-
 ‘뻔하지 않은 창의적인 의자’그리는 AI 기술 개발
최근 텍스트 기반 이미지 생성 모델은 자연어로 제공된 설명만으로도 고해상도·고품질 이미지를 자동 생성할 수 있다. 하지만, 대표적인 예인 스테이블 디퓨전(Stable Diffusion) 모델에서 ‘창의적인’이라는 텍스트를 입력했을 경우, 창의적인 이미지 생성은 아직은 제한적인 수준이다. KAIST 연구진이 스테이블 디퓨전(Stable Diffusion) 등 텍스트 기반 이미지 생성 모델에 별도 학습 없이 창의성을 강화할 수 있는 기술을 개발해, 예컨대 뻔하지 않은 창의적인 의자 디자인도 인공지능이 스스로 그려낼 수 있게 됐다.
우리 대학 김재철AI대학원 최재식 교수 연구팀이 네이버(NAVER) AI Lab과 공동 연구를 통해, 추가적 학습 없이 인공지능(AI) 생성 모델의 창의적 생성을 강화하는 기술을 개발했다.
최 교수 연구팀은 텍스트 기반 이미지 생성 모델의 내부 특징 맵을 증폭해 창의적 생성을 강화하는 기술을 개발했다. 또한, 모델 내부의 얕은 블록들이 창의적 생성에 중요한 역할을 한다는 것을 발견하고, 특징 맵을 주파수 영역으로 변환 후, 높은 주파수 영역에 해당하는 부분의 값을 증폭하면 노이즈나 작게 조각난 색깔 패턴의 형태를 유발하는 것을 확인했다. 이에 따라, 연구팀은 얕은 블록의 낮은 주파수 영역을 증폭함으로써 효과적으로 창의적 생성을 강화할 수 있음을 보였다.
연구팀은 창의성을 정의하는 두 가지 핵심 요소인 독창성과 유용성을 모두 고려해, 생성 모델 내부의 각 블록 별로 최적의 증폭 값을 자동으로 선택하는 알고리즘을 제시했다.
개발된 알고리즘을 통해 사전 학습된 스테이블 디퓨전 모델의 내부 특징 맵을 적절히 증폭해 추가적인 분류 데이터나 학습 없이 창의적 생성을 강화할 수 있었다.
연구팀은 개발된 알고리즘을 사용하면 기존 모델 대비 더욱 참신하면서도 유용성이 크게 저하되지 않은 이미지를 생성할 수 있음을 다양한 측정치를 활용해 정량적으로 입증했다.
특히, 스테이블 디퓨전 XL(SDXL) 모델의 이미지 생성 속도를 대폭 향상하기 위해 개발된 SDXL-Turbo 모델에서 발생하는 모드 붕괴 문제를 완화함으로써 이미지 다양성이 증가한 것을 확인했다. 나아가, 사용자 연구를 통해 사람이 직접 평가했을 때도 기존 방법에 비해 유용성 대비 참신성이 크게 향상됨을 입증했다.
공동 제1 저자인 KAIST 한지연, 권다희 박사과정은 "생성 모델을 새로 학습하거나 미세조정 학습하지 않고 생성 모델의 창의적인 생성을 강화하는 최초의 방법론ˮ이라며 "학습된 인공지능 생성 모델 내부에 잠재된 창의성을 특징 맵 조작을 통해 강화할 수 있음을 보였다ˮ 라고 말했다.
이어 “이번 연구는 기존 학습된 모델에서도 텍스트만으로 창의적 이미지를 손쉽게 생성할 수 있게 됐으며, 이를 통해 창의적인 상품 디자인 등 다양한 분야에서 새로운 영감을 제공하고, 인공지능 모델이 창의적 생태계에서 실질적으로 유용하게 활용될 수 있도록 기여할 것으로 기대된다”라고 밝혔다.
KAIST 김재철AI대학원 한지연 박사과정과 권다희 박사과정이 공동 제1 저자로 참여한 이번 연구는 국제 학술지 `국제 컴퓨터 비전 및 패턴인식 학술대회 (IEEE Conference on Computer Vision and Pattern Recognition, CVPR)’에서 6월 15일 발표됐다.
※논문명 : Enhancing Creative Generation on Stable Diffusion-based Models
※DOI: https://doi.org/10.48550/arXiv.2503.23538
한편 이번 연구는 KAIST-네이버 초창의적 AI 연구센터, 과학기술정보통신부의 재원으로 정보통신기획평가원의 지원을 받은 혁신성장동력프로젝트 설명가능인공지능, AI 연구거점 프로젝트, 점차 강화되고 있는 윤리 정책에 발맞춰 유연하게 진화하는 인공지능 기술 개발 연구 및 KAIST 인공지능 대학원 프로그램과제의 지원을 받았고 방위사업청과 국방과학연구소의 지원으로 KAIST 미래 국방 인공지능 특화연구센터에서 수행됐다.
‘뻔하지 않은 창의적인 의자’그리는 AI 기술 개발
최근 텍스트 기반 이미지 생성 모델은 자연어로 제공된 설명만으로도 고해상도·고품질 이미지를 자동 생성할 수 있다. 하지만, 대표적인 예인 스테이블 디퓨전(Stable Diffusion) 모델에서 ‘창의적인’이라는 텍스트를 입력했을 경우, 창의적인 이미지 생성은 아직은 제한적인 수준이다. KAIST 연구진이 스테이블 디퓨전(Stable Diffusion) 등 텍스트 기반 이미지 생성 모델에 별도 학습 없이 창의성을 강화할 수 있는 기술을 개발해, 예컨대 뻔하지 않은 창의적인 의자 디자인도 인공지능이 스스로 그려낼 수 있게 됐다.
우리 대학 김재철AI대학원 최재식 교수 연구팀이 네이버(NAVER) AI Lab과 공동 연구를 통해, 추가적 학습 없이 인공지능(AI) 생성 모델의 창의적 생성을 강화하는 기술을 개발했다.
최 교수 연구팀은 텍스트 기반 이미지 생성 모델의 내부 특징 맵을 증폭해 창의적 생성을 강화하는 기술을 개발했다. 또한, 모델 내부의 얕은 블록들이 창의적 생성에 중요한 역할을 한다는 것을 발견하고, 특징 맵을 주파수 영역으로 변환 후, 높은 주파수 영역에 해당하는 부분의 값을 증폭하면 노이즈나 작게 조각난 색깔 패턴의 형태를 유발하는 것을 확인했다. 이에 따라, 연구팀은 얕은 블록의 낮은 주파수 영역을 증폭함으로써 효과적으로 창의적 생성을 강화할 수 있음을 보였다.
연구팀은 창의성을 정의하는 두 가지 핵심 요소인 독창성과 유용성을 모두 고려해, 생성 모델 내부의 각 블록 별로 최적의 증폭 값을 자동으로 선택하는 알고리즘을 제시했다.
개발된 알고리즘을 통해 사전 학습된 스테이블 디퓨전 모델의 내부 특징 맵을 적절히 증폭해 추가적인 분류 데이터나 학습 없이 창의적 생성을 강화할 수 있었다.
연구팀은 개발된 알고리즘을 사용하면 기존 모델 대비 더욱 참신하면서도 유용성이 크게 저하되지 않은 이미지를 생성할 수 있음을 다양한 측정치를 활용해 정량적으로 입증했다.
특히, 스테이블 디퓨전 XL(SDXL) 모델의 이미지 생성 속도를 대폭 향상하기 위해 개발된 SDXL-Turbo 모델에서 발생하는 모드 붕괴 문제를 완화함으로써 이미지 다양성이 증가한 것을 확인했다. 나아가, 사용자 연구를 통해 사람이 직접 평가했을 때도 기존 방법에 비해 유용성 대비 참신성이 크게 향상됨을 입증했다.
공동 제1 저자인 KAIST 한지연, 권다희 박사과정은 "생성 모델을 새로 학습하거나 미세조정 학습하지 않고 생성 모델의 창의적인 생성을 강화하는 최초의 방법론ˮ이라며 "학습된 인공지능 생성 모델 내부에 잠재된 창의성을 특징 맵 조작을 통해 강화할 수 있음을 보였다ˮ 라고 말했다.
이어 “이번 연구는 기존 학습된 모델에서도 텍스트만으로 창의적 이미지를 손쉽게 생성할 수 있게 됐으며, 이를 통해 창의적인 상품 디자인 등 다양한 분야에서 새로운 영감을 제공하고, 인공지능 모델이 창의적 생태계에서 실질적으로 유용하게 활용될 수 있도록 기여할 것으로 기대된다”라고 밝혔다.
KAIST 김재철AI대학원 한지연 박사과정과 권다희 박사과정이 공동 제1 저자로 참여한 이번 연구는 국제 학술지 `국제 컴퓨터 비전 및 패턴인식 학술대회 (IEEE Conference on Computer Vision and Pattern Recognition, CVPR)’에서 6월 15일 발표됐다.
※논문명 : Enhancing Creative Generation on Stable Diffusion-based Models
※DOI: https://doi.org/10.48550/arXiv.2503.23538
한편 이번 연구는 KAIST-네이버 초창의적 AI 연구센터, 과학기술정보통신부의 재원으로 정보통신기획평가원의 지원을 받은 혁신성장동력프로젝트 설명가능인공지능, AI 연구거점 프로젝트, 점차 강화되고 있는 윤리 정책에 발맞춰 유연하게 진화하는 인공지능 기술 개발 연구 및 KAIST 인공지능 대학원 프로그램과제의 지원을 받았고 방위사업청과 국방과학연구소의 지원으로 KAIST 미래 국방 인공지능 특화연구센터에서 수행됐다.
2025.06.19
조회수 1044
-
 AI 기반 화재 걱정없는 고효율 아연-공기 배터리 개발
‘제2의 반도체’로 불리는 리튬이온 전지(LIB)는 가장 높은 시장 점유율로 에너지 저장 장치 시장을 주도하고 있지만, 화재에 취약하는 약점을 가지고 있다. 한국 연구진이 화재로부터 안전하고 값이 저렴한 아연 금속과 공기중의 산소로 구동되는 고에너지 밀도를 가진 고출력 차세대 전지를 개발했다.
우리 대학 신소재공학과 강정구 교수 연구팀이 연세대 한병찬 교수 연구팀, 경북대 최상일 교수 연구팀 및 성균관대 정형모 교수 연구팀과의 공동연구를 통해, 인공지능 기반 이종기능* 전기화학 촉매를 개발 및 촉매 활성 메커니즘을 규명하고, 고효율 아연-공기 전지를 개발했다고 4일 밝혔다.
*이종기능: 충전(Charging) 동안에서의 산소 발생(OER) 기능과 방전(Discharging) 동안의 산소 환원 (ORR) 기능
최근 활발하게 연구가 진행되고 있는 아연-공기 전지 배터리의 음극에 사용되는 아연 금속과 공기극*에 필요한 공기는 자연에 풍부하다는 특성 때문에 소재 비용이 적다는 장점이 있다.
*공기극: 공기 중의 산소를 전극 반응에 활용하는 양극(+)
하지만 고효율 아연-공기 전지를 구현하기 위해서는 충·방전 시에 공기극에서 일어나는 산소 환원 및 산소 발생 반응이 잘 일어나게 하는 이종기능 촉매의 설계가 필수적이다. 하지만 기존에 알려진 상용 촉매는 백금, 이리듐 등 귀금속을 기반으로 하고 있어 가격 경쟁력이 있으면서도 높은 활성도를 지닌 촉매 물질의 개발이 필요하다.
강정구 교수 공동연구팀은 아연 금속-공기 전지에 쓰일 값이 저렴한 전이금속산화물 이종접합 촉매 물질을 개발했다. 해당 촉매 물질은 아연-공기 전지에 사용 시에 귀금속 기반 촉매보다 높은 활성도 및 안정성을 나타냈다. 이와 더불어 해당 연구팀은 인공지능을 활용하여, 기계학습 힘장*을 개발하여 계면에서의 원자구조와 촉매 활성 메커니즘을 정확히 규명하였다.
