%EB%94%A5%EB%9F%AC%EB%8B%9D
-
 딥러닝 대부 요슈아 벤지오 교수와 AI 연구센터 설립
우리 대학 전산학부 안성진 교수 연구팀이 세계적인 인공지능 권위자인 캐나다의 요슈아 벤지오(Yoshua Bengio) 교수와 함께 ‘KAIST-밀라(MILA) 프리프론탈 인공지능 연구센터’를 KAIST에 7월 1일부로 설립했다고 4일 밝혔다.
이 사업은 과학기술정보통신부와 한국연구재단이 지원하는 ‘2024년도 해외우수연구기관 협력허브구축사업’의 일환으로, 안성진 교수 연구팀은 2024년 7월부터 2028년 12월까지 총 27억 원의 지원을 받게 된다. 이 센터는 차세대 인공지능 기술 개발을 위한 국제공동연구의 중심지로서 역할을 하게 될 예정이다.
요슈아 벤지오 교수는 딥러닝 분야의 창시자 중 한 명으로, 현대 인공지능 연구에 지대한 영향을 미친 인물이다. 그의 연구는 현재의 딥러닝 기술을 탄생시키고 발전시키는 데 중요한 역할을 했다. KAIST 안성진 교수팀과의 이번 협력은 요슈아 벤지오 교수의 몬트리올 학습 알고리즘 연구소(MILA, Montreal Institute for Learning Algorithms)와 KAIST의 선도적인 인공지능 연구 역량을 결합해, 차세대 인공지능 기술 발전에 새로운 지평을 열 것으로 기대된다.
이번 연구의 핵심은 인간의 고위인지 능력을 모방하는 ‘시스템2’ AI 기술의 개발이다. 시스템2는 데니얼 카네만의 듀얼프로세스 이론에서 제시된 개념으로, 직관적이고 빠른 인지를 담당하는 ‘시스템1‘과 달리, 수학적 논리 추론 같이 복잡하고 순차적인 사고 과정을 담당하는 기능을 수행한다. 이 과정은 주로 뇌의 전두엽에서 이뤄지며, 계획, 판단, 추론 등 고차원적인 인지 기능을 관리한다. 대형언어모델의 발전에도 불구하고, 현재의 딥러닝 기술은 이러한 고위인지 기능을 효과적으로 구현하는 데 여전히 한계를 보이고 있다.
이번 연구는 이러한 한계를 극복하고, 전두엽이 담당하는 고위인지 기능을 AI에 통합하는 ‘프리프론탈 AI’를 구현하기 위한 기반 기술을 확보하는 것을 목표로 한다.
또한, 이번 연구에는 우리 대학 홍승훈 교수와 포항공과대학교(POSTECH)의 안성수 교수도 공동 연구진으로 참여할 예정이다. 홍승훈 교수는 시스템2 메타 학습 알고리즘을 연구하며, 안성수 교수는 시스템2 기능을 ‘과학을 위한 AI(AI4Science)’ 응용에 적용하기 위한 연구를 진행할 예정이다.
안성진 교수는 “요슈아 벤지오 교수와의 협력은 차세대 인공지능 기술 개발에 있어 중요한 이정표가 될 것이다”라며, “이 연구를 통해 인간의 전두엽이 수행하는 고위인지 기능을 모방하는 딥러닝 알고리즘을 개발하고, 안전하고 신뢰할 수 있는 인공지능 에이전트를 구현하는 기술적 기반을 마련할 수 있을 것이다”라고 연구의 의의를 설명했다.
이번 연구센터 설립을 통해 우리 대학은 국제적인 연구 네트워크를 강화하고, 인공지능 분야에서 세계적인 선도 기관으로서의 위치를 더욱 공고히 할 전망이다.
2024.09.04 조회수 7472
딥러닝 대부 요슈아 벤지오 교수와 AI 연구센터 설립
우리 대학 전산학부 안성진 교수 연구팀이 세계적인 인공지능 권위자인 캐나다의 요슈아 벤지오(Yoshua Bengio) 교수와 함께 ‘KAIST-밀라(MILA) 프리프론탈 인공지능 연구센터’를 KAIST에 7월 1일부로 설립했다고 4일 밝혔다.
이 사업은 과학기술정보통신부와 한국연구재단이 지원하는 ‘2024년도 해외우수연구기관 협력허브구축사업’의 일환으로, 안성진 교수 연구팀은 2024년 7월부터 2028년 12월까지 총 27억 원의 지원을 받게 된다. 이 센터는 차세대 인공지능 기술 개발을 위한 국제공동연구의 중심지로서 역할을 하게 될 예정이다.
요슈아 벤지오 교수는 딥러닝 분야의 창시자 중 한 명으로, 현대 인공지능 연구에 지대한 영향을 미친 인물이다. 그의 연구는 현재의 딥러닝 기술을 탄생시키고 발전시키는 데 중요한 역할을 했다. KAIST 안성진 교수팀과의 이번 협력은 요슈아 벤지오 교수의 몬트리올 학습 알고리즘 연구소(MILA, Montreal Institute for Learning Algorithms)와 KAIST의 선도적인 인공지능 연구 역량을 결합해, 차세대 인공지능 기술 발전에 새로운 지평을 열 것으로 기대된다.
이번 연구의 핵심은 인간의 고위인지 능력을 모방하는 ‘시스템2’ AI 기술의 개발이다. 시스템2는 데니얼 카네만의 듀얼프로세스 이론에서 제시된 개념으로, 직관적이고 빠른 인지를 담당하는 ‘시스템1‘과 달리, 수학적 논리 추론 같이 복잡하고 순차적인 사고 과정을 담당하는 기능을 수행한다. 이 과정은 주로 뇌의 전두엽에서 이뤄지며, 계획, 판단, 추론 등 고차원적인 인지 기능을 관리한다. 대형언어모델의 발전에도 불구하고, 현재의 딥러닝 기술은 이러한 고위인지 기능을 효과적으로 구현하는 데 여전히 한계를 보이고 있다.
이번 연구는 이러한 한계를 극복하고, 전두엽이 담당하는 고위인지 기능을 AI에 통합하는 ‘프리프론탈 AI’를 구현하기 위한 기반 기술을 확보하는 것을 목표로 한다.
또한, 이번 연구에는 우리 대학 홍승훈 교수와 포항공과대학교(POSTECH)의 안성수 교수도 공동 연구진으로 참여할 예정이다. 홍승훈 교수는 시스템2 메타 학습 알고리즘을 연구하며, 안성수 교수는 시스템2 기능을 ‘과학을 위한 AI(AI4Science)’ 응용에 적용하기 위한 연구를 진행할 예정이다.
안성진 교수는 “요슈아 벤지오 교수와의 협력은 차세대 인공지능 기술 개발에 있어 중요한 이정표가 될 것이다”라며, “이 연구를 통해 인간의 전두엽이 수행하는 고위인지 기능을 모방하는 딥러닝 알고리즘을 개발하고, 안전하고 신뢰할 수 있는 인공지능 에이전트를 구현하는 기술적 기반을 마련할 수 있을 것이다”라고 연구의 의의를 설명했다.
이번 연구센터 설립을 통해 우리 대학은 국제적인 연구 네트워크를 강화하고, 인공지능 분야에서 세계적인 선도 기관으로서의 위치를 더욱 공고히 할 전망이다.
2024.09.04 조회수 7472 -
 인공지능 챗봇 이미지 데이터 훈련 비용 최소화하다
최근 다양한 분야에서 인공지능 심층 학습(딥러닝) 기술을 활용한 서비스가 급속히 증가하고 있다. GPT와 같은 거대 언어 모델을 훈련하기 위해서는 수백 대의 GPU와 몇 주 이상의 시간이 필요하다고 알려져 있다. 따라서, 심층신경망 훈련 비용을 최소화하는 방법 개발이 요구되고 있다.
우리 대학 전산학부 이재길 교수 연구팀이 심층신경망 훈련 비용을 최소화할 수 있도록 훈련 데이터의 양을 줄이는 새로운 데이터 선택 기술을 개발했다고 2일 밝혔다.
일반적으로 대용량의 심층 학습용 훈련 데이터는 레이블 오류(예를 들어, 강아지 사진이 `고양이'라고 잘못 표기되어 있음)를 포함한다. 최신 인공지능 방법론인 재(再)레이블링(Re-labeling) 학습법은 훈련 도중 레이블 오류를 스스로 수정하면서 높은 심층신경망 성능을 달성하는데, 레이블 오류를 수정하기 위한 추가적인 과정들로 인해 훈련에 필요한 시간이 더욱 증가한다는 단점이 있다. 한편 막대한 훈련 시간을 줄이려는 방법으로 중복되거나 성능 향상에 도움이 되지 않는 데이터를 제거해 훈련 데이터의 크기를 줄이는 핵심 집합 선별(coreset selection) 방식이 큰 주목을 받고 있다. 그러나 기존 핵심 집합 선별 방식은 훈련 데이터에 레이블 오류가 없다고 가정한 표준 학습법을 위해 개발됐고, 재레이블링 학습법을 위한 핵심 집합 선별 방식에 관한 연구는 부족한 실정이다.
이재길 교수팀이 개발한 기술은 레이블 오류를 스스로 수정하는 최신 재레이블링 학습법을 위해 핵심 집합 선별을 수행하여 심층 학습 훈련 비용을 최소화할 수 있도록 해준다. 따라서, 레이블 오류가 포함된 현실적인 훈련 데이터를 지원하므로 실용성이 매우 높다.
또한 이 교수팀은 특정 데이터의 레이블 오류 수정 정확도가 해당 데이터의 이웃 데이터의 신뢰도와 높은 상관관계가 있음을 발견했다. 즉, 이웃 데이터의 신뢰도가 높으면 레이블 오류 수정 정확도가 커지는 경향이 있다. 이웃 데이터의 신뢰도는 심층신경망의 충분한 훈련 전에도 측정할 수 있으므로, 각 데이터의 레이블 수정 가능 여부를 예측할 수 있게 된다. 연구팀은 이러한 발견을 기반으로 전체 훈련 데이터의 총합 이웃 신뢰도를 최대화하는 데이터 부분 집합을 선별해 레이블 수정 정확도와 일반화 성능을 최대화하는 `재레이블링을 위한 핵심 집합 선별'을 제안했다. 총합 이웃 신뢰도를 최대화하는 부분 집합을 찾는 조합 최적화 문제의 효율적인 해법을 위해 총합 이웃 신뢰도를 가장 증가시키는 데이터를 차례차례 선택하는 탐욕 알고리즘(greedy algorithm)을 도입했다.
연구팀은 이미지 분류 문제에 대해 다양한 실세계의 훈련 데이터를 사용해 방법론을 검증했다. 그 결과, 레이블 오류가 없다는 가정에 따른 표준 학습법에서는 최대 9%, 재레이블링 학습법에서는 최대 21% 최종 예측 정확도가 기존 방법론에 비해 향상되었고, 모든 범위의 데이터 선별 비율에서 일관되게 최고 성능을 달성했다. 또한, 총합 이웃 신뢰도를 최대화한 효율적 탐욕 알고리즘을 통해 기존 방법론에 비해 획기적으로 시간을 줄이고 수백만 장의 이미지를 포함하는 초대용량 훈련 데이터에도 쉽게 확장될 수 있음을 확인했다.
제1 저자인 박동민 박사과정 학생은 "이번 기술은 오류를 포함한 데이터에 대한 최신 인공지능 방법론의 훈련 가속화를 위한 획기적인 방법ˮ 이라면서 "다양한 데이터 상황에서의 강건성이 검증됐기 때문에, 실생활의 기계 학습 문제에 폭넓게 적용될 수 있어 전반적인 심층 학습의 훈련 데이터 준비 비용 절감에 기여할 것ˮ 이라고 밝혔다.
연구팀을 지도한 이재길 교수도 "이 기술이 파이토치(PyTorch) 혹은 텐서플로우(TensorFlow)와 같은 기존의 심층 학습 라이브러리에 추가되면 기계 학습 및 심층 학습 학계에 큰 파급효과를 낼 수 있을 것이다ˮ고 말했다.
우리 대학 데이터사이언스대학원에 재학 중인 박동민 박사과정 학생이 제1 저자, 최설아 석사과정, 김도영 박사과정 학생이 제2, 제3 저자로 각각 참여한 이번 연구는 최고권위 국제학술대회 `신경정보처리시스템학회(NeurIPS) 2023'에서 올 12월 발표될 예정이다. (논문명 : Robust Data Pruning under Label Noise via Maximizing Re-labeling Accuracy)
한편, 이 기술은 과학기술정보통신부 재원으로 정보통신기획평가원의 지원을 받아 SW컴퓨팅산업원천기술개발사업 SW스타랩 과제로 개발한 연구성과 결과물(2020-0-00862, DB4DL: 딥러닝 지원 고사용성 및 고성능 분산 인메모리 DBMS 개발)이다.
2023.11.02 조회수 6473
인공지능 챗봇 이미지 데이터 훈련 비용 최소화하다
최근 다양한 분야에서 인공지능 심층 학습(딥러닝) 기술을 활용한 서비스가 급속히 증가하고 있다. GPT와 같은 거대 언어 모델을 훈련하기 위해서는 수백 대의 GPU와 몇 주 이상의 시간이 필요하다고 알려져 있다. 따라서, 심층신경망 훈련 비용을 최소화하는 방법 개발이 요구되고 있다.
우리 대학 전산학부 이재길 교수 연구팀이 심층신경망 훈련 비용을 최소화할 수 있도록 훈련 데이터의 양을 줄이는 새로운 데이터 선택 기술을 개발했다고 2일 밝혔다.
일반적으로 대용량의 심층 학습용 훈련 데이터는 레이블 오류(예를 들어, 강아지 사진이 `고양이'라고 잘못 표기되어 있음)를 포함한다. 최신 인공지능 방법론인 재(再)레이블링(Re-labeling) 학습법은 훈련 도중 레이블 오류를 스스로 수정하면서 높은 심층신경망 성능을 달성하는데, 레이블 오류를 수정하기 위한 추가적인 과정들로 인해 훈련에 필요한 시간이 더욱 증가한다는 단점이 있다. 한편 막대한 훈련 시간을 줄이려는 방법으로 중복되거나 성능 향상에 도움이 되지 않는 데이터를 제거해 훈련 데이터의 크기를 줄이는 핵심 집합 선별(coreset selection) 방식이 큰 주목을 받고 있다. 그러나 기존 핵심 집합 선별 방식은 훈련 데이터에 레이블 오류가 없다고 가정한 표준 학습법을 위해 개발됐고, 재레이블링 학습법을 위한 핵심 집합 선별 방식에 관한 연구는 부족한 실정이다.
이재길 교수팀이 개발한 기술은 레이블 오류를 스스로 수정하는 최신 재레이블링 학습법을 위해 핵심 집합 선별을 수행하여 심층 학습 훈련 비용을 최소화할 수 있도록 해준다. 따라서, 레이블 오류가 포함된 현실적인 훈련 데이터를 지원하므로 실용성이 매우 높다.
또한 이 교수팀은 특정 데이터의 레이블 오류 수정 정확도가 해당 데이터의 이웃 데이터의 신뢰도와 높은 상관관계가 있음을 발견했다. 즉, 이웃 데이터의 신뢰도가 높으면 레이블 오류 수정 정확도가 커지는 경향이 있다. 이웃 데이터의 신뢰도는 심층신경망의 충분한 훈련 전에도 측정할 수 있으므로, 각 데이터의 레이블 수정 가능 여부를 예측할 수 있게 된다. 연구팀은 이러한 발견을 기반으로 전체 훈련 데이터의 총합 이웃 신뢰도를 최대화하는 데이터 부분 집합을 선별해 레이블 수정 정확도와 일반화 성능을 최대화하는 `재레이블링을 위한 핵심 집합 선별'을 제안했다. 총합 이웃 신뢰도를 최대화하는 부분 집합을 찾는 조합 최적화 문제의 효율적인 해법을 위해 총합 이웃 신뢰도를 가장 증가시키는 데이터를 차례차례 선택하는 탐욕 알고리즘(greedy algorithm)을 도입했다.
