 우주 환경에서 군집위성의 편대비행 유지, 우주쓰레기 감축을 위한 궤도이탈 기동, 혜성이나 화성 탐사와 같은 심우주 탐사를 위한 추진력 제공 등 다양한 임무에 폭넓게 활용되고 있다.
최근 뉴스페이스 시대에 접어들어 우주산업이 확장됨에 따라 우주 임무가 다양해지고 있고 이에 맞는 홀추력기 수요가 증가하고 있다. 각각의 고유한 임무에 최적화된 고효율 홀추력기를 신속하게 개발하기 위해서는 설계단계에서부터 추력기의 성능을 정확하게 예측하는 기법이 필수적이다.
그러나 기존의 방식들은 홀추력기 내에서 복잡하게 일어나는 플라즈마 현상을 정밀하게 다루지 못하거나, 특정 조건에 한정돼, 성능 예측 정확도가 낮은 한계가 있었다.
연구팀은 홀추력기의 설계, 제작, 시험의 반복 작업에 걸리는 시간과 비용을 획기적으로 줄이는 인공지능을 기반으로 한 정확도가 높은 추력기 성능 예측기법을 개발했다.
2003년부터 국내에서 전기추력기 개발 연구를 처음으로 시작해 관련 연구개발을 주도하고 있는 최원호 교수팀은 자체적으로 개발한 전기추력기 전산 해석 도구를 활용해 생성한 18,000개의 홀추력기 학습데이터를 기반으로 인공신경망 앙상블 구조를 도입해 추력 성능 예측에 적용했다.
양질의 학습데이터를 확보하기 위해 개발된 전산 해석 도구는 플라즈마 물리 현상과 추력 성능을 모델링한다. 전산 해석 도구의 정확성은, 연구팀이 국내 최초로 개발한 10개의 홀추력기로 수행된 100여 개의 실험 데이터와 비교해 평균오차가 10% 이내로 정확도가 높은 것으로 검증됐다.
학습된 인공신경망 앙상블 모델은 홀추력기의 설계 변수에 따라 높은 정확도로 단지 수초 내로 짧은 시간 안에 추력기 성능을 예측할 수 있는 디지털트윈 모델로 작동한다.
특히 기존에 알려진 스케일링 법칙으로는 분석하기 어려웠던 연료 유량이나 자기장과 같은 설계 변수에 따른 추력과 방전전류와 같은 성능지표 변화를 상세히 분석할 수 있다.
연구팀은 이번에 개발한 인공신경망 모델이 자체 개발한 700W급 및 1kW급 홀추력기에서 평균오차 5% 이내, 미 공군연구소에서 개발한 5kW급 고전력 홀추력기에 대해 평균오차 9% 이내의 정확도를 보여주었다. 이번 연구로 개발한 인공지능 예측기법이 다양한 전력 크기의 홀추력기에 폭넓게 적용할 수 있는 것을 입증했다.
최원호 교수는 “연구팀에서 개발한 인공지능 기반 성능 예측기법은 정확도가 높아 인공위성과 우주선의 엔진인 홀추력기의 추력성능 분석과 고효율 저전력 홀추력기 개발에 이미 활용되고 있다. 이 인공지능 기법은 홀추력기 뿐만 아니라 반도체, 표면 처리 및 코팅 등 다양한 산업에서 활용되는 이온빔 소스의 연구개발에도 접목될 수 있다”라고 밝혔다.
또한, 최교수는 “연구팀의 실험실 창업기업으로 전기추진 전문기업인 코스모비㈜와 함께 인공지능 기법을 사용해 개발한 큐브위성용 홀추력기는 올해 11월에 예정된 누리호 4차 발사에서 3U(30x10x10 cm) 큐브위성인 K-HERO에 탑재돼 우주에서 성능 검증을 진행할 예정”이라고 설명했다.
원자력및양자공학과(우주탐사공학학제전공) 박재홍 박사과정 학생이 제1 저자로 참여한 이번 연구 결과는 국제적으로 저명한 인공지능 다학제 학술지인 ‘어드밴스드 인텔리전트 시스템(Advanced Intelligent Systems)’에 2024년 12월 25일에 온라인 게재됐으며, 저널 표지논문(front cover)으로 채택돼 혁신성을 인정받았다.
이번 연구는 한국연구재단 스페이스파이오니어사업(200mN급 고추력 전기추진시스템 개발)의 지원을 받아 수행됐다.
(논문 제목: Predicting Performance of Hall Effect Ion Source Using Machine Learning, DOI: https://doi.org/10.1002/aisy.202400555)
2025.02.03 조회수 4675 -
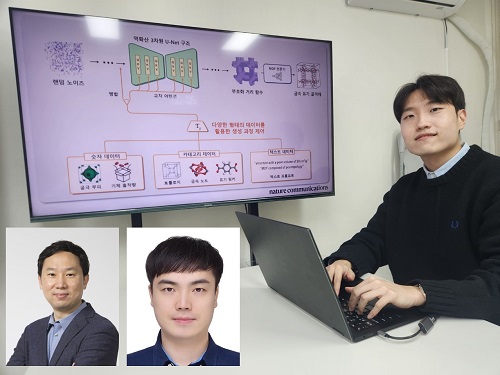 원하는 소재 개발 인공지능 모퓨전(MOFFUSION)으로
최근 생성형 인공지능은 텍스트, 이미지, 비디오 생성 등 다양한 분야에서 널리 사용되고 있지만, 소재 개발 분야에서는 아직 충분히 활용되지 못하고 있다. 이러한 상황에서 KAIST 연구진이 구조적 복잡성을 지닌 다공성 소재를 생성하는 인공지능 모델을 개발하여, 사용자가 원하는 특성의 소재를 선택적으로 생성할 수 있게 되었다.
우리 대학 생명화학공학과 김지한 교수 연구팀이 원하는 물성을 가진 금속 유기 골격체(Metal-Organic Frameworks, MOF)를 생성하는 인공지능 모델을 개발했다고 23일 밝혔다.
김지한 교수 연구팀이 개발한 생성형 인공지능 모델인 모퓨전(MOFFUSION)은 금속 유기 골격체의 구조를 보다 효율적으로 표현하기 위해, 이들의 공극 구조를 3차원 모델링 기법을 활용해 나타내는 혁신적인 접근 방식을 채택했다. 이 기법을 통해 기존 모델들에서 보고된 낮은 구조 생성 효율을 81.7%로 크게 향상시켰다.
또한, 모퓨전은 생성 과정에서 사용자가 원하는 특성을 다양한 형태로 표현하여 인공지능 모델에 입력할 수 있는 특징이 있다. 연구진은 사용자가 원하는 물성을 숫자, 카테고리, 텍스트 등 다양한 형태로 입력할 수 있으며, 데이터 형태와 관계없이 높은 생성 성능을 보임을 확인했다.
예를 들어, 사용자가 생성하고자 하는 물질의 특성값을 텍스트 형태(예:“30 g/L의 수소 흡착량을 갖는 구조”)로 모델에 입력하면, 모델은 이에 상응하는 물질을 선택적으로 생성한다. 이러한 특징은 소재 개발에 있어 인공지능 모델의 활용성과 편의성을 크게 개선하는 요소로 작용한다.
김지한 교수는 “원하는 물성의 소재를 개발하는 것은 소재 분야의 가장 큰 목표이며 오랜 연구 주제”라며, “연구팀이 개발한 기술은 인공지능을 활용한 다공성 소재 개발에 있어 큰 발전을 이뤘으며, 앞으로 해당 분야에서 생성형 인공지능의 도입을 촉진할 것”이라고 말했다.
우리 대학 생명화학공학과 박준길 박사, 이유한 박사가 공동 제1 저자로 참여한 이번 연구 결과는 국제 학술지 `네이처 커뮤니케이션즈(Nature Communications)'에 지난 1월 2일 게재됐다. (논문명 : Multi-modal conditional diffusion model using signed distance functions for metal-organic frameworks generation) (https://doi.org/10.1038/s41467-024-55390-9)
한편 이번 연구는 과학기술정보통신부의 탑-티어 연구기관 간 협력 플랫폼 구축 및 공동연구 지원사업, 나노 및 소재기술 개발사업, 그리고 한국연구재단 (NRF) 중견연구자 지원사업의 지원을 받아 수행됐다.
2025.01.23 조회수 5026
원하는 소재 개발 인공지능 모퓨전(MOFFUSION)으로
최근 생성형 인공지능은 텍스트, 이미지, 비디오 생성 등 다양한 분야에서 널리 사용되고 있지만, 소재 개발 분야에서는 아직 충분히 활용되지 못하고 있다. 이러한 상황에서 KAIST 연구진이 구조적 복잡성을 지닌 다공성 소재를 생성하는 인공지능 모델을 개발하여, 사용자가 원하는 특성의 소재를 선택적으로 생성할 수 있게 되었다.
우리 대학 생명화학공학과 김지한 교수 연구팀이 원하는 물성을 가진 금속 유기 골격체(Metal-Organic Frameworks, MOF)를 생성하는 인공지능 모델을 개발했다고 23일 밝혔다.
김지한 교수 연구팀이 개발한 생성형 인공지능 모델인 모퓨전(MOFFUSION)은 금속 유기 골격체의 구조를 보다 효율적으로 표현하기 위해, 이들의 공극 구조를 3차원 모델링 기법을 활용해 나타내는 혁신적인 접근 방식을 채택했다. 이 기법을 통해 기존 모델들에서 보고된 낮은 구조 생성 효율을 81.7%로 크게 향상시켰다.
또한, 모퓨전은 생성 과정에서 사용자가 원하는 특성을 다양한 형태로 표현하여 인공지능 모델에 입력할 수 있는 특징이 있다. 연구진은 사용자가 원하는 물성을 숫자, 카테고리, 텍스트 등 다양한 형태로 입력할 수 있으며, 데이터 형태와 관계없이 높은 생성 성능을 보임을 확인했다.
예를 들어, 사용자가 생성하고자 하는 물질의 특성값을 텍스트 형태(예:“30 g/L의 수소 흡착량을 갖는 구조”)로 모델에 입력하면, 모델은 이에 상응하는 물질을 선택적으로 생성한다. 이러한 특징은 소재 개발에 있어 인공지능 모델의 활용성과 편의성을 크게 개선하는 요소로 작용한다.