* 기계학습 힘장(Machine learning force field): 촉매의 성능을 높이려면 계면에서 반응이 원활하게 일어나야 함. 계면에 존재하는 수천만개의 원자들간의 상호 힘을 정확히 이해하기는 기존 방법으로 불가능함. 본 연구에서는 인공지능을 활용하여 양자역학 기반 기계학습 힘장을 개발하여 수천만개의 원자로 구성된 계면구조와 계면에서의 반응 메커니즘을 규명하는데 활용하였음.
연구팀은 개발된 이종기능 촉매를 활용해 아연-공기 완전셀을 구성해 고성능 에너지 저장 소자를 구현했다. 구현된 아연-공기 전지는 기존 상용화된 리튬이온 배터리를 뛰어넘는 에너지 밀도를 가짐을 확인했으며, 저렴한 원료 소재 및 안전성으로 인해 향후 전기 자동차, 웨어러블 전자기기 등에 적용할 수 있을 것으로 예상된다.
강 교수는 "이번 연구로 개발된 전이금속 산화물 기반의 차세대 촉매 소재는 가격 경쟁력과 더불어 높은 촉매 활성도로 인해 아연-금속 공기 전지의 상용화에 기여할 수 있다ˮ라며 "중·소형 전력원뿐만 아니라 향후 전기 자동차까지 활용 범위를 확대해 적용될 수 있을 것이다ˮ고 말했다.
신소재공학과 최종휘 박사과정이 주도한 이번 연구 결과는 에너지 저장 소재 분야의 국제 학술지 `에너지 스토리지 머터리얼스(Energy Storage Materials)'에 지난 1월 14일 字 게재됐다. (논문명: Zeolitic imidazolate framework-derived bifunctional CoO-Mn3O4 heterostructure cathode enhancing oxygen reduction/evolution via dynamic O-vacancy formation and healing for high-performance Zn-air batteries, https://doi.org/10.1016/j.ensm.2025.104040)
한편 이번 연구는 과학기술정보통신부와 한국연구재단의 나노 및 소재기술개발사업 미래기술연구실의 지원을 받아 수행됐다.
AI 기반 화재 걱정없는 고효율 아연-공기 배터리 개발
‘제2의 반도체’로 불리는 리튬이온 전지(LIB)는 가장 높은 시장 점유율로 에너지 저장 장치 시장을 주도하고 있지만, 화재에 취약하는 약점을 가지고 있다. 한국 연구진이 화재로부터 안전하고 값이 저렴한 아연 금속과 공기중의 산소로 구동되는 고에너지 밀도를 가진 고출력 차세대 전지를 개발했다.
우리 대학 신소재공학과 강정구 교수 연구팀이 연세대 한병찬 교수 연구팀, 경북대 최상일 교수 연구팀 및 성균관대 정형모 교수 연구팀과의 공동연구를 통해, 인공지능 기반 이종기능* 전기화학 촉매를 개발 및 촉매 활성 메커니즘을 규명하고, 고효율 아연-공기 전지를 개발했다고 4일 밝혔다.
*이종기능: 충전(Charging) 동안에서의 산소 발생(OER) 기능과 방전(Discharging) 동안의 산소 환원 (ORR) 기능
최근 활발하게 연구가 진행되고 있는 아연-공기 전지 배터리의 음극에 사용되는 아연 금속과 공기극*에 필요한 공기는 자연에 풍부하다는 특성 때문에 소재 비용이 적다는 장점이 있다.
*공기극: 공기 중의 산소를 전극 반응에 활용하는 양극(+)
하지만 고효율 아연-공기 전지를 구현하기 위해서는 충·방전 시에 공기극에서 일어나는 산소 환원 및 산소 발생 반응이 잘 일어나게 하는 이종기능 촉매의 설계가 필수적이다. 하지만 기존에 알려진 상용 촉매는 백금, 이리듐 등 귀금속을 기반으로 하고 있어 가격 경쟁력이 있으면서도 높은 활성도를 지닌 촉매 물질의 개발이 필요하다.
강정구 교수 공동연구팀은 아연 금속-공기 전지에 쓰일 값이 저렴한 전이금속산화물 이종접합 촉매 물질을 개발했다. 해당 촉매 물질은 아연-공기 전지에 사용 시에 귀금속 기반 촉매보다 높은 활성도 및 안정성을 나타냈다. 이와 더불어 해당 연구팀은 인공지능을 활용하여, 기계학습 힘장*을 개발하여 계면에서의 원자구조와 촉매 활성 메커니즘을 정확히 규명하였다.
* 기계학습 힘장(Machine learning force field): 촉매의 성능을 높이려면 계면에서 반응이 원활하게 일어나야 함. 계면에 존재하는 수천만개의 원자들간의 상호 힘을 정확히 이해하기는 기존 방법으로 불가능함. 본 연구에서는 인공지능을 활용하여 양자역학 기반 기계학습 힘장을 개발하여 수천만개의 원자로 구성된 계면구조와 계면에서의 반응 메커니즘을 규명하는데 활용하였음.
연구팀은 개발된 이종기능 촉매를 활용해 아연-공기 완전셀을 구성해 고성능 에너지 저장 소자를 구현했다. 구현된 아연-공기 전지는 기존 상용화된 리튬이온 배터리를 뛰어넘는 에너지 밀도를 가짐을 확인했으며, 저렴한 원료 소재 및 안전성으로 인해 향후 전기 자동차, 웨어러블 전자기기 등에 적용할 수 있을 것으로 예상된다.
강 교수는 "이번 연구로 개발된 전이금속 산화물 기반의 차세대 촉매 소재는 가격 경쟁력과 더불어 높은 촉매 활성도로 인해 아연-금속 공기 전지의 상용화에 기여할 수 있다ˮ라며 "중·소형 전력원뿐만 아니라 향후 전기 자동차까지 활용 범위를 확대해 적용될 수 있을 것이다ˮ고 말했다.
신소재공학과 최종휘 박사과정이 주도한 이번 연구 결과는 에너지 저장 소재 분야의 국제 학술지 `에너지 스토리지 머터리얼스(Energy Storage Materials)'에 지난 1월 14일 字 게재됐다. (논문명: Zeolitic imidazolate framework-derived bifunctional CoO-Mn3O4 heterostructure cathode enhancing oxygen reduction/evolution via dynamic O-vacancy formation and healing for high-performance Zn-air batteries, https://doi.org/10.1016/j.ensm.2025.104040)
한편 이번 연구는 과학기술정보통신부와 한국연구재단의 나노 및 소재기술개발사업 미래기술연구실의 지원을 받아 수행됐다.
2025.03.04
조회수 3919
-
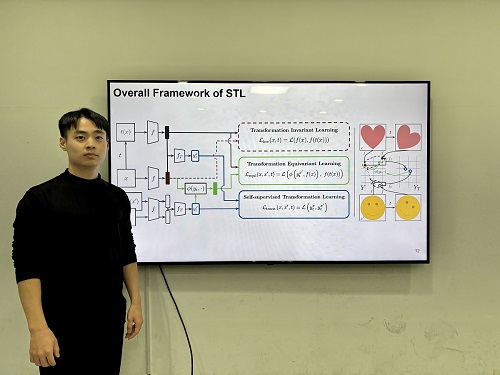 인간의 인지 방식과 유사한 AI 모델 개발
우리 연구진이 인간의 인지 방식을 모방해 이미지 변화를 이해하고, 시각적 일반화와 특정성을 동시에 확보하는 인공지능 기술을 개발했다. 이 기술은 의료 영상 분석, 자율주행, 로보틱스 등 다양한 분야에서 이미지를 이해하여 객체를 분류, 탐지하는 데 활용될 전망이다.
우리 대학 전기및전자공학부 김준모 교수 연구팀이 변환 레이블(transformational labels) 없이도 스스로 변환 민감 특징(transformation-sensitive features)을 학습할 수 있는 새로운 시각 인공지능 모델 STL(Self-supervised Transformation Learning)을 개발했다고 13일 밝혔다.
연구팀이 개발한 시각 인공지능 모델 STL은 스스로 이미지의 변환을 학습하여, 이미지 변환의 종류를 인간이 직접 알려주면서 학습하는 기존 방법들보다 높은 시각 정보 이해 능력을 보였다. 특히, 기존 방법론들을 통해 학습한 모델이 이해할 수 없는 세부적인 특징까지도 학습하여 기존 방법 대비 최대 42% 우수한 성능을 보여줬다.
컴퓨터 비전에서 이미지 변환을 통한 데이터 증강을 활용해 강건한 시각 표현을 학습하는 방식은 일반화 능력을 갖추는 데 효과적이지만, 변환에 따른 시각적 세부 사항을 무시하는 경향이 있어 범용 시각 인공지능 모델로서 한계가 있다.
연구팀이 제안한 STL은 변환 라벨 없이 변환 정보를 학습할 수 있도록 설계된 새로운 학습 기법으로, 라벨 없이 변환 민감 특징을 학습할 수 있다. 또한, 기존 학습 방법 대비 학습 복잡도를 유지한 채로 효율적인 최적화할 수 있는 방법을 제안했다.
실험 결과, STL은 정확하게 객체를 분류하고 탐지 실험에서 가장 낮은 오류율을 기록했다. 또한, STL이 생성한 표현 공간은 변환의 강도와 유형에 따라 명확히 군집화되어 변환 간 관계를 잘 반영하는 것으로 나타났다.
김준모 교수는 "이번에 개발한 STL은 복잡한 변환 패턴을 학습하고 이를 표현 공간에서 효과적으로 반영하는 능력을 통해 변환 민감 특징 학습의 새로운 가능성을 제시했다”며, "라벨 없이도 변환 정보를 학습할 수 있는 기술은 다양한 AI 응용 분야에서 핵심적인 역할을 할 것”이라고 말했다.
우리 대학 전기및전자공학부 유재명 박사과정이 제1 저자로 참여한 이번 연구는 최고 권위 국제 학술지 ‘신경정보처리시스템학회(NeurIPS) 2024’에서 올 12월 발표될 예정이다.(논문명: Self-supervised Transformation Learning for Equivariant Representations)
한편 이번 연구는 이 논문은 2024년도 정부(과학기술정보통신부)의 재원으로 정보통신기획평가원의 지원을 받아 수행된 연구 성과물(No.RS-2024-00439020, 지속가능한 실시간 멀티모달 인터렉티브 생성 AI 개발, SW스타랩) 이다.
인간의 인지 방식과 유사한 AI 모델 개발
우리 연구진이 인간의 인지 방식을 모방해 이미지 변화를 이해하고, 시각적 일반화와 특정성을 동시에 확보하는 인공지능 기술을 개발했다. 이 기술은 의료 영상 분석, 자율주행, 로보틱스 등 다양한 분야에서 이미지를 이해하여 객체를 분류, 탐지하는 데 활용될 전망이다.
우리 대학 전기및전자공학부 김준모 교수 연구팀이 변환 레이블(transformational labels) 없이도 스스로 변환 민감 특징(transformation-sensitive features)을 학습할 수 있는 새로운 시각 인공지능 모델 STL(Self-supervised Transformation Learning)을 개발했다고 13일 밝혔다.
연구팀이 개발한 시각 인공지능 모델 STL은 스스로 이미지의 변환을 학습하여, 이미지 변환의 종류를 인간이 직접 알려주면서 학습하는 기존 방법들보다 높은 시각 정보 이해 능력을 보였다. 특히, 기존 방법론들을 통해 학습한 모델이 이해할 수 없는 세부적인 특징까지도 학습하여 기존 방법 대비 최대 42% 우수한 성능을 보여줬다.
컴퓨터 비전에서 이미지 변환을 통한 데이터 증강을 활용해 강건한 시각 표현을 학습하는 방식은 일반화 능력을 갖추는 데 효과적이지만, 변환에 따른 시각적 세부 사항을 무시하는 경향이 있어 범용 시각 인공지능 모델로서 한계가 있다.
연구팀이 제안한 STL은 변환 라벨 없이 변환 정보를 학습할 수 있도록 설계된 새로운 학습 기법으로, 라벨 없이 변환 민감 특징을 학습할 수 있다. 또한, 기존 학습 방법 대비 학습 복잡도를 유지한 채로 효율적인 최적화할 수 있는 방법을 제안했다.
