-
 AI가 여론 조작? 한국어 'AI 생성 댓글' 탐지 기술 개발
생성형 AI 기술이 발전하면서 이를 악용한 온라인 여론 조작 우려가 커지고 있다. 이에 따른 AI 생성글 탐지 기술도 개발되었는데 대부분 영어로 된 장문의 정형화된 글을 기반으로 개발돼, 짧고(평균 51자), 구어체 표현이 많은 한국어 뉴스 댓글에는 적용이 어려웠다. 우리 연구진이 한국어 AI 생성 댓글을 탐지하는 기술을 개발해서 화제다.
우리 대학 전기및전자공학부 김용대 교수 연구팀이 국가보안기술연구소(국보연)와 협력해, 한국어 AI 생성 댓글을 탐지하는 기술 'XDAC'를 세계 최초로 개발했다고 23일 밝혔다.
최근 생성형 AI는 뉴스 기사 맥락에 맞춰 감정과 논조까지 조절할 수 있으며, 몇 시간 만에 수십만 개의 댓글을 자동 생성할 수 있어 여론 조작에 악용될 수 있다. OpenAI의 GPT-4o API를 기준으로 하면 댓글 1개 생성 비용은 약 1원 수준이며, 국내 주요 뉴스 플랫폼의 하루 평균 댓글 수인 20만 개를 생성하는 데 단 20만 원이면 가능할 정도다. 공개 LLM은 자체 GPU 인프라만 갖추면 사실상 무상으로도 대량의 댓글 생성을 수행할 수 있다.
연구팀은 AI 생성 댓글과 사람 작성 댓글을 사람이 구별할 수 있는지 실험했다. 총 210개의 댓글을 평가한 결과, AI 생성 댓글의 67%를 사람이 작성한 것으로 착각했고, 실제 사람 작성 댓글도 73%만 정확히 구분해냈다. 즉, 사람조차 AI 생성 댓글을 정확히 구별하기 어려운 수준에 이르렀다는 의미다. AI 생성 댓글은 오히려 기사 맥락 관련성(95% vs 87%), 문장 유창성(71% vs 45%), 편향성 인식(33% vs 50%)에서 사람 작성 댓글보다 높은 평가를 받았다.
그동안 AI 생성글 탐지 기술은 대부분 영어로 된 장문의 정형화된 글을 기반으로 개발되어 한국어의 짧은 댓글에는 적용이 어려웠다. 짧은 댓글은 통계적 특징이 불충분하고, 이모지·비속어·반복 문자 등 비정형 구어 표현이 많아 기존 탐지 모델이 효과적으로 작동하지 않는다. 또한, 현실적인 한국어 AI 생성 댓글 데이터셋이 부족하고, 기존의 단순한 프롬프팅 방식으로는 다양하고 실제적인 댓글을 생성하는 데 한계가 있었다.
이에 연구팀은 ▲14종의 다양한 LLM 활용 ▲자연스러움 강화 ▲세밀한 감정 제어 ▲참조자료를 통한 증강 생성의 네 가지 전략을 적용한 AI 댓글 생성 프레임워크를 개발해, 실제 이용자 스타일을 모방한 한국어 AI 생성 댓글 데이터셋을 구축하고 이 중 일부를 벤치마크 데이터셋으로 공개했다. 또 설명 가능한 AI(XAI) 기법을 적용해 언어 표현을 정밀 분석한 결과, AI 생성 댓글에는 사람과 다른 고유한 말투 패턴이 있음을 확인했다.
예를 들어, AI는 "것 같다", "에 대해" 등 형식적 표현과 높은 접속어 사용률을 보였고, 사람은 반복 문자(ㅋㅋㅋㅋ), 감정 표현, 줄바꿈, 특수기호 등 자유로운 구어체 표현을 즐겨 사용했다.
특수문자 사용에서도 AI는 전 세계적으로 통용되는 표준화된 이모지를 주로 사용하는 반면, 사람은 한국어 자음(ㅋ, ㅠ, ㅜ 등)이나 특수 기호(ㆍ, ♡, ★, • 등) 등 문화적 특수성이 담긴 다양한 문자를 활용했다.
특히, 서식 문자(줄바꿈, 여러 칸 띄어쓰기 등) 사용에서 사람 작성 댓글의 26%는 이런 서식 문자를 포함했지만, AI 생성 댓글은 단 1%만 사용했다. 반복 문자(예: ㅋㅋㅋㅋ, ㅎㅎㅎㅎ 등) 사용 비율도 사람 작성 댓글이 52%로, AI 생성 댓글(12%)보다 훨씬 높았다.