김지한 교수는 “원하는 물성의 소재를 개발하는 것은 소재 분야의 가장 큰 목표이며 오랜 연구 주제”라며, “연구팀이 개발한 기술은 인공지능을 활용한 다공성 소재 개발에 있어 큰 발전을 이뤘으며, 앞으로 해당 분야에서 생성형 인공지능의 도입을 촉진할 것”이라고 말했다.
우리 대학 생명화학공학과 박준길 박사, 이유한 박사가 공동 제1 저자로 참여한 이번 연구 결과는 국제 학술지 `네이처 커뮤니케이션즈(Nature Communications)'에 지난 1월 2일 게재됐다. (논문명 : Multi-modal conditional diffusion model using signed distance functions for metal-organic frameworks generation) (https://doi.org/10.1038/s41467-024-55390-9)
한편 이번 연구는 과학기술정보통신부의 탑-티어 연구기관 간 협력 플랫폼 구축 및 공동연구 지원사업, 나노 및 소재기술 개발사업, 그리고 한국연구재단 (NRF) 중견연구자 지원사업의 지원을 받아 수행됐다.
2025.01.23 조회수 5026 -
 스스로 학습·수정하는 뉴로모픽 반도체칩 개발
기존 컴퓨터 시스템은 데이터 처리 장치와 저장 장치가 분리돼 있어, 인공지능처럼 복잡한 데이터를 처리하기에는 효율적이지 않다. KAIST 연구팀은 우리 뇌의 정보 처리 방식과 유사한 멤리스터 기반 통합 시스템을 개발했다. 이제 원격 클라우드 서버에 의존하지 않고 의심스러운 활동을 즉시 인식하는 스마트 보안 카메라부터 건강 데이터를 실시간으로 분석할 수 있는 의료기기까지 다양한 분야에 적용될 수 있게 되었다.
우리 대학 전기및전자공학부 최신현 교수, 윤영규 교수 공동연구팀이 스스로 학습하고 오류를 수정할 수 있는 차세대 뉴로모픽 반도체 기반 초소형 컴퓨팅 칩을 개발했다고 17일 밝혔다.
연구팀이 개발한 이 컴퓨팅 칩의 특별한 점은 기존 뉴로모픽 소자에서 해결이 어려웠던 비이상적 특성에서 발생하는 오류를 스스로 학습하고 수정할 수 있다는 것이다. 예를 들어, 영상 스트림을 처리할 때 칩은 움직이는 물체를 배경에서 자동으로 분리하는 법을 학습하며 시간이 지날수록 이 작업을 더 잘 수행하게 된다.
이러한 자가 학습 능력은 실시간 영상 처리에서 이상적인 컴퓨터 시뮬레이션에 견줄 만한 정확도를 달성하며 입증됐다. 연구팀의 주요성과는 뇌와 유사한 구성 요소의 개발을 넘어, 신뢰성과 실용성을 모두 갖춘 시스템으로 완성한 것에 있다.
연구팀은 세계 최초로 즉각적인 환경 변화에 적응할 수 있는 멤리스터 기반 통합 시스템을 개발하며, 기존 기술의 한계를 극복하는 혁신적인 해결책을 제시했다.
이 혁신의 핵심에는 멤리스터(memristor)*라고 불리는 차세대 반도체 소자가 있다. 이 소자의 가변 저항 특성은 신경망의 시냅스 역할을 대체할 수 있게 되고, 이를 활용해 우리 뇌세포처럼 데이터 저장 및 연산을 동시에 수행할 수 있다.
*멤리스터: 메모리(memory)와 저항(resistor)의 합성어로 두 단자 사이로 과거에 흐른 전하량과 방향에 따라 저항값이 결정되는 차세대 전기소자
연구팀은 저항 변화를 정밀하게 제어할 수 있는 고신뢰성 멤리스터를 설계하고, 자가 학습을 통해 복잡한 보정 과정을 배제한 효율적인 시스템을 개발했다. 이번 연구는 실시간 학습과 추론을 지원하는 차세대 뉴로모픽 반도체 기반 통합 시스템의 상용화 가능성을 실험적으로 검증했다는 점에서 중요한 의미를 가진다.
이 기술은 일상적인 기기에서 인공지능을 사용하는 방식을 혁신하여 AI 작업 처리를 위해 원격 클라우드 서버에 의존하지 않고 로컬에서 처리할 수 있게 되어, 더 빠르고 사생활 보호가 강화되며 에너지 효율성이 높아질 것이다.
이 기술 개발을 주도한 KAIST 정학천 연구원과 한승재 연구원은 “이 시스템은 책상과 자료 캐비닛을 오가며 일하는 대신 모든 것이 손이 닿는 곳에 있는 스마트 작업 공간과 같다. 이는 모든 것이 한 곳에서 처리돼 매우 효율적인 우리 뇌의 정보 처리 방식과 유사하다”고 설명했다.
전기및전자공학부 정학천 석박통합과정생과 한승재 석박사통합과정생이 제 1저자로 연구에 참여했으며 국제 학술지 `네이처 일렉트로닉스 (Nature Electronics)'에 2025년 1월 8일 자로 온라인 게재됐다.
(논문 제목: Self-supervised video processing with self-calibration on an analogue computing platform based on a selector-less memristor array, https://doi.org/10.1038/s41928-024-01318-6)
이번 연구는 한국연구재단의 차세대지능형반도체기술개발사업, 우수신진연구사업, PIM인공지능반도체핵심기술개발사업, 정보통신기획평가원의 한국전자통신연구원연구개발지원사업의 지원을 받아 수행됐다.
2025.01.22 조회수 4663
스스로 학습·수정하는 뉴로모픽 반도체칩 개발
기존 컴퓨터 시스템은 데이터 처리 장치와 저장 장치가 분리돼 있어, 인공지능처럼 복잡한 데이터를 처리하기에는 효율적이지 않다. KAIST 연구팀은 우리 뇌의 정보 처리 방식과 유사한 멤리스터 기반 통합 시스템을 개발했다. 이제 원격 클라우드 서버에 의존하지 않고 의심스러운 활동을 즉시 인식하는 스마트 보안 카메라부터 건강 데이터를 실시간으로 분석할 수 있는 의료기기까지 다양한 분야에 적용될 수 있게 되었다.
우리 대학 전기및전자공학부 최신현 교수, 윤영규 교수 공동연구팀이 스스로 학습하고 오류를 수정할 수 있는 차세대 뉴로모픽 반도체 기반 초소형 컴퓨팅 칩을 개발했다고 17일 밝혔다.
연구팀이 개발한 이 컴퓨팅 칩의 특별한 점은 기존 뉴로모픽 소자에서 해결이 어려웠던 비이상적 특성에서 발생하는 오류를 스스로 학습하고 수정할 수 있다는 것이다. 예를 들어, 영상 스트림을 처리할 때 칩은 움직이는 물체를 배경에서 자동으로 분리하는 법을 학습하며 시간이 지날수록 이 작업을 더 잘 수행하게 된다.
이러한 자가 학습 능력은 실시간 영상 처리에서 이상적인 컴퓨터 시뮬레이션에 견줄 만한 정확도를 달성하며 입증됐다. 연구팀의 주요성과는 뇌와 유사한 구성 요소의 개발을 넘어, 신뢰성과 실용성을 모두 갖춘 시스템으로 완성한 것에 있다.
연구팀은 세계 최초로 즉각적인 환경 변화에 적응할 수 있는 멤리스터 기반 통합 시스템을 개발하며, 기존 기술의 한계를 극복하는 혁신적인 해결책을 제시했다.
이 혁신의 핵심에는 멤리스터(memristor)*라고 불리는 차세대 반도체 소자가 있다. 이 소자의 가변 저항 특성은 신경망의 시냅스 역할을 대체할 수 있게 되고, 이를 활용해 우리 뇌세포처럼 데이터 저장 및 연산을 동시에 수행할 수 있다.
*멤리스터: 메모리(memory)와 저항(resistor)의 합성어로 두 단자 사이로 과거에 흐른 전하량과 방향에 따라 저항값이 결정되는 차세대 전기소자
연구팀은 저항 변화를 정밀하게 제어할 수 있는 고신뢰성 멤리스터를 설계하고, 자가 학습을 통해 복잡한 보정 과정을 배제한 효율적인 시스템을 개발했다. 이번 연구는 실시간 학습과 추론을 지원하는 차세대 뉴로모픽 반도체 기반 통합 시스템의 상용화 가능성을 실험적으로 검증했다는 점에서 중요한 의미를 가진다.
이 기술은 일상적인 기기에서 인공지능을 사용하는 방식을 혁신하여 AI 작업 처리를 위해 원격 클라우드 서버에 의존하지 않고 로컬에서 처리할 수 있게 되어, 더 빠르고 사생활 보호가 강화되며 에너지 효율성이 높아질 것이다.
이 기술 개발을 주도한 KAIST 정학천 연구원과 한승재 연구원은 “이 시스템은 책상과 자료 캐비닛을 오가며 일하는 대신 모든 것이 손이 닿는 곳에 있는 스마트 작업 공간과 같다. 이는 모든 것이 한 곳에서 처리돼 매우 효율적인 우리 뇌의 정보 처리 방식과 유사하다”고 설명했다.
전기및전자공학부 정학천 석박통합과정생과 한승재 석박사통합과정생이 제 1저자로 연구에 참여했으며 국제 학술지 `네이처 일렉트로닉스 (Nature Electronics)'에 2025년 1월 8일 자로 온라인 게재됐다.
(논문 제목: Self-supervised video processing with self-calibration on an analogue computing platform based on a selector-less memristor array, https://doi.org/10.1038/s41928-024-01318-6)
이번 연구는 한국연구재단의 차세대지능형반도체기술개발사업, 우수신진연구사업, PIM인공지능반도체핵심기술개발사업, 정보통신기획평가원의 한국전자통신연구원연구개발지원사업의 지원을 받아 수행됐다.