실험 결과, STL은 정확하게 객체를 분류하고 탐지 실험에서 가장 낮은 오류율을 기록했다. 또한, STL이 생성한 표현 공간은 변환의 강도와 유형에 따라 명확히 군집화되어 변환 간 관계를 잘 반영하는 것으로 나타났다.
김준모 교수는 "이번에 개발한 STL은 복잡한 변환 패턴을 학습하고 이를 표현 공간에서 효과적으로 반영하는 능력을 통해 변환 민감 특징 학습의 새로운 가능성을 제시했다”며, "라벨 없이도 변환 정보를 학습할 수 있는 기술은 다양한 AI 응용 분야에서 핵심적인 역할을 할 것”이라고 말했다.
우리 대학 전기및전자공학부 유재명 박사과정이 제1 저자로 참여한 이번 연구는 최고 권위 국제 학술지 ‘신경정보처리시스템학회(NeurIPS) 2024’에서 올 12월 발표될 예정이다.(논문명: Self-supervised Transformation Learning for Equivariant Representations)
한편 이번 연구는 이 논문은 2024년도 정부(과학기술정보통신부)의 재원으로 정보통신기획평가원의 지원을 받아 수행된 연구 성과물(No.RS-2024-00439020, 지속가능한 실시간 멀티모달 인터렉티브 생성 AI 개발, SW스타랩) 이다.
2024.12.15
조회수 4486
-
 인공지능 화학 학습으로 새로운 소재 개발 가능
새로운 물질을 설계하거나 물질의 물성을 예측하는 데 인공지능을 활용하기도 한다. 한미 공동 연구진이 기본 인공지능 모델보다 발전되어 화학 개념 학습을 하고 소재 예측, 새로운 물질 설계, 물질의 물성 예측에 더 높은 정확도를 제공하는 인공지능을 개발하는 데 성공했다.
우리 대학 화학과 이억균 명예교수와 김형준 교수 공동 연구팀이 창원대학교 생물학화학융합학부 김원준 교수, 미국 UC 머세드(Merced) 응용수학과의 김창호 교수 연구팀과 공동연구를 통해, 새로운 인공지능(AI) 기술인 ‘프로핏-넷(이하 PROFiT-Net)’을 개발하는 데 성공했다고 9일 밝혔다.
연구팀이 개발한 인공지능은 유전율, 밴드갭, 형성 에너지 등의 주요한 소재 물성 예측 정확도에 있어서 이번 기술은 기존 딥러닝 모델의 오차를 최소 10%, 최대 40% 줄일 수 있는 것으로 보여 주목받고 있다.
PROFiT-Net의 가장 큰 특징은 화학의 기본 개념을 학습해 예측 성능을 크게 높였다는 점이다. 최외각 전자 배치, 이온화 에너지, 전기 음성도와 같은 내용은 화학을 배울 때 가장 먼저 배우는 기본 개념 중 하나다.
기존 AI 모델과 달리, PROFiT-Net은 이러한 기본 화학적 속성과 이들 간의 상호작용을 직접적으로 학습함으로써 더욱 정밀한 예측을 할 수 있다. 이는 특히 새로운 물질을 설계하거나 물질의 물성을 예측하는 데 있어 더 높은 정확도를 제공하며, 화학 및 소재 과학 분야에서 크게 기여할 것으로 기대된다.
김형준 교수는 "AI 기술이 기초 화학 개념을 바탕으로 한층 더 발전할 수 있다는 가능성을 보여주었다ˮ고 말했으며 “추후 반도체 소재나 기능성 소재 개발과 같은 다양한 응용 분야에서 AI가 중요한 도구로 자리 잡을 수 있는 발판을 마련했다ˮ고 말했다.
이번 연구는 KAIST의 김세준 박사가 제1 저자로 참여하였고, 국제 학술지 `미국화학회지(Journal of the American Chemical Society)' 에 지난 9월 25일 字 게재됐다.
(논문명: PROFiT-Net: Property-networking deep learning model for materials, PROFiT-Net 링크: https://github.com/sejunkim6370/PROFiT-Net)
한편 이번 연구는 한국연구재단(NRF)의 나노·소재 기술개발(In-memory 컴퓨팅용 강유전체 개발을 위한 전주기 AI 기술)과 탑-티어 연구기관 간 협력 플랫폼 구축 및 공동연구 지원사업으로 진행됐다.
인공지능 화학 학습으로 새로운 소재 개발 가능
새로운 물질을 설계하거나 물질의 물성을 예측하는 데 인공지능을 활용하기도 한다. 한미 공동 연구진이 기본 인공지능 모델보다 발전되어 화학 개념 학습을 하고 소재 예측, 새로운 물질 설계, 물질의 물성 예측에 더 높은 정확도를 제공하는 인공지능을 개발하는 데 성공했다.
우리 대학 화학과 이억균 명예교수와 김형준 교수 공동 연구팀이 창원대학교 생물학화학융합학부 김원준 교수, 미국 UC 머세드(Merced) 응용수학과의 김창호 교수 연구팀과 공동연구를 통해, 새로운 인공지능(AI) 기술인 ‘프로핏-넷(이하 PROFiT-Net)’을 개발하는 데 성공했다고 9일 밝혔다.
연구팀이 개발한 인공지능은 유전율, 밴드갭, 형성 에너지 등의 주요한 소재 물성 예측 정확도에 있어서 이번 기술은 기존 딥러닝 모델의 오차를 최소 10%, 최대 40% 줄일 수 있는 것으로 보여 주목받고 있다.
PROFiT-Net의 가장 큰 특징은 화학의 기본 개념을 학습해 예측 성능을 크게 높였다는 점이다. 최외각 전자 배치, 이온화 에너지, 전기 음성도와 같은 내용은 화학을 배울 때 가장 먼저 배우는 기본 개념 중 하나다.
기존 AI 모델과 달리, PROFiT-Net은 이러한 기본 화학적 속성과 이들 간의 상호작용을 직접적으로 학습함으로써 더욱 정밀한 예측을 할 수 있다. 이는 특히 새로운 물질을 설계하거나 물질의 물성을 예측하는 데 있어 더 높은 정확도를 제공하며, 화학 및 소재 과학 분야에서 크게 기여할 것으로 기대된다.
김형준 교수는 "AI 기술이 기초 화학 개념을 바탕으로 한층 더 발전할 수 있다는 가능성을 보여주었다ˮ고 말했으며 “추후 반도체 소재나 기능성 소재 개발과 같은 다양한 응용 분야에서 AI가 중요한 도구로 자리 잡을 수 있는 발판을 마련했다ˮ고 말했다.
이번 연구는 KAIST의 김세준 박사가 제1 저자로 참여하였고, 국제 학술지 `미국화학회지(Journal of the American Chemical Society)' 에 지난 9월 25일 字 게재됐다.
(논문명: PROFiT-Net: Property-networking deep learning model for materials, PROFiT-Net 링크: https://github.com/sejunkim6370/PROFiT-Net)
한편 이번 연구는 한국연구재단(NRF)의 나노·소재 기술개발(In-memory 컴퓨팅용 강유전체 개발을 위한 전주기 AI 기술)과 탑-티어 연구기관 간 협력 플랫폼 구축 및 공동연구 지원사업으로 진행됐다.
2024.10.10
조회수 8633
-
 고비용 인프라 없이 AI 학습 가속화 가능
우리 대학 연구진이 고가의 데이터센터급 GPU나 고속 네트워크 없이도 AI 모델을 효율적으로 학습할 수 있는 기술을 개발했다. 이 기술을 통해 자원이 제한된 기업이나 연구자들이 AI 연구를 보다 효과적으로 수행할 수 있을 것으로 기대된다.
우리 대학 전기및전자공학부 한동수 교수 연구팀이 일반 소비자용 GPU를 활용해, 네트워크 대역폭이 제한된 분산 환경에서도 AI 모델 학습을 수십에서 수백 배 가속할 수 있는 기술을 개발했다고 19일 밝혔다.
기존에는 AI 모델을 학습하기 위해 개당 수천만 원에 달하는 고성능 서버용 GPU(엔비디아 H100) 여러 대와 이들을 연결하기 위한 400Gbps급 고속 네트워크를 가진 고가 인프라가 필요했다. 하지만 소수의 거대 IT 기업을 제외한 대부분의 기업과 연구자들은 비용 문제로 이러한 고가의 인프라를 도입하기 어려웠다.
한동수 교수 연구팀은 이러한 문제를 해결하기 위해 '스텔라트레인(StellaTrain)'이라는 분산 학습 프레임워크를 개발했다. 이 기술은 고성능 H100에 비해 10~20배 저렴한 소비자용 GPU를 활용해, 고속의 전용 네트워크 대신 대역폭이 수백에서 수천 배 낮은 일반 인터넷 환경에서도 효율적인 분산 학습을 가능하게 한다.
기존의 저가 GPU를 사용할 경우, 작은 GPU 메모리와 네트워크 속도 제한으로 인해 대규모 AI 모델 학습 시 속도가 수백 배 느려지는 한계가 있었다. 하지만 연구팀이 개발한 스텔라트레인 기술은 CPU와 GPU를 병렬로 활용해 학습 속도를 높이고, 네트워크 속도에 맞춰 데이터를 효율적으로 압축 및 전송하는 알고리즘을 적용해 고속 네트워크 없이도 여러 대의 저가 GPU를 이용해 빠른 학습을 가능하게 했다.
특히, 학습을 작업 단계별로 CPU와 GPU가 나누어 병렬적으로 처리할 수 있는 새로운 파이프라인 기술을 도입해 연산 자원의 효율을 극대화했다. 또한, 원거리 분산 환경에서도 GPU 연산 효율을 높이기 위해, AI 모델별 GPU 활용률을 실시간으로 모니터링해 모델이 학습하는 샘플의 개수(배치 크기)를 동적으로 결정하고, 변화하는 네트워크 대역폭에 맞추어 GPU 간의 데이터 전송을 효율화하는 기술을 개발했다.
연구 결과, 스텔라트레인 기술을 사용하면 기존의 데이터 병렬 학습에 비해 최대 104배 빠른 성능을 낼 수 있는 것으로 나타났다.
한동수 교수는 "이번 연구가 대규모 AI 모델 학습을 누구나 쉽게 접근할 수 있게 하는 데 큰 기여를 할 것"이라고 밝혔다. “앞으로도 저비용 환경에서도 대규모 AI 모델을 학습할 수 있는 기술 개발을 계속할 계획이다”라고 말했다.
이번 연구는 우리 대학 임휘준 박사, 예준철 박사과정 학생, UC 어바인의 산기타 압두 조시(Sangeetha Abdu Jyothi) 교수와 공동으로 진행됐으며, 연구 성과는 지난 8월 호주 시드니에서 열린 ACM SIGCOMM 2024에서 발표됐다.
한편, 한동수 교수 연구팀은 2024년 7월 GPU 메모리 한계를 극복해 소수의 GPU로 거대 언어 모델을 학습하는 새로운 기술도 발표했다. 해당 연구는 최신 거대 언어 모델의 기반이 되는 전문가 혼합형(Mixture of Expert) 모델을 제한된 메모리 환경에서도 효율적인 학습을 가능하게 한다.
이 결과 기존에 32~64개 GPU가 필요한 150억 파라미터 규모의 언어 모델을 단 4개의 GPU만으로도 학습할 수 있게 됐다. 이를 통해 학습의 필요한 최소 GPU 대수를 8배~16배 낮출 수 있게 됐다. 해당 논문은 KAIST 임휘준 박사와 김예찬 연구원이 참여했으며, 오스트리아 빈에서 열린 AI 분야 최고 권위 학회인 ICML에 발표됐다. 이러한 일련의 연구 결과는 자원이 제한된 환경에서도 대규모 AI 모델 학습이 가능하다는 점에서 중요한 의미를 가진다.
해당 연구는 과학기술정보통신부 한국연구재단이 주관하는 중견연구사업 (RS-2024-00340099), 정보통신기획평가원(IITP)이 주관하는 정보통신·방송 기술개발사업 및 표준개발지원사업 (RS-2024-00418784), 차세대통신클라우드리더십구축사업 (RS-2024-00123456), 삼성전자의 지원을 받아 수행됐다.