연구팀은 이미지 분류 문제에 대해 다양한 실세계의 훈련 데이터를 사용해 방법론을 검증했다. 그 결과, 레이블 오류가 없다는 가정에 따른 표준 학습법에서는 최대 9%, 재레이블링 학습법에서는 최대 21% 최종 예측 정확도가 기존 방법론에 비해 향상되었고, 모든 범위의 데이터 선별 비율에서 일관되게 최고 성능을 달성했다. 또한, 총합 이웃 신뢰도를 최대화한 효율적 탐욕 알고리즘을 통해 기존 방법론에 비해 획기적으로 시간을 줄이고 수백만 장의 이미지를 포함하는 초대용량 훈련 데이터에도 쉽게 확장될 수 있음을 확인했다.
제1 저자인 박동민 박사과정 학생은 "이번 기술은 오류를 포함한 데이터에 대한 최신 인공지능 방법론의 훈련 가속화를 위한 획기적인 방법ˮ 이라면서 "다양한 데이터 상황에서의 강건성이 검증됐기 때문에, 실생활의 기계 학습 문제에 폭넓게 적용될 수 있어 전반적인 심층 학습의 훈련 데이터 준비 비용 절감에 기여할 것ˮ 이라고 밝혔다.
연구팀을 지도한 이재길 교수도 "이 기술이 파이토치(PyTorch) 혹은 텐서플로우(TensorFlow)와 같은 기존의 심층 학습 라이브러리에 추가되면 기계 학습 및 심층 학습 학계에 큰 파급효과를 낼 수 있을 것이다ˮ고 말했다.
우리 대학 데이터사이언스대학원에 재학 중인 박동민 박사과정 학생이 제1 저자, 최설아 석사과정, 김도영 박사과정 학생이 제2, 제3 저자로 각각 참여한 이번 연구는 최고권위 국제학술대회 `신경정보처리시스템학회(NeurIPS) 2023'에서 올 12월 발표될 예정이다. (논문명 : Robust Data Pruning under Label Noise via Maximizing Re-labeling Accuracy)
한편, 이 기술은 과학기술정보통신부 재원으로 정보통신기획평가원의 지원을 받아 SW컴퓨팅산업원천기술개발사업 SW스타랩 과제로 개발한 연구성과 결과물(2020-0-00862, DB4DL: 딥러닝 지원 고사용성 및 고성능 분산 인메모리 DBMS 개발)이다.
2023.11.02 조회수 6473 -
 면역항암치료 부작용 인공지능으로 예측
면역항암치료는 환자의 면역 시스템을 활성화해 암을 치료하는 혁신적인 3세대 항암 치료 방법으로 알려져 있다. 하지만 면역항암 치료제는 면역활성화에 의해 기존 항암제와는 구분되는 자가면역질환과 유사한 부작용을 유발할 수 있다는 새로운 문제가 제기됐다. 이러한 부작용은 심각한 경우 환자를 죽음에까지 이르게 할 수 있기에 부작용에 대한 연구가 절실한 상황에 놓여있다.
우리 대학 바이오및뇌공학과 최정균 교수팀과 서울아산병원 종양내과 박숙련 교수팀은 면역항암제 치료를 받은 고형암 환자에 대한 대규모 전향적 코호트를 구축하고, 다차원적 분석을 통해 면역항암제 부작용의 위험요인을 규명했다고 22일 밝혔다. 또한 인공지능 딥러닝을 이용해 치료 전 환자에게서 부작용이 나타날지를 예측할 수 있는 모델까지도 개발했다고 알렸다.
기존의 관련 연구들은 소규모로 진행이 되거나, 적은 수의 지표로 국한된 범위에 대해서만 행해졌다. 또한 수행된 연구들은 면역 관련 부작용을 위해 디자인된 연구 설계가 아닌, 다른 목적을 위해 모집된 환자군을 모아 수행하는 후향적 연구 설계로 진행됐다는 한계점이 있었다.
연구팀은 이러한 한계점을 극복하기 위해, 서울아산병원을 필두로 국내 9개 기관과 협력하여 면역 관련 부작용의 포괄적인 위험요인을 밝히기 위한 대규모 전향적 코호트를 구축했다. 또한 환자의 유전체, 전사체, 혈액 지표 등 폭넓은 범위에서 면역 관련 부작용에 대한 위험요인을 밝혀냄으로써, 궁극적으로는 치료 전 미리 환자가 면역항암치료에 대한 부작용을 보일지 알아낼 수 있는 딥러닝 예측 모델을 개발했다. 해당 연구 결과는 다양한 고형암 환자의 임상데이터와 혈액 유전체 데이터에 기반했기에, 향후 환자의 암종과 상관없이 폭넓게 적용될 수 있을 것으로 기대된다.
우리 대학 바이오및뇌공학과 성창환 박사(現 : 서울아산병원 핵의학과)와 안진현 박사과정이 공동 제1 저자로 참여한 이번 연구는 국제 학술지 ‘네이처 캔서(Nature Cancer)’ 에 게재됐다. (논문명 : Integrative analysis of risk factors for immune-related adverse events of checkpoint blockade therapy in cancer).
이번 연구에는 고려대학교 안암병원, 인제대학교 해운대백병원, 국립암센터, 서울삼성병원, 분당서울대학교병원, 고려대학교 구로병원, 연세대학교 세브란스병원, 서울대학교병원의 연구자들도 참여했다.
최정균 교수는 “이번 연구를 통해 면역항암 치료의 아킬레스건이라고 할 수 있는 면역관련 부작용에 대한 폭넓은 분석과 예측모델의 제시를 통해 향후 전세계 연구진이 사용할 수 있는 대규모 면역관련 부작용 리소스를 제공할 수 있을 것이라 기대한다”라고 말했다.
임상연구를 총괄한 서울아산병원 박숙련 교수는 “현재 면역항암제가 임상에서 광범위하게 사용되고 있고 그 치료 영역을 완치적 세팅으로까지 확장하고 있어 치료 효과뿐 아니라 환자 안전성이 더욱 중요한데 그동안 치료 부작용을 예측할 수 있는 좋은 지표가 없던 상황에서, 이번 연구 결과는 개별 환자의 임상데이터와 유전체 데이터에 기반해 면역항암제의 부작용 발생을 예측할 수 있어 암 환자의 정밀 의료 치료를 실현할 수 있는 기반이 될 것으로 기대한다”고 전했다.
이번 연구는 과학기술정보통신부 인공지능 신약개발 플랫폼 구축 사업의 지원을 받아 수행됐다.
2023.06.22 조회수 8175
면역항암치료 부작용 인공지능으로 예측
면역항암치료는 환자의 면역 시스템을 활성화해 암을 치료하는 혁신적인 3세대 항암 치료 방법으로 알려져 있다. 하지만 면역항암 치료제는 면역활성화에 의해 기존 항암제와는 구분되는 자가면역질환과 유사한 부작용을 유발할 수 있다는 새로운 문제가 제기됐다. 이러한 부작용은 심각한 경우 환자를 죽음에까지 이르게 할 수 있기에 부작용에 대한 연구가 절실한 상황에 놓여있다.
우리 대학 바이오및뇌공학과 최정균 교수팀과 서울아산병원 종양내과 박숙련 교수팀은 면역항암제 치료를 받은 고형암 환자에 대한 대규모 전향적 코호트를 구축하고, 다차원적 분석을 통해 면역항암제 부작용의 위험요인을 규명했다고 22일 밝혔다. 또한 인공지능 딥러닝을 이용해 치료 전 환자에게서 부작용이 나타날지를 예측할 수 있는 모델까지도 개발했다고 알렸다.
기존의 관련 연구들은 소규모로 진행이 되거나, 적은 수의 지표로 국한된 범위에 대해서만 행해졌다. 또한 수행된 연구들은 면역 관련 부작용을 위해 디자인된 연구 설계가 아닌, 다른 목적을 위해 모집된 환자군을 모아 수행하는 후향적 연구 설계로 진행됐다는 한계점이 있었다.
연구팀은 이러한 한계점을 극복하기 위해, 서울아산병원을 필두로 국내 9개 기관과 협력하여 면역 관련 부작용의 포괄적인 위험요인을 밝히기 위한 대규모 전향적 코호트를 구축했다. 또한 환자의 유전체, 전사체, 혈액 지표 등 폭넓은 범위에서 면역 관련 부작용에 대한 위험요인을 밝혀냄으로써, 궁극적으로는 치료 전 미리 환자가 면역항암치료에 대한 부작용을 보일지 알아낼 수 있는 딥러닝 예측 모델을 개발했다. 해당 연구 결과는 다양한 고형암 환자의 임상데이터와 혈액 유전체 데이터에 기반했기에, 향후 환자의 암종과 상관없이 폭넓게 적용될 수 있을 것으로 기대된다.
우리 대학 바이오및뇌공학과 성창환 박사(現 : 서울아산병원 핵의학과)와 안진현 박사과정이 공동 제1 저자로 참여한 이번 연구는 국제 학술지 ‘네이처 캔서(Nature Cancer)’ 에 게재됐다. (논문명 : Integrative analysis of risk factors for immune-related adverse events of checkpoint blockade therapy in cancer).
이번 연구에는 고려대학교 안암병원, 인제대학교 해운대백병원, 국립암센터, 서울삼성병원, 분당서울대학교병원, 고려대학교 구로병원, 연세대학교 세브란스병원, 서울대학교병원의 연구자들도 참여했다.
최정균 교수는 “이번 연구를 통해 면역항암 치료의 아킬레스건이라고 할 수 있는 면역관련 부작용에 대한 폭넓은 분석과 예측모델의 제시를 통해 향후 전세계 연구진이 사용할 수 있는 대규모 면역관련 부작용 리소스를 제공할 수 있을 것이라 기대한다”라고 말했다.
임상연구를 총괄한 서울아산병원 박숙련 교수는 “현재 면역항암제가 임상에서 광범위하게 사용되고 있고 그 치료 영역을 완치적 세팅으로까지 확장하고 있어 치료 효과뿐 아니라 환자 안전성이 더욱 중요한데 그동안 치료 부작용을 예측할 수 있는 좋은 지표가 없던 상황에서, 이번 연구 결과는 개별 환자의 임상데이터와 유전체 데이터에 기반해 면역항암제의 부작용 발생을 예측할 수 있어 암 환자의 정밀 의료 치료를 실현할 수 있는 기반이 될 것으로 기대한다”고 전했다.
이번 연구는 과학기술정보통신부 인공지능 신약개발 플랫폼 구축 사업의 지원을 받아 수행됐다.
2023.06.22 조회수 8175 -
 99% 실시간 가스를 구별하는 초저전력 전자 코 기술 개발
우리 대학 기계공학과 박인규 교수, 윤국진 교수와 물리학과 조용훈 교수 공동 연구팀이 `초저전력, 상온 동작이 가능한 광원 일체형 마이크로 LED 가스 센서 기반의 전자 코 시스템'을 개발하는 데 성공했다고 14일 밝혔다.
공동 연구팀은 마이크로 크기의 초소형 LED가 집적된 광원 일체형 가스 센서를 제작한 이후 합성곱 신경망 (CNN) 알고리즘을 적용해 5가지의 미지의 가스를 실시간으로 가스 종류 판별 정확도 99.3%, 농도 값 예측 오차 13.8%의 높은 정확도로 선택적 판별하는 기술을 개발했다. 특히 마이크로 LED를 활용한 광활성 방식의 가스 감지 기술은 기존의 마이크로 히터 방식 대비 소모 전력을 100분의 1 수준으로 획기적으로 절감한 것이 특징이다.
이번 연구에서 개발된 초저전력 전자 코 기술은 어떠한 장소에서든지 배터리 구동 기반으로 장시간 동작할 수 있는 모바일 가스 센서로 활용될 것으로 기대된다.
타깃 가스의 유무에 따라 금속산화물 가스 감지 소재의 전기전도성이 변화하는 원리를 이용한 반도체식 가스 센서는 높은 민감도, 빠른 응답속도, 대량 생산 가능성 등 많은 장점이 있어 활발히 연구되고 있다. 금속산화물 감지 소재가 높은 민감도와 빠른 응답속도를 보이기 위해서는 외부에서 에너지 공급을 통한 활성화가 필요한데 기존에는 집적된 히터를 이용한 줄 히팅 방식이 많이 사용됐다. 고온 가열 방식의 반도체식 가스 센서는 높은 소모전력과 낮은 선택성 등의 한계점이 있었다.
한편, 이번 연구에서 연구팀은 자외선 파장대의 빛을 방출하는 마이크로 크기의 LED를 제작한 후 바로 위에 산화인듐(In2O3) 금속산화물을 집적함으로써 광활성 방식의 가스 센서를 개발했다. 광원과 감지 소재 사이의 거리를 최소화한 광원 일체형 센서 구조는 광 손실을 줄임으로써 μW(마이크로와트) 수준의 초저전력 가스 감지를 실현할 수 있었다. 또한, 연구진은 광 활성식 가스 센서의 반응성을 극대화하기 위해 금속산화물 표면에 금속 나노입자를 코팅해 국소 표면 플라즈몬 공명(Localized surface plasmon resonsance, LSPR)* 현상을 활용했고 이를 통해 센서의 응답도가 향상되는 것을 확인했다.
* 국소표면 플라즈몬 공명에 의해 생성된 핫 전자들이 금속산화물로 이동(Hot electron transfer)해 타깃 가스와의 산화-환원 반응을 촉진하는 원리
그 후, 공동 연구팀은 앞서 설명한 반도체식 가스 센서의 낮은 선택성 문제를 해결하기 위해서 마이크로 LED 가스 센서에 서로 다른 감지 소재를 집적해 센서 어레이를 제작하고 합성곱 신경망의 딥러닝 알고리즘을 적용하여 각 타깃 가스가 만들어내는 고유한 금속산화물의 응답 패턴(저항 변화)을 포착하고 분석했다. 그 결과, 개발된 전자 코 시스템은 총 소모전력 0.38mW(밀리와트)의 초저전력으로 5가지 가스(일반 공기, 이산화질소, 에탄올, 아세톤, 메탄올)를 실시간으로 선택적 판별할 수 있었다.
연구책임자인 기계공학과 박인규 교수는 "마이크로 LED 기반의 광 활성식 가스 센서는 상온 동작이 가능하고 고온 가열 줄히팅을 하는 기존의 반도체식 가스 센서에 비해 소모전력이 100분의 1 수준으로 초저전력 구동이 가능해 대기오염 모니터링, 음식물 부패 관리 모니터링, 헬스케어 등 다양한 분야에서도 응용될 수 있는 기반 기술이 될 것ˮ이라고 연구의 의미를 설명했다.
우리 대학 기계공학과 이기철 박사과정 학생이 제1 저자로 참여하고 한국연구재단의 지원으로 수행된 이번 연구 결과는 나노 과학 분야의 저명한 국제 학술지 `ACS 나노 (ACS Nano)'에 2023년 1월 10일 字 정식 게재됐다. (논문명: Ultra-Low-Power E-Nose System Based on Multi-Micro-LED-Integrated, Nanostructured Gas Sensors and Deep Learning)
2023.02.14 조회수 10032
99% 실시간 가스를 구별하는 초저전력 전자 코 기술 개발
우리 대학 기계공학과 박인규 교수, 윤국진 교수와 물리학과 조용훈 교수 공동 연구팀이 `초저전력, 상온 동작이 가능한 광원 일체형 마이크로 LED 가스 센서 기반의 전자 코 시스템'을 개발하는 데 성공했다고 14일 밝혔다.