2025.01.22 조회수 4663 -
 KAIST 설명가능 인공지능연구센터, 플러그앤플레이 방식의 설명가능 인공지능 프레임워크 공개
KAIST 설명가능 인공지능연구센터(센터장 최재식 교수)는 별도의 복잡한 설정이나 전문 지식 없이도 손쉽게 AI모델에 대한 설명성을 제공할 수 있는 플러그앤플레이(Plug-and-Play) 방식의 설명가능 인공지능 프레임워크를 개발해, 이를 27일 오픈소스로 공개했다.
설명가능 인공지능(Explainable AI, 이하 XAI)이란 AI 시스템의 결과에 영향을 미치는 주요 요소를 사람이 이해할 수 있는 형태로 설명해주는 제반 기술을 말한다. 최근 딥러닝 모델과 같이 내부 의사 결정 프로세스가 불투명한 블랙박스 AI 모델에 대한 의존도가 커지면서 설명가능 인공지능 분야에 대한 관심과 연구가 증가했다. 그러나 지금까지는 연구자와 기업 실무자들이 설명가능 인공지능 기술을 활용하는 것이 몇 가지 이유로 쉽지 않았다. 우선, 딥러닝 모델의 유형별로 적용 가능한 설명 알고리즘들이 서로 달라서 해당 모델에 적용할 수 있는 설명 알고리즘이 무엇인지 알기 위해서는 XAI에 대해 어느 정도 사전지식이 필요하기 때문이다. 두번째로, 대상 모델에 적용할 수 있는 설명 알고리즘을 파악하더라도, 각 알고리즘마다 다른 하이퍼 파라미터를 어떻게 설정해야 최적의 설명 결과를 얻을 수 있을지 이해하는 것은 여전히 어려운 과제이다. 세번째로는 적용된 다수의 설명 알고리즘들 중에 어떤 알고리즘이 가장 정확하고 신뢰할 수 있는 것인지를 정량적으로 평가하기 위해서 또다른 툴을 이용해야 하는 번거로운 과정이 뒤따라야 했다. 이번에 오픈소스로 공개된 플러그앤플레이 설명가능 인공지능 프레임워크(Plug-and-Play XAI Framework, 이하 PnPXAI 프레임워크)는 이러한 어려움을 해결하고자 개발되었으며, AI의 신뢰성이 중요한 다양한 AI시스템 연구개발 현장에서 유용한 도구로 활용될 것으로 기대된다.
PnPXAI 프레임워크는 적용 가능한 설명알고리즘을 자동으로 추천하기 위해 모델 구조를 인식하는 탐지모듈(Detector)과 적용가능한 설명 알고리즘을 선별하는 추천모듈(Recommender), 설명 알고리즘을 최적화하는 최적화모듈(Optimizer) 및 설명 결과 평가모듈(Evaluator)로 구성되어 있다. 사용자는 ‘자동설명(Auto Explanation)’ 모드에서 대상 모델과 데이터만 입력하면 설명 알고리즘의 시각적 결과(히트맵 또는 모델 결과에 영향을 끼친 중요한 속성들)와 설명의 정확도를 한번에 확인할 수 있다. 사용자들은 자동설명 모드를 통해 XAI에 대한 기본지식과 사용법을 숙지한 이후에는 프레임워크에 포함된 설명 알고리즘과 평가지표를 원하는 방식으로 자유롭게 활용할 수 있다.
현재 프레임워크에는 이미지, 텍스트, 시계열, 표 데이터 등 다양한 데이터유형을 지원하는 설명 알고리즘들이 제공되고 있다. 특히, 서울대학교(2세부 연구책임자 한보형교수)와 협력을 통해 뇌MRI 기반 알츠하이머병 진단모델에 대한 반예제 설명 알고리즘을 지원하였고, 서강대학교(3세부 연구책임자 구명완교수)와 공동연구를 통해 마비말장애 진단모델에 PnPXAI 프레임워크의 설명 알고리즘을 적용하여 AI 기반 의사결정지원 시스템에서 설명성을 성공적으로 구현하기도 했다. 또한, 한국전자통신연구원(4세부 연구책임자 배경만박사)에서 개발한 LLM(대규모언어모델) 생성결과의 사실성을 검증하는 알고리즘을 프레임워크에 통합하는 등 지원 범위를 지속적으로 확장하고 있다.
KAIST 설명가능 인공지능연구센터 최재식 센터장은 “기존 설명가능 인공지능 도구들의 한계를 해결하고, 다양한 도메인에서 실질적으로 활용하기 쉬운 도구를 제공하기 위해 국내 최고의 연구진과 수년간 협력한 성과”라며, “이 프레임워크 공개를 통해 AI 기술의 신뢰성을 높여 상용화에 기여하는 것은 물론, 우리 연구센터가 설명가능 인공지능 분야의 글로벌 연구 생태계를 선도하는 중요한 발판을 마련했다는 점에서 의의가 있다”고 밝혔다.
PnPXAI 프레임워크는 현재 국내 및 국제특허 출원을 완료했으며, Apache 2.0 라이선스를 준수하는 경우 누구나 깃허브 페이지[링크]를 통해 사용할 수 있다. 한편, 이 연구는 2022년도 정부(과학기술정보통신부)의 재원으로 정보통신기획평가원의 지원을 받아 수행된 연구이다. (No. RS-2022-II220984, 플러그앤플레이 방식으로 설명가능성을 제공하는 인공지능 기술 개발 및 인공지능 시스템에 대한 설명 제공 검증)
2024.12.27 조회수 4634
KAIST 설명가능 인공지능연구센터, 플러그앤플레이 방식의 설명가능 인공지능 프레임워크 공개
KAIST 설명가능 인공지능연구센터(센터장 최재식 교수)는 별도의 복잡한 설정이나 전문 지식 없이도 손쉽게 AI모델에 대한 설명성을 제공할 수 있는 플러그앤플레이(Plug-and-Play) 방식의 설명가능 인공지능 프레임워크를 개발해, 이를 27일 오픈소스로 공개했다.
설명가능 인공지능(Explainable AI, 이하 XAI)이란 AI 시스템의 결과에 영향을 미치는 주요 요소를 사람이 이해할 수 있는 형태로 설명해주는 제반 기술을 말한다. 최근 딥러닝 모델과 같이 내부 의사 결정 프로세스가 불투명한 블랙박스 AI 모델에 대한 의존도가 커지면서 설명가능 인공지능 분야에 대한 관심과 연구가 증가했다. 그러나 지금까지는 연구자와 기업 실무자들이 설명가능 인공지능 기술을 활용하는 것이 몇 가지 이유로 쉽지 않았다. 우선, 딥러닝 모델의 유형별로 적용 가능한 설명 알고리즘들이 서로 달라서 해당 모델에 적용할 수 있는 설명 알고리즘이 무엇인지 알기 위해서는 XAI에 대해 어느 정도 사전지식이 필요하기 때문이다. 두번째로, 대상 모델에 적용할 수 있는 설명 알고리즘을 파악하더라도, 각 알고리즘마다 다른 하이퍼 파라미터를 어떻게 설정해야 최적의 설명 결과를 얻을 수 있을지 이해하는 것은 여전히 어려운 과제이다. 세번째로는 적용된 다수의 설명 알고리즘들 중에 어떤 알고리즘이 가장 정확하고 신뢰할 수 있는 것인지를 정량적으로 평가하기 위해서 또다른 툴을 이용해야 하는 번거로운 과정이 뒤따라야 했다. 이번에 오픈소스로 공개된 플러그앤플레이 설명가능 인공지능 프레임워크(Plug-and-Play XAI Framework, 이하 PnPXAI 프레임워크)는 이러한 어려움을 해결하고자 개발되었으며, AI의 신뢰성이 중요한 다양한 AI시스템 연구개발 현장에서 유용한 도구로 활용될 것으로 기대된다.
PnPXAI 프레임워크는 적용 가능한 설명알고리즘을 자동으로 추천하기 위해 모델 구조를 인식하는 탐지모듈(Detector)과 적용가능한 설명 알고리즘을 선별하는 추천모듈(Recommender), 설명 알고리즘을 최적화하는 최적화모듈(Optimizer) 및 설명 결과 평가모듈(Evaluator)로 구성되어 있다. 사용자는 ‘자동설명(Auto Explanation)’ 모드에서 대상 모델과 데이터만 입력하면 설명 알고리즘의 시각적 결과(히트맵 또는 모델 결과에 영향을 끼친 중요한 속성들)와 설명의 정확도를 한번에 확인할 수 있다. 사용자들은 자동설명 모드를 통해 XAI에 대한 기본지식과 사용법을 숙지한 이후에는 프레임워크에 포함된 설명 알고리즘과 평가지표를 원하는 방식으로 자유롭게 활용할 수 있다.
현재 프레임워크에는 이미지, 텍스트, 시계열, 표 데이터 등 다양한 데이터유형을 지원하는 설명 알고리즘들이 제공되고 있다. 특히, 서울대학교(2세부 연구책임자 한보형교수)와 협력을 통해 뇌MRI 기반 알츠하이머병 진단모델에 대한 반예제 설명 알고리즘을 지원하였고, 서강대학교(3세부 연구책임자 구명완교수)와 공동연구를 통해 마비말장애 진단모델에 PnPXAI 프레임워크의 설명 알고리즘을 적용하여 AI 기반 의사결정지원 시스템에서 설명성을 성공적으로 구현하기도 했다. 또한, 한국전자통신연구원(4세부 연구책임자 배경만박사)에서 개발한 LLM(대규모언어모델) 생성결과의 사실성을 검증하는 알고리즘을 프레임워크에 통합하는 등 지원 범위를 지속적으로 확장하고 있다.
KAIST 설명가능 인공지능연구센터 최재식 센터장은 “기존 설명가능 인공지능 도구들의 한계를 해결하고, 다양한 도메인에서 실질적으로 활용하기 쉬운 도구를 제공하기 위해 국내 최고의 연구진과 수년간 협력한 성과”라며, “이 프레임워크 공개를 통해 AI 기술의 신뢰성을 높여 상용화에 기여하는 것은 물론, 우리 연구센터가 설명가능 인공지능 분야의 글로벌 연구 생태계를 선도하는 중요한 발판을 마련했다는 점에서 의의가 있다”고 밝혔다.