고비용 인프라 없이 AI 학습 가속화 가능
우리 대학 연구진이 고가의 데이터센터급 GPU나 고속 네트워크 없이도 AI 모델을 효율적으로 학습할 수 있는 기술을 개발했다. 이 기술을 통해 자원이 제한된 기업이나 연구자들이 AI 연구를 보다 효과적으로 수행할 수 있을 것으로 기대된다.
우리 대학 전기및전자공학부 한동수 교수 연구팀이 일반 소비자용 GPU를 활용해, 네트워크 대역폭이 제한된 분산 환경에서도 AI 모델 학습을 수십에서 수백 배 가속할 수 있는 기술을 개발했다고 19일 밝혔다.
기존에는 AI 모델을 학습하기 위해 개당 수천만 원에 달하는 고성능 서버용 GPU(엔비디아 H100) 여러 대와 이들을 연결하기 위한 400Gbps급 고속 네트워크를 가진 고가 인프라가 필요했다. 하지만 소수의 거대 IT 기업을 제외한 대부분의 기업과 연구자들은 비용 문제로 이러한 고가의 인프라를 도입하기 어려웠다.
한동수 교수 연구팀은 이러한 문제를 해결하기 위해 '스텔라트레인(StellaTrain)'이라는 분산 학습 프레임워크를 개발했다. 이 기술은 고성능 H100에 비해 10~20배 저렴한 소비자용 GPU를 활용해, 고속의 전용 네트워크 대신 대역폭이 수백에서 수천 배 낮은 일반 인터넷 환경에서도 효율적인 분산 학습을 가능하게 한다.
기존의 저가 GPU를 사용할 경우, 작은 GPU 메모리와 네트워크 속도 제한으로 인해 대규모 AI 모델 학습 시 속도가 수백 배 느려지는 한계가 있었다. 하지만 연구팀이 개발한 스텔라트레인 기술은 CPU와 GPU를 병렬로 활용해 학습 속도를 높이고, 네트워크 속도에 맞춰 데이터를 효율적으로 압축 및 전송하는 알고리즘을 적용해 고속 네트워크 없이도 여러 대의 저가 GPU를 이용해 빠른 학습을 가능하게 했다.
특히, 학습을 작업 단계별로 CPU와 GPU가 나누어 병렬적으로 처리할 수 있는 새로운 파이프라인 기술을 도입해 연산 자원의 효율을 극대화했다. 또한, 원거리 분산 환경에서도 GPU 연산 효율을 높이기 위해, AI 모델별 GPU 활용률을 실시간으로 모니터링해 모델이 학습하는 샘플의 개수(배치 크기)를 동적으로 결정하고, 변화하는 네트워크 대역폭에 맞추어 GPU 간의 데이터 전송을 효율화하는 기술을 개발했다.
연구 결과, 스텔라트레인 기술을 사용하면 기존의 데이터 병렬 학습에 비해 최대 104배 빠른 성능을 낼 수 있는 것으로 나타났다.
한동수 교수는 "이번 연구가 대규모 AI 모델 학습을 누구나 쉽게 접근할 수 있게 하는 데 큰 기여를 할 것"이라고 밝혔다. “앞으로도 저비용 환경에서도 대규모 AI 모델을 학습할 수 있는 기술 개발을 계속할 계획이다”라고 말했다.
이번 연구는 우리 대학 임휘준 박사, 예준철 박사과정 학생, UC 어바인의 산기타 압두 조시(Sangeetha Abdu Jyothi) 교수와 공동으로 진행됐으며, 연구 성과는 지난 8월 호주 시드니에서 열린 ACM SIGCOMM 2024에서 발표됐다.
한편, 한동수 교수 연구팀은 2024년 7월 GPU 메모리 한계를 극복해 소수의 GPU로 거대 언어 모델을 학습하는 새로운 기술도 발표했다. 해당 연구는 최신 거대 언어 모델의 기반이 되는 전문가 혼합형(Mixture of Expert) 모델을 제한된 메모리 환경에서도 효율적인 학습을 가능하게 한다.
이 결과 기존에 32~64개 GPU가 필요한 150억 파라미터 규모의 언어 모델을 단 4개의 GPU만으로도 학습할 수 있게 됐다. 이를 통해 학습의 필요한 최소 GPU 대수를 8배~16배 낮출 수 있게 됐다. 해당 논문은 KAIST 임휘준 박사와 김예찬 연구원이 참여했으며, 오스트리아 빈에서 열린 AI 분야 최고 권위 학회인 ICML에 발표됐다. 이러한 일련의 연구 결과는 자원이 제한된 환경에서도 대규모 AI 모델 학습이 가능하다는 점에서 중요한 의미를 가진다.
해당 연구는 과학기술정보통신부 한국연구재단이 주관하는 중견연구사업 (RS-2024-00340099), 정보통신기획평가원(IITP)이 주관하는 정보통신·방송 기술개발사업 및 표준개발지원사업 (RS-2024-00418784), 차세대통신클라우드리더십구축사업 (RS-2024-00123456), 삼성전자의 지원을 받아 수행됐다.
2024.09.19
조회수 6071
-
 변화에 민감한 사용자도 맞춰주는 인공지능 기술 개발
인공지능 심층신경망 모델의 추천시스템에서 시간이 지남에 따라 사용자의 관심이 변하더라도 변화한 관심 또한 효과적으로 학습할 수 있는 인공지능 훈련 기술 개발이 요구되고 있다. 사용자의 관심이 급변하더라도 기존의 지식을 유지하며 새로운 지식을 축적하는 인공지능 연속 학습을 가능하게 하는 기술이 KAIST 연구진에 의해 개발됐다.
우리 대학 전산학부 이재길 교수 연구팀이 다양한 데이터 변화에 적응하며 새로운 지식을 학습함과 동시에 기존의 지식을 망각하지 않는 새로운 연속 학습(continual learning) 기술을 개발했다고 5일 밝혔다.
최근 연속 학습은 훈련 비용을 줄일 수 있도록 프롬프트(prompt) 기반 방식이 대세를 이루고 있다. 각 작업에 특화된 지식을 프롬프트에 저장하고, 적절한 프롬프트를 입력 데이터에 추가해 심층신경망에 전달함으로써 과거 지식을 효과적으로 활용한다.
이재길 교수팀은 기존 접근방식과 다르게 작업 간의 다양한 변화 정도에 적응할 수 있는 적응적 프롬프팅(adaptive prompting)에 기반한 연속 학습 기술을 제안했다. 현재 학습하려는 작업이 기존에 학습하였던 작업과 유사하다면 새로운 프롬프트를 생성하지 않고 그 작업에 할당된 프롬프트에 추가로 지식을 축적한다. 즉, 완전히 새로운 작업이 입력될 때만 이를 담당하기 위한 새로운 프롬프트를 생성하도록 하고 연구팀은 새로운 작업이 들어올 때마다 클러스터링이 적절한지 검사해 최적의 클러스터링 상태를 유지하도록 했다.
연구팀은 이미지 분류 문제에 대해 작업 간의 다양한 변화 정도를 가지는 실세계 데이터를 사용해 방법론을 검증했다. 이 결과 연구팀은 기존의 프롬프트 기반 연속 학습 방법론에 비해, 작업 간의 변화 정도가 항상 큰 환경에서는 최대 14%의 정확도 향상을 달성했고, 작업 간의 변화가 클 수도 있고 작을 수도 있는 환경에서는 최대 8%의 정확도 향상을 달성했다.
또한, 제안한 방법에서 유지하는 클러스터 개수가 실제 유사한 작업의 그룹 개수와 거의 같음을 확인했다. 온라인 클러스터링을 수행하는 비용이 매우 작아 대용량 데이터에도 쉽게 적용할 수 있다.
연구팀을 지도한 이재길 교수도 "연속 학습 분야의 새로운 지평을 열 만한 획기적인 방법이며 실용화 및 기술 이전이 이뤄지면 심층 학습 학계 및 산업계에 큰 파급효과를 낼 수 있을 것이다ˮ고 말했다.
전산학부 김도영 박사과정 학생이 제1 저자, 이영준 박사과정, 방지환 박사과정 학생이 제4, 제6 저자로 각각 참여한 이번 연구는 최고권위 국제학술대회 `국제머신러닝학회(ICML) 2024'에서 지난 7월 발표됐다. (논문명 : One Size Fits All for Semantic Shifts: Adaptive Prompt Tuning for Continual Learning)
한편, 이 기술은 과학기술정보통신부 재원으로 정보통신기획평가원의 지원을 받아 사람중심인공지능핵심원천기술개발사업 AI학습능력개선기술개발 과제로 개발한 연구성과 결과물(2022-0-00157, 강건하고 공정하며 확장 가능한 데이터 중심의 연속 학습)이다.
변화에 민감한 사용자도 맞춰주는 인공지능 기술 개발
인공지능 심층신경망 모델의 추천시스템에서 시간이 지남에 따라 사용자의 관심이 변하더라도 변화한 관심 또한 효과적으로 학습할 수 있는 인공지능 훈련 기술 개발이 요구되고 있다. 사용자의 관심이 급변하더라도 기존의 지식을 유지하며 새로운 지식을 축적하는 인공지능 연속 학습을 가능하게 하는 기술이 KAIST 연구진에 의해 개발됐다.
우리 대학 전산학부 이재길 교수 연구팀이 다양한 데이터 변화에 적응하며 새로운 지식을 학습함과 동시에 기존의 지식을 망각하지 않는 새로운 연속 학습(continual learning) 기술을 개발했다고 5일 밝혔다.
최근 연속 학습은 훈련 비용을 줄일 수 있도록 프롬프트(prompt) 기반 방식이 대세를 이루고 있다. 각 작업에 특화된 지식을 프롬프트에 저장하고, 적절한 프롬프트를 입력 데이터에 추가해 심층신경망에 전달함으로써 과거 지식을 효과적으로 활용한다.
이재길 교수팀은 기존 접근방식과 다르게 작업 간의 다양한 변화 정도에 적응할 수 있는 적응적 프롬프팅(adaptive prompting)에 기반한 연속 학습 기술을 제안했다. 현재 학습하려는 작업이 기존에 학습하였던 작업과 유사하다면 새로운 프롬프트를 생성하지 않고 그 작업에 할당된 프롬프트에 추가로 지식을 축적한다. 즉, 완전히 새로운 작업이 입력될 때만 이를 담당하기 위한 새로운 프롬프트를 생성하도록 하고 연구팀은 새로운 작업이 들어올 때마다 클러스터링이 적절한지 검사해 최적의 클러스터링 상태를 유지하도록 했다.
연구팀은 이미지 분류 문제에 대해 작업 간의 다양한 변화 정도를 가지는 실세계 데이터를 사용해 방법론을 검증했다. 이 결과 연구팀은 기존의 프롬프트 기반 연속 학습 방법론에 비해, 작업 간의 변화 정도가 항상 큰 환경에서는 최대 14%의 정확도 향상을 달성했고, 작업 간의 변화가 클 수도 있고 작을 수도 있는 환경에서는 최대 8%의 정확도 향상을 달성했다.
또한, 제안한 방법에서 유지하는 클러스터 개수가 실제 유사한 작업의 그룹 개수와 거의 같음을 확인했다. 온라인 클러스터링을 수행하는 비용이 매우 작아 대용량 데이터에도 쉽게 적용할 수 있다.
연구팀을 지도한 이재길 교수도 "연속 학습 분야의 새로운 지평을 열 만한 획기적인 방법이며 실용화 및 기술 이전이 이뤄지면 심층 학습 학계 및 산업계에 큰 파급효과를 낼 수 있을 것이다ˮ고 말했다.
전산학부 김도영 박사과정 학생이 제1 저자, 이영준 박사과정, 방지환 박사과정 학생이 제4, 제6 저자로 각각 참여한 이번 연구는 최고권위 국제학술대회 `국제머신러닝학회(ICML) 2024'에서 지난 7월 발표됐다. (논문명 : One Size Fits All for Semantic Shifts: Adaptive Prompt Tuning for Continual Learning)
한편, 이 기술은 과학기술정보통신부 재원으로 정보통신기획평가원의 지원을 받아 사람중심인공지능핵심원천기술개발사업 AI학습능력개선기술개발 과제로 개발한 연구성과 결과물(2022-0-00157, 강건하고 공정하며 확장 가능한 데이터 중심의 연속 학습)이다.