공동 연구팀은 마이크로 크기의 초소형 LED가 집적된 광원 일체형 가스 센서를 제작한 이후 합성곱 신경망 (CNN) 알고리즘을 적용해 5가지의 미지의 가스를 실시간으로 가스 종류 판별 정확도 99.3%, 농도 값 예측 오차 13.8%의 높은 정확도로 선택적 판별하는 기술을 개발했다. 특히 마이크로 LED를 활용한 광활성 방식의 가스 감지 기술은 기존의 마이크로 히터 방식 대비 소모 전력을 100분의 1 수준으로 획기적으로 절감한 것이 특징이다.
이번 연구에서 개발된 초저전력 전자 코 기술은 어떠한 장소에서든지 배터리 구동 기반으로 장시간 동작할 수 있는 모바일 가스 센서로 활용될 것으로 기대된다.
타깃 가스의 유무에 따라 금속산화물 가스 감지 소재의 전기전도성이 변화하는 원리를 이용한 반도체식 가스 센서는 높은 민감도, 빠른 응답속도, 대량 생산 가능성 등 많은 장점이 있어 활발히 연구되고 있다. 금속산화물 감지 소재가 높은 민감도와 빠른 응답속도를 보이기 위해서는 외부에서 에너지 공급을 통한 활성화가 필요한데 기존에는 집적된 히터를 이용한 줄 히팅 방식이 많이 사용됐다. 고온 가열 방식의 반도체식 가스 센서는 높은 소모전력과 낮은 선택성 등의 한계점이 있었다.
한편, 이번 연구에서 연구팀은 자외선 파장대의 빛을 방출하는 마이크로 크기의 LED를 제작한 후 바로 위에 산화인듐(In2O3) 금속산화물을 집적함으로써 광활성 방식의 가스 센서를 개발했다. 광원과 감지 소재 사이의 거리를 최소화한 광원 일체형 센서 구조는 광 손실을 줄임으로써 μW(마이크로와트) 수준의 초저전력 가스 감지를 실현할 수 있었다. 또한, 연구진은 광 활성식 가스 센서의 반응성을 극대화하기 위해 금속산화물 표면에 금속 나노입자를 코팅해 국소 표면 플라즈몬 공명(Localized surface plasmon resonsance, LSPR)* 현상을 활용했고 이를 통해 센서의 응답도가 향상되는 것을 확인했다.
* 국소표면 플라즈몬 공명에 의해 생성된 핫 전자들이 금속산화물로 이동(Hot electron transfer)해 타깃 가스와의 산화-환원 반응을 촉진하는 원리
그 후, 공동 연구팀은 앞서 설명한 반도체식 가스 센서의 낮은 선택성 문제를 해결하기 위해서 마이크로 LED 가스 센서에 서로 다른 감지 소재를 집적해 센서 어레이를 제작하고 합성곱 신경망의 딥러닝 알고리즘을 적용하여 각 타깃 가스가 만들어내는 고유한 금속산화물의 응답 패턴(저항 변화)을 포착하고 분석했다. 그 결과, 개발된 전자 코 시스템은 총 소모전력 0.38mW(밀리와트)의 초저전력으로 5가지 가스(일반 공기, 이산화질소, 에탄올, 아세톤, 메탄올)를 실시간으로 선택적 판별할 수 있었다.
연구책임자인 기계공학과 박인규 교수는 "마이크로 LED 기반의 광 활성식 가스 센서는 상온 동작이 가능하고 고온 가열 줄히팅을 하는 기존의 반도체식 가스 센서에 비해 소모전력이 100분의 1 수준으로 초저전력 구동이 가능해 대기오염 모니터링, 음식물 부패 관리 모니터링, 헬스케어 등 다양한 분야에서도 응용될 수 있는 기반 기술이 될 것ˮ이라고 연구의 의미를 설명했다.
우리 대학 기계공학과 이기철 박사과정 학생이 제1 저자로 참여하고 한국연구재단의 지원으로 수행된 이번 연구 결과는 나노 과학 분야의 저명한 국제 학술지 `ACS 나노 (ACS Nano)'에 2023년 1월 10일 字 정식 게재됐다. (논문명: Ultra-Low-Power E-Nose System Based on Multi-Micro-LED-Integrated, Nanostructured Gas Sensors and Deep Learning)
2023.02.14 조회수 10032 -
 똑똑한 영상 복원 인공지능 기술 개발
딥러닝 기술은 영상 복원 속도가 기존 알고리즘 대비 수백 배 이상 빠를 뿐만 아니라 복원 정확도 역시 높다. 하지만, 주어진 학습 데이터에만 의존하는 딥러닝 기술은 영상 취득 환경상에 변화가 생기면 성능이 급격히 저하되는 치명적인 약점이 있다. 이는 알파고와 이세돌 九단과의 대국 시 `신의 한 수'에 의해 알파고의 성능이 급격하게 저하되었던 사례를 떠올리면 쉽게 이해할 수 있다. 즉, 인공지능이 학습하지 못했던 변수(학습 데이터상에 존재하지 않는 수)가 발생할 때 신뢰도가 급격히 낮아지는 인공지능 기술의 근본적인 문제이기도 하다.
우리 대학 바이오및뇌공학과 장무석 교수 연구팀과 김재철AI 대학원 예종철 교수 연구팀이 공동 연구를 통해 인공 지능의 신뢰도 문제를 해결할 수 있는 물리적 학습 기반의 영상 복원 딥러닝 기술을 개발했다고 6일 밝혔다.
연구팀은 영상 취득 환경에서 발생할 수 있는 변수 대부분이 물리적 법칙을 통해 수학적으로 기술 가능하다는 점에 착안해 물리적 법칙과 심층 신경망이 통합된 학습 기법을 제시했다.
모든 영상 기술은 물리적인 영상 기기를 통해 영상 정보를 취득한다. 연구팀은 이 정보 취득 과정에 대한 물리적인 통찰력을 인공지능에 학습시키는 방법을 개발했다. 예를 들면, `네가 도출한 복원 결과가 물리적으로 합당할까?' 혹은 `이 영상 기기는 물리적으로 이런 변수가 생길 수 있을 것 같은데?'라는 식의 질문을 통해 물리적 통찰력을 인공지능에 이식하는 방법을 제시한 것이다.
연구팀은 변화하는 영상 취득 환경에서도 신뢰도 높은 홀로그래피 영상* 을 복원하는데 성공했다. 홀로그래피 영상 기술은 의료 영상, 군용 감시, 자율 주행용 영상 등 다양한 정밀 영상 기술에 다양하게 활용될 수 있는데, 이번 연구는 의료 진단 분야의 활용성을 집중적으로 검증하였다.
*홀로그래피 영상: 물체의 그림자 패턴(회절 패턴)으로부터 물체의 형태를 복원하는 영상 기법, 일반적인 영상 기술과 달리 위상 변화에 의한 물체의 미세 구조를 감지할 수 있는 영상 기술
연구팀은 먼저 3차원 공간상에서 매우 빠르게 움직이는 적혈구의 회절 영상(확산된 그림자형상)으로부터 적혈구의 형태를 실시간으로 복원하는데 성공했다. 이러한 동적인 영상 환경에서 예상치 못한 변수로는 여러 개의 적혈구 덩어리가 복잡하게 겹쳐진다거나 적혈구가 예상하지 못했던 위치로 흘러가는 경우를 생각해 볼 수 있다. 여기서, 연구팀은 인공 지능이 생성한 영상이 합당한 결과인지 빛 전파 이론을 통해 검산하는 방식으로 물리적으로 유효한 복원 신뢰도를 구현하는데 성공하였다.
연구팀은 암 진단의 표준기술로 자리잡고 있는 생검 조직(생체에서 조직 일부를 메스나 바늘로 채취하는 것)의 영상 복원에도 성공했다. 주목할 점은 특정한 카메라 위치에서 측정된 회절 영상만을 학습했음에도 인공지능의 인지능력이 부가되어 다양한 카메라 위치에서도 물체를 인식하는데 성공했다는 점이다. 이번에 구현된 기술은 세포 염색 과정이나 수 천 만원에 달하는 현미경이 필요하지 않아 생검 조직 검사의 속도와 비용을 크게 개선할 수 있을 것으로 기대된다.
물리적 통찰력을 인공 지능에 이식하는 영상 복원 기술은 의료 진단 분야 뿐만 아니라 광범위한 영상 기술에 활용될 것으로 기대된다. 최근 영상 기술 산업계 (모바일 기기 카메라, 의료 진단용 MRI, CT, 광 기반 반도체 공정 불량 검출 등) 에선 인공지능 솔루션 탑재가 활발히 이루어지고 있다. 영상 취득에 사용되는 센서, 물체의 밝기, 물체까지의 거리와 같은 영상 취득 환경은 사용자마다 다를 수밖에 없어 적응 능력을 갖춘 인공 지능 솔루션에 대한 수요가 큰 상황이다. 현재 대부분의 인공 지능 기술은 적응 능력 부재로 신뢰도가 낮은 문제 때문에 실제 현장에서 활용성이 제한적인 상황이다.
바이오및뇌공학과 이찬석 연구원은 "데이터와 물리 법칙을 동시에 학습하는 적응형 인공지능 기술은 홀로그래피 영상뿐만 아니라 초고해상도 영상, 3차원 영상, 비시선 영상(장애물 뒷면을 보는 영상) 등 다양한 계산 영상 기술에 적용될 수 있을 것으로 기대된다ˮ고 밝혔다.
연구진은 "이번 연구를 통해 인공지능 학습에 있어서 학습 데이터에 대한 강한 의존성(신뢰도 문제)을 물리적 법칙을 결합해 해소했을 뿐만 아니라, 이미지 복원에 있어 매게 변수화된 전방 모델을 기반으로 했기 때문에 신뢰도와 적응성이 크게 향상됐다ˮ며, 이어 "이번 연구에서는 데이터의 다양한 특성 중에서 수학적 혹은 물리적으로 정확히 다룰 수 있는 측면에 집중했고, 향후 무작위적인 잡음이나 데이터의 형태에 대해서도 제약받지 않는 범용 복원 알고리즘을 개발하는 데 주력할 것이다ˮ라고 밝혔다.
바이오및뇌공학과 이찬석 박사과정이 제1 저자로 참여한 이번 연구는 국제 학술지 `네이처 머신 인텔리전스(Nature Machine Intelligence)'에 지난 1월 17일 字 출판됐다. (논문명: Deep learning based on parameterized physical forward model for adaptive holographic imaging with unpaired data)
한편 이번 연구는 삼성미래기술육성사업과 선도연구센터사업의 지원을 받아 수행됐다.
2023.02.06 조회수 8847
똑똑한 영상 복원 인공지능 기술 개발
딥러닝 기술은 영상 복원 속도가 기존 알고리즘 대비 수백 배 이상 빠를 뿐만 아니라 복원 정확도 역시 높다. 하지만, 주어진 학습 데이터에만 의존하는 딥러닝 기술은 영상 취득 환경상에 변화가 생기면 성능이 급격히 저하되는 치명적인 약점이 있다. 이는 알파고와 이세돌 九단과의 대국 시 `신의 한 수'에 의해 알파고의 성능이 급격하게 저하되었던 사례를 떠올리면 쉽게 이해할 수 있다. 즉, 인공지능이 학습하지 못했던 변수(학습 데이터상에 존재하지 않는 수)가 발생할 때 신뢰도가 급격히 낮아지는 인공지능 기술의 근본적인 문제이기도 하다.
우리 대학 바이오및뇌공학과 장무석 교수 연구팀과 김재철AI 대학원 예종철 교수 연구팀이 공동 연구를 통해 인공 지능의 신뢰도 문제를 해결할 수 있는 물리적 학습 기반의 영상 복원 딥러닝 기술을 개발했다고 6일 밝혔다.
연구팀은 영상 취득 환경에서 발생할 수 있는 변수 대부분이 물리적 법칙을 통해 수학적으로 기술 가능하다는 점에 착안해 물리적 법칙과 심층 신경망이 통합된 학습 기법을 제시했다.
모든 영상 기술은 물리적인 영상 기기를 통해 영상 정보를 취득한다. 연구팀은 이 정보 취득 과정에 대한 물리적인 통찰력을 인공지능에 학습시키는 방법을 개발했다. 예를 들면, `네가 도출한 복원 결과가 물리적으로 합당할까?' 혹은 `이 영상 기기는 물리적으로 이런 변수가 생길 수 있을 것 같은데?'라는 식의 질문을 통해 물리적 통찰력을 인공지능에 이식하는 방법을 제시한 것이다.
연구팀은 변화하는 영상 취득 환경에서도 신뢰도 높은 홀로그래피 영상* 을 복원하는데 성공했다. 홀로그래피 영상 기술은 의료 영상, 군용 감시, 자율 주행용 영상 등 다양한 정밀 영상 기술에 다양하게 활용될 수 있는데, 이번 연구는 의료 진단 분야의 활용성을 집중적으로 검증하였다.
*홀로그래피 영상: 물체의 그림자 패턴(회절 패턴)으로부터 물체의 형태를 복원하는 영상 기법, 일반적인 영상 기술과 달리 위상 변화에 의한 물체의 미세 구조를 감지할 수 있는 영상 기술
연구팀은 먼저 3차원 공간상에서 매우 빠르게 움직이는 적혈구의 회절 영상(확산된 그림자형상)으로부터 적혈구의 형태를 실시간으로 복원하는데 성공했다. 이러한 동적인 영상 환경에서 예상치 못한 변수로는 여러 개의 적혈구 덩어리가 복잡하게 겹쳐진다거나 적혈구가 예상하지 못했던 위치로 흘러가는 경우를 생각해 볼 수 있다. 여기서, 연구팀은 인공 지능이 생성한 영상이 합당한 결과인지 빛 전파 이론을 통해 검산하는 방식으로 물리적으로 유효한 복원 신뢰도를 구현하는데 성공하였다.
연구팀은 암 진단의 표준기술로 자리잡고 있는 생검 조직(생체에서 조직 일부를 메스나 바늘로 채취하는 것)의 영상 복원에도 성공했다. 주목할 점은 특정한 카메라 위치에서 측정된 회절 영상만을 학습했음에도 인공지능의 인지능력이 부가되어 다양한 카메라 위치에서도 물체를 인식하는데 성공했다는 점이다. 이번에 구현된 기술은 세포 염색 과정이나 수 천 만원에 달하는 현미경이 필요하지 않아 생검 조직 검사의 속도와 비용을 크게 개선할 수 있을 것으로 기대된다.
물리적 통찰력을 인공 지능에 이식하는 영상 복원 기술은 의료 진단 분야 뿐만 아니라 광범위한 영상 기술에 활용될 것으로 기대된다. 최근 영상 기술 산업계 (모바일 기기 카메라, 의료 진단용 MRI, CT, 광 기반 반도체 공정 불량 검출 등) 에선 인공지능 솔루션 탑재가 활발히 이루어지고 있다. 영상 취득에 사용되는 센서, 물체의 밝기, 물체까지의 거리와 같은 영상 취득 환경은 사용자마다 다를 수밖에 없어 적응 능력을 갖춘 인공 지능 솔루션에 대한 수요가 큰 상황이다. 현재 대부분의 인공 지능 기술은 적응 능력 부재로 신뢰도가 낮은 문제 때문에 실제 현장에서 활용성이 제한적인 상황이다.
바이오및뇌공학과 이찬석 연구원은 "데이터와 물리 법칙을 동시에 학습하는 적응형 인공지능 기술은 홀로그래피 영상뿐만 아니라 초고해상도 영상, 3차원 영상, 비시선 영상(장애물 뒷면을 보는 영상) 등 다양한 계산 영상 기술에 적용될 수 있을 것으로 기대된다ˮ고 밝혔다.