PnPXAI 프레임워크는 현재 국내 및 국제특허 출원을 완료했으며, Apache 2.0 라이선스를 준수하는 경우 누구나 깃허브 페이지[링크]를 통해 사용할 수 있다. 한편, 이 연구는 2022년도 정부(과학기술정보통신부)의 재원으로 정보통신기획평가원의 지원을 받아 수행된 연구이다. (No. RS-2022-II220984, 플러그앤플레이 방식으로 설명가능성을 제공하는 인공지능 기술 개발 및 인공지능 시스템에 대한 설명 제공 검증)
2024.12.27 조회수 4634 -
 바이오 경로 이미지 분석하는 AI 최초 개발
유전자, 단백질, 대사물질 등 복잡한 정보를 표현하는 바이오 경로 이미지는 중요한 연구 결과를 내포하고 있지만, 이미지 기반 정보 추출에 대해 그동안 충분한 연구가 이뤄지지 않았다. 이에 우리 연구진은 바이오 경로 정보를 자동으로 추출할 수 있는 인공지능 프레임워크를 개발했다.
우리 대학 생명화학공학과 김현욱 교수 연구팀이 바이오 경로 이미지에서 유전자와 대사물질 정보를 자동으로 추출하는 기계학습 기반의 ‘바이오 경로 정보 추출 프레임워크(이하 EBPI, Extraction of Biological Pathway Information)’를 개발했다고 28일 밝혔다.
연구팀이 개발한 EBPI는 문헌에서 추출한 이미지 속의 화살표와 텍스트를 인식하고, 이를 기반으로 바이오 경로를 편집 가능한 표의 형태로 재구성한다. 객체 감지 모델 등의 기계학습을 사용해 경로 이미지 내 화살표의 위치와 방향을 감지하고, 이미지 속 텍스트를 유전자, 단백질, 대사물질로 분류한다. 그 후 추출된 정보를 통합해 경로 정보를 표 형식으로 제공한다.
연구팀은 74,853편의 논문에서 추출한 바이오 경로 이미지와 기존 수작업으로 작성된 경로 지도를 비교하며 EBPI의 성능을 검증했다. 그 결과, 높은 정확도로 바이오 경로 정보가 자동으로 추출됐음을 확인했다.
EBPI를 사용해 대표적인 바이오 경로 데이터베이스에 포함되지 않은 생화학 반응 정보를 대량의 문헌 내 바이오 경로 이미지로부터 추출하는 데에도 성공했다.
다양한 산업적 가치를 지닌 대사물질들의 생합성 관련 문헌을 EBPI로 분석한 결과, 문헌에서는 보고가 됐지만, 기존 데이터베이스에서는 누락된 생화학 반응들이 확인된 것이다. 화학산업에서 다양한 응용분야를 갖는 1,4-부탄디올, 2-메틸부티르산, 하이드록시티로솔, 레불린산 및 발레로락탐의 생합성 경로를 예시로 이러한 발견을 제시했다.
연구를 총괄한 김현욱 교수는 “이번 연구에서 개발된 EBPI는 대규모 문헌 데이터 분석에 있어 중요한 도구가 될 것이며 생명공학, 대사공학 및 합성생물학 분야에서 바이오 경로 이미지를 AI로 분석하는 최초의 사례로, 관련 연구의 실험 디자인 및 분석 시 유용하게 활용될 수 있을 것”이라고 밝혔다.
생명화학공학과 권문수 박사과정생과 이준규 박사과정생이 공동 제1 저자인 이번 연구는 대사공학 및 합성생물학 분야의 대표적 국제학술지인 대사공학(Metabolic Engineering, JCR 분야 상위 10% 이내)에 11월호에 게재됐다.
※ 논문명 : A machine learning framework for extracting information from biological pathway images in the literature
※ 저자 정보 : 권문수(한국과학기술원, 공동 제1 저자), 이준규(한국과학기술원, 공동 제1 저자), 김현욱(한국과학기술원, 교신저자) 포함 총 3명
한편 이번 연구는 과학기술정보통신부 한국연구재단 및 농촌진흥청의 농업미생물사업단의 지원을 받아 수행됐다.
2024.11.28 조회수 5418
바이오 경로 이미지 분석하는 AI 최초 개발
유전자, 단백질, 대사물질 등 복잡한 정보를 표현하는 바이오 경로 이미지는 중요한 연구 결과를 내포하고 있지만, 이미지 기반 정보 추출에 대해 그동안 충분한 연구가 이뤄지지 않았다. 이에 우리 연구진은 바이오 경로 정보를 자동으로 추출할 수 있는 인공지능 프레임워크를 개발했다.
우리 대학 생명화학공학과 김현욱 교수 연구팀이 바이오 경로 이미지에서 유전자와 대사물질 정보를 자동으로 추출하는 기계학습 기반의 ‘바이오 경로 정보 추출 프레임워크(이하 EBPI, Extraction of Biological Pathway Information)’를 개발했다고 28일 밝혔다.
연구팀이 개발한 EBPI는 문헌에서 추출한 이미지 속의 화살표와 텍스트를 인식하고, 이를 기반으로 바이오 경로를 편집 가능한 표의 형태로 재구성한다. 객체 감지 모델 등의 기계학습을 사용해 경로 이미지 내 화살표의 위치와 방향을 감지하고, 이미지 속 텍스트를 유전자, 단백질, 대사물질로 분류한다. 그 후 추출된 정보를 통합해 경로 정보를 표 형식으로 제공한다.
연구팀은 74,853편의 논문에서 추출한 바이오 경로 이미지와 기존 수작업으로 작성된 경로 지도를 비교하며 EBPI의 성능을 검증했다. 그 결과, 높은 정확도로 바이오 경로 정보가 자동으로 추출됐음을 확인했다.
EBPI를 사용해 대표적인 바이오 경로 데이터베이스에 포함되지 않은 생화학 반응 정보를 대량의 문헌 내 바이오 경로 이미지로부터 추출하는 데에도 성공했다.
다양한 산업적 가치를 지닌 대사물질들의 생합성 관련 문헌을 EBPI로 분석한 결과, 문헌에서는 보고가 됐지만, 기존 데이터베이스에서는 누락된 생화학 반응들이 확인된 것이다. 화학산업에서 다양한 응용분야를 갖는 1,4-부탄디올, 2-메틸부티르산, 하이드록시티로솔, 레불린산 및 발레로락탐의 생합성 경로를 예시로 이러한 발견을 제시했다.
연구를 총괄한 김현욱 교수는 “이번 연구에서 개발된 EBPI는 대규모 문헌 데이터 분석에 있어 중요한 도구가 될 것이며 생명공학, 대사공학 및 합성생물학 분야에서 바이오 경로 이미지를 AI로 분석하는 최초의 사례로, 관련 연구의 실험 디자인 및 분석 시 유용하게 활용될 수 있을 것”이라고 밝혔다.
생명화학공학과 권문수 박사과정생과 이준규 박사과정생이 공동 제1 저자인 이번 연구는 대사공학 및 합성생물학 분야의 대표적 국제학술지인 대사공학(Metabolic Engineering, JCR 분야 상위 10% 이내)에 11월호에 게재됐다.
※ 논문명 : A machine learning framework for extracting information from biological pathway images in the literature
※ 저자 정보 : 권문수(한국과학기술원, 공동 제1 저자), 이준규(한국과학기술원, 공동 제1 저자), 김현욱(한국과학기술원, 교신저자) 포함 총 3명
한편 이번 연구는 과학기술정보통신부 한국연구재단 및 농촌진흥청의 농업미생물사업단의 지원을 받아 수행됐다.
2024.11.28 조회수 5418 -
 반도체 정밀 공정 흐린 영상 복원 가능하다
생물학 연구에 사용되는 형광 현미경이나 반도체 산업에 사용되는 주사전자현미경의 공통점은 불안정성으로 인해 흐려진 영상(블러, blur)을 보정하는 과정이 반드시 필요하다는 점이다. 우리 연구진이 굉장히 강한 잡음에 의해 손상된 왜곡 영상에 대해 적응형 필터와 생성형 인공지능 모델을 융합해 영상을 복원하는 데 성공했다.
우리 대학 바이오및뇌공학과 장무석 교수 연구팀이 삼성전자 DS부문 반도체연구소 차세대공정개발실과 공동 연구를 통해 왜곡 및 강한 잡음이 존재하는 의료·산업 영상을 복원하는 기술을 개발했다고 26일 밝혔다.
스마트폰 카메라 사진에 영상의 흐림·왜곡이 생겼을 때 보정하는 문제를 디컨볼루션(deconvolution) 또는 디블러링(deblurring)이라고 하며, 흐려진 영상 정보만 이용해 선명한 영상을 복원하는 기술을 블라인드 디컨볼루션(blind deconvolution)이라고 한다. 흥미롭게도 디컨볼루션 문제는 일상뿐만 아니라 생물학 연구, 반도체 산업 등 다양한 분야에서 공통적으로 발생한다.
예를 들어, 형광 현미경은 세포와 분자 수준의 미세 구조를 시각화하기 때문에 측정된 형광 신호는 산란이나 회절, 수차 등의 효과로 인해 흐려지기 때문에 디컨볼루션 기법을 통해 보정하는 과정이 반드시 필요하다.
또한, 반도체 산업에서는 수천 개의 생산 공정 중간에 검사·계측 기술을 통해 발생할 수 있는 미세 공정 오류를 감지하고, 공정 수율 개선을 위한 프로세스 개선 과정에 사용되는 주사전자현미경이 전자 빔의 불안정성으로 인해 영상이 흐려지기 쉬우며, 이를 보정하는 과정이 반드시 필요하다.
연구팀은 이처럼 영상이 흐려지는 원인은 움직임, 빛의 산란, 전자의 불안정성 등과 같이 다양하지만, 공통적으로 ‘영상의 흐려짐을 없앤다’라는 점에서 수학적으로 동일한 접근 방법이 활용될 수 있다고 생각했다.
특히 잡음 수준이 높은 영상의 경우, 영상의 잡음을 효과적으로 억제함과 동시에 블러 효과가 제거된 선명한 영상을 복원하는 과정의 균형을 맞추는 것이 매우 중요하다는 점을 착안했다.