2024.08.06
조회수 4650
-
 로봇 등 온디바이스 인공지능 실현 가능
자율주행차, 로봇 등 온디바이스 자율 시스템 환경에서 클라우드의 원격 컴퓨팅 자원 없이 기기 자체에 내장된 인공지능 칩을 활용한 온디바이스 자원만으로 적응형 AI를 실현하는 기술이 개발됐다.
우리 대학 전산학부 박종세 교수 연구팀이 지난 6월 29일부터 7월 3일까지 아르헨티나 부에노스아이레스에서 열린 ‘2024 국제 컴퓨터구조 심포지엄(International Symposium on Computer Architecture, ISCA 2024)’에서 최우수 연구 기록물상(Distinguished Artifact Award)을 수상했다고 1일 밝혔다.
* 논문명: 자율 시스템의 비디오 분석을 위한 연속학습 가속화 기법(DaCapo: Accelerating Continuous Learning in Autonomous Systems for Video Analytics)
국제 컴퓨터 구조 심포지움(ISCA)은 컴퓨터 아키텍처 분야에서 최고 권위를 자랑하는 국제 학회로 올해는 423편의 논문이 제출됐으며 그중 83편 만이 채택됐다. (채택률 19.6%). 최우수 연구 기록물 상은 학회에서 주어지는 특별한 상 중 하나로, 제출 논문 중 연구 기록물의 혁신성, 활용 가능성, 영향력을 고려해 선정된다.
이번 수상 연구는 적응형 AI의 기반 기술인 ‘연속 학습’ 가속을 위한 NPU(신경망처리장치) 구조 및 온디바이스 소프트웨어 시스템을 최초 개발한 점, 향후 온디바이스 AI 시스템 연구의 지속적인 발전을 위해 오픈소스로 공개한 코드, 데이터 등의 완성도 측면에서 높은 평가를 받았다.
연구 결과는 소프트웨어 중심 자동차(SDV; Software-Defined Vehicles), 소프트웨어 중심 로봇(SDR; Software-Defined Robots)으로 대표되는 미래 모빌리티 환경에서 온디바이스 AI 시스템을 구축하는 등 다양한 분야에 활용될 수 있을 것으로 기대된다.
상을 받은 전산학부 박종세 교수는 “이번 연구를 통해 온디바이스 자원만으로 적응형 AI를 실현할 수 있다는 것을 입증하게 되어 매우 기쁘고 이 성과는 학생들의 헌신적인 노력과 구글 및 메타 연구자들과의 긴밀한 협력 덕분이다”라며, “앞으로도 온디바이스 AI를 위한 하드웨어와 소프트웨어 연구를 지속해 나갈 것이다”라고 소감을 전했다.
이번 연구는 우리 대학 전산학부 김윤성, 오창훈, 황진우, 김원웅, 오성룡, 이유빈 학생들과 메타(Meta)의 하딕 샤르마(Hardik Sharma) 박사, 구글 딥마인드(Google Deepmind)의 아미르 야즈단바크시(Amir Yazdanbakhsh) 박사, 전산학부 박종세 교수가 참여했다.
한편 이번 연구는 한국연구재단 우수신진연구자지원사업, 정보통신기획평가원(IITP), 대학ICT연구센터(ITRC), 인공지능대학원지원사업, 인공지능반도체대학원지원사업의 지원을 받아 수행됐다.
로봇 등 온디바이스 인공지능 실현 가능
자율주행차, 로봇 등 온디바이스 자율 시스템 환경에서 클라우드의 원격 컴퓨팅 자원 없이 기기 자체에 내장된 인공지능 칩을 활용한 온디바이스 자원만으로 적응형 AI를 실현하는 기술이 개발됐다.
우리 대학 전산학부 박종세 교수 연구팀이 지난 6월 29일부터 7월 3일까지 아르헨티나 부에노스아이레스에서 열린 ‘2024 국제 컴퓨터구조 심포지엄(International Symposium on Computer Architecture, ISCA 2024)’에서 최우수 연구 기록물상(Distinguished Artifact Award)을 수상했다고 1일 밝혔다.
* 논문명: 자율 시스템의 비디오 분석을 위한 연속학습 가속화 기법(DaCapo: Accelerating Continuous Learning in Autonomous Systems for Video Analytics)
국제 컴퓨터 구조 심포지움(ISCA)은 컴퓨터 아키텍처 분야에서 최고 권위를 자랑하는 국제 학회로 올해는 423편의 논문이 제출됐으며 그중 83편 만이 채택됐다. (채택률 19.6%). 최우수 연구 기록물 상은 학회에서 주어지는 특별한 상 중 하나로, 제출 논문 중 연구 기록물의 혁신성, 활용 가능성, 영향력을 고려해 선정된다.
이번 수상 연구는 적응형 AI의 기반 기술인 ‘연속 학습’ 가속을 위한 NPU(신경망처리장치) 구조 및 온디바이스 소프트웨어 시스템을 최초 개발한 점, 향후 온디바이스 AI 시스템 연구의 지속적인 발전을 위해 오픈소스로 공개한 코드, 데이터 등의 완성도 측면에서 높은 평가를 받았다.
연구 결과는 소프트웨어 중심 자동차(SDV; Software-Defined Vehicles), 소프트웨어 중심 로봇(SDR; Software-Defined Robots)으로 대표되는 미래 모빌리티 환경에서 온디바이스 AI 시스템을 구축하는 등 다양한 분야에 활용될 수 있을 것으로 기대된다.
상을 받은 전산학부 박종세 교수는 “이번 연구를 통해 온디바이스 자원만으로 적응형 AI를 실현할 수 있다는 것을 입증하게 되어 매우 기쁘고 이 성과는 학생들의 헌신적인 노력과 구글 및 메타 연구자들과의 긴밀한 협력 덕분이다”라며, “앞으로도 온디바이스 AI를 위한 하드웨어와 소프트웨어 연구를 지속해 나갈 것이다”라고 소감을 전했다.
이번 연구는 우리 대학 전산학부 김윤성, 오창훈, 황진우, 김원웅, 오성룡, 이유빈 학생들과 메타(Meta)의 하딕 샤르마(Hardik Sharma) 박사, 구글 딥마인드(Google Deepmind)의 아미르 야즈단바크시(Amir Yazdanbakhsh) 박사, 전산학부 박종세 교수가 참여했다.
한편 이번 연구는 한국연구재단 우수신진연구자지원사업, 정보통신기획평가원(IITP), 대학ICT연구센터(ITRC), 인공지능대학원지원사업, 인공지능반도체대학원지원사업의 지원을 받아 수행됐다.
2024.08.01
조회수 6947
-
 대형언어모델로 42% 향상된 추천 기술 연구 개발
최근 소셜 미디어, 전자 상거래 플랫폼 등에서 소비자의 만족도를 높이는 다양한 추천서비스를 제공하고 있다. 그 중에서도 상품의 제목 및 설명과 같은 텍스트를 주입하여 상품 추천을 제공하는 대형언어모델(Large Language Model, LLM) 기반 기술이 각광을 받고 있다. 한국 연구진이 이런 대형언어모델 기반 추천 기술의 기존 한계를 극복하고 빠르고 최상의 추천을 해주는 시스템을 개발하여 화제다.
우리 대학 산업및시스템공학과 박찬영 교수 연구팀이 네이버와 공동연구를 통해 협업 필터링(Collaborative filtering) 기반 추천 모델이 학습한 사용자의 선호에 대한 정보를 추출하고 이를 상품의 텍스트와 함께 대형언어모델에 주입해 상품 추천의 높은 정확도를 달성할 수 있는 새로운 대형언어모델 기반 추천시스템 기술을 개발했다고 17일 밝혔다.
이번 연구는 기존 연구에 비해 학습 속도에서 253% 향상, 추론 속도에서 171% 향상, 상품 추천에서 평균 12%의 성능 향상을 이뤄냈다. 특히, 사용자의 소비 이력이 제한된 퓨샷(Few-shot) 상품* 추천에서 평균 20%의 성능 향상, 다중-도메인(Cross-domain) 상품 추천**에서 42%의 성능 향상을 이뤄냈다.
*퓨샷 상품: 사용자의 소비 이력이 풍부하지 않은 상품.
**다중-도메인 상품 추천: 타 도메인에서 학습된 모델을 활용하여 추가학습없이 현재 도메인에서 추천을 수행. 예를 들어, 의류 도메인에 추천 모델을 학습한 뒤, 도서 도메인에서 추천을 수행하는 상황을 일컫는다.
기존 대형언어모델을 활용한 추천 기술들은 사용자가 소비한 상품 이름들을 단순히 텍스트 형태로 나열해 대형언어모델에 주입하는 방식으로 추천을 진행했다. 예를 들어 ‘사용자가 영화 극한직업, 범죄도시1, 범죄도시2를 보았을 때 다음으로 시청할 영화는 무엇인가?’라고 대형언어모델에 질문하는 방식이었다.
이에 반해, 연구팀이 착안한 점은 상품 제목 및 설명과 같은 텍스트뿐 아니라 협업 필터링 지식, 즉, 사용자와 비슷한 상품을 소비한 다른 사용자들에 대한 정보가 정확한 상품 추천에 중요한 역할을 한다는 점이었다. 하지만, 이러한 정보를 단순히 텍스트화하기에는 한계가 존재한다. 이에 따라, 연구팀은 미리 학습된 협업 필터링 기반 추천 모델로부터 사용자의 선호에 대한 정보를 추출하고 이를 대형언어모델이 이해할 수 있도록 변환하는 경량화된 신경망을 도입했다.
연구팀이 개발한 기술의 특징으로는 대형언어모델의 추가적인 학습이 필요하지 않다는 점이다. 기존 연구들은 상품 추천을 목적으로 학습되지 않은 대형언어모델이 상품 추천이 가능하게 하도록 대형언어모델을 파인튜닝(Fine-tuning)* 하는 방법을 사용했다. 하지만, 이는 학습과 추론에 드는 시간을 급격히 증가시키므로 실제 서비스에서 대형언어모델을 추천에 활용하는 것에 큰 걸림돌이 된다. 이에 반해, 연구팀은 대형언어모델의 직접적인 학습 대신 경량화된 신경망의 학습을 통해 대형언어모델이 사용자의 선호를 이해할 수 있도록 했고, 이에 따라 기존 연구보다 빠른 학습 및 추론 속도를 달성했다.
*파인튜닝: 사전 학습된 대규모 언어모델을 특정 작업이나 데이터셋에 맞게 최적화하는 과정.
연구팀을 지도한 박찬영 교수는 “제안한 기술은 대형언어모델을 추천 문제에 해결하려는 기존 연구들이 간과한 사용자-상품 상호작용 정보를 전통적인 협업 필터링 모델에서 추출해 대형언어모델에 전달하는 새로운 방법으로 이는 대화형 추천 시스템이나 개인화 상품 정보 생성 등 다양한 고도화된 추천 서비스를 등장시킬 수 있을 것이며, 추천 도메인에 국한되지 않고 이미지, 텍스트, 사용자-상품 상호작용 정보를 모두 사용하는 진정한 멀티모달 추천 방법론으로 나아갈 수 있을 것”이라고 말했다.
우리 대학 산업및시스템공학과 김세인 박사과정 학생과 전산학부 강홍석 학사과정(졸) 학생이 공동 제1 저자, 네이버의 김동현 박사, 양민철 박사가 공동 저자, KAIST 산업및시스템공학과의 박찬영 교수가 교신저자로 참여한 이번 연구는 데이터마이닝 최고권위 국제학술대회인 ‘국제 데이터 마이닝 학회 ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD 2024)’에서 올 8월 발표할 예정이다. (논문명: Large Language Models meet Collaborative Filtering: An Efficient All-round LLM-based Recommender System).