연구진은 "이번 연구를 통해 인공지능 학습에 있어서 학습 데이터에 대한 강한 의존성(신뢰도 문제)을 물리적 법칙을 결합해 해소했을 뿐만 아니라, 이미지 복원에 있어 매게 변수화된 전방 모델을 기반으로 했기 때문에 신뢰도와 적응성이 크게 향상됐다ˮ며, 이어 "이번 연구에서는 데이터의 다양한 특성 중에서 수학적 혹은 물리적으로 정확히 다룰 수 있는 측면에 집중했고, 향후 무작위적인 잡음이나 데이터의 형태에 대해서도 제약받지 않는 범용 복원 알고리즘을 개발하는 데 주력할 것이다ˮ라고 밝혔다.
바이오및뇌공학과 이찬석 박사과정이 제1 저자로 참여한 이번 연구는 국제 학술지 `네이처 머신 인텔리전스(Nature Machine Intelligence)'에 지난 1월 17일 字 출판됐다. (논문명: Deep learning based on parameterized physical forward model for adaptive holographic imaging with unpaired data)
한편 이번 연구는 삼성미래기술육성사업과 선도연구센터사업의 지원을 받아 수행됐다.
2023.02.06 조회수 8847 -
 실시간 나노 측정이 가능한 3D 표면예측 기술 개발
우리 대학 기계공학과 이정철 교수 연구팀이 현미경 사진을 이용해 나노 스케일 3D 표면을 예측하는 딥러닝 기반 방법론을 제시했다고 17일 밝혔다.
물리적 접촉 기반으로 나노 스케일의 표면 형상을 3D 측정하는 원자현미경은 웨이퍼 소자 검사 등 반도체 산업에서 사용되고 있다. 하지만, 원자현미경은 물리적으로 표면을 스캔하기 때문에 측정 속도*가 느리고, 고온 극한 환경에서는 작동할 수 없다는 단점을 지닌다.
* 측정 속도를 높이기 위해 표면 스캔 방식의 효율을 개선해 20 FPS(초당 프레임 수) 수준의 비디오 프레임 원자현미경이 개발됐지만, 측정 가능한 표면의 면적이 100제곱마이크로미터(μm2) 수준으로 제한되며, 극한의 환경에서는 여전히 작동이 제한된다.
이에 연구팀은 비접촉 측정 방법인 광 현미경에서 딥러닝을 이용하여 원자현미경으로 얻어질 수 있는 나노 스케일 3D 표면을 예측했다. 비슷한 개념인 사진에서 깊이를 예측하는 기술은 자율주행을 위해 많이 연구되고 있는 분야다. 연구팀은 이러한 기술이 적용되는 스케일을 일상생활 범위에서 나노 스케일 범위로 옮겨 인공지능 모델을 훈련했다. 인공지능 모델로는 입력 데이터에서 대상의 특징을 추출하고, 추출된 특징에서 출력 데이터를 표현하는 인코더-디코더 구조*를 활용했다. 연구팀이 제안한 모델은 광 현미경 사진을 하나의 변수로 표현하고, 이후 이 변수에서 현미경 사진을 3D 표면으로 계산하여 나타내는데 성공했다.
*인코더-디코더 구조: 입력 데이터에서 인공 신경망 혹은 합성곱 층을 이용하여 데이터의 크기 및 차원을 추출하며 특징을 추출하고 (인코더), 추출된 특징에서 출력 데이터를 생성하는 (디코더) 구조. 활용 목적에 따라 추출된 특징 혹은 출력 데이터가 사용됨.
연구팀은 제안된 방법론을 반도체 산업의 센서, 태양 전지 및 나노 입자 제작에 응용되는 저메니움(게르마늄) 자가조립 구조*의 공정 중 분석 및 검사를 위해 적용했다. 광 현미경 사진을 이용해 15% 오차 수준 이내에서 1.72배까지 더 높은 해상도의 높이 맵을 예측하였는데, 이를 기반으로 각 응용에 필요한 형상의 자가조립 구조가 만들어지도록 실시간으로 공정 과정을 검사하였다. 또한, 같은 딥러닝 모델로 어닐링(가열) 중 동적으로 변하는 표면 형상을 시뮬레이션 하여 공정 과정을 분석 및 최적화하여 기존 공정으로는 불가능했던 공동의 형상을 만들어냈다.
* 저메니움 자가조립 구조란, 저메니움 웨이퍼에 마이크로 단위 수직 구멍을 식각 후 고온 어닐링(가열)을 하면 생기는 표면 아래의 공동을 뜻한다. 가열과정 중 구멍이 식각된 표면이 닫히고, 이후 표면과 표면 아래 공동의 형상이 함께 변하는데 공동의 형상에 따라 각기 다른 용도로 활용된다. 연구팀은 이렇게 동적으로 변하는 구조의 표면 높이 맵을 예측했다.
이번 연구에서 제안된 딥러닝 기반 방법론은 원자현미경으로는 제한돼있던 나노 스케일 표면 높이 맵 측정을 1 제곱밀리미터(mm2) 까지의 넓은 표면에 대해 기존 원자현미경 측정 속도 대비 10배에 해당하는 200 FPS까지 측정 가능하도록 속도를 높였으며, 광학을 이용한 비접촉 관측이기에 극한의 열 환경에서도 측정이 가능한 방법을 제시한 데에 의의가 있다. 이번 연구는 광학 현미경 해상도의 물리적 한계인 빛의 파장 이하의 작은 나노 스케일에서 동적인 현상을 현미경만으로 분석할 수 있게 해, 공정 중 혹은 이후 표면 분석이 필요한 재료, 물리, 화학 등에서의 나노 스케일 연구를 촉진할 것으로 기대된다.
또한 학계 뿐 아니라 산업계에서도 쓰일 것으로 기대된다. 향후 반도체 사업에는 웨이퍼의 표면 분석 속도와 정확도를 개선함으로서, 반도체 공정 시 생산 속도와 정밀한 측정으로 수율 개선에 기여할 수 있다.
연구를 주도한 이정철 교수는 "개발된 기술은 시간에 따라 변화하는 반도체 표면 및 내부 구조에 대해 불연속적인 저해상도 광학 현미경 사진 몇 장만 이용해서, 연속적인 고해상도 원자현미경 동영상을 생성해내는 최초의 연구로서, 극한 공정 중 실시간 나노 측정을 대체하는 효과를 가져와 반도체 및 첨단센서 산업 발전에 기여할 것ˮ이라고 말했다.
한편, 이번 연구는 국제 학술지 어드밴스드 인텔리전트 시스템(Advanced Intelligent Systems)에 지난 12월 20일 字에 온라인 게재됐으며, 23년 1사분기의 표지 논문(Inside back cover) 중 하나로 선정됐다. 이번 연구는 한국연구재단의 중견연구자지원사업과 기초연구실 지원사업의 지원을 받아 수행됐다.
2023.01.17 조회수 7922
실시간 나노 측정이 가능한 3D 표면예측 기술 개발
우리 대학 기계공학과 이정철 교수 연구팀이 현미경 사진을 이용해 나노 스케일 3D 표면을 예측하는 딥러닝 기반 방법론을 제시했다고 17일 밝혔다.
물리적 접촉 기반으로 나노 스케일의 표면 형상을 3D 측정하는 원자현미경은 웨이퍼 소자 검사 등 반도체 산업에서 사용되고 있다. 하지만, 원자현미경은 물리적으로 표면을 스캔하기 때문에 측정 속도*가 느리고, 고온 극한 환경에서는 작동할 수 없다는 단점을 지닌다.
* 측정 속도를 높이기 위해 표면 스캔 방식의 효율을 개선해 20 FPS(초당 프레임 수) 수준의 비디오 프레임 원자현미경이 개발됐지만, 측정 가능한 표면의 면적이 100제곱마이크로미터(μm2) 수준으로 제한되며, 극한의 환경에서는 여전히 작동이 제한된다.
이에 연구팀은 비접촉 측정 방법인 광 현미경에서 딥러닝을 이용하여 원자현미경으로 얻어질 수 있는 나노 스케일 3D 표면을 예측했다. 비슷한 개념인 사진에서 깊이를 예측하는 기술은 자율주행을 위해 많이 연구되고 있는 분야다. 연구팀은 이러한 기술이 적용되는 스케일을 일상생활 범위에서 나노 스케일 범위로 옮겨 인공지능 모델을 훈련했다. 인공지능 모델로는 입력 데이터에서 대상의 특징을 추출하고, 추출된 특징에서 출력 데이터를 표현하는 인코더-디코더 구조*를 활용했다. 연구팀이 제안한 모델은 광 현미경 사진을 하나의 변수로 표현하고, 이후 이 변수에서 현미경 사진을 3D 표면으로 계산하여 나타내는데 성공했다.
*인코더-디코더 구조: 입력 데이터에서 인공 신경망 혹은 합성곱 층을 이용하여 데이터의 크기 및 차원을 추출하며 특징을 추출하고 (인코더), 추출된 특징에서 출력 데이터를 생성하는 (디코더) 구조. 활용 목적에 따라 추출된 특징 혹은 출력 데이터가 사용됨.
연구팀은 제안된 방법론을 반도체 산업의 센서, 태양 전지 및 나노 입자 제작에 응용되는 저메니움(게르마늄) 자가조립 구조*의 공정 중 분석 및 검사를 위해 적용했다. 광 현미경 사진을 이용해 15% 오차 수준 이내에서 1.72배까지 더 높은 해상도의 높이 맵을 예측하였는데, 이를 기반으로 각 응용에 필요한 형상의 자가조립 구조가 만들어지도록 실시간으로 공정 과정을 검사하였다. 또한, 같은 딥러닝 모델로 어닐링(가열) 중 동적으로 변하는 표면 형상을 시뮬레이션 하여 공정 과정을 분석 및 최적화하여 기존 공정으로는 불가능했던 공동의 형상을 만들어냈다.
* 저메니움 자가조립 구조란, 저메니움 웨이퍼에 마이크로 단위 수직 구멍을 식각 후 고온 어닐링(가열)을 하면 생기는 표면 아래의 공동을 뜻한다. 가열과정 중 구멍이 식각된 표면이 닫히고, 이후 표면과 표면 아래 공동의 형상이 함께 변하는데 공동의 형상에 따라 각기 다른 용도로 활용된다. 연구팀은 이렇게 동적으로 변하는 구조의 표면 높이 맵을 예측했다.
이번 연구에서 제안된 딥러닝 기반 방법론은 원자현미경으로는 제한돼있던 나노 스케일 표면 높이 맵 측정을 1 제곱밀리미터(mm2) 까지의 넓은 표면에 대해 기존 원자현미경 측정 속도 대비 10배에 해당하는 200 FPS까지 측정 가능하도록 속도를 높였으며, 광학을 이용한 비접촉 관측이기에 극한의 열 환경에서도 측정이 가능한 방법을 제시한 데에 의의가 있다. 이번 연구는 광학 현미경 해상도의 물리적 한계인 빛의 파장 이하의 작은 나노 스케일에서 동적인 현상을 현미경만으로 분석할 수 있게 해, 공정 중 혹은 이후 표면 분석이 필요한 재료, 물리, 화학 등에서의 나노 스케일 연구를 촉진할 것으로 기대된다.
또한 학계 뿐 아니라 산업계에서도 쓰일 것으로 기대된다. 향후 반도체 사업에는 웨이퍼의 표면 분석 속도와 정확도를 개선함으로서, 반도체 공정 시 생산 속도와 정밀한 측정으로 수율 개선에 기여할 수 있다.
연구를 주도한 이정철 교수는 "개발된 기술은 시간에 따라 변화하는 반도체 표면 및 내부 구조에 대해 불연속적인 저해상도 광학 현미경 사진 몇 장만 이용해서, 연속적인 고해상도 원자현미경 동영상을 생성해내는 최초의 연구로서, 극한 공정 중 실시간 나노 측정을 대체하는 효과를 가져와 반도체 및 첨단센서 산업 발전에 기여할 것ˮ이라고 말했다.
한편, 이번 연구는 국제 학술지 어드밴스드 인텔리전트 시스템(Advanced Intelligent Systems)에 지난 12월 20일 字에 온라인 게재됐으며, 23년 1사분기의 표지 논문(Inside back cover) 중 하나로 선정됐다. 이번 연구는 한국연구재단의 중견연구자지원사업과 기초연구실 지원사업의 지원을 받아 수행됐다.
2023.01.17 조회수 7922 -
 세계 최고 수준의 딥러닝 의사결정 설명기술 개발
우리 대학 김재철AI대학원 최재식 교수(㈜인이지 대표이사) 연구팀이 인공지능 딥러닝의 의사결정에 큰 영향을 미치는 입력 변수의 기여도를 계산하는 세계 최고 수준의 기술을 개발했다고 23일 밝혔다.
최근 딥러닝 모델은 문서 자동 번역이나 자율 주행 등 실생활에 널리 보급되고 활용되는 추세 및 발전에도 불구하고 비선형적이고 복잡한 모델의 구조와 고차원의 입력 데이터로 인해 정확한 모델 예측의 근거를 제시하기 어렵다. 이처럼 부족한 설명성은 딥러닝이 국방, 의료, 금융과 같이 의사결정에 대한 근거가 필요한 중요한 작업에 대한 적용을 어렵게 한다. 따라서 적용 분야의 확장을 위해 딥러닝의 부족한 설명성은 반드시 해결해야 할 문제다.
최교수 연구팀은 딥러닝 모델이 국소적인 입력 공간에서 보이는 입력 데이터와 예측 사이의 관계를 기반으로, 입력 데이터의 특징 중 모델 예측의 기여도가 높은 특징만을 점진적으로 추출해나가는 알고리즘과 그 과정에서의 입력과 예측 사이의 관계를 종합하는 방법을 고안해 모델의 예측 과정에 기여하는 입력 특징의 정확한 기여도를 계산했다. 해당 기술은 모델 구조에 대한 의존성이 없어 다양한 기존 학습 모델에서도 적용이 가능하며, 딥러닝 예측 모델의 판단 근거를 제공함으로써 신뢰도를 높여 딥러닝 모델의 활용성에도 크게 기여할 것으로 기대된다.
㈜인이지의 전기영 연구원, 우리 대학 김재철AI대학원의 정해동 연구원이 공동 제1 저자로 참여한 이번 연구는 오는 12월 1일, 국제 학술대회 `신경정보처리학회(Neural Information Processing Systems, NeurIPS) 2022'에서 발표될 예정이다.
모델의 예측에 대한 입력 특징의 기여도를 계산하는 문제는 해석이 불가능한 딥러닝 모델의 작동 방식을 설명하는 직관적인 방법 중 하나다. 특히, 이미지 데이터를 다루는 문제에서는 모델의 예측 과정에 많이 기여한 부분을 강조하는 방식으로 시각화해 설명을 제공한다.
딥러닝 예측 모델의 입력 기여도를 정확하게 계산하기 위해서 모델의 경사도를 이용하거나, 입력 섭동(행동을 다스림)을 이용하는 등의 연구가 활발히 진행되고 있다. 그러나 경사도를 이용한 방식의 경우 결과물에 잡음이 많아 신뢰성을 확보하기 어렵고, 입력 섭동을 이용하는 경우 모든 경우의 섭동을 시도해야 하지만 너무 많은 연산을 요구하기 때문에, 근사치를 추정한 결과만을 얻을 수 있다.
연구팀은 이러한 문제 해결을 위해 입력 데이터의 특징 중에서 모델의 예측과 연관성이 적은 특징을 점진적으로 제거해나가는 증류 알고리즘을 개발했다. 증류 알고리즘은 딥러닝 모델이 국소적으로 보이는 입력 데이터와 예측 사이의 관계에 기반해 상대적으로 예측에 기여도가 적은 특징을 선별 및 제거하며, 이러한 과정의 반복을 통해 증류된 입력 데이터에는 기여도가 높은 특징만 남게 된다. 또한, 해당 과정을 통해 얻게 되는 변형된 데이터에 대한 국소적 입력 기여도를 종합해 신뢰도 높은 최종 입력 기여도를 산출한다.