연구팀은 위너 디컨볼루션*을 기반으로 영상을 복원하는 접근법을 개발했다. 이를 적응형 잡음 억제 변수, 영상 생성형 인공지능 모델과 결합해 영상 복원 과정에서 발생할 수 있는 잡음을 억제하고 영상 선명도도 높였다.
*위너 디컨볼루션(Wiener deconvolution)은 왜곡된 영상을 역 필터(inverse filter)를 기반으로 깨끗한 영상으로 복원하는 전통적인 방식임.
연구팀은 잡음 민감도가 높은 주사전자현미경으로부터 측정된 왜곡된 영상으로부터 깨끗하고 초점이 맞는 나노미터 단위의 반도체 구조에 대한 영상을 성공적으로 복원해 냄으로써 반도체 검사·계측에 매우 효과적으로 적용할 수 있음을 실험적으로 증명했다.
바이오및뇌공학과 이찬석 연구원은 “이번 연구를 통해 강한 잡음 속에서 왜곡된 영상을 복원하는 난제를 해결했다ˮ며, 이어 "이번 연구에서는 무작위적 잡음을 극복하는 영상 복원 기술을 개발하는 데에 집중했고, 향후 비균일 영상 복원 및 다양한 손상 형태를 극복하는 영상 복원 기술 개발에 주력할 것이다ˮ라고 밝혔다.
바이오및뇌공학과 이찬석 박사과정이 제1 저자로 참여한 이번 연구는 컴퓨터 비전 분야 최고 학회인 ‘제18회 유럽 컴퓨터 비전 학회(The 18th European Conference on Computer Vision)’ 에서 지난 10월 1일에 이탈리아 밀란에서 발표됐고, Springer Nature에서 출판하는 Lecture Notes in Computer Science의 ECCV 2024 프로시딩 집에 게재될 예정이다. (논문명: Blind image deblurring with noise-robust kernel estimation).
2024.11.26 조회수 4119
반도체 정밀 공정 흐린 영상 복원 가능하다
생물학 연구에 사용되는 형광 현미경이나 반도체 산업에 사용되는 주사전자현미경의 공통점은 불안정성으로 인해 흐려진 영상(블러, blur)을 보정하는 과정이 반드시 필요하다는 점이다. 우리 연구진이 굉장히 강한 잡음에 의해 손상된 왜곡 영상에 대해 적응형 필터와 생성형 인공지능 모델을 융합해 영상을 복원하는 데 성공했다.
우리 대학 바이오및뇌공학과 장무석 교수 연구팀이 삼성전자 DS부문 반도체연구소 차세대공정개발실과 공동 연구를 통해 왜곡 및 강한 잡음이 존재하는 의료·산업 영상을 복원하는 기술을 개발했다고 26일 밝혔다.
스마트폰 카메라 사진에 영상의 흐림·왜곡이 생겼을 때 보정하는 문제를 디컨볼루션(deconvolution) 또는 디블러링(deblurring)이라고 하며, 흐려진 영상 정보만 이용해 선명한 영상을 복원하는 기술을 블라인드 디컨볼루션(blind deconvolution)이라고 한다. 흥미롭게도 디컨볼루션 문제는 일상뿐만 아니라 생물학 연구, 반도체 산업 등 다양한 분야에서 공통적으로 발생한다.
예를 들어, 형광 현미경은 세포와 분자 수준의 미세 구조를 시각화하기 때문에 측정된 형광 신호는 산란이나 회절, 수차 등의 효과로 인해 흐려지기 때문에 디컨볼루션 기법을 통해 보정하는 과정이 반드시 필요하다.
또한, 반도체 산업에서는 수천 개의 생산 공정 중간에 검사·계측 기술을 통해 발생할 수 있는 미세 공정 오류를 감지하고, 공정 수율 개선을 위한 프로세스 개선 과정에 사용되는 주사전자현미경이 전자 빔의 불안정성으로 인해 영상이 흐려지기 쉬우며, 이를 보정하는 과정이 반드시 필요하다.
연구팀은 이처럼 영상이 흐려지는 원인은 움직임, 빛의 산란, 전자의 불안정성 등과 같이 다양하지만, 공통적으로 ‘영상의 흐려짐을 없앤다’라는 점에서 수학적으로 동일한 접근 방법이 활용될 수 있다고 생각했다.
특히 잡음 수준이 높은 영상의 경우, 영상의 잡음을 효과적으로 억제함과 동시에 블러 효과가 제거된 선명한 영상을 복원하는 과정의 균형을 맞추는 것이 매우 중요하다는 점을 착안했다.
연구팀은 위너 디컨볼루션*을 기반으로 영상을 복원하는 접근법을 개발했다. 이를 적응형 잡음 억제 변수, 영상 생성형 인공지능 모델과 결합해 영상 복원 과정에서 발생할 수 있는 잡음을 억제하고 영상 선명도도 높였다.
*위너 디컨볼루션(Wiener deconvolution)은 왜곡된 영상을 역 필터(inverse filter)를 기반으로 깨끗한 영상으로 복원하는 전통적인 방식임.
연구팀은 잡음 민감도가 높은 주사전자현미경으로부터 측정된 왜곡된 영상으로부터 깨끗하고 초점이 맞는 나노미터 단위의 반도체 구조에 대한 영상을 성공적으로 복원해 냄으로써 반도체 검사·계측에 매우 효과적으로 적용할 수 있음을 실험적으로 증명했다.
바이오및뇌공학과 이찬석 연구원은 “이번 연구를 통해 강한 잡음 속에서 왜곡된 영상을 복원하는 난제를 해결했다ˮ며, 이어 "이번 연구에서는 무작위적 잡음을 극복하는 영상 복원 기술을 개발하는 데에 집중했고, 향후 비균일 영상 복원 및 다양한 손상 형태를 극복하는 영상 복원 기술 개발에 주력할 것이다ˮ라고 밝혔다.
바이오및뇌공학과 이찬석 박사과정이 제1 저자로 참여한 이번 연구는 컴퓨터 비전 분야 최고 학회인 ‘제18회 유럽 컴퓨터 비전 학회(The 18th European Conference on Computer Vision)’ 에서 지난 10월 1일에 이탈리아 밀란에서 발표됐고, Springer Nature에서 출판하는 Lecture Notes in Computer Science의 ECCV 2024 프로시딩 집에 게재될 예정이다. (논문명: Blind image deblurring with noise-robust kernel estimation).
2024.11.26 조회수 4119 -
 AI가 그린수소와 배터리 미래 신소재 찾아낸다
그린수소 또는 배터리 분야 등 청정 에너지의 성능을 높이는데 가장 큰 영향을 미치는 소재 중 하나는 전극이다. 한국 연구진이 차세대 전극 및 촉매로 활용될 수 있는 신소재를 효율적으로 설계하는 인공지능 기술을 개발했다. 이 기술을 통해 친환경 에너지 사회를 촉진하는데 중요한 역할을 할 것으로 기대된다.
우리 대학 기계공학과 이강택 교수 연구팀의 주도로 한국에너지기술연구원 (원장 이창근), 한국지질자원연구원 (원장 이평구), KAIST 신소재공학과 공동 연구팀들과 함께, 인공지능(AI)과 계산화학을 결합해 그린수소 및 배터리에 활용될 수 있는 스피넬 산화물 신소재를 설계하고, 성능과 안정성을 예측할 수 있는 새로운 지표를 개발하는 데 성공했다고 21일 밝혔다.
스피넬 산화물(AB2O4)은 그린수소 또는 배터리 분야의 차세대 촉매 및 전극 물질로 활용되어 산소 환원 반응(ORR)과 산소 발생 반응(OER)의 속도를 향상시킬 수 있는 잠재력이 높은 물질이다. 하지만, 수천 개 이상의 후보군을 일일이 실험으로 성능을 확인하기 위해서는 많은 시간과 노력이 소요된다.
연구팀은 이를 해결하기 위해 AI와 계산화학을 동시에 사용해 1,240개의 스피넬 산화물 후보 물질을 체계적으로 선별하고, 그중 기존 촉매보다 뛰어난 성능을 보일 촉매 물질들을 찾는 데 성공했다.
그뿐만 아니라, 연구팀은 이번 연구를 통해서 전공 서적에서 손쉽게 찾아볼 수 있는 원자들의 전기음성도를 바탕으로 스피넬 촉매의 안정성과 성능을 예측할 수 있는 지표를 개발했다.
이로써 기존의 실험 방식에 비해 촉매 설계 과정을 훨씬 더 빠르고 효율적으로 진행할 수 있게 되었다. 또한, 연구팀은 스피넬 산화물에서 산소 이온이 움직일 수 있는 3차원 확산 경로를 발견해, 촉매의 성능을 더욱 향상할 수 있는 메커니즘을 처음으로 규명했다.
이강택 교수는 “이번 연구는 인공지능을 통해 신소재의 성능을 빠르고 정확하게 예측할 수 있는 새로운 방법을 제시했다”며, “특히, 이를 통해 그린수소와 배터리 분야에 활용될 수 있는 촉매 및 전극의 개발을 가속화해, 고성능의 친환경 에너지 기술의 발전에 기여할 것”이라고 전했다.
연구팀이 제시한 예측 방법은 기존 실험 방식에 비해 신소재 개발의 효율성을 70배 이상 크게 높였으며, 이러한 성과가 차세대 에너지 변환 및 저장 장치를 위한 소재 개발 연구에 핵심 기술로 자리 잡을 가능성을 높게 보고 있다.
한국에너지기술연구원 이찬우 박사가 공동 교신 저자로 참여하였으며, 한국지질자원연구원 정인철 박사, KAIST 신소재공학과 심윤수 박사가 공동 제1 저자로 참여하고, KAIST 신소재공학과 육종민 교수, 한국지질자원연구원 노기민 박사가 공동 저자로 참여한 이번 연구 결과는 세계적인 학술지‘어드밴스드 에너지 머터리얼즈, Advanced Energy Materials (IF:24.4)’에 중요한 연구 결과임을 인정받아 표지(Inside Front cover) 에 선정됐으며, 24년 10월 21일에 게재됐다. (논문명: A Machine Learning-Enhanced Framework for the Accelerated Development of Spinel Oxide Electrocatalysts)
한편, 이번 연구는 과학기술정보통신부의 개인기초 연구사업, 집단기초연구사업, 그리고 국가과학기술연구회 창의형 융합연구사업의 지원을 받아 수행됐다.