한편 이번 연구는 네이버 및 정부(과학기술정보통신부)의 재원으로 한국연구재단의 지원을 받아 수행됐다. (NRF-2022M3J6A1063021, RS-2024-00335098)
대형언어모델로 42% 향상된 추천 기술 연구 개발
최근 소셜 미디어, 전자 상거래 플랫폼 등에서 소비자의 만족도를 높이는 다양한 추천서비스를 제공하고 있다. 그 중에서도 상품의 제목 및 설명과 같은 텍스트를 주입하여 상품 추천을 제공하는 대형언어모델(Large Language Model, LLM) 기반 기술이 각광을 받고 있다. 한국 연구진이 이런 대형언어모델 기반 추천 기술의 기존 한계를 극복하고 빠르고 최상의 추천을 해주는 시스템을 개발하여 화제다.
우리 대학 산업및시스템공학과 박찬영 교수 연구팀이 네이버와 공동연구를 통해 협업 필터링(Collaborative filtering) 기반 추천 모델이 학습한 사용자의 선호에 대한 정보를 추출하고 이를 상품의 텍스트와 함께 대형언어모델에 주입해 상품 추천의 높은 정확도를 달성할 수 있는 새로운 대형언어모델 기반 추천시스템 기술을 개발했다고 17일 밝혔다.
이번 연구는 기존 연구에 비해 학습 속도에서 253% 향상, 추론 속도에서 171% 향상, 상품 추천에서 평균 12%의 성능 향상을 이뤄냈다. 특히, 사용자의 소비 이력이 제한된 퓨샷(Few-shot) 상품* 추천에서 평균 20%의 성능 향상, 다중-도메인(Cross-domain) 상품 추천**에서 42%의 성능 향상을 이뤄냈다.
*퓨샷 상품: 사용자의 소비 이력이 풍부하지 않은 상품.
**다중-도메인 상품 추천: 타 도메인에서 학습된 모델을 활용하여 추가학습없이 현재 도메인에서 추천을 수행. 예를 들어, 의류 도메인에 추천 모델을 학습한 뒤, 도서 도메인에서 추천을 수행하는 상황을 일컫는다.
기존 대형언어모델을 활용한 추천 기술들은 사용자가 소비한 상품 이름들을 단순히 텍스트 형태로 나열해 대형언어모델에 주입하는 방식으로 추천을 진행했다. 예를 들어 ‘사용자가 영화 극한직업, 범죄도시1, 범죄도시2를 보았을 때 다음으로 시청할 영화는 무엇인가?’라고 대형언어모델에 질문하는 방식이었다.
이에 반해, 연구팀이 착안한 점은 상품 제목 및 설명과 같은 텍스트뿐 아니라 협업 필터링 지식, 즉, 사용자와 비슷한 상품을 소비한 다른 사용자들에 대한 정보가 정확한 상품 추천에 중요한 역할을 한다는 점이었다. 하지만, 이러한 정보를 단순히 텍스트화하기에는 한계가 존재한다. 이에 따라, 연구팀은 미리 학습된 협업 필터링 기반 추천 모델로부터 사용자의 선호에 대한 정보를 추출하고 이를 대형언어모델이 이해할 수 있도록 변환하는 경량화된 신경망을 도입했다.
연구팀이 개발한 기술의 특징으로는 대형언어모델의 추가적인 학습이 필요하지 않다는 점이다. 기존 연구들은 상품 추천을 목적으로 학습되지 않은 대형언어모델이 상품 추천이 가능하게 하도록 대형언어모델을 파인튜닝(Fine-tuning)* 하는 방법을 사용했다. 하지만, 이는 학습과 추론에 드는 시간을 급격히 증가시키므로 실제 서비스에서 대형언어모델을 추천에 활용하는 것에 큰 걸림돌이 된다. 이에 반해, 연구팀은 대형언어모델의 직접적인 학습 대신 경량화된 신경망의 학습을 통해 대형언어모델이 사용자의 선호를 이해할 수 있도록 했고, 이에 따라 기존 연구보다 빠른 학습 및 추론 속도를 달성했다.
*파인튜닝: 사전 학습된 대규모 언어모델을 특정 작업이나 데이터셋에 맞게 최적화하는 과정.
연구팀을 지도한 박찬영 교수는 “제안한 기술은 대형언어모델을 추천 문제에 해결하려는 기존 연구들이 간과한 사용자-상품 상호작용 정보를 전통적인 협업 필터링 모델에서 추출해 대형언어모델에 전달하는 새로운 방법으로 이는 대화형 추천 시스템이나 개인화 상품 정보 생성 등 다양한 고도화된 추천 서비스를 등장시킬 수 있을 것이며, 추천 도메인에 국한되지 않고 이미지, 텍스트, 사용자-상품 상호작용 정보를 모두 사용하는 진정한 멀티모달 추천 방법론으로 나아갈 수 있을 것”이라고 말했다.
우리 대학 산업및시스템공학과 김세인 박사과정 학생과 전산학부 강홍석 학사과정(졸) 학생이 공동 제1 저자, 네이버의 김동현 박사, 양민철 박사가 공동 저자, KAIST 산업및시스템공학과의 박찬영 교수가 교신저자로 참여한 이번 연구는 데이터마이닝 최고권위 국제학술대회인 ‘국제 데이터 마이닝 학회 ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD 2024)’에서 올 8월 발표할 예정이다. (논문명: Large Language Models meet Collaborative Filtering: An Efficient All-round LLM-based Recommender System).
한편 이번 연구는 네이버 및 정부(과학기술정보통신부)의 재원으로 한국연구재단의 지원을 받아 수행됐다. (NRF-2022M3J6A1063021, RS-2024-00335098)
2024.07.17
조회수 5884
-
 화합물 생성AI 기술로 신약 개발 앞당긴다
신약 개발이나 재료과학과 같은 분야에서는 원하는 화학 특성 조건을 갖춘 물질을 발굴하는 것이 중요한 도전으로 부상하고 있다. 우리 대학 연구팀은 화학반응 예측이나 독성 예측, 그리고 화합물 구조 설계 등 다양한 문제를 동시에 풀면서 기존의 인공지능 기술을 뛰어넘는 성능을 보이는 기술을 개발했다.
김재철AI대학원 예종철 교수 연구팀이 분자 데이터에 다중 모달리티 학습(multi-modal learning) 기술을 도입해, 분자 구조와 그 생화학적 특성을 동시에 생성하고 예측이 가능해 다양한 화학적 과제에 광범위하게 활용가능한 인공지능 기술을 개발했다고 25일 밝혔다.
심층신경망 기술을 통한 인공지능의 발달 이래 이러한 분자와 그 특성값 사이의 관계를 파악하려는 시도는 꾸준히 이루어져 왔다. 최근 비 지도 학습(unsupervised training)을 통한 사전학습 기법이 떠오르면서 분자 구조 자체로부터 화합물의 성질을 예측하는 인공지능 연구들이 제시되었으나 새로운 화합물의 생성하면서도 기존 화합물의 특성 예측이 동시에 가능한 기술은 개발되지 못했다.
연구팀은 화학 특성값의 집합 자체를, 분자를 표현하는 데이터 형식으로 간주해 분자 구조의 표현식과 함께 둘 사이의 상관관계를 아울러 학습하는 AI학습 모델을 제안했다. 유용한 분자 표현식 학습을 위해 컴퓨터 비전 분야에서 주로 연구된 다중 모달리티 학습 기법을 도입해, 두 다른 형식의 데이터를 통합하는 방식으로, 바라는 화합물의 성질을 만족하는 새로운 화합물의 구조를 생성하거나 주어진 화합물의 성질을 예측하는 생성 및 성질 특성이 동시에 가능한 모델을 개발했다.
연구팀이 제안한 모델은 50가지 이상의 동시에 주어지는 특성값 입력을 따르는 분자 구조를 예측하는 등 분자의 구조와 특성 모두의 이해를 요구하는 과제를 해결하는 능력을 보였으며, 이러한 두 데이터 정보 공유를 통해 화학반응 예측 및 독성 예측과 같은 다양한 문제에도 기존의 인공지능 기술을 뛰어넘는 성능을 보이는 것으로 확인됐다.
이 연구는 독성 예측, 후보물질 탐색과 같이 많은 산업계에서 중요하게 다뤄지는 과제를 포함해, 더 광범위하고 풍부한 분자 양식과 고분자, 단백질과 같은 다양한 생화학적 영역에 적용될 수 있을 것으로 기대된다.
예종철 교수는 “새로운 화합물의 생성과 화합물의 특성 예측 기술을 통합하는 화학분야의 새로운 생성 AI기술의 개척을 통해 생성 AI 기술의 저변을 넓힌 것에 자부심을 갖는다”고 말했다.
예종철 교수 연구팀의 장진호 석박통합과정이 제1 저자로 참여한 이번 연구 결과는 국제 학술지 ‘네이처 커뮤니케이션즈(Nature Communications)’지난 3월 14일 자 온라인판에 게재됐다. (논문명 : Bidirectional Generation of Structure and Properties Through a Single Molecular Foundation Model)
한편 이번 연구는 한국연구재단의 AI데이터바이오선도기술개발사업으로 지원됐다.
화합물 생성AI 기술로 신약 개발 앞당긴다
신약 개발이나 재료과학과 같은 분야에서는 원하는 화학 특성 조건을 갖춘 물질을 발굴하는 것이 중요한 도전으로 부상하고 있다. 우리 대학 연구팀은 화학반응 예측이나 독성 예측, 그리고 화합물 구조 설계 등 다양한 문제를 동시에 풀면서 기존의 인공지능 기술을 뛰어넘는 성능을 보이는 기술을 개발했다.
김재철AI대학원 예종철 교수 연구팀이 분자 데이터에 다중 모달리티 학습(multi-modal learning) 기술을 도입해, 분자 구조와 그 생화학적 특성을 동시에 생성하고 예측이 가능해 다양한 화학적 과제에 광범위하게 활용가능한 인공지능 기술을 개발했다고 25일 밝혔다.
심층신경망 기술을 통한 인공지능의 발달 이래 이러한 분자와 그 특성값 사이의 관계를 파악하려는 시도는 꾸준히 이루어져 왔다. 최근 비 지도 학습(unsupervised training)을 통한 사전학습 기법이 떠오르면서 분자 구조 자체로부터 화합물의 성질을 예측하는 인공지능 연구들이 제시되었으나 새로운 화합물의 생성하면서도 기존 화합물의 특성 예측이 동시에 가능한 기술은 개발되지 못했다.
연구팀은 화학 특성값의 집합 자체를, 분자를 표현하는 데이터 형식으로 간주해 분자 구조의 표현식과 함께 둘 사이의 상관관계를 아울러 학습하는 AI학습 모델을 제안했다. 유용한 분자 표현식 학습을 위해 컴퓨터 비전 분야에서 주로 연구된 다중 모달리티 학습 기법을 도입해, 두 다른 형식의 데이터를 통합하는 방식으로, 바라는 화합물의 성질을 만족하는 새로운 화합물의 구조를 생성하거나 주어진 화합물의 성질을 예측하는 생성 및 성질 특성이 동시에 가능한 모델을 개발했다.
연구팀이 제안한 모델은 50가지 이상의 동시에 주어지는 특성값 입력을 따르는 분자 구조를 예측하는 등 분자의 구조와 특성 모두의 이해를 요구하는 과제를 해결하는 능력을 보였으며, 이러한 두 데이터 정보 공유를 통해 화학반응 예측 및 독성 예측과 같은 다양한 문제에도 기존의 인공지능 기술을 뛰어넘는 성능을 보이는 것으로 확인됐다.
이 연구는 독성 예측, 후보물질 탐색과 같이 많은 산업계에서 중요하게 다뤄지는 과제를 포함해, 더 광범위하고 풍부한 분자 양식과 고분자, 단백질과 같은 다양한 생화학적 영역에 적용될 수 있을 것으로 기대된다.
예종철 교수는 “새로운 화합물의 생성과 화합물의 특성 예측 기술을 통합하는 화학분야의 새로운 생성 AI기술의 개척을 통해 생성 AI 기술의 저변을 넓힌 것에 자부심을 갖는다”고 말했다.