연구팀의 이러한 입력 기여도 측정 기술은 산업공정 최적화 프로젝트에 적용해 딥러닝 모델이 예측 결과를 도출하기 위해서 어떤 입력 특징에 주목하는지 찾을 수 있었다. 또한 딥러닝 모델의 구조에 상관없이 적용할 수 있는 이 기술을 바탕으로 복잡한 공정 내부의 다양한 예측변수 간 상관관계를 정확하게 분석하고 예측함으로써 공정 최적화(에너지 절감, 품질향상, 생산량 증가)의 효과를 도출할 수 있었다.
연구팀은 잘 알려진 이미지 분류 모델인 VGG-16, ResNet-18, Inception-v3 모델에서 개발 기술이 입력 기여도를 계산하는 데에 효과가 있음을 확인했다. 해당 기술은 구글(Google)이 보유하고 텐서플로우 설명가능 인공지능(TensorFlow Explainable AI) 툴 키트에 적용된 것으로 알려진 입력 기여도 측정 기술(Guided Integrated Gradient) 대비 LeRF/MoRF 점수가 각각 최대 0.436/0.020 개선됨을 보였다. 특히, 입력 기여도의 시각화를 비교했을 때, 기존 방식 대비 잡음이 적고, 주요 객체와 잘 정렬됐으며, 선명한 결과를 보였다. 연구팀은 여러 가지 모델 구조에 대해 신뢰도 높은 입력 기여도 계산 성능을 보임으로써, 개발 기술의 유효성과 확장성을 보였다.
연구팀이 개발한 딥러닝 모델의 입력 기여도 측정 기술은 이미지 외에도 다양한 예측 모델에 적용돼 모델의 예측에 대한 신뢰성을 높일 것으로 기대된다.
전기영 연구원은 "딥러닝 모델의 국소 지역에서 계산된 입력 기여도를 기반으로 상대적인 중요도가 낮은 입력을 점진적으로 제거하며, 이러한 과정에서 축적된 입력 기여도를 종합해 더욱 정확한 설명을 제공할 수 있음을 보였다ˮ라며 "딥러닝 모델에 대해 신뢰도 높은 설명을 제공하기 위해서는 입력 데이터를 적절히 변형한 상황에서도 모델 예측과 관련도가 높은 입력 특성에 주목해야 한다ˮ라고 말했다.
이번 연구는 2022년도 과학기술정보통신부의 재원으로 정보통신기획평가원의 지원을 받은 사람 중심 AI강국 실현을 위한 차세대 인공지능 핵심원천기술개발 사용자 맞춤형 플로그앤플레이 방식의 설명가능성 제공, 한국과학기술원 인공지능 대학원 프로그램, 인공지능 공정성 AIDEP 및 국방과학연구소의 지원을 받은 설명 가능 인공지능 프로젝트 및 인이지의 지원으로 수행됐다.
2022.11.23 조회수 11159
세계 최고 수준의 딥러닝 의사결정 설명기술 개발
우리 대학 김재철AI대학원 최재식 교수(㈜인이지 대표이사) 연구팀이 인공지능 딥러닝의 의사결정에 큰 영향을 미치는 입력 변수의 기여도를 계산하는 세계 최고 수준의 기술을 개발했다고 23일 밝혔다.
최근 딥러닝 모델은 문서 자동 번역이나 자율 주행 등 실생활에 널리 보급되고 활용되는 추세 및 발전에도 불구하고 비선형적이고 복잡한 모델의 구조와 고차원의 입력 데이터로 인해 정확한 모델 예측의 근거를 제시하기 어렵다. 이처럼 부족한 설명성은 딥러닝이 국방, 의료, 금융과 같이 의사결정에 대한 근거가 필요한 중요한 작업에 대한 적용을 어렵게 한다. 따라서 적용 분야의 확장을 위해 딥러닝의 부족한 설명성은 반드시 해결해야 할 문제다.
최교수 연구팀은 딥러닝 모델이 국소적인 입력 공간에서 보이는 입력 데이터와 예측 사이의 관계를 기반으로, 입력 데이터의 특징 중 모델 예측의 기여도가 높은 특징만을 점진적으로 추출해나가는 알고리즘과 그 과정에서의 입력과 예측 사이의 관계를 종합하는 방법을 고안해 모델의 예측 과정에 기여하는 입력 특징의 정확한 기여도를 계산했다. 해당 기술은 모델 구조에 대한 의존성이 없어 다양한 기존 학습 모델에서도 적용이 가능하며, 딥러닝 예측 모델의 판단 근거를 제공함으로써 신뢰도를 높여 딥러닝 모델의 활용성에도 크게 기여할 것으로 기대된다.
㈜인이지의 전기영 연구원, 우리 대학 김재철AI대학원의 정해동 연구원이 공동 제1 저자로 참여한 이번 연구는 오는 12월 1일, 국제 학술대회 `신경정보처리학회(Neural Information Processing Systems, NeurIPS) 2022'에서 발표될 예정이다.
모델의 예측에 대한 입력 특징의 기여도를 계산하는 문제는 해석이 불가능한 딥러닝 모델의 작동 방식을 설명하는 직관적인 방법 중 하나다. 특히, 이미지 데이터를 다루는 문제에서는 모델의 예측 과정에 많이 기여한 부분을 강조하는 방식으로 시각화해 설명을 제공한다.
딥러닝 예측 모델의 입력 기여도를 정확하게 계산하기 위해서 모델의 경사도를 이용하거나, 입력 섭동(행동을 다스림)을 이용하는 등의 연구가 활발히 진행되고 있다. 그러나 경사도를 이용한 방식의 경우 결과물에 잡음이 많아 신뢰성을 확보하기 어렵고, 입력 섭동을 이용하는 경우 모든 경우의 섭동을 시도해야 하지만 너무 많은 연산을 요구하기 때문에, 근사치를 추정한 결과만을 얻을 수 있다.
연구팀은 이러한 문제 해결을 위해 입력 데이터의 특징 중에서 모델의 예측과 연관성이 적은 특징을 점진적으로 제거해나가는 증류 알고리즘을 개발했다. 증류 알고리즘은 딥러닝 모델이 국소적으로 보이는 입력 데이터와 예측 사이의 관계에 기반해 상대적으로 예측에 기여도가 적은 특징을 선별 및 제거하며, 이러한 과정의 반복을 통해 증류된 입력 데이터에는 기여도가 높은 특징만 남게 된다. 또한, 해당 과정을 통해 얻게 되는 변형된 데이터에 대한 국소적 입력 기여도를 종합해 신뢰도 높은 최종 입력 기여도를 산출한다.
연구팀의 이러한 입력 기여도 측정 기술은 산업공정 최적화 프로젝트에 적용해 딥러닝 모델이 예측 결과를 도출하기 위해서 어떤 입력 특징에 주목하는지 찾을 수 있었다. 또한 딥러닝 모델의 구조에 상관없이 적용할 수 있는 이 기술을 바탕으로 복잡한 공정 내부의 다양한 예측변수 간 상관관계를 정확하게 분석하고 예측함으로써 공정 최적화(에너지 절감, 품질향상, 생산량 증가)의 효과를 도출할 수 있었다.
연구팀은 잘 알려진 이미지 분류 모델인 VGG-16, ResNet-18, Inception-v3 모델에서 개발 기술이 입력 기여도를 계산하는 데에 효과가 있음을 확인했다. 해당 기술은 구글(Google)이 보유하고 텐서플로우 설명가능 인공지능(TensorFlow Explainable AI) 툴 키트에 적용된 것으로 알려진 입력 기여도 측정 기술(Guided Integrated Gradient) 대비 LeRF/MoRF 점수가 각각 최대 0.436/0.020 개선됨을 보였다. 특히, 입력 기여도의 시각화를 비교했을 때, 기존 방식 대비 잡음이 적고, 주요 객체와 잘 정렬됐으며, 선명한 결과를 보였다. 연구팀은 여러 가지 모델 구조에 대해 신뢰도 높은 입력 기여도 계산 성능을 보임으로써, 개발 기술의 유효성과 확장성을 보였다.
연구팀이 개발한 딥러닝 모델의 입력 기여도 측정 기술은 이미지 외에도 다양한 예측 모델에 적용돼 모델의 예측에 대한 신뢰성을 높일 것으로 기대된다.
전기영 연구원은 "딥러닝 모델의 국소 지역에서 계산된 입력 기여도를 기반으로 상대적인 중요도가 낮은 입력을 점진적으로 제거하며, 이러한 과정에서 축적된 입력 기여도를 종합해 더욱 정확한 설명을 제공할 수 있음을 보였다ˮ라며 "딥러닝 모델에 대해 신뢰도 높은 설명을 제공하기 위해서는 입력 데이터를 적절히 변형한 상황에서도 모델 예측과 관련도가 높은 입력 특성에 주목해야 한다ˮ라고 말했다.
이번 연구는 2022년도 과학기술정보통신부의 재원으로 정보통신기획평가원의 지원을 받은 사람 중심 AI강국 실현을 위한 차세대 인공지능 핵심원천기술개발 사용자 맞춤형 플로그앤플레이 방식의 설명가능성 제공, 한국과학기술원 인공지능 대학원 프로그램, 인공지능 공정성 AIDEP 및 국방과학연구소의 지원을 받은 설명 가능 인공지능 프로젝트 및 인이지의 지원으로 수행됐다.
2022.11.23 조회수 11159 -
 딥러닝 적대적 공격을 막는 방어 프레임 개발
우리 대학 전기및전자공학부 노용만 교수 연구팀이 물체를 검출하는 딥러닝 신경망에 대한 적대적 공격을 방어하는 알고리즘을 개발했다고 15일 밝혔다.
최근 몇 년간 인공지능 딥러닝 신경망 기술이 나날이 발전하고 실세계에 활용되면서, 딥러닝 신경망 기술은 자율주행 및 물체검출 등 다양한 분야에서 떠오르는 핵심기술로 주목받고 있다.
하지만 현재의 딥러닝 기반 검출 네트워크는, 특정한 적대적 패턴을 입력 이미지에 악의적으로 주입하여 잘못된 예측 결과를 초래하는 적대적 공격에 대해 심각하게 취약하다. 적대적 패턴이란 공격자가 검출이 되지 않기 위해 인위적으로 만든 패턴이다. 이 패턴이 포함된 물체는 검출이 되지 않게 하는 것으로 적대적 패턴 공격이라 한다.
이러한 취약성은 인공지능으로 대표되는 딥러닝 기반의 모델을 국방이나 의료 및 자율주행 등 국민의 생명과 재산을 직접 다루는 분야에 적용할 때 크게 문제가 된다. 구체적인 예로 국방·보안을 위한 감시 정찰 분야에서 적군이 적대적 패턴으로 위장하여 침입하면 검출을 못하는 경우가 발생하여 국방 및 보안에 매우 큰 위험을 초래할 수 있다.
기존의 많은 연구가 적대적 패턴 공격을 막기 위해 노력했으나 추가로 복잡한 모듈이 필요하거나 네트워크를 처음부터 다시 학습해야 했기 때문에, 기존 연구는 실시간으로 동작하는 물체검출 알고리즘에 현실적으로 적용하기가 쉽지 않았다.
노 교수 연구팀은 물리적인 환경에서 적대적 패턴 공격의 원리를 반대로 이용해 적대적 공격을 막아내는 방어 프레임을 고안했다. 이러한 방어 프레임은 부가적인 복잡한 모듈이나 네트워크의 재학습이 필요하지 않으므로 보다 실용적이고 강인한 물체검출 네트워크를 구축하는데 폭넓게 응용 및 적용될 수 있을 것으로 기대된다.
공동 제1 저자인 전기및전자공학부 유영준 박사과정 학생과 이홍주 박사과정 학생 등이 함께 수행한 이번 연구는 영상처리 분야 최고의 국제 학술지인 `IEEE Transactions on Image Processing'에 11월 1일 자로 온라인 게재됐다. (논문명 : Defending Person Detection Against Adversarial Patch Attack by using Universal Defensive Frame).
연구팀은 문제 해결을 위해 적대적 공격의 원리를 역으로 이용해, 학습된 네트워크에 접근하지 않으면서도 입력단에서 방어할 수 있는 방어 프레임 기술을 고안했다.
연구팀의 방어 기술은 적대적 공격과 정반대로 물체검출 시 딥러닝 모델이 옳은 예측 결과를 내리도록 방어 프레임을 만드는 것이다. 이러한 방어 프레임은 마치 창과 방패의 싸움처럼 적대적 패턴과 함께 경쟁적으로 학습되며, 해당 과정을 반복해 최종적으로 모든 적대적 패턴 공격에 대해 높은 방어성능을 지니도록 최적화된다.
연구팀은 입력 이미지 외부에 덧붙이는 방어 프레임을 변화시킴으로써 손쉽게 방어성능을 조절할 수 있음을 확인했고, 개발된 방어 프레임은 인리아(INRIA) 검출 벤치마크 데이터셋에서 기존 방어 알고리즘 대비 평균 31.6% 정확도가 향상하는 성과를 거뒀다.
연구팀이 개발한 방어 프레임은 실시간 물체 탐지 시, 모델의 재학습 없이 적대적 패턴 공격을 방어할 수 있으므로 예측 시간 및 비용 절감을 크게 이룰 수 있을 것으로 기대된다.
연구팀은 나아가 이번 연구에서 개발된 방어 프레임을 물리적으로 직접 구현시켜서, 물리적 환경에 자연스레 놓여있는 적대적 패턴 공격과 마찬가지로 좀 더 접근성 있는 방어 방법으로도 활발히 응용될 수 있음을 제시하였다.
노용만 교수는 "국방 및 보안 분야에서 인공지능이 활용되기 위해서 아직 인공지능의 완전성을 높이는 많은 연구가 필요한데, 이번에 개발된 방어 기술은 이 분야들에서 인공지능 모델을 적용 시 실용적인 적대적 방어를 제시함에 의의가 있을 것ˮ이라며 "이 기술은 국방 감시정찰, 보안, 자율주행 분야에도 적용될 수 있을 것이다ˮ라고 말했다.
한편 이번 연구는 방위사업청과 국방과학연구소의 지원으로 한국과학기술원 미래국방 인공지능 특화연구센터에서 수행됐다.
2022.11.15 조회수 7458
딥러닝 적대적 공격을 막는 방어 프레임 개발
우리 대학 전기및전자공학부 노용만 교수 연구팀이 물체를 검출하는 딥러닝 신경망에 대한 적대적 공격을 방어하는 알고리즘을 개발했다고 15일 밝혔다.
최근 몇 년간 인공지능 딥러닝 신경망 기술이 나날이 발전하고 실세계에 활용되면서, 딥러닝 신경망 기술은 자율주행 및 물체검출 등 다양한 분야에서 떠오르는 핵심기술로 주목받고 있다.
하지만 현재의 딥러닝 기반 검출 네트워크는, 특정한 적대적 패턴을 입력 이미지에 악의적으로 주입하여 잘못된 예측 결과를 초래하는 적대적 공격에 대해 심각하게 취약하다. 적대적 패턴이란 공격자가 검출이 되지 않기 위해 인위적으로 만든 패턴이다. 이 패턴이 포함된 물체는 검출이 되지 않게 하는 것으로 적대적 패턴 공격이라 한다.
이러한 취약성은 인공지능으로 대표되는 딥러닝 기반의 모델을 국방이나 의료 및 자율주행 등 국민의 생명과 재산을 직접 다루는 분야에 적용할 때 크게 문제가 된다. 구체적인 예로 국방·보안을 위한 감시 정찰 분야에서 적군이 적대적 패턴으로 위장하여 침입하면 검출을 못하는 경우가 발생하여 국방 및 보안에 매우 큰 위험을 초래할 수 있다.