XDAC는 이러한 차이를 정교하게 반영해 탐지 성능을 높였다. 줄바꿈, 공백 등 서식 문자를 변환하고, 반복 문자 패턴을 기계가 이해할 수 있도록 변환하는 방식이 적용됐다. 또 각 LLM의 고유 말투 특징을 파악해 어떤 AI 모델이 댓글을 생성했는지도 식별 가능하게 설계됐다.
이러한 최적화로 XDAC는 AI 생성 댓글 탐지에서 98.5% F1 점수로 기존 연구 대비 68% 성능을 향상시켰으며, 댓글 생성 LLM 식별에서도 84.3% F1 성능을 기록했다.
고우영 선임연구원은 "이번 연구는 생성형 AI가 작성한 짧은 댓글을 높은 정확도로 탐지하고, 생성 모델까지 식별할 수 있는 세계 최초 기술"이라며 "AI 기반 여론 조작 대응의 기술적 기반을 마련한 데 큰 의의가 있다"고 강조했다.
연구팀은 XDAC의 탐지 기술이 단순 판별을 넘어 심리적 억제 장치로도 작용할 수 있다고 설명했다. 마치 음주단속, 마약 검사, CCTV 설치 등이 범죄 억제 효과를 가지듯, 정밀 탐지 기술의 존재 자체가 AI 악용 시도를 줄일 수 있다는 것이다.
XDAC는 플랫폼 사업자가 의심스러운 계정이나 조직적 여론 조작 시도를 정밀 감시·대응하는 데 활용될 수 있으며, 향후 실시간 감시 시스템이나 자동 대응 알고리즘으로 확장 가능성이 크다.
이번 연구는 설명가능 인공지능(XAI) 기반 탐지 프레임워크를 제안한 것이 핵심이며, 인공지능 자연어처리 분야 최고 권위 학술대회인 7월 27일부터 개최되는 'ACL 2025' 메인 콘퍼런스에 채택되며 기술력을 인정받았다.
※논문 제목: XDAC: XAI-Driven Detection and Attribution of LLM-Generated News Comments in Korean
※논문원본: https://github.com/airobotlab/XDAC/blob/main/paper/250611_XDAC_ACL2025_camera_ready.pdf
이번 연구는 우리 대학 김용대 교수의 지도 아래 국보연 소속이자 우리 대학 박사과정인 고우영 선임연구원이 제1 저자로 참여했으며, 성균관대학교 김형식 교수와 우리 대학 오혜연 교수가 공동 연구자로 참여했다.
AI가 여론 조작? 한국어 'AI 생성 댓글' 탐지 기술 개발
생성형 AI 기술이 발전하면서 이를 악용한 온라인 여론 조작 우려가 커지고 있다. 이에 따른 AI 생성글 탐지 기술도 개발되었는데 대부분 영어로 된 장문의 정형화된 글을 기반으로 개발돼, 짧고(평균 51자), 구어체 표현이 많은 한국어 뉴스 댓글에는 적용이 어려웠다. 우리 연구진이 한국어 AI 생성 댓글을 탐지하는 기술을 개발해서 화제다.
우리 대학 전기및전자공학부 김용대 교수 연구팀이 국가보안기술연구소(국보연)와 협력해, 한국어 AI 생성 댓글을 탐지하는 기술 'XDAC'를 세계 최초로 개발했다고 23일 밝혔다.
최근 생성형 AI는 뉴스 기사 맥락에 맞춰 감정과 논조까지 조절할 수 있으며, 몇 시간 만에 수십만 개의 댓글을 자동 생성할 수 있어 여론 조작에 악용될 수 있다. OpenAI의 GPT-4o API를 기준으로 하면 댓글 1개 생성 비용은 약 1원 수준이며, 국내 주요 뉴스 플랫폼의 하루 평균 댓글 수인 20만 개를 생성하는 데 단 20만 원이면 가능할 정도다. 공개 LLM은 자체 GPU 인프라만 갖추면 사실상 무상으로도 대량의 댓글 생성을 수행할 수 있다.
연구팀은 AI 생성 댓글과 사람 작성 댓글을 사람이 구별할 수 있는지 실험했다. 총 210개의 댓글을 평가한 결과, AI 생성 댓글의 67%를 사람이 작성한 것으로 착각했고, 실제 사람 작성 댓글도 73%만 정확히 구분해냈다. 즉, 사람조차 AI 생성 댓글을 정확히 구별하기 어려운 수준에 이르렀다는 의미다. AI 생성 댓글은 오히려 기사 맥락 관련성(95% vs 87%), 문장 유창성(71% vs 45%), 편향성 인식(33% vs 50%)에서 사람 작성 댓글보다 높은 평가를 받았다.