예종철 교수 연구팀의 장진호 석박통합과정이 제1 저자로 참여한 이번 연구 결과는 국제 학술지 ‘네이처 커뮤니케이션즈(Nature Communications)’지난 3월 14일 자 온라인판에 게재됐다. (논문명 : Bidirectional Generation of Structure and Properties Through a Single Molecular Foundation Model)
한편 이번 연구는 한국연구재단의 AI데이터바이오선도기술개발사업으로 지원됐다.
2024.03.25
조회수 10560
-
 항암 효과 낮추는 ‘세포 간 이질성’ 극복 전략 찾았다
효과가 높은 신약 및 치료법 개발을 위한 단서가 제시됐다. 우리 대학 수리과학과 김재경 교수(기초과학연구원(IBS) 수리 및 계산 과학 연구단 의생명 수학 그룹 CI(Chief Investigator)) 연구팀은 인공지능(AI)을 이용해 동일 외부 자극에 개별 세포마다 반응하는 정도가 다른 ‘세포 간 이질성’의 근본적인 원인을 찾아내고, 이질성을 최소화할 수 있는 전략을 제시했다.
우리 몸속 세포는 약물, 삼투압 변화 등 다양한 외부 자극에 반응하는 신호 전달 체계(signaling pathway)가 있다. 신호 전달 체계는 세포가 외부 환경과 상호작용하며 생존하는 데 핵심적인 역할을 한다. 세포의 신호 전달 체계는 노벨생리의학상의 단골 주제일 정도로 중요하지만, 규명을 위해서는 수십 년에 걸친 연구가 필요하다.
신호 전달 체계는 세포 간 이질성에도 영향을 미친다. 세포 간 이질성은 똑같은 유전자를 가진 세포들이 동일 외부 자극에 다르게 반응하는 정도를 뜻한다. 하지만 복잡한 신호 전달 체계의 전 과정을 직접 관측하는 일이 현재 기술로는 어렵기 때문에 지금까지는 신호 전달 체계와 세포 간 이질성의 명확한 연결고리를 알지 못했다.
세포 간 이질성은 질병 치료에 있어 더욱 중요한 고려 요소다. 가령, 항암제를 투여했을 때 세포 간 이질성으로 인해 일부 암세포만 사멸되고, 일부는 살아남는다면 완치가 되지 않는다. 세포 간 이질성의 근본적인 원인을 찾고, 이질성을 최소화할 수 있는 전략을 도출해야 치료 효과를 높인 신약 설계가 가능해진다.
제1 저자인 홍혁표 IBS 전(前) 학생연수원(現 미국 위스콘신 메디슨대 방문조교수)은 “우리 연구진은 선행 연구(Science Advances, 2022)에서 세포 내 신호 전달 체계를 묘사한 수리 모델을 개발한 바 있다”며 “당시엔 신호 전달 체계의 중간 과정이 한 개의 경로만 있다고 가정해 얻을 수 있는 정보도 한계가 있었지만, 이번 연구에서는 AI를 활용해 중간 과정의 비밀까지 풀어냈다”고 말했다.
연구진은 기계 학습 방법론인 ‘Density-PINNs(Density Physics-Informed Neural Networks)’를 개발해 신호 전달 체계와 세포 간 이질성의 연결고리를 찾았다. 세포가 외부 자극에 노출되면 신호 전달 체계를 거쳐 반응 단백질이 생성된다. 시간에 따라 축적된 반응 단백질의 양을 이용하면 신호 전달 소요 시간의 분포를 추론할 수 있다. 이 분포는 신호 전달 체계가 몇 개의 경로로 구성됐는지를 알려준다. 즉, Density-PINNs를 이용하면 쉽게 관측할 수 있는 반응 단백질의 시계열 데이터로부터 직접 관찰하기 어려운 신호 전달 체계에 대한 정보를 추정할 수 있다는 의미다.
이어 연구진은 실제 대장균의 항생제에 대한 반응 실험 데이터에 Density-PINNs를 적용하여 세포 간 이질성의 원인도 찾았다. 신호 전달 체계가 단일 경로로 이뤄진 때(직렬)에 비해 여러 경로로 이뤄졌을 때(병렬)가 세포 간 이질성이 적다는 것을 알아냈다.
제1 저자인 조현태 연구원은 “추가 연구가 필요하지만, 신호 전달 체계가 병렬 구조일 경우 극단적인 신호가 서로 상쇄되어서 세포 간 이질성이 적어지는 것으로 보인다”며 “신호 전달 체계가 병렬 구조를 보이도록 약물이나 화학 요법 치료 전략을 세우면 치료 효과를 높일 수 있다는 의미”라고 설명했다.
연구를 이끈 김재경 교수는 “복잡한 세포 신호 전달 체계의 전 과정을 파악하려면 수십 년의 연구가 필요하지만, 우리 연구진이 제시한 방법론은 수 시간 내에 치료에 필요한 핵심 정보만 알아내 치료에 활용할 수 있다”며 “이번 연구를 실제 현장에서 사용되는 약물에 적용하여 치료 효과를 개선할 수 있기를 기대한다”고 말했다.
연구 결과는 지난해 12월 26일 국제학술지 셀(Cell)의 자매지인 ‘패턴스(Patterns)’에 실렸다.
※ 논문명: Density physics-informed neural networks reveal sources of cell heterogeneity in signal transduction
항암 효과 낮추는 ‘세포 간 이질성’ 극복 전략 찾았다
효과가 높은 신약 및 치료법 개발을 위한 단서가 제시됐다. 우리 대학 수리과학과 김재경 교수(기초과학연구원(IBS) 수리 및 계산 과학 연구단 의생명 수학 그룹 CI(Chief Investigator)) 연구팀은 인공지능(AI)을 이용해 동일 외부 자극에 개별 세포마다 반응하는 정도가 다른 ‘세포 간 이질성’의 근본적인 원인을 찾아내고, 이질성을 최소화할 수 있는 전략을 제시했다.
우리 몸속 세포는 약물, 삼투압 변화 등 다양한 외부 자극에 반응하는 신호 전달 체계(signaling pathway)가 있다. 신호 전달 체계는 세포가 외부 환경과 상호작용하며 생존하는 데 핵심적인 역할을 한다. 세포의 신호 전달 체계는 노벨생리의학상의 단골 주제일 정도로 중요하지만, 규명을 위해서는 수십 년에 걸친 연구가 필요하다.
신호 전달 체계는 세포 간 이질성에도 영향을 미친다. 세포 간 이질성은 똑같은 유전자를 가진 세포들이 동일 외부 자극에 다르게 반응하는 정도를 뜻한다. 하지만 복잡한 신호 전달 체계의 전 과정을 직접 관측하는 일이 현재 기술로는 어렵기 때문에 지금까지는 신호 전달 체계와 세포 간 이질성의 명확한 연결고리를 알지 못했다.
세포 간 이질성은 질병 치료에 있어 더욱 중요한 고려 요소다. 가령, 항암제를 투여했을 때 세포 간 이질성으로 인해 일부 암세포만 사멸되고, 일부는 살아남는다면 완치가 되지 않는다. 세포 간 이질성의 근본적인 원인을 찾고, 이질성을 최소화할 수 있는 전략을 도출해야 치료 효과를 높인 신약 설계가 가능해진다.
제1 저자인 홍혁표 IBS 전(前) 학생연수원(現 미국 위스콘신 메디슨대 방문조교수)은 “우리 연구진은 선행 연구(Science Advances, 2022)에서 세포 내 신호 전달 체계를 묘사한 수리 모델을 개발한 바 있다”며 “당시엔 신호 전달 체계의 중간 과정이 한 개의 경로만 있다고 가정해 얻을 수 있는 정보도 한계가 있었지만, 이번 연구에서는 AI를 활용해 중간 과정의 비밀까지 풀어냈다”고 말했다.
연구진은 기계 학습 방법론인 ‘Density-PINNs(Density Physics-Informed Neural Networks)’를 개발해 신호 전달 체계와 세포 간 이질성의 연결고리를 찾았다. 세포가 외부 자극에 노출되면 신호 전달 체계를 거쳐 반응 단백질이 생성된다. 시간에 따라 축적된 반응 단백질의 양을 이용하면 신호 전달 소요 시간의 분포를 추론할 수 있다. 이 분포는 신호 전달 체계가 몇 개의 경로로 구성됐는지를 알려준다. 즉, Density-PINNs를 이용하면 쉽게 관측할 수 있는 반응 단백질의 시계열 데이터로부터 직접 관찰하기 어려운 신호 전달 체계에 대한 정보를 추정할 수 있다는 의미다.
이어 연구진은 실제 대장균의 항생제에 대한 반응 실험 데이터에 Density-PINNs를 적용하여 세포 간 이질성의 원인도 찾았다. 신호 전달 체계가 단일 경로로 이뤄진 때(직렬)에 비해 여러 경로로 이뤄졌을 때(병렬)가 세포 간 이질성이 적다는 것을 알아냈다.
제1 저자인 조현태 연구원은 “추가 연구가 필요하지만, 신호 전달 체계가 병렬 구조일 경우 극단적인 신호가 서로 상쇄되어서 세포 간 이질성이 적어지는 것으로 보인다”며 “신호 전달 체계가 병렬 구조를 보이도록 약물이나 화학 요법 치료 전략을 세우면 치료 효과를 높일 수 있다는 의미”라고 설명했다.
연구를 이끈 김재경 교수는 “복잡한 세포 신호 전달 체계의 전 과정을 파악하려면 수십 년의 연구가 필요하지만, 우리 연구진이 제시한 방법론은 수 시간 내에 치료에 필요한 핵심 정보만 알아내 치료에 활용할 수 있다”며 “이번 연구를 실제 현장에서 사용되는 약물에 적용하여 치료 효과를 개선할 수 있기를 기대한다”고 말했다.
연구 결과는 지난해 12월 26일 국제학술지 셀(Cell)의 자매지인 ‘패턴스(Patterns)’에 실렸다.
※ 논문명: Density physics-informed neural networks reveal sources of cell heterogeneity in signal transduction
2024.01.17
조회수 6075
-
 ‘당신 우울한가요?’ 스마트폰으로 진단하다
요즘 현대인들에게 많이 찾아오는 우울증을 진단하기 위한 스마트폰으로 진단하는 연구가 개발되어 화제다.
우리 대학 전기및전자공학부 이성주 교수 연구팀이 사용자의 언어 사용 패턴을 개인정보 유출 없이 스마트폰에서 자동으로 분석해 사용자의 정신건강 상태를 모니터링하는 인공지능 기술을 개발했다고 21일 밝혔다. 사용자가 스마트폰을 소지하고 일상적으로 사용하기만 해도 스마트폰이 사용자의 정신건강 상태를 분석 및 진단할 수 있는 것이다.
연구팀은 임상적으로 이뤄지는 정신질환 진단이 환자와의 상담을 통한 언어 사용 분석에서 이루어진다는 점에 착안해 연구를 진행했다. 이번 기술에서는 (1) 사용자가 직접 작성한 문자 메시지 등의 키보드 입력 내용과, (2) 스마트폰 위 마이크에서 실시간으로 수집되는 사용자의 음성 데이터를 기반으로 정신건강 진단을 수행한다.
이러한 언어 데이터는 사용자의 민감한 정보를 담고 있을 수 있어 기존에는 활용이 어려웠다. 이러한 문제의 해결을 위해 이번 기술에는 연합학습 인공지능 기술이 적용됐는데, 이는 사용자 기기 외부로의 데이터 유출 없이 인공지능 모델을 학습해 사생활 침해의 우려가 없다는 것이 특징이다.
인공지능 모델은 일상 대화 내용과 화자의 정신건강을 바탕으로 한 데이터셋을 기반으로 학습되었다. 모델은 스마트폰에서 입력으로 주어지는 대화를 실시간으로 분석하여 학습된 내용을 바탕으로 사용자의 정신건강 척도를 예측한다.