기존의 많은 연구가 적대적 패턴 공격을 막기 위해 노력했으나 추가로 복잡한 모듈이 필요하거나 네트워크를 처음부터 다시 학습해야 했기 때문에, 기존 연구는 실시간으로 동작하는 물체검출 알고리즘에 현실적으로 적용하기가 쉽지 않았다.
노 교수 연구팀은 물리적인 환경에서 적대적 패턴 공격의 원리를 반대로 이용해 적대적 공격을 막아내는 방어 프레임을 고안했다. 이러한 방어 프레임은 부가적인 복잡한 모듈이나 네트워크의 재학습이 필요하지 않으므로 보다 실용적이고 강인한 물체검출 네트워크를 구축하는데 폭넓게 응용 및 적용될 수 있을 것으로 기대된다.
공동 제1 저자인 전기및전자공학부 유영준 박사과정 학생과 이홍주 박사과정 학생 등이 함께 수행한 이번 연구는 영상처리 분야 최고의 국제 학술지인 `IEEE Transactions on Image Processing'에 11월 1일 자로 온라인 게재됐다. (논문명 : Defending Person Detection Against Adversarial Patch Attack by using Universal Defensive Frame).
연구팀은 문제 해결을 위해 적대적 공격의 원리를 역으로 이용해, 학습된 네트워크에 접근하지 않으면서도 입력단에서 방어할 수 있는 방어 프레임 기술을 고안했다.
연구팀의 방어 기술은 적대적 공격과 정반대로 물체검출 시 딥러닝 모델이 옳은 예측 결과를 내리도록 방어 프레임을 만드는 것이다. 이러한 방어 프레임은 마치 창과 방패의 싸움처럼 적대적 패턴과 함께 경쟁적으로 학습되며, 해당 과정을 반복해 최종적으로 모든 적대적 패턴 공격에 대해 높은 방어성능을 지니도록 최적화된다.
연구팀은 입력 이미지 외부에 덧붙이는 방어 프레임을 변화시킴으로써 손쉽게 방어성능을 조절할 수 있음을 확인했고, 개발된 방어 프레임은 인리아(INRIA) 검출 벤치마크 데이터셋에서 기존 방어 알고리즘 대비 평균 31.6% 정확도가 향상하는 성과를 거뒀다.
연구팀이 개발한 방어 프레임은 실시간 물체 탐지 시, 모델의 재학습 없이 적대적 패턴 공격을 방어할 수 있으므로 예측 시간 및 비용 절감을 크게 이룰 수 있을 것으로 기대된다.
연구팀은 나아가 이번 연구에서 개발된 방어 프레임을 물리적으로 직접 구현시켜서, 물리적 환경에 자연스레 놓여있는 적대적 패턴 공격과 마찬가지로 좀 더 접근성 있는 방어 방법으로도 활발히 응용될 수 있음을 제시하였다.
노용만 교수는 "국방 및 보안 분야에서 인공지능이 활용되기 위해서 아직 인공지능의 완전성을 높이는 많은 연구가 필요한데, 이번에 개발된 방어 기술은 이 분야들에서 인공지능 모델을 적용 시 실용적인 적대적 방어를 제시함에 의의가 있을 것ˮ이라며 "이 기술은 국방 감시정찰, 보안, 자율주행 분야에도 적용될 수 있을 것이다ˮ라고 말했다.
한편 이번 연구는 방위사업청과 국방과학연구소의 지원으로 한국과학기술원 미래국방 인공지능 특화연구센터에서 수행됐다.
2022.11.15 조회수 7458 -
 인공지능 심층 학습(딥러닝) 서비스 구축 비용 최소화 가능한 데이터 정제 기술 개발
최근 다양한 분야에서 인공지능 심층 학습(딥러닝) 기술을 활용한 서비스가 급속히 증가하고 있다. 서비스 구축을 위해서 인공지능은 심층신경망을 훈련해야 하며, 이를 위해서는 충분한 훈련 데이터를 준비해야 한다. 특히 훈련 데이터에 정답지를 만드는 레이블링(labeling) 과정이 필요한데 (예를 들어, 고양이 사진에 `고양이'라고 정답을 적어줌), 이 과정은 일반적으로 수작업으로 진행되므로 엄청난 노동력과 시간적 비용이 소요된다. 따라서 훈련 데이터 구축 비용을 최소화하는 방법 개발이 요구되고 있다.
우리 대학 전산학부 이재길 교수 연구팀이 심층 학습 훈련 데이터 구축 비용을 최소화할 수 있는 새로운 데이터 동시 정제 및 선택 기술을 개발했다고 12일 밝혔다.
일반적으로 심층 학습용 훈련 데이터 구축 과정은 수집, 정제, 선택 및 레이블링 단계로 이뤄진다. 수집 단계에서는 웹, 카메라, 센서 등으로부터 대용량의 데이터가 정제되지 않은 채로 수집된다. 따라서 수집된 데이터에는 목표 서비스와 관련이 없어서 주어진 레이블에 해당하지 않는 분포 외(out-of-distribution) 데이터가 포함된다 (예를 들어, 동물 사진을 수집할 때 재규어 `자동차'가 포함됨). 이러한 분포 외 데이터는 데이터 정제 단계에서 정제돼야 한다. 모든 정제된 데이터에 정답지를 만들기 위해서는 막대한 비용이 소모되는데, 이를 최소화하기 위해 심층 학습 성능 향상에 가장 도움이 되는 훈련 데이터를 먼저 선택해 레이블링하는 능동 학습(active learning)이 큰 주목을 받고 있다. 그러나 정제와 레이블링을 별도로 진행하는 것은 데이터 검사 측면에서 중복적인 비용을 초래한다. 또한 아직 정제되지 않고 남아 있는 분포 외 데이터가 레이블링 단계에서 선택된다면 레이블링 노력을 낭비할 수 있다.
이재길 교수팀이 개발한 기술은 훈련 데이터 구축 단계에서 데이터의 정제 및 선택을 동시에 수행해 심층 학습용 훈련 데이터 구축 비용을 최소화할 수 있도록 해준다.
우리 대학 데이터사이언스대학원에 재학 중인 박동민 박사과정 학생이 제1 저자, 신유주 박사과정, 이영준 박사과정 학생이 제2, 제4 저자로 각각 참여한 이번 연구는 최고권위 국제학술대회 `신경정보처리시스템학회(NeurIPS) 2022'에서 올 12월 발표될 예정이다. (논문명 : Meta-Query-Net: Resolving Purity-Informativeness Dilemma in Open-set Active Learning)
데이터의 정제 및 선택을 동시에 고려하기 위해서 구체적으로 가장 분포 외 데이터가 아닐 것 같은 데이터 중에서 가장 심층 학습 성능 향상에 도움이 될 데이터를 선택한다. 즉, 주어진 훈련 데이터 구축 비용 내에서 최고의 효과를 내도록 데이터의 순도(purity) 지표와 정보도(informativeness) 지표의 최적 균형(trade-off)을 찾는다. 순도와 정보도는 일반적으로 서로 상충하므로 최적 균형을 찾는 것이 간단하지 않다. 이 교수팀은 이러한 최적 균형이 정제 전 데이터의 분포 외 데이터 비율과 현재 심층신경망 훈련 정도에 따라 달라진다는 점을 발견했다.
이 교수팀은 이러한 최적 균형을 찾아내기 위해 추가적인 작은 신경망 모델을 도입했다. 연구팀은 추가된 모델을 훈련하기 위해 능동 학습에서 여러 단계에 걸쳐 데이터를 선별하는 과정을 활용했다. 즉, 새롭게 선택돼 레이블링 된 데이터를 순도-정보도 최적 균형을 찾기 위한 훈련 데이터로 활용했고, 레이블이 추가될 때마다 최적 균형을 갱신했다. 이러한 방법은 목표 심층신경망의 성능 향상을 위해 추가적인 상위 레벨의 신경망을 사용하였다는 점에서 메타학습(meta-learning)의 일종이라 볼 수 있다.
연구팀은 이 메타학습 방법론을 `메타 질의 네트워크'라고 이름 붙이고 이미지 분류 문제에 대해 다양한 데이터와 광범위한 분포 외 데이터 비율에 걸쳐 방법론을 검증했다. 그 결과, 기존 최신 방법론과 비교했을 때 최대 20% 향상된 최종 예측 정확도를 향상했고, 모든 범위의 분포 외 데이터 비율에서 일관되게 최고 성능을 보였다. 또한, `메타 질의 네트워크'의 최적 균형 분석을 통해, 분포 외 데이터의 비율이 낮고 현재 심층신경망의 성능이 높을수록 정보도에 높은 가중치를 둬야 함을 연구팀은 밝혀냈다.
제1 저자인 박동민 박사과정 학생은 "이번 기술은 실세계 능동 학습에서의 순도-정보도 딜레마를 발견하고 해결한 획기적인 방법ˮ 이라면서 "다양한 데이터 분포 상황에서의 강건성이 검증됐기 때문에, 실생활의 기계 학습 문제에 폭넓게 적용될 수 있어 전반적인 심층 학습의 훈련 데이터 준비 비용 절감에 기여할 것ˮ 이라고 밝혔다.
연구팀을 지도한 이재길 교수도 "이 기술이 텐서플로우(TensorFlow) 혹은 파이토치(PyTorch)와 같은 기존의 심층 학습 라이브러리에 추가되면 기계 학습 및 심층 학습 학계에 큰 파급효과를 낼 수 있을 것이다ˮ고 말했다.
한편, 이 기술은 과학기술정보통신부 재원으로 정보통신기획평가원의 지원을 받아 SW컴퓨팅산업원천기술개발사업 SW스타랩 과제로 개발한 연구성과 결과물(2020-0-00862, DB4DL: 딥러닝 지원 고사용성 및 고성능 분산 인메모리 DBMS 개발)이다.
2022.10.12 조회수 9367
인공지능 심층 학습(딥러닝) 서비스 구축 비용 최소화 가능한 데이터 정제 기술 개발
최근 다양한 분야에서 인공지능 심층 학습(딥러닝) 기술을 활용한 서비스가 급속히 증가하고 있다. 서비스 구축을 위해서 인공지능은 심층신경망을 훈련해야 하며, 이를 위해서는 충분한 훈련 데이터를 준비해야 한다. 특히 훈련 데이터에 정답지를 만드는 레이블링(labeling) 과정이 필요한데 (예를 들어, 고양이 사진에 `고양이'라고 정답을 적어줌), 이 과정은 일반적으로 수작업으로 진행되므로 엄청난 노동력과 시간적 비용이 소요된다. 따라서 훈련 데이터 구축 비용을 최소화하는 방법 개발이 요구되고 있다.
우리 대학 전산학부 이재길 교수 연구팀이 심층 학습 훈련 데이터 구축 비용을 최소화할 수 있는 새로운 데이터 동시 정제 및 선택 기술을 개발했다고 12일 밝혔다.
일반적으로 심층 학습용 훈련 데이터 구축 과정은 수집, 정제, 선택 및 레이블링 단계로 이뤄진다. 수집 단계에서는 웹, 카메라, 센서 등으로부터 대용량의 데이터가 정제되지 않은 채로 수집된다. 따라서 수집된 데이터에는 목표 서비스와 관련이 없어서 주어진 레이블에 해당하지 않는 분포 외(out-of-distribution) 데이터가 포함된다 (예를 들어, 동물 사진을 수집할 때 재규어 `자동차'가 포함됨). 이러한 분포 외 데이터는 데이터 정제 단계에서 정제돼야 한다. 모든 정제된 데이터에 정답지를 만들기 위해서는 막대한 비용이 소모되는데, 이를 최소화하기 위해 심층 학습 성능 향상에 가장 도움이 되는 훈련 데이터를 먼저 선택해 레이블링하는 능동 학습(active learning)이 큰 주목을 받고 있다. 그러나 정제와 레이블링을 별도로 진행하는 것은 데이터 검사 측면에서 중복적인 비용을 초래한다. 또한 아직 정제되지 않고 남아 있는 분포 외 데이터가 레이블링 단계에서 선택된다면 레이블링 노력을 낭비할 수 있다.
이재길 교수팀이 개발한 기술은 훈련 데이터 구축 단계에서 데이터의 정제 및 선택을 동시에 수행해 심층 학습용 훈련 데이터 구축 비용을 최소화할 수 있도록 해준다.
우리 대학 데이터사이언스대학원에 재학 중인 박동민 박사과정 학생이 제1 저자, 신유주 박사과정, 이영준 박사과정 학생이 제2, 제4 저자로 각각 참여한 이번 연구는 최고권위 국제학술대회 `신경정보처리시스템학회(NeurIPS) 2022'에서 올 12월 발표될 예정이다. (논문명 : Meta-Query-Net: Resolving Purity-Informativeness Dilemma in Open-set Active Learning)
데이터의 정제 및 선택을 동시에 고려하기 위해서 구체적으로 가장 분포 외 데이터가 아닐 것 같은 데이터 중에서 가장 심층 학습 성능 향상에 도움이 될 데이터를 선택한다. 즉, 주어진 훈련 데이터 구축 비용 내에서 최고의 효과를 내도록 데이터의 순도(purity) 지표와 정보도(informativeness) 지표의 최적 균형(trade-off)을 찾는다. 순도와 정보도는 일반적으로 서로 상충하므로 최적 균형을 찾는 것이 간단하지 않다. 이 교수팀은 이러한 최적 균형이 정제 전 데이터의 분포 외 데이터 비율과 현재 심층신경망 훈련 정도에 따라 달라진다는 점을 발견했다.
이 교수팀은 이러한 최적 균형을 찾아내기 위해 추가적인 작은 신경망 모델을 도입했다. 연구팀은 추가된 모델을 훈련하기 위해 능동 학습에서 여러 단계에 걸쳐 데이터를 선별하는 과정을 활용했다. 즉, 새롭게 선택돼 레이블링 된 데이터를 순도-정보도 최적 균형을 찾기 위한 훈련 데이터로 활용했고, 레이블이 추가될 때마다 최적 균형을 갱신했다. 이러한 방법은 목표 심층신경망의 성능 향상을 위해 추가적인 상위 레벨의 신경망을 사용하였다는 점에서 메타학습(meta-learning)의 일종이라 볼 수 있다.
연구팀은 이 메타학습 방법론을 `메타 질의 네트워크'라고 이름 붙이고 이미지 분류 문제에 대해 다양한 데이터와 광범위한 분포 외 데이터 비율에 걸쳐 방법론을 검증했다. 그 결과, 기존 최신 방법론과 비교했을 때 최대 20% 향상된 최종 예측 정확도를 향상했고, 모든 범위의 분포 외 데이터 비율에서 일관되게 최고 성능을 보였다. 또한, `메타 질의 네트워크'의 최적 균형 분석을 통해, 분포 외 데이터의 비율이 낮고 현재 심층신경망의 성능이 높을수록 정보도에 높은 가중치를 둬야 함을 연구팀은 밝혀냈다.
제1 저자인 박동민 박사과정 학생은 "이번 기술은 실세계 능동 학습에서의 순도-정보도 딜레마를 발견하고 해결한 획기적인 방법ˮ 이라면서 "다양한 데이터 분포 상황에서의 강건성이 검증됐기 때문에, 실생활의 기계 학습 문제에 폭넓게 적용될 수 있어 전반적인 심층 학습의 훈련 데이터 준비 비용 절감에 기여할 것ˮ 이라고 밝혔다.
연구팀을 지도한 이재길 교수도 "이 기술이 텐서플로우(TensorFlow) 혹은 파이토치(PyTorch)와 같은 기존의 심층 학습 라이브러리에 추가되면 기계 학습 및 심층 학습 학계에 큰 파급효과를 낼 수 있을 것이다ˮ고 말했다.