2024.11.21 조회수 5758
AI가 그린수소와 배터리 미래 신소재 찾아낸다
그린수소 또는 배터리 분야 등 청정 에너지의 성능을 높이는데 가장 큰 영향을 미치는 소재 중 하나는 전극이다. 한국 연구진이 차세대 전극 및 촉매로 활용될 수 있는 신소재를 효율적으로 설계하는 인공지능 기술을 개발했다. 이 기술을 통해 친환경 에너지 사회를 촉진하는데 중요한 역할을 할 것으로 기대된다.
우리 대학 기계공학과 이강택 교수 연구팀의 주도로 한국에너지기술연구원 (원장 이창근), 한국지질자원연구원 (원장 이평구), KAIST 신소재공학과 공동 연구팀들과 함께, 인공지능(AI)과 계산화학을 결합해 그린수소 및 배터리에 활용될 수 있는 스피넬 산화물 신소재를 설계하고, 성능과 안정성을 예측할 수 있는 새로운 지표를 개발하는 데 성공했다고 21일 밝혔다.
스피넬 산화물(AB2O4)은 그린수소 또는 배터리 분야의 차세대 촉매 및 전극 물질로 활용되어 산소 환원 반응(ORR)과 산소 발생 반응(OER)의 속도를 향상시킬 수 있는 잠재력이 높은 물질이다. 하지만, 수천 개 이상의 후보군을 일일이 실험으로 성능을 확인하기 위해서는 많은 시간과 노력이 소요된다.
연구팀은 이를 해결하기 위해 AI와 계산화학을 동시에 사용해 1,240개의 스피넬 산화물 후보 물질을 체계적으로 선별하고, 그중 기존 촉매보다 뛰어난 성능을 보일 촉매 물질들을 찾는 데 성공했다.
그뿐만 아니라, 연구팀은 이번 연구를 통해서 전공 서적에서 손쉽게 찾아볼 수 있는 원자들의 전기음성도를 바탕으로 스피넬 촉매의 안정성과 성능을 예측할 수 있는 지표를 개발했다.
이로써 기존의 실험 방식에 비해 촉매 설계 과정을 훨씬 더 빠르고 효율적으로 진행할 수 있게 되었다. 또한, 연구팀은 스피넬 산화물에서 산소 이온이 움직일 수 있는 3차원 확산 경로를 발견해, 촉매의 성능을 더욱 향상할 수 있는 메커니즘을 처음으로 규명했다.
이강택 교수는 “이번 연구는 인공지능을 통해 신소재의 성능을 빠르고 정확하게 예측할 수 있는 새로운 방법을 제시했다”며, “특히, 이를 통해 그린수소와 배터리 분야에 활용될 수 있는 촉매 및 전극의 개발을 가속화해, 고성능의 친환경 에너지 기술의 발전에 기여할 것”이라고 전했다.
연구팀이 제시한 예측 방법은 기존 실험 방식에 비해 신소재 개발의 효율성을 70배 이상 크게 높였으며, 이러한 성과가 차세대 에너지 변환 및 저장 장치를 위한 소재 개발 연구에 핵심 기술로 자리 잡을 가능성을 높게 보고 있다.
한국에너지기술연구원 이찬우 박사가 공동 교신 저자로 참여하였으며, 한국지질자원연구원 정인철 박사, KAIST 신소재공학과 심윤수 박사가 공동 제1 저자로 참여하고, KAIST 신소재공학과 육종민 교수, 한국지질자원연구원 노기민 박사가 공동 저자로 참여한 이번 연구 결과는 세계적인 학술지‘어드밴스드 에너지 머터리얼즈, Advanced Energy Materials (IF:24.4)’에 중요한 연구 결과임을 인정받아 표지(Inside Front cover) 에 선정됐으며, 24년 10월 21일에 게재됐다. (논문명: A Machine Learning-Enhanced Framework for the Accelerated Development of Spinel Oxide Electrocatalysts)
한편, 이번 연구는 과학기술정보통신부의 개인기초 연구사업, 집단기초연구사업, 그리고 국가과학기술연구회 창의형 융합연구사업의 지원을 받아 수행됐다.
2024.11.21 조회수 5758 -
 천천히 걸음 속도 높여도 다 아는 인공지능 기술 개발
최근 건강에 관한 관심이 점차 커지면서 일상생활에서 스마트 워치, 스마트 링 등을 통해 자기 신체 변화를 살펴보는 일이 보편화되었다. 그런데 기존 헬스케어 앱에서는 걷기에서 뛰기로 갑자기 변화를 줄 경우는 잘 측정이 되지만 천천히 속도를 높이는 경우는 측정이 안 되는 현상이 발생했다. 우리 연구진이 완만한 변화에도 동작을 정확하게 파악하는 기술을 개발했다.
우리 대학 전산학부 이재길 교수 연구팀이 다양한 착용 기기 센서 데이터에서 사용자 상태 변화를 정확하게 검출하는 새로운 인공지능 기술을 개발했다고 12일 밝혔다.
보통 헬스케어 앱에서는 센서 데이터를 통해 사용자의 상태 변화를 탐지하여 현재 동작을 정확히 인식하는 기능이 필수이다. 이를 변화점 탐지라 부르며 다양한 인공지능 기술이 변화점 탐지 품질을 향상하기 위해 적용되고 있다.
이재길 교수팀은 사용자의 상태가 급진적으로 변하거나 점진적으로 변하는지에 관계없이 정확하게 잘 동작하는 변화점 탐지 방법론을 개발했다.
연구팀은 각 시점의 센서 데이터를 인공지능 기술을 통해 벡터*로 표현하였을 때, 이러한 벡터가 시간이 지남에 따라 이동하는 방향을 주목하였다. 같은 동작이 유지될 때는 벡터가 이동하는 방향이 급변하는 경향이 크고, 동작이 바뀔 때는 벡터가 직선상으로 이동하는 경향이 크게 나타났다.
*벡터: 사용자의 시점별 상태 특성(이동속도, 자세, 움직임 등)을 나타내는 가장 좋은 수학적 개념
연구팀은 제안한 방법론을 ‘리커브(RECURVE)’라고 명명했다. 리커브(RECURVE)는 양궁 경기에 쓰이는 활의 한 종류이며, 활이 휘어 있는 모습이 데이터의 이동 방향 변화 정도(곡률)로 변화점을 탐지하는 본 방법론의 동작 방식을 잘 나타낸다고 보았다. 이 방법은 변화점 탐지의 기준을 거리에서 곡률이라는 새로운 관점으로 바라본 매우 신선한 방법이라는 평가를 받았다.
연구팀은 변화점 탐지 문제에서 다양한 헬스케어 센서 스트림 데이터를 사용하여 방법론의 우수성을 검증하여 기존 방법론에 비해 최대 12.7% 정확도 향상을 달성했다.
연구팀을 지도한 이재길 교수는 "센서 스트림 데이터 변화점 탐지 분야의 새로운 지평을 열 만한 획기적인 방법이며 실용화 및 기술 이전이 이뤄지면 실시간 데이터 분석 연구 및 디지털 헬스케어 산업에 큰 파급효과를 낼 수 있을 것이다ˮ고 말했다.
데이터사이언스대학원을 졸업한 신유주 박사가 제1 저자, 전산학부 박재현 석사과정 학생이 제2 저자로 참여한 이번 연구는 최고권위 국제학술대회 `신경정보처리시스템학회(NeurIPS) 2024'에서 올 12월 발표될 예정이다. (논문명 : Exploiting Representation Curvature for Boundary Detection in Time Series)
한편, 이 기술은 과학기술정보통신부 재원으로 정보통신기획평가원의 지원을 받아 SW컴퓨팅산업원천기술개발사업 SW스타랩 과제로 개발한 연구성과 결과물(RS-2020-II200862, DB4DL: 딥러닝 지원 고사용성 및 고성능 분산 인메모리 DBMS 개발)이다.
2024.11.12 조회수 4804
천천히 걸음 속도 높여도 다 아는 인공지능 기술 개발
최근 건강에 관한 관심이 점차 커지면서 일상생활에서 스마트 워치, 스마트 링 등을 통해 자기 신체 변화를 살펴보는 일이 보편화되었다. 그런데 기존 헬스케어 앱에서는 걷기에서 뛰기로 갑자기 변화를 줄 경우는 잘 측정이 되지만 천천히 속도를 높이는 경우는 측정이 안 되는 현상이 발생했다. 우리 연구진이 완만한 변화에도 동작을 정확하게 파악하는 기술을 개발했다.
우리 대학 전산학부 이재길 교수 연구팀이 다양한 착용 기기 센서 데이터에서 사용자 상태 변화를 정확하게 검출하는 새로운 인공지능 기술을 개발했다고 12일 밝혔다.
보통 헬스케어 앱에서는 센서 데이터를 통해 사용자의 상태 변화를 탐지하여 현재 동작을 정확히 인식하는 기능이 필수이다. 이를 변화점 탐지라 부르며 다양한 인공지능 기술이 변화점 탐지 품질을 향상하기 위해 적용되고 있다.
이재길 교수팀은 사용자의 상태가 급진적으로 변하거나 점진적으로 변하는지에 관계없이 정확하게 잘 동작하는 변화점 탐지 방법론을 개발했다.
연구팀은 각 시점의 센서 데이터를 인공지능 기술을 통해 벡터*로 표현하였을 때, 이러한 벡터가 시간이 지남에 따라 이동하는 방향을 주목하였다. 같은 동작이 유지될 때는 벡터가 이동하는 방향이 급변하는 경향이 크고, 동작이 바뀔 때는 벡터가 직선상으로 이동하는 경향이 크게 나타났다.
*벡터: 사용자의 시점별 상태 특성(이동속도, 자세, 움직임 등)을 나타내는 가장 좋은 수학적 개념
연구팀은 제안한 방법론을 ‘리커브(RECURVE)’라고 명명했다. 리커브(RECURVE)는 양궁 경기에 쓰이는 활의 한 종류이며, 활이 휘어 있는 모습이 데이터의 이동 방향 변화 정도(곡률)로 변화점을 탐지하는 본 방법론의 동작 방식을 잘 나타낸다고 보았다. 이 방법은 변화점 탐지의 기준을 거리에서 곡률이라는 새로운 관점으로 바라본 매우 신선한 방법이라는 평가를 받았다.