그동안 AI 생성글 탐지 기술은 대부분 영어로 된 장문의 정형화된 글을 기반으로 개발되어 한국어의 짧은 댓글에는 적용이 어려웠다. 짧은 댓글은 통계적 특징이 불충분하고, 이모지·비속어·반복 문자 등 비정형 구어 표현이 많아 기존 탐지 모델이 효과적으로 작동하지 않는다. 또한, 현실적인 한국어 AI 생성 댓글 데이터셋이 부족하고, 기존의 단순한 프롬프팅 방식으로는 다양하고 실제적인 댓글을 생성하는 데 한계가 있었다.
이에 연구팀은 ▲14종의 다양한 LLM 활용 ▲자연스러움 강화 ▲세밀한 감정 제어 ▲참조자료를 통한 증강 생성의 네 가지 전략을 적용한 AI 댓글 생성 프레임워크를 개발해, 실제 이용자 스타일을 모방한 한국어 AI 생성 댓글 데이터셋을 구축하고 이 중 일부를 벤치마크 데이터셋으로 공개했다. 또 설명 가능한 AI(XAI) 기법을 적용해 언어 표현을 정밀 분석한 결과, AI 생성 댓글에는 사람과 다른 고유한 말투 패턴이 있음을 확인했다.
예를 들어, AI는 "것 같다", "에 대해" 등 형식적 표현과 높은 접속어 사용률을 보였고, 사람은 반복 문자(ㅋㅋㅋㅋ), 감정 표현, 줄바꿈, 특수기호 등 자유로운 구어체 표현을 즐겨 사용했다.
특수문자 사용에서도 AI는 전 세계적으로 통용되는 표준화된 이모지를 주로 사용하는 반면, 사람은 한국어 자음(ㅋ, ㅠ, ㅜ 등)이나 특수 기호(ㆍ, ♡, ★, • 등) 등 문화적 특수성이 담긴 다양한 문자를 활용했다.
특히, 서식 문자(줄바꿈, 여러 칸 띄어쓰기 등) 사용에서 사람 작성 댓글의 26%는 이런 서식 문자를 포함했지만, AI 생성 댓글은 단 1%만 사용했다. 반복 문자(예: ㅋㅋㅋㅋ, ㅎㅎㅎㅎ 등) 사용 비율도 사람 작성 댓글이 52%로, AI 생성 댓글(12%)보다 훨씬 높았다.
XDAC는 이러한 차이를 정교하게 반영해 탐지 성능을 높였다. 줄바꿈, 공백 등 서식 문자를 변환하고, 반복 문자 패턴을 기계가 이해할 수 있도록 변환하는 방식이 적용됐다. 또 각 LLM의 고유 말투 특징을 파악해 어떤 AI 모델이 댓글을 생성했는지도 식별 가능하게 설계됐다.
이러한 최적화로 XDAC는 AI 생성 댓글 탐지에서 98.5% F1 점수로 기존 연구 대비 68% 성능을 향상시켰으며, 댓글 생성 LLM 식별에서도 84.3% F1 성능을 기록했다.
고우영 선임연구원은 "이번 연구는 생성형 AI가 작성한 짧은 댓글을 높은 정확도로 탐지하고, 생성 모델까지 식별할 수 있는 세계 최초 기술"이라며 "AI 기반 여론 조작 대응의 기술적 기반을 마련한 데 큰 의의가 있다"고 강조했다.
연구팀은 XDAC의 탐지 기술이 단순 판별을 넘어 심리적 억제 장치로도 작용할 수 있다고 설명했다. 마치 음주단속, 마약 검사, CCTV 설치 등이 범죄 억제 효과를 가지듯, 정밀 탐지 기술의 존재 자체가 AI 악용 시도를 줄일 수 있다는 것이다.
XDAC는 플랫폼 사업자가 의심스러운 계정이나 조직적 여론 조작 시도를 정밀 감시·대응하는 데 활용될 수 있으며, 향후 실시간 감시 시스템이나 자동 대응 알고리즘으로 확장 가능성이 크다.
이번 연구는 설명가능 인공지능(XAI) 기반 탐지 프레임워크를 제안한 것이 핵심이며, 인공지능 자연어처리 분야 최고 권위 학술대회인 7월 27일부터 개최되는 'ACL 2025' 메인 콘퍼런스에 채택되며 기술력을 인정받았다.