한편, 이 기술은 과학기술정보통신부 재원으로 정보통신기획평가원의 지원을 받아 SW컴퓨팅산업원천기술개발사업 SW스타랩 과제로 개발한 연구성과 결과물(2020-0-00862, DB4DL: 딥러닝 지원 고사용성 및 고성능 분산 인메모리 DBMS 개발)이다.
2022.10.12 조회수 9367 -
 초대규모 인공지능 모델 처리하기 위한 세계 최고 성능의 기계학습 시스템 기술 개발
우리 연구진이 오늘날 인공지능 딥러닝 모델들을 처리하기 위해 필수적으로 사용되는 기계학습 시스템을 세계 최고 수준의 성능으로 끌어올렸다.
우리 대학 전산학부 김민수 교수 연구팀이 딥러닝 모델을 비롯한 기계학습 모델을 학습하거나 추론하기 위해 필수적으로 사용되는 기계학습 시스템의 성능을 대폭 높일 수 있는 세계 최고 수준의 행렬 연산자 융합 기술(일명 FuseME)을 개발했다고 20일 밝혔다.
오늘날 광범위한 산업 분야들에서 사용되고 있는 딥러닝 모델들은 대부분 구글 텐서플로우(TensorFlow)나 IBM 시스템DS와 같은 기계학습 시스템을 이용해 처리되는데, 딥러닝 모델의 규모가 점점 더 커지고, 그 모델에 사용되는 데이터의 규모가 점점 더 커짐에 따라, 이들을 원활히 처리할 수 있는 고성능 기계학습 시스템에 대한 중요성도 점점 더 커지고 있다.
일반적으로 딥러닝 모델은 행렬 곱셈, 행렬 합, 행렬 집계 등의 많은 행렬 연산자들로 구성된 방향성 비순환 그래프(Directed Acyclic Graph; 이하 DAG) 형태의 질의 계획으로 표현돼 기계학습 시스템에 의해 처리된다. 모델과 데이터의 규모가 클 때는 일반적으로 DAG 질의 계획은 수많은 컴퓨터로 구성된 클러스터에서 처리된다. 클러스터의 사양에 비해 모델과 데이터의 규모가 커지면 처리에 실패하거나 시간이 오래 걸리는 근본적인 문제가 있었다.
지금까지는 더 큰 규모의 모델이나 데이터를 처리하기 위해 단순히 컴퓨터 클러스터의 규모를 증가시키는 방식을 주로 사용했다. 그러나, 김 교수팀은 DAG 질의 계획을 구성하는 각 행렬 연산자로부터 생성되는 일종의 `중간 데이터'를 메모리에 저장하거나 네트워크 통신을 통해 다른 컴퓨터로 전송하는 것이 문제의 원인임에 착안해, 중간 데이터를 저장하지 않거나 다른 컴퓨터로 전송하지 않도록 여러 행렬 연산자들을 하나의 연산자로 융합(fusion)하는 세계 최고 성능의 융합 기술인 FuseME(Fused Matrix Engine)을 개발해 문제를 해결했다.
현재까지의 기계학습 시스템들은 낮은 수준의 연산자 융합 기술만을 사용하고 있었다. 가장 복잡한 행렬 연산자인 행렬 곱을 제외한 나머지 연산자들만 융합해 성능이 별로 개선되지 않거나, 전체 DAG 질의 계획을 단순히 하나의 연산자처럼 실행해 메모리 부족으로 처리에 실패하는 한계를 지니고 있었다.
김 교수팀이 개발한 FuseME 기술은 수십 개 이상의 행렬 연산자들로 구성되는 DAG 질의 계획에서 어떤 연산자들끼리 서로 융합하는 것이 더 우수한 성능을 내는지 비용 기반으로 판별해 그룹으로 묶고, 클러스터의 사양, 네트워크 통신 속도, 입력 데이터 크기 등을 모두 고려해 각 융합 연산자 그룹을 메모리 부족으로 처리에 실패하지 않으면서 이론적으로 최적 성능을 낼 수 있는 CFO(Cuboid-based Fused Operator)라 불리는 연산자로 융합함으로써 한계를 극복했다. 이때, 행렬 곱 연산자까지 포함해 연산자들을 융합하는 것이 핵심이다.
김민수 교수 연구팀은 FuseME 기술을 종래 최고 기술로 알려진 구글의 텐서플로우나 IBM의 시스템DS와 비교 평가한 결과, 딥러닝 모델의 처리 속도를 최대 8.8배 향상하고, 텐서플로우나 시스템DS가 처리할 수 없는 훨씬 더 큰 규모의 모델 및 데이터를 처리하는 데 성공함을 보였다. 또한, FuseME의 CFO 융합 연산자는 종래의 최고 수준 융합 연산자와 비교해 처리 속도를 최대 238배 향상시키고, 네트워크 통신 비용을 최대 64배 감소시키는 사실을 확인했다.
김 교수팀은 이미 지난 2019년에 초대규모 행렬 곱 연산에 대해 종래 세계 최고 기술이었던 IBM 시스템ML과 슈퍼컴퓨팅 분야의 스칼라팩(ScaLAPACK) 대비 성능과 처리 규모를 훨씬 향상시킨 DistME라는 기술을 개발해 데이터베이스 분야 최고 국제학술대회 중 하나인 ACM SIGMOD에서 발표한 바 있다. 이번 FuseME 기술은 연산자 융합이 가능하도록 DistME를 한층 더 발전시킨 것으로, 해당 분야를 세계 최고 수준의 기술력을 바탕으로 지속적으로 선도하는 쾌거를 보여준 것이다.
교신저자로 참여한 김민수 교수는 "연구팀이 개발한 새로운 기술은 딥러닝 등 기계학습 모델의 처리 규모와 성능을 획기적으로 높일 수 있어 산업적 측면에서 파급 효과가 매우 클 것으로 기대한다ˮ 라고 말했다.
이번 연구에는 김 교수의 제자이자 현재 GraphAI(그래파이) 스타트업의 공동 창업자인 한동형 박사가 제1 저자로, 김 교수가 교신저자로 참여했으며 지난 16일 미국 필라델피아에서 열린 데이터베이스 분야 최고 국제학술대회 중 하나인 ACM SIGMOD에서 발표됐다. (논문명 : FuseME: Distributed Matrix Computation Engine based on Cuboid-based Fused Operator and Plan Generation).
한편, 이번 연구는 한국연구재단 선도연구센터 사업 및 중견연구자 지원사업, 과기정통부 IITP SW스타랩 사업의 지원을 받아 수행됐다.
2022.06.20 조회수 8733
초대규모 인공지능 모델 처리하기 위한 세계 최고 성능의 기계학습 시스템 기술 개발
우리 연구진이 오늘날 인공지능 딥러닝 모델들을 처리하기 위해 필수적으로 사용되는 기계학습 시스템을 세계 최고 수준의 성능으로 끌어올렸다.
우리 대학 전산학부 김민수 교수 연구팀이 딥러닝 모델을 비롯한 기계학습 모델을 학습하거나 추론하기 위해 필수적으로 사용되는 기계학습 시스템의 성능을 대폭 높일 수 있는 세계 최고 수준의 행렬 연산자 융합 기술(일명 FuseME)을 개발했다고 20일 밝혔다.
오늘날 광범위한 산업 분야들에서 사용되고 있는 딥러닝 모델들은 대부분 구글 텐서플로우(TensorFlow)나 IBM 시스템DS와 같은 기계학습 시스템을 이용해 처리되는데, 딥러닝 모델의 규모가 점점 더 커지고, 그 모델에 사용되는 데이터의 규모가 점점 더 커짐에 따라, 이들을 원활히 처리할 수 있는 고성능 기계학습 시스템에 대한 중요성도 점점 더 커지고 있다.
일반적으로 딥러닝 모델은 행렬 곱셈, 행렬 합, 행렬 집계 등의 많은 행렬 연산자들로 구성된 방향성 비순환 그래프(Directed Acyclic Graph; 이하 DAG) 형태의 질의 계획으로 표현돼 기계학습 시스템에 의해 처리된다. 모델과 데이터의 규모가 클 때는 일반적으로 DAG 질의 계획은 수많은 컴퓨터로 구성된 클러스터에서 처리된다. 클러스터의 사양에 비해 모델과 데이터의 규모가 커지면 처리에 실패하거나 시간이 오래 걸리는 근본적인 문제가 있었다.
지금까지는 더 큰 규모의 모델이나 데이터를 처리하기 위해 단순히 컴퓨터 클러스터의 규모를 증가시키는 방식을 주로 사용했다. 그러나, 김 교수팀은 DAG 질의 계획을 구성하는 각 행렬 연산자로부터 생성되는 일종의 `중간 데이터'를 메모리에 저장하거나 네트워크 통신을 통해 다른 컴퓨터로 전송하는 것이 문제의 원인임에 착안해, 중간 데이터를 저장하지 않거나 다른 컴퓨터로 전송하지 않도록 여러 행렬 연산자들을 하나의 연산자로 융합(fusion)하는 세계 최고 성능의 융합 기술인 FuseME(Fused Matrix Engine)을 개발해 문제를 해결했다.
현재까지의 기계학습 시스템들은 낮은 수준의 연산자 융합 기술만을 사용하고 있었다. 가장 복잡한 행렬 연산자인 행렬 곱을 제외한 나머지 연산자들만 융합해 성능이 별로 개선되지 않거나, 전체 DAG 질의 계획을 단순히 하나의 연산자처럼 실행해 메모리 부족으로 처리에 실패하는 한계를 지니고 있었다.
김 교수팀이 개발한 FuseME 기술은 수십 개 이상의 행렬 연산자들로 구성되는 DAG 질의 계획에서 어떤 연산자들끼리 서로 융합하는 것이 더 우수한 성능을 내는지 비용 기반으로 판별해 그룹으로 묶고, 클러스터의 사양, 네트워크 통신 속도, 입력 데이터 크기 등을 모두 고려해 각 융합 연산자 그룹을 메모리 부족으로 처리에 실패하지 않으면서 이론적으로 최적 성능을 낼 수 있는 CFO(Cuboid-based Fused Operator)라 불리는 연산자로 융합함으로써 한계를 극복했다. 이때, 행렬 곱 연산자까지 포함해 연산자들을 융합하는 것이 핵심이다.
김민수 교수 연구팀은 FuseME 기술을 종래 최고 기술로 알려진 구글의 텐서플로우나 IBM의 시스템DS와 비교 평가한 결과, 딥러닝 모델의 처리 속도를 최대 8.8배 향상하고, 텐서플로우나 시스템DS가 처리할 수 없는 훨씬 더 큰 규모의 모델 및 데이터를 처리하는 데 성공함을 보였다. 또한, FuseME의 CFO 융합 연산자는 종래의 최고 수준 융합 연산자와 비교해 처리 속도를 최대 238배 향상시키고, 네트워크 통신 비용을 최대 64배 감소시키는 사실을 확인했다.
김 교수팀은 이미 지난 2019년에 초대규모 행렬 곱 연산에 대해 종래 세계 최고 기술이었던 IBM 시스템ML과 슈퍼컴퓨팅 분야의 스칼라팩(ScaLAPACK) 대비 성능과 처리 규모를 훨씬 향상시킨 DistME라는 기술을 개발해 데이터베이스 분야 최고 국제학술대회 중 하나인 ACM SIGMOD에서 발표한 바 있다. 이번 FuseME 기술은 연산자 융합이 가능하도록 DistME를 한층 더 발전시킨 것으로, 해당 분야를 세계 최고 수준의 기술력을 바탕으로 지속적으로 선도하는 쾌거를 보여준 것이다.
교신저자로 참여한 김민수 교수는 "연구팀이 개발한 새로운 기술은 딥러닝 등 기계학습 모델의 처리 규모와 성능을 획기적으로 높일 수 있어 산업적 측면에서 파급 효과가 매우 클 것으로 기대한다ˮ 라고 말했다.
이번 연구에는 김 교수의 제자이자 현재 GraphAI(그래파이) 스타트업의 공동 창업자인 한동형 박사가 제1 저자로, 김 교수가 교신저자로 참여했으며 지난 16일 미국 필라델피아에서 열린 데이터베이스 분야 최고 국제학술대회 중 하나인 ACM SIGMOD에서 발표됐다. (논문명 : FuseME: Distributed Matrix Computation Engine based on Cuboid-based Fused Operator and Plan Generation).
한편, 이번 연구는 한국연구재단 선도연구센터 사업 및 중견연구자 지원사업, 과기정통부 IITP SW스타랩 사업의 지원을 받아 수행됐다.
2022.06.20 조회수 8733 -
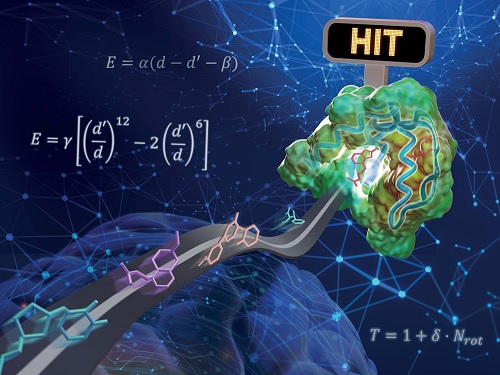 실제 약물로 개발되는 단백질-리간드 상호작용 예측 인공지능 모델 개발
우리 대학 연구진이 물리화학적 아이디어를 인공지능 딥러닝에 접목해 기존의 방법보다 일반화 성능이 높은 단백질-리간드 상호작용 예측 모델을 개발했다. 리간드란 수용체와 같은 큰 생체 분자에 특이적으로 결합하는 물질을 말하며, 생체 내의 중요한 요소이자 의약품의 개발 등에 큰 역할을 한다.
화학과 김우연 교수 연구팀이 교원창업 인공지능 신약 개발 스타트업 HITS 연구진과 함께 물리 기반 삼차원 그래프 심층 신경망을 이용해 일반화 성능을 높인 단백질-리간드 상호작용 예측 모델을 개발했다고 17일 밝혔다.
약물 후보 분자를 발굴하기 위해서 타깃 단백질과 강하게 결합하는 리간드를 찾는 것이 중요하다. 하지만 유효 물질을 찾기 위해 수백만에서 수천만 개의 무작위 리간드 라이브러리를 대상으로 실험 전수 조사를 수행하는 것은 천문학적인 시간과 비용이 필요하다. 이러한 시간과 비용을 절감하기 위해 최근 단백질-리간드 상호작용 예측에 기반한 가상탐색(virtual screening) 기술이 주목받고 있다.
기존의 상호작용 예측 인공지능 모델들은 학습에 사용한 구조에 대해서는 높은 예측 성능을 보여주지만, 새로운 단백질 구조에 대해서는 낮은 성능을 보이는 과적합(over-fitting)이 문제가 됐다. 과적합 문제는 일반적으로 모델의 복잡도에 비해 데이터가 적을 때 발생한다. 이번 연구는 이러한 과적합 문제를 해결함으로써 다양한 단백질에 대해 고른 성능을 보여주는 예측 모델을 개발하는데 주안점을 뒀다.
연구진은 물리화학적 아이디어들을 딥러닝 모델에 적용해 모델의 복잡도를 줄임과 동시에 물리 시뮬레이션을 통해 부족한 데이터를 보강함으로써 과적합 문제를 해결하고자 하였다. 단백질 원자와 리간드 원자 사이의 거리에 따른 반데르발스 힘, 수소 결합력 등을 물리화학적 방정식으로 모델링하고, 매개변수를 딥러닝으로 예측함으로써 물리 법칙을 만족하는 예측을 가능하게 했다.