연구팀은 변화점 탐지 문제에서 다양한 헬스케어 센서 스트림 데이터를 사용하여 방법론의 우수성을 검증하여 기존 방법론에 비해 최대 12.7% 정확도 향상을 달성했다.
연구팀을 지도한 이재길 교수는 "센서 스트림 데이터 변화점 탐지 분야의 새로운 지평을 열 만한 획기적인 방법이며 실용화 및 기술 이전이 이뤄지면 실시간 데이터 분석 연구 및 디지털 헬스케어 산업에 큰 파급효과를 낼 수 있을 것이다ˮ고 말했다.
데이터사이언스대학원을 졸업한 신유주 박사가 제1 저자, 전산학부 박재현 석사과정 학생이 제2 저자로 참여한 이번 연구는 최고권위 국제학술대회 `신경정보처리시스템학회(NeurIPS) 2024'에서 올 12월 발표될 예정이다. (논문명 : Exploiting Representation Curvature for Boundary Detection in Time Series)
한편, 이 기술은 과학기술정보통신부 재원으로 정보통신기획평가원의 지원을 받아 SW컴퓨팅산업원천기술개발사업 SW스타랩 과제로 개발한 연구성과 결과물(RS-2020-II200862, DB4DL: 딥러닝 지원 고사용성 및 고성능 분산 인메모리 DBMS 개발)이다.
2024.11.12 조회수 4804 -
 인공지능으로 고성능 양자물성 계산시간 획기적 단축
인공지능과 고성능 과학계산 간의 밀접한 관련성은 최근 2024년도 노벨 물리학상과 화학상이 동시에 수상된 것을 보면 알 수 있다. 우리 연구진이 인공지능을 활용하여 3차원 공간에 분포하는 원자 수준의 화학결합 정보를 예측하여 양자역학적 고성능 컴퓨터 시뮬레이션의 계산 시간을 획기적으로 단축하는데 성공했다.
우리 대학 전기및전자공학부 김용훈 교수팀이 물질의 특성을 도출하기 위해 슈퍼컴퓨터를 활용해 수행되는 원자 수준 양자역학적 계산에 필요한 복잡한 알고리즘을 우회하는 3차원 컴퓨터 비전 인공신경망 기반 계산 방법론을 세계 최초로 개발했다고 30일 밝혔다.
슈퍼컴퓨터를 활용한 양자역학적 밀도범함수론(density functional theory, DFT)* 계산은 빠르면서도 정확하게 양자 물성을 예측할 수 있게 해 첨단 소재 및 약물 설계를 포함한 광범위한 연구·개발 분야에서 표준적인 도구로 자리 잡아 필수 불가결한 역할을 하고 있다.
*밀도범함수론(DFT): 원자 단위에서부터 양자역학적으로 물성을 계산하는 제1원리 계산의 대표적인 이론
그러나 실제 밀도범함수론 계산에서는 3차원적인 전자밀도를 생성한 후 양자역학 방정식을 푸는 복잡한 자기일관장 과정(self-consistent field, SCF)*을 수십에서 수백 번씩 반복해야 해서 그 적용 범위가 수백~수천 개의 원자로 제한되는 한계가 있었다.
*자기일관장(SCF): 상호 연결된 여러 개의 연립 미분 방정식으로 기술해야 하는 복잡한 다체 문제(many-body problem)를 해결하기 위해 널리 사용되는 과학계산법
김용훈 교수 연구팀은 자기일관장 과정을 최근 급속한 발전을 이룬 인공지능 기법으로 회피하는 것이 가능한지 질문했다. 그 결과 3차원 공간에 분포된 화학 결합 정보를 컴퓨터 비전 분야의 신경망 알고리즘을 통해 학습해 계산을 가속화하는 딥SCF(DeepSCF) 모델을 개발했다.
연구진은 밀도범함수론에 따라 전자밀도가 전자들의 양자역학적 정보를 모두 포함하고 있으며 이에 더해 전체 전자밀도와 구성 원자들의 전자밀도의 합 간의 차이인 잔여 전자밀도가 화학결합 정보를 담고 있는 점에 주목하고 기계학습의 목표물로 선정했다.
이후 다양한 화학결합 특성을 포함한 유기 분자들의 데이터 세트를 채택했고 그 안에 포함된 분자들의 원자구조들에 임의의 회전과 변형을 가해 모델의 정확도 및 일반화 성능을 더욱 높였다. 최종적으로 연구팀은 복잡하고 큰 시스템에 대해 딥SCF 방법론의 유효성 및 효율성을 입증했다.
이번 연구를 지도한 김용훈 교수는“3차원 공간에 분포된 양자역학적 화학결합 정보를 인공 신경망에 대응시키는 방법을 찾았다”며 “양자역학적 전자구조 계산이 모든 스케일의 물성 시뮬레이션의 근간이 되므로 인공지능을 통한 물질 계산 가속화의 전반적인 기반 원리를 확립한 것”이라고 연구의 의의를 부여했다.
전기및전자공학부 이룡규 박사과정이 제 1저자로 수행한 이번 연구는 소재 계산 분야의 권위 있는 학술지 '네이쳐 파트너 저널 컴퓨테이셔널 머터리얼즈(Npj Computational Materials)'에 10월 24일 字 온라인판에 게재됐다. (논문명 : Convolutional network learning of self-consistent electron density via grid-projected atomic fingerprints)
한편, 이번 연구는 KAIST 석박사 모험사업, 한국연구재단 중견연구자지원사업 등의 지원을 받아 수행되었다.
2024.10.30 조회수 5842
인공지능으로 고성능 양자물성 계산시간 획기적 단축
인공지능과 고성능 과학계산 간의 밀접한 관련성은 최근 2024년도 노벨 물리학상과 화학상이 동시에 수상된 것을 보면 알 수 있다. 우리 연구진이 인공지능을 활용하여 3차원 공간에 분포하는 원자 수준의 화학결합 정보를 예측하여 양자역학적 고성능 컴퓨터 시뮬레이션의 계산 시간을 획기적으로 단축하는데 성공했다.
우리 대학 전기및전자공학부 김용훈 교수팀이 물질의 특성을 도출하기 위해 슈퍼컴퓨터를 활용해 수행되는 원자 수준 양자역학적 계산에 필요한 복잡한 알고리즘을 우회하는 3차원 컴퓨터 비전 인공신경망 기반 계산 방법론을 세계 최초로 개발했다고 30일 밝혔다.
슈퍼컴퓨터를 활용한 양자역학적 밀도범함수론(density functional theory, DFT)* 계산은 빠르면서도 정확하게 양자 물성을 예측할 수 있게 해 첨단 소재 및 약물 설계를 포함한 광범위한 연구·개발 분야에서 표준적인 도구로 자리 잡아 필수 불가결한 역할을 하고 있다.
*밀도범함수론(DFT): 원자 단위에서부터 양자역학적으로 물성을 계산하는 제1원리 계산의 대표적인 이론
그러나 실제 밀도범함수론 계산에서는 3차원적인 전자밀도를 생성한 후 양자역학 방정식을 푸는 복잡한 자기일관장 과정(self-consistent field, SCF)*을 수십에서 수백 번씩 반복해야 해서 그 적용 범위가 수백~수천 개의 원자로 제한되는 한계가 있었다.
*자기일관장(SCF): 상호 연결된 여러 개의 연립 미분 방정식으로 기술해야 하는 복잡한 다체 문제(many-body problem)를 해결하기 위해 널리 사용되는 과학계산법
김용훈 교수 연구팀은 자기일관장 과정을 최근 급속한 발전을 이룬 인공지능 기법으로 회피하는 것이 가능한지 질문했다. 그 결과 3차원 공간에 분포된 화학 결합 정보를 컴퓨터 비전 분야의 신경망 알고리즘을 통해 학습해 계산을 가속화하는 딥SCF(DeepSCF) 모델을 개발했다.
연구진은 밀도범함수론에 따라 전자밀도가 전자들의 양자역학적 정보를 모두 포함하고 있으며 이에 더해 전체 전자밀도와 구성 원자들의 전자밀도의 합 간의 차이인 잔여 전자밀도가 화학결합 정보를 담고 있는 점에 주목하고 기계학습의 목표물로 선정했다.
이후 다양한 화학결합 특성을 포함한 유기 분자들의 데이터 세트를 채택했고 그 안에 포함된 분자들의 원자구조들에 임의의 회전과 변형을 가해 모델의 정확도 및 일반화 성능을 더욱 높였다. 최종적으로 연구팀은 복잡하고 큰 시스템에 대해 딥SCF 방법론의 유효성 및 효율성을 입증했다.
이번 연구를 지도한 김용훈 교수는“3차원 공간에 분포된 양자역학적 화학결합 정보를 인공 신경망에 대응시키는 방법을 찾았다”며 “양자역학적 전자구조 계산이 모든 스케일의 물성 시뮬레이션의 근간이 되므로 인공지능을 통한 물질 계산 가속화의 전반적인 기반 원리를 확립한 것”이라고 연구의 의의를 부여했다.
전기및전자공학부 이룡규 박사과정이 제 1저자로 수행한 이번 연구는 소재 계산 분야의 권위 있는 학술지 '네이쳐 파트너 저널 컴퓨테이셔널 머터리얼즈(Npj Computational Materials)'에 10월 24일 字 온라인판에 게재됐다. (논문명 : Convolutional network learning of self-consistent electron density via grid-projected atomic fingerprints)
한편, 이번 연구는 KAIST 석박사 모험사업, 한국연구재단 중견연구자지원사업 등의 지원을 받아 수행되었다.
2024.10.30 조회수 5842 -
 뇌 기반 인공지능의 난제 해결
인간의 두뇌는 외부 세상으로부터 감각 정보를 받아들이기 이전부터 자발적인 무작위 활동을 통해 학습을 시작한다. 우리 연구진이 개발한 기술은 뇌 모방 인공신경망에서 무작위 정보를 사전 학습시켜 실제 데이터를 접했을 때 훨씬 빠르고 정확한 학습을 가능하게 하며, 향후 뇌 기반 인공지능 및 뉴로모픽 컴퓨팅 기술 개발의 돌파구를 열어줄 것으로 기대된다.