더 나아가, 연구팀은 스마트폰 위 대량으로 주어지는 사용자 언어 데이터로부터 효과적인 정신건강 진단을 수행하는 방법론을 개발했다. 연구팀은 사용자들이 언어를 사용하는 패턴이 실생활 속 다양한 상황에 따라 다르다는 것에 착안해, 스마트폰 위에서 주어지는 현재 상황에 대한 단서를 기반으로, 인공지능 모델이 상대적으로 중요한 언어 데이터에 집중하도록 설계했다. 예를 들어, 업무 시간보다는 저녁 시간에 가족 또는 친구들과 나누는 대화에 정신건강을 모니터링 할 수 있는 단서가 많다고 인공지능 모델이 판단해 중점을 두고 분석하는 식이다.
이번 논문은 전산학부 신재민 박사과정, 전기및전자공학부 윤형준 박사과정, 이승주 석사과정, 이성주 교수와 박성준 SoftlyAI 대표(KAIST 졸업생), 중국 칭화대학교 윤신 리우(Yunxin Liu) 교수, 그리고 미국 에모리(Emory) 대학교 최진호 교수의 공동연구로 이뤄졌다.
이번 논문은 올해 12월 6일부터 10일까지 싱가폴에서 열린 자연어 처리 분야 최고 권위 학회인 EMNLP(Conference on Empirical Methods in Natural Language Processing)에서 발표됐다.
※ 논문명(FedTherapist: Mental Health Monitoring with User-Generated Linguistic Expressions on Smartphones via Federated Learning)
이성주 교수는 "이번 연구는 모바일 센싱, 자연어 처리, 인공지능, 심리학 전문가들의 협력으로 이루어져서 의미가 깊으며, 정신질환으로 어려워하는 사람들이 많은데, 개인정보 유출이나 사생활 침범의 걱정 없이 스마트폰 사용만으로 정신건강 상태를 조기진단 할 수 있게 되었다ˮ라며, "이번 연구가 서비스화되어 사회에 도움이 되면 좋겠다ˮ라고 소감을 밝혔다.
이 연구는 정부(과학기술정보통신부)의 재원으로 정보통신기획평가원의 지원을 받아 수행됐다. (No. 2022-0-00495, 휴대폰 단말에서의 보이스피싱 탐지 예방 기술 개발, No. 2022-0-00064, 감정노동자의 정신건강 위험 예측 및 관리를 위한 휴먼 디지털 트윈 기술 개발)
‘당신 우울한가요?’ 스마트폰으로 진단하다
요즘 현대인들에게 많이 찾아오는 우울증을 진단하기 위한 스마트폰으로 진단하는 연구가 개발되어 화제다.
우리 대학 전기및전자공학부 이성주 교수 연구팀이 사용자의 언어 사용 패턴을 개인정보 유출 없이 스마트폰에서 자동으로 분석해 사용자의 정신건강 상태를 모니터링하는 인공지능 기술을 개발했다고 21일 밝혔다. 사용자가 스마트폰을 소지하고 일상적으로 사용하기만 해도 스마트폰이 사용자의 정신건강 상태를 분석 및 진단할 수 있는 것이다.
연구팀은 임상적으로 이뤄지는 정신질환 진단이 환자와의 상담을 통한 언어 사용 분석에서 이루어진다는 점에 착안해 연구를 진행했다. 이번 기술에서는 (1) 사용자가 직접 작성한 문자 메시지 등의 키보드 입력 내용과, (2) 스마트폰 위 마이크에서 실시간으로 수집되는 사용자의 음성 데이터를 기반으로 정신건강 진단을 수행한다.
이러한 언어 데이터는 사용자의 민감한 정보를 담고 있을 수 있어 기존에는 활용이 어려웠다. 이러한 문제의 해결을 위해 이번 기술에는 연합학습 인공지능 기술이 적용됐는데, 이는 사용자 기기 외부로의 데이터 유출 없이 인공지능 모델을 학습해 사생활 침해의 우려가 없다는 것이 특징이다.
인공지능 모델은 일상 대화 내용과 화자의 정신건강을 바탕으로 한 데이터셋을 기반으로 학습되었다. 모델은 스마트폰에서 입력으로 주어지는 대화를 실시간으로 분석하여 학습된 내용을 바탕으로 사용자의 정신건강 척도를 예측한다.
더 나아가, 연구팀은 스마트폰 위 대량으로 주어지는 사용자 언어 데이터로부터 효과적인 정신건강 진단을 수행하는 방법론을 개발했다. 연구팀은 사용자들이 언어를 사용하는 패턴이 실생활 속 다양한 상황에 따라 다르다는 것에 착안해, 스마트폰 위에서 주어지는 현재 상황에 대한 단서를 기반으로, 인공지능 모델이 상대적으로 중요한 언어 데이터에 집중하도록 설계했다. 예를 들어, 업무 시간보다는 저녁 시간에 가족 또는 친구들과 나누는 대화에 정신건강을 모니터링 할 수 있는 단서가 많다고 인공지능 모델이 판단해 중점을 두고 분석하는 식이다.
이번 논문은 전산학부 신재민 박사과정, 전기및전자공학부 윤형준 박사과정, 이승주 석사과정, 이성주 교수와 박성준 SoftlyAI 대표(KAIST 졸업생), 중국 칭화대학교 윤신 리우(Yunxin Liu) 교수, 그리고 미국 에모리(Emory) 대학교 최진호 교수의 공동연구로 이뤄졌다.
이번 논문은 올해 12월 6일부터 10일까지 싱가폴에서 열린 자연어 처리 분야 최고 권위 학회인 EMNLP(Conference on Empirical Methods in Natural Language Processing)에서 발표됐다.
※ 논문명(FedTherapist: Mental Health Monitoring with User-Generated Linguistic Expressions on Smartphones via Federated Learning)
이성주 교수는 "이번 연구는 모바일 센싱, 자연어 처리, 인공지능, 심리학 전문가들의 협력으로 이루어져서 의미가 깊으며, 정신질환으로 어려워하는 사람들이 많은데, 개인정보 유출이나 사생활 침범의 걱정 없이 스마트폰 사용만으로 정신건강 상태를 조기진단 할 수 있게 되었다ˮ라며, "이번 연구가 서비스화되어 사회에 도움이 되면 좋겠다ˮ라고 소감을 밝혔다.
이 연구는 정부(과학기술정보통신부)의 재원으로 정보통신기획평가원의 지원을 받아 수행됐다. (No. 2022-0-00495, 휴대폰 단말에서의 보이스피싱 탐지 예방 기술 개발, No. 2022-0-00064, 감정노동자의 정신건강 위험 예측 및 관리를 위한 휴먼 디지털 트윈 기술 개발)
2023.12.21
조회수 9929
-
 하운드(Hound) 로봇, 100m를 19.87초 주파, 기네스 기록
우리 대학 기계공학과의 박해원 교수 연구팀이 제작한 사족 로봇 하운드(Hound)의 사족 보행 로봇의 100m 달리기 기록이 기네스 세계 기록으로 인정받았다고 15일 밝혔다.
하운드(Hound)는 KAIST 동적 로봇 설계 및 제어 연구실(Dynamic Robot Control and Design Laboratory)에서 제작된 로봇으로, 지난 2023년 10월 26일에 측정된 실험을 통해 정지 상태에서 출발해 100미터 선을 19.87초 만에 통과한 후 완전히 멈추는 데 성공했다. 이 성과는 AI 방법론 중 하나인 강화학습을 이용해 시뮬레이션 가상환경에서 훈련된 단일 제어기를 통해 달성됐다.
연구팀은 하운드(Hound) 로봇이 고속으로 달릴 수 있도록, 액추에이터 출력의 한계를 최대한 이용하기 위해, 모터가 최대로 낼 수 있는 한계 토크와 속도 특성을 강화학습에 활용했다. 또한, 대칭적인 걸음새를 통해 모터의 출력을 고르게 분배하고, 로봇의 빠른 움직임을 위해 경량 발바닥을 설계했다. 이러한 종합적인 설계와 제어에 대한 접근방식을 통해 하운드(Hound)는 빠른 속도로 100미터를 주파할 수 있었다.
하운드(Hound)의 100미터 달리기 기록은 우리 대학 대운동장의 실외 육상 트랙에서 공식적으로 측정됐다.
하운드(Hound)는 실외뿐만 아니라 실내 러닝머신 위에서 6.5m/s (시속 23.4km)의 주행 속도를 기록했다. 이는 전기 모터 기반 사족 로봇의 최고속도이며, 기존 메사추세츠 공과대학교(MIT)의 치타 2(Cheetah 2)의 6.4m/s를 뛰어넘는 기록이다. 박해원 교수 연구팀은 이 성과 또한 기네스 기록 인증을 신청 중이다.
연구 책임자인 기계공학과 박해원 교수는 “KAIST의 기술로 직접 설계 제작된 사족 보행 로봇과 AI 학습 기반 제어기로 보행 로봇 세계 최고속도를 세움으로써 우리나라의 로봇 하드웨어 기술 및 로봇제어 AI 기술이 세계 최고 수준을 보여줬다는 데 의의가 있다”이라고 소감을 전했다.
한편 이번 연구는 2019년 국방과학연구소 미래도전국방기술 연구개발사업(912768601)의 지원을 받아 수행됐다.
기네스 기록 홈페이지 링크 : https://www.guinnessworldrecords.com/world-records/625586-fastest-100-m-by-a-quadrupedal-robot
기네스 Youtube 계정에 올라온 영상 : https://www.youtube.com/shorts/sdF1cn7iX0g
하운드(Hound) 로봇, 100m를 19.87초 주파, 기네스 기록
우리 대학 기계공학과의 박해원 교수 연구팀이 제작한 사족 로봇 하운드(Hound)의 사족 보행 로봇의 100m 달리기 기록이 기네스 세계 기록으로 인정받았다고 15일 밝혔다.
하운드(Hound)는 KAIST 동적 로봇 설계 및 제어 연구실(Dynamic Robot Control and Design Laboratory)에서 제작된 로봇으로, 지난 2023년 10월 26일에 측정된 실험을 통해 정지 상태에서 출발해 100미터 선을 19.87초 만에 통과한 후 완전히 멈추는 데 성공했다. 이 성과는 AI 방법론 중 하나인 강화학습을 이용해 시뮬레이션 가상환경에서 훈련된 단일 제어기를 통해 달성됐다.
연구팀은 하운드(Hound) 로봇이 고속으로 달릴 수 있도록, 액추에이터 출력의 한계를 최대한 이용하기 위해, 모터가 최대로 낼 수 있는 한계 토크와 속도 특성을 강화학습에 활용했다. 또한, 대칭적인 걸음새를 통해 모터의 출력을 고르게 분배하고, 로봇의 빠른 움직임을 위해 경량 발바닥을 설계했다. 이러한 종합적인 설계와 제어에 대한 접근방식을 통해 하운드(Hound)는 빠른 속도로 100미터를 주파할 수 있었다.
하운드(Hound)의 100미터 달리기 기록은 우리 대학 대운동장의 실외 육상 트랙에서 공식적으로 측정됐다.
하운드(Hound)는 실외뿐만 아니라 실내 러닝머신 위에서 6.5m/s (시속 23.4km)의 주행 속도를 기록했다. 이는 전기 모터 기반 사족 로봇의 최고속도이며, 기존 메사추세츠 공과대학교(MIT)의 치타 2(Cheetah 2)의 6.4m/s를 뛰어넘는 기록이다. 박해원 교수 연구팀은 이 성과 또한 기네스 기록 인증을 신청 중이다.
연구 책임자인 기계공학과 박해원 교수는 “KAIST의 기술로 직접 설계 제작된 사족 보행 로봇과 AI 학습 기반 제어기로 보행 로봇 세계 최고속도를 세움으로써 우리나라의 로봇 하드웨어 기술 및 로봇제어 AI 기술이 세계 최고 수준을 보여줬다는 데 의의가 있다”이라고 소감을 전했다.
한편 이번 연구는 2019년 국방과학연구소 미래도전국방기술 연구개발사업(912768601)의 지원을 받아 수행됐다.
기네스 기록 홈페이지 링크 : https://www.guinnessworldrecords.com/world-records/625586-fastest-100-m-by-a-quadrupedal-robot
기네스 Youtube 계정에 올라온 영상 : https://www.youtube.com/shorts/sdF1cn7iX0g
2023.12.15
조회수 7517