또한, 학습에 사용한 단백질-리간드 결정 구조가 실험적으로 판명된 가장 안정한 구조임에 착안했다. 부족한 실험 데이터를 보강하기 위해 불안정한 단백질-리간드 구조로 이루어진 수십만 개의 인공 데이터를 생성해 학습에 활용했고, 그 결과 생성된 구조에 비해 실제 구조를 안정하게 예측하도록 모델을 학습할 수 있었다.
연구진은 개발된 모델의 성능을 검증하기 위해 대조군으로 `CASF-2016 벤치마크'를 활용했다. 이 벤치마크는 다양한 단백질-리간드 구조들 사이에서 실험적으로 판명된 결정 구조에 근접한 구조를 찾는 도킹과 상대적으로 결합력이 큰 단백질-리간드 쌍을 찾는 스크리닝 등 실제 약물을 개발하는 과정에 필수적인 과제를 포함하고 있다. 검증 테스트 결과 기존에 보고된 기술에 비해 높은 도킹 및 스크리닝 성공률을 보여줬으며, 특히 스크리닝 성능은 기존에 보고된 최고 성능 대비 약 두 배 높은 수치를 보였다.
연구진이 개발한 물리 기반 딥러닝 방법론의 또 다른 장점은 예측의 결과를 물리적으로 해석 가능하다는 것이다. 이는 딥러닝으로 최적화된 물리화학 식을 통해 최종 상호작용 값을 예측하기 때문이다. 리간드 분자 내 원자별 상호작용 에너지의 기여도를 분석함으로써 어떤 작용기가 단백질-리간드 결합에 있어서 중요한 역할을 했는지 파악할 수 있으며, 이와 같은 정보는 추후 약물 설계를 통해 성능을 높이는 데 직접 활용할 수 있다.
공동 제1 저자로 참여한 화학과 문석현, 정원호, 양수정(현재 MIT 박사과정) 박사과정 학생들은 "데이터가 적은 화학 및 바이오 분야에서 일반화 문제는 항상 중요한 문제로 강조돼왔다ˮ며 "이번 연구에서 사용한 물리 기반 딥러닝 방법론은 단백질-리간드 간 상호작용 예측 뿐 아니라 다양한 물리 문제에 적용될 수 있을 것ˮ이라고 말했다.
한국연구재단의 지원을 받아 수행된 이번 연구는 국제 학술지 `Chemical Science(IF=9.825)' 2022년 4월 13호에 표지 논문 및 `금주의 논문(Pick of the Week)'으로 선정됐다. (논문명 : PIGNet: a physics-informed deep learning model toward generalized drug–target interaction predictions, 논문 링크 : https://doi.org/10.1039/D1SC06946B)
2022.05.17 조회수 15599
실제 약물로 개발되는 단백질-리간드 상호작용 예측 인공지능 모델 개발
우리 대학 연구진이 물리화학적 아이디어를 인공지능 딥러닝에 접목해 기존의 방법보다 일반화 성능이 높은 단백질-리간드 상호작용 예측 모델을 개발했다. 리간드란 수용체와 같은 큰 생체 분자에 특이적으로 결합하는 물질을 말하며, 생체 내의 중요한 요소이자 의약품의 개발 등에 큰 역할을 한다.
화학과 김우연 교수 연구팀이 교원창업 인공지능 신약 개발 스타트업 HITS 연구진과 함께 물리 기반 삼차원 그래프 심층 신경망을 이용해 일반화 성능을 높인 단백질-리간드 상호작용 예측 모델을 개발했다고 17일 밝혔다.
약물 후보 분자를 발굴하기 위해서 타깃 단백질과 강하게 결합하는 리간드를 찾는 것이 중요하다. 하지만 유효 물질을 찾기 위해 수백만에서 수천만 개의 무작위 리간드 라이브러리를 대상으로 실험 전수 조사를 수행하는 것은 천문학적인 시간과 비용이 필요하다. 이러한 시간과 비용을 절감하기 위해 최근 단백질-리간드 상호작용 예측에 기반한 가상탐색(virtual screening) 기술이 주목받고 있다.
기존의 상호작용 예측 인공지능 모델들은 학습에 사용한 구조에 대해서는 높은 예측 성능을 보여주지만, 새로운 단백질 구조에 대해서는 낮은 성능을 보이는 과적합(over-fitting)이 문제가 됐다. 과적합 문제는 일반적으로 모델의 복잡도에 비해 데이터가 적을 때 발생한다. 이번 연구는 이러한 과적합 문제를 해결함으로써 다양한 단백질에 대해 고른 성능을 보여주는 예측 모델을 개발하는데 주안점을 뒀다.
연구진은 물리화학적 아이디어들을 딥러닝 모델에 적용해 모델의 복잡도를 줄임과 동시에 물리 시뮬레이션을 통해 부족한 데이터를 보강함으로써 과적합 문제를 해결하고자 하였다. 단백질 원자와 리간드 원자 사이의 거리에 따른 반데르발스 힘, 수소 결합력 등을 물리화학적 방정식으로 모델링하고, 매개변수를 딥러닝으로 예측함으로써 물리 법칙을 만족하는 예측을 가능하게 했다.
또한, 학습에 사용한 단백질-리간드 결정 구조가 실험적으로 판명된 가장 안정한 구조임에 착안했다. 부족한 실험 데이터를 보강하기 위해 불안정한 단백질-리간드 구조로 이루어진 수십만 개의 인공 데이터를 생성해 학습에 활용했고, 그 결과 생성된 구조에 비해 실제 구조를 안정하게 예측하도록 모델을 학습할 수 있었다.
연구진은 개발된 모델의 성능을 검증하기 위해 대조군으로 `CASF-2016 벤치마크'를 활용했다. 이 벤치마크는 다양한 단백질-리간드 구조들 사이에서 실험적으로 판명된 결정 구조에 근접한 구조를 찾는 도킹과 상대적으로 결합력이 큰 단백질-리간드 쌍을 찾는 스크리닝 등 실제 약물을 개발하는 과정에 필수적인 과제를 포함하고 있다. 검증 테스트 결과 기존에 보고된 기술에 비해 높은 도킹 및 스크리닝 성공률을 보여줬으며, 특히 스크리닝 성능은 기존에 보고된 최고 성능 대비 약 두 배 높은 수치를 보였다.
연구진이 개발한 물리 기반 딥러닝 방법론의 또 다른 장점은 예측의 결과를 물리적으로 해석 가능하다는 것이다. 이는 딥러닝으로 최적화된 물리화학 식을 통해 최종 상호작용 값을 예측하기 때문이다. 리간드 분자 내 원자별 상호작용 에너지의 기여도를 분석함으로써 어떤 작용기가 단백질-리간드 결합에 있어서 중요한 역할을 했는지 파악할 수 있으며, 이와 같은 정보는 추후 약물 설계를 통해 성능을 높이는 데 직접 활용할 수 있다.
공동 제1 저자로 참여한 화학과 문석현, 정원호, 양수정(현재 MIT 박사과정) 박사과정 학생들은 "데이터가 적은 화학 및 바이오 분야에서 일반화 문제는 항상 중요한 문제로 강조돼왔다ˮ며 "이번 연구에서 사용한 물리 기반 딥러닝 방법론은 단백질-리간드 간 상호작용 예측 뿐 아니라 다양한 물리 문제에 적용될 수 있을 것ˮ이라고 말했다.
한국연구재단의 지원을 받아 수행된 이번 연구는 국제 학술지 `Chemical Science(IF=9.825)' 2022년 4월 13호에 표지 논문 및 `금주의 논문(Pick of the Week)'으로 선정됐다. (논문명 : PIGNet: a physics-informed deep learning model toward generalized drug–target interaction predictions, 논문 링크 : https://doi.org/10.1039/D1SC06946B)
2022.05.17 조회수 15599 -
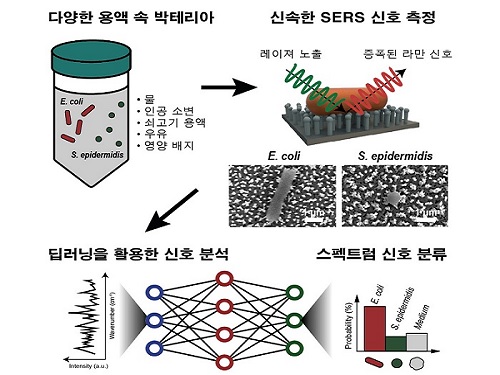 딥러닝을 응용한 신속한 박테리아 검출 방법 개발
우리 대학 전산학부 조성호 교수, 신소재공학과 정연식 교수 공동 연구팀이 딥러닝(deep learning) 기법과 표면 증강 라만 분광법(surface-enhanced Raman spectroscopy, SERS)의 결합을 통해 효율적인 박테리아 검출 플랫폼 확립에 성공했다고 10일 밝혔다.
공동 연구팀은 질량분석법, 면역분석법(ELISA), 중합효소 연쇄 반응(PCR) 등과 같은 일반적인 박테리아 검출 방법보다 획기적으로 빠르게 신호 습득이 가능한 SERS 스펙트럼을 연구팀 고유의 딥러닝 기술로 분석해 다양한 용액 속 박테리아 신호 구분에 성공했다.
전산학부 노어진 석박사통합과정 학생과 신소재공학과 김민준 박사과정 학생이 공동 제1 저자로 참여한 이번 연구는 국제학술지‘바이오센서 및 바이오일렉트로닉스 (Biosensors and Bioelectronics)’1월 18일 字 온라인 판에 게재됐다. (논문명: Separation-free bacterial identification in arbitrary media via deep neural network-based SERS analysis)
박테리아 감염으로 인한 질병 예방과 원인 분석을 위해 소변 또는 음식물에서 신속한 박테리아 검출법이 요구되며, 다양한 바이오마커 분석물의 스펙트럼 신호를 높은 민감도로 수초~수십초 이내에 측정하는 SERS가 검출 방법으로 주목받고 있다.
박테리아 대상의 기존 SERS 신호 분석은 그 복잡성과 수많은 신호 겹침 현상 때문에 주성분 분석(principal component analysis, PCA)과 같은 통계적인 방법으로도 정확도에 한계가 있었다. 특히, 박테리아의 고유 신호와 간섭현상을 일으키는 환경 매질의 신호를 제거하기 위해 번거로운 박테리아 분리 과정을 거쳐 시간 소모가 큰 것이 문제로 지적돼 왔다. 따라서 SERS를 이용한 박테리아 검출의 활용도를 높이기 위해서는 분리 단계를 최소화하고 신속하게 높은 정확도로 분석하는 기술 개발이 요구된다.
연구팀은 분리 단계를 완전히 생략해 박테리아가 담긴 서식 용액을 SERS 측정 기판에 올려 신호를 측정하고 딥러닝을 이용해 분석하는 방법을 시도했으며, 이를 위해 서로 다른 커널 크기(kernel size)를 가지는 이중 분기 네트워크로 구성된 `듀얼 WK넷' (DualWKNet, Dual-Branch Wide Kernel Network)라는 효율적인 딥러닝 모델을 개발했다.
특정 매질 속 박테리아의 신호는 매질의 신호와 유사해 사람의 눈으로는 구별하기가 사실상 불가능하지만, 연구팀은 DualWKNet을 이용해 스펙트럼 신호의 특징을 추출하고 물, 소변, 소고기 용액, 우유, 배양 배지 등 다양한 환경 내 대장균(Escherichia coli)과 표피 포도상구균(Staphylococcus epidermidis)의 신호를 학습해 최대 98%의 정확도로 검출 및 구분했다.
조성호 교수는 "이번 연구는 딥러닝 기술을 활용해 실제 환경에서 사용 가능한 라만 신호 분석 방법을 제시했다는 점에서 의미가 있다ˮ며 "의료 분야와 식품 안전 분야로 확장하여 사용돼 발전에 이바지할 것ˮ이라고 예상했다.
한편 이번 연구는 한국연구재단의 나노 및 소재기술개발사업의 지원을 받아 수행됐으며, 향후 추가 연구와 기술이전을 통해 KAIST 교원/학생 공동 창업 기업인 ㈜피코파운드리에서 상용화를 추진할 계획이다.
2022.02.10 조회수 11686
딥러닝을 응용한 신속한 박테리아 검출 방법 개발
우리 대학 전산학부 조성호 교수, 신소재공학과 정연식 교수 공동 연구팀이 딥러닝(deep learning) 기법과 표면 증강 라만 분광법(surface-enhanced Raman spectroscopy, SERS)의 결합을 통해 효율적인 박테리아 검출 플랫폼 확립에 성공했다고 10일 밝혔다.
공동 연구팀은 질량분석법, 면역분석법(ELISA), 중합효소 연쇄 반응(PCR) 등과 같은 일반적인 박테리아 검출 방법보다 획기적으로 빠르게 신호 습득이 가능한 SERS 스펙트럼을 연구팀 고유의 딥러닝 기술로 분석해 다양한 용액 속 박테리아 신호 구분에 성공했다.
전산학부 노어진 석박사통합과정 학생과 신소재공학과 김민준 박사과정 학생이 공동 제1 저자로 참여한 이번 연구는 국제학술지‘바이오센서 및 바이오일렉트로닉스 (Biosensors and Bioelectronics)’1월 18일 字 온라인 판에 게재됐다. (논문명: Separation-free bacterial identification in arbitrary media via deep neural network-based SERS analysis)
박테리아 감염으로 인한 질병 예방과 원인 분석을 위해 소변 또는 음식물에서 신속한 박테리아 검출법이 요구되며, 다양한 바이오마커 분석물의 스펙트럼 신호를 높은 민감도로 수초~수십초 이내에 측정하는 SERS가 검출 방법으로 주목받고 있다.
박테리아 대상의 기존 SERS 신호 분석은 그 복잡성과 수많은 신호 겹침 현상 때문에 주성분 분석(principal component analysis, PCA)과 같은 통계적인 방법으로도 정확도에 한계가 있었다. 특히, 박테리아의 고유 신호와 간섭현상을 일으키는 환경 매질의 신호를 제거하기 위해 번거로운 박테리아 분리 과정을 거쳐 시간 소모가 큰 것이 문제로 지적돼 왔다. 따라서 SERS를 이용한 박테리아 검출의 활용도를 높이기 위해서는 분리 단계를 최소화하고 신속하게 높은 정확도로 분석하는 기술 개발이 요구된다.
연구팀은 분리 단계를 완전히 생략해 박테리아가 담긴 서식 용액을 SERS 측정 기판에 올려 신호를 측정하고 딥러닝을 이용해 분석하는 방법을 시도했으며, 이를 위해 서로 다른 커널 크기(kernel size)를 가지는 이중 분기 네트워크로 구성된 `듀얼 WK넷' (DualWKNet, Dual-Branch Wide Kernel Network)라는 효율적인 딥러닝 모델을 개발했다.
특정 매질 속 박테리아의 신호는 매질의 신호와 유사해 사람의 눈으로는 구별하기가 사실상 불가능하지만, 연구팀은 DualWKNet을 이용해 스펙트럼 신호의 특징을 추출하고 물, 소변, 소고기 용액, 우유, 배양 배지 등 다양한 환경 내 대장균(Escherichia coli)과 표피 포도상구균(Staphylococcus epidermidis)의 신호를 학습해 최대 98%의 정확도로 검출 및 구분했다.
조성호 교수는 "이번 연구는 딥러닝 기술을 활용해 실제 환경에서 사용 가능한 라만 신호 분석 방법을 제시했다는 점에서 의미가 있다ˮ며 "의료 분야와 식품 안전 분야로 확장하여 사용돼 발전에 이바지할 것ˮ이라고 예상했다.
한편 이번 연구는 한국연구재단의 나노 및 소재기술개발사업의 지원을 받아 수행됐으며, 향후 추가 연구와 기술이전을 통해 KAIST 교원/학생 공동 창업 기업인 ㈜피코파운드리에서 상용화를 추진할 계획이다.
2022.02.10 조회수 11686