우리 대학 뇌인지과학과 백세범 교수 연구팀이 뇌 모방 인공신경망 학습의 오래된 난제였던 가중치 수송 문제(weight transport problem)*를 해결하고, 이를 통해 생물학적 뇌 신경망에서 자원 효율적 학습이 가능한 원리를 설명했다고 23일 밝혔다.
*가중치 수송 문제: 생물학적 뇌를 모방한 인공지능 개발에 가장 큰 장애물이 되는 난제로, 현재 일반적인 인공신경망의 학습에서 생물학적 뇌와 달리 대규모의 메모리와 계산 작업이 필요한 근본적인 이유임.
지난 수십 년간 인공지능의 발전은 올해 노벨 물리학상을 받은 제프리 힌튼(Geoffery Hinton)이 제시한 오류 역전파(error backpropagation) 학습에 기반한다. 그러나 오류 역전파 학습은 생물학적 뇌에서는 가능하지 않다고 생각되어 왔는데, 이는 학습을 위한 오류 신호를 계산하기 위해 개별 뉴런들이 다음 계층의 모든 연결 정보를 알고 있어야 하는 비현실적인 가정이 필요하기 때문이다.
가중치 수송 문제라고 불리는 이 난제는 1986년 힌튼에 의해 오류 역전파 학습이 제안된 이후, DNA 구조의 발견으로 노벨 생리의학상을 받은 프랜시스 크릭(Francis Crick)에 의해 제기됐으며, 이후 자연신경망과 인공신경망 작동 원리가 근본적으로 다를 수밖에 없는 이유로 여겨진다.
인공지능과 신경과학의 경계선에서, 힌튼을 비롯한 연구자들은 가중치 수송 문제를 해결함으로써 뇌의 학습 원리를 구현할 수 있는, 생물학적으로 타당한 모델을 만들고자 하는 시도를 계속해 왔다.
지난 2016년, 영국 옥스퍼드(Oxford) 대학과 딥마인드(DeepMind) 공동 연구진은 가중치 수송을 사용하지 않고도 오류 역전파 학습이 가능하다는 개념을 최초로 제시해 학계의 주목을 받았다. 그러나, 가중치 수송을 사용하지 않는 생물학적으로 타당한 오류 역전파 학습은 학습 속도가 느리고 정확도가 낮은 등 효율성이 떨어져, 현실적인 적용에는 문제가 있었다.
연구팀은 생물학적 뇌가 외부적인 감각 경험을 하기 이전부터 내부의 자발적인 무작위 신경 활동을 통해 이미 학습을 시작한다는 점에 주목했다. 이를 모방해 연구팀은 가중치 수송이 없는 생물학적으로 타당한 신경망에 의미 없는 무작위 정보(random noise)를 사전 학습시켰다.
그 결과, 오류 역전파 학습을 위해 필수적 조건인 신경망의 순방향과 역방향 신경세포 연결 구조의 대칭성이 만들어질 수 있음을 보였다. 즉, 무작위적 사전 학습을 통해 가중치 수송 없이 학습이 가능해진 것이다.
연구팀은 실제 데이터 학습에 앞서 무작위 정보를 학습하는 것이 ‘배우는 방법을 배우는’메타 학습(meta learning)의 성질을 가진다는 것을 밝혔다. 무작위 정보를 사전 학습한 신경망은 실제 데이터를 접했을 때 훨씬 빠르고 정확한 학습을 수행하며, 가중치 수송 없이 높은 학습 효율성을 얻을 수 있음을 보였다.
백세범 교수는 “데이터 학습만이 중요하다는 기존 기계학습의 통념을 깨고, 학습 전부터 적절한 조건을 만드는 뇌신경과학적 원리에 주목하는 새로운 관점을 제공하는 것”이라며 “발달 신경과학으로부터의 단서를 통해 인공신경망 학습의 중요한 문제를 해결함과 동시에, 인공신경망 모델을 통해 뇌의 학습 원리에 대한 통찰을 제공한다는 점에서 중요한 의미를 가진다”고 언급했다.
뇌인지과학과 천정환 석사과정이 제1 저자로, 같은 학과 이상완 교수가 공동 저자로 참여한 이번 연구는 12월 10일부터 15일까지 캐나다 벤쿠버에서 열리는 세계 최고 수준의 인공지능 학회인 제38회 신경정보처리학회(NeurIPS)에서 발표될 예정이다. (논문명: Pretraining with random noise for fast and robust learning without weight transport (가중치 수송 없는 빠르고 안정적인 신경망 학습을 위한 무작위 사전 훈련))
한편 이번 연구는 한국연구재단의 이공분야기초연구사업, 정보통신기획평가원 인재양성사업 및 KAIST 특이점교수 사업의 지원을 받아 수행됐다.
2024.10.23 조회수 6135
뇌 기반 인공지능의 난제 해결
인간의 두뇌는 외부 세상으로부터 감각 정보를 받아들이기 이전부터 자발적인 무작위 활동을 통해 학습을 시작한다. 우리 연구진이 개발한 기술은 뇌 모방 인공신경망에서 무작위 정보를 사전 학습시켜 실제 데이터를 접했을 때 훨씬 빠르고 정확한 학습을 가능하게 하며, 향후 뇌 기반 인공지능 및 뉴로모픽 컴퓨팅 기술 개발의 돌파구를 열어줄 것으로 기대된다.
우리 대학 뇌인지과학과 백세범 교수 연구팀이 뇌 모방 인공신경망 학습의 오래된 난제였던 가중치 수송 문제(weight transport problem)*를 해결하고, 이를 통해 생물학적 뇌 신경망에서 자원 효율적 학습이 가능한 원리를 설명했다고 23일 밝혔다.
*가중치 수송 문제: 생물학적 뇌를 모방한 인공지능 개발에 가장 큰 장애물이 되는 난제로, 현재 일반적인 인공신경망의 학습에서 생물학적 뇌와 달리 대규모의 메모리와 계산 작업이 필요한 근본적인 이유임.
지난 수십 년간 인공지능의 발전은 올해 노벨 물리학상을 받은 제프리 힌튼(Geoffery Hinton)이 제시한 오류 역전파(error backpropagation) 학습에 기반한다. 그러나 오류 역전파 학습은 생물학적 뇌에서는 가능하지 않다고 생각되어 왔는데, 이는 학습을 위한 오류 신호를 계산하기 위해 개별 뉴런들이 다음 계층의 모든 연결 정보를 알고 있어야 하는 비현실적인 가정이 필요하기 때문이다.
가중치 수송 문제라고 불리는 이 난제는 1986년 힌튼에 의해 오류 역전파 학습이 제안된 이후, DNA 구조의 발견으로 노벨 생리의학상을 받은 프랜시스 크릭(Francis Crick)에 의해 제기됐으며, 이후 자연신경망과 인공신경망 작동 원리가 근본적으로 다를 수밖에 없는 이유로 여겨진다.
인공지능과 신경과학의 경계선에서, 힌튼을 비롯한 연구자들은 가중치 수송 문제를 해결함으로써 뇌의 학습 원리를 구현할 수 있는, 생물학적으로 타당한 모델을 만들고자 하는 시도를 계속해 왔다.
지난 2016년, 영국 옥스퍼드(Oxford) 대학과 딥마인드(DeepMind) 공동 연구진은 가중치 수송을 사용하지 않고도 오류 역전파 학습이 가능하다는 개념을 최초로 제시해 학계의 주목을 받았다. 그러나, 가중치 수송을 사용하지 않는 생물학적으로 타당한 오류 역전파 학습은 학습 속도가 느리고 정확도가 낮은 등 효율성이 떨어져, 현실적인 적용에는 문제가 있었다.
연구팀은 생물학적 뇌가 외부적인 감각 경험을 하기 이전부터 내부의 자발적인 무작위 신경 활동을 통해 이미 학습을 시작한다는 점에 주목했다. 이를 모방해 연구팀은 가중치 수송이 없는 생물학적으로 타당한 신경망에 의미 없는 무작위 정보(random noise)를 사전 학습시켰다.
그 결과, 오류 역전파 학습을 위해 필수적 조건인 신경망의 순방향과 역방향 신경세포 연결 구조의 대칭성이 만들어질 수 있음을 보였다. 즉, 무작위적 사전 학습을 통해 가중치 수송 없이 학습이 가능해진 것이다.
연구팀은 실제 데이터 학습에 앞서 무작위 정보를 학습하는 것이 ‘배우는 방법을 배우는’메타 학습(meta learning)의 성질을 가진다는 것을 밝혔다. 무작위 정보를 사전 학습한 신경망은 실제 데이터를 접했을 때 훨씬 빠르고 정확한 학습을 수행하며, 가중치 수송 없이 높은 학습 효율성을 얻을 수 있음을 보였다.
백세범 교수는 “데이터 학습만이 중요하다는 기존 기계학습의 통념을 깨고, 학습 전부터 적절한 조건을 만드는 뇌신경과학적 원리에 주목하는 새로운 관점을 제공하는 것”이라며 “발달 신경과학으로부터의 단서를 통해 인공신경망 학습의 중요한 문제를 해결함과 동시에, 인공신경망 모델을 통해 뇌의 학습 원리에 대한 통찰을 제공한다는 점에서 중요한 의미를 가진다”고 언급했다.
뇌인지과학과 천정환 석사과정이 제1 저자로, 같은 학과 이상완 교수가 공동 저자로 참여한 이번 연구는 12월 10일부터 15일까지 캐나다 벤쿠버에서 열리는 세계 최고 수준의 인공지능 학회인 제38회 신경정보처리학회(NeurIPS)에서 발표될 예정이다. (논문명: Pretraining with random noise for fast and robust learning without weight transport (가중치 수송 없는 빠르고 안정적인 신경망 학습을 위한 무작위 사전 훈련))
한편 이번 연구는 한국연구재단의 이공분야기초연구사업, 정보통신기획평가원 인재양성사업 및 KAIST 특이점교수 사업의 지원을 받아 수행됐다.
2024.10.23 조회수 6135