※논문 제목: XDAC: XAI-Driven Detection and Attribution of LLM-Generated News Comments in Korean
※논문원본: https://github.com/airobotlab/XDAC/blob/main/paper/250611_XDAC_ACL2025_camera_ready.pdf
이번 연구는 우리 대학 김용대 교수의 지도 아래 국보연 소속이자 우리 대학 박사과정인 고우영 선임연구원이 제1 저자로 참여했으며, 성균관대학교 김형식 교수와 우리 대학 오혜연 교수가 공동 연구자로 참여했다.
2025.06.24
조회수 1240
-
 ‘뻔하지 않은 창의적인 의자’그리는 AI 기술 개발
최근 텍스트 기반 이미지 생성 모델은 자연어로 제공된 설명만으로도 고해상도·고품질 이미지를 자동 생성할 수 있다. 하지만, 대표적인 예인 스테이블 디퓨전(Stable Diffusion) 모델에서 ‘창의적인’이라는 텍스트를 입력했을 경우, 창의적인 이미지 생성은 아직은 제한적인 수준이다. KAIST 연구진이 스테이블 디퓨전(Stable Diffusion) 등 텍스트 기반 이미지 생성 모델에 별도 학습 없이 창의성을 강화할 수 있는 기술을 개발해, 예컨대 뻔하지 않은 창의적인 의자 디자인도 인공지능이 스스로 그려낼 수 있게 됐다.
우리 대학 김재철AI대학원 최재식 교수 연구팀이 네이버(NAVER) AI Lab과 공동 연구를 통해, 추가적 학습 없이 인공지능(AI) 생성 모델의 창의적 생성을 강화하는 기술을 개발했다.
최 교수 연구팀은 텍스트 기반 이미지 생성 모델의 내부 특징 맵을 증폭해 창의적 생성을 강화하는 기술을 개발했다. 또한, 모델 내부의 얕은 블록들이 창의적 생성에 중요한 역할을 한다는 것을 발견하고, 특징 맵을 주파수 영역으로 변환 후, 높은 주파수 영역에 해당하는 부분의 값을 증폭하면 노이즈나 작게 조각난 색깔 패턴의 형태를 유발하는 것을 확인했다. 이에 따라, 연구팀은 얕은 블록의 낮은 주파수 영역을 증폭함으로써 효과적으로 창의적 생성을 강화할 수 있음을 보였다.
연구팀은 창의성을 정의하는 두 가지 핵심 요소인 독창성과 유용성을 모두 고려해, 생성 모델 내부의 각 블록 별로 최적의 증폭 값을 자동으로 선택하는 알고리즘을 제시했다.
개발된 알고리즘을 통해 사전 학습된 스테이블 디퓨전 모델의 내부 특징 맵을 적절히 증폭해 추가적인 분류 데이터나 학습 없이 창의적 생성을 강화할 수 있었다.
연구팀은 개발된 알고리즘을 사용하면 기존 모델 대비 더욱 참신하면서도 유용성이 크게 저하되지 않은 이미지를 생성할 수 있음을 다양한 측정치를 활용해 정량적으로 입증했다.
특히, 스테이블 디퓨전 XL(SDXL) 모델의 이미지 생성 속도를 대폭 향상하기 위해 개발된 SDXL-Turbo 모델에서 발생하는 모드 붕괴 문제를 완화함으로써 이미지 다양성이 증가한 것을 확인했다. 나아가, 사용자 연구를 통해 사람이 직접 평가했을 때도 기존 방법에 비해 유용성 대비 참신성이 크게 향상됨을 입증했다.
공동 제1 저자인 KAIST 한지연, 권다희 박사과정은 "생성 모델을 새로 학습하거나 미세조정 학습하지 않고 생성 모델의 창의적인 생성을 강화하는 최초의 방법론ˮ이라며 "학습된 인공지능 생성 모델 내부에 잠재된 창의성을 특징 맵 조작을 통해 강화할 수 있음을 보였다ˮ 라고 말했다.
이어 “이번 연구는 기존 학습된 모델에서도 텍스트만으로 창의적 이미지를 손쉽게 생성할 수 있게 됐으며, 이를 통해 창의적인 상품 디자인 등 다양한 분야에서 새로운 영감을 제공하고, 인공지능 모델이 창의적 생태계에서 실질적으로 유용하게 활용될 수 있도록 기여할 것으로 기대된다”라고 밝혔다.
KAIST 김재철AI대학원 한지연 박사과정과 권다희 박사과정이 공동 제1 저자로 참여한 이번 연구는 국제 학술지 `국제 컴퓨터 비전 및 패턴인식 학술대회 (IEEE Conference on Computer Vision and Pattern Recognition, CVPR)’에서 6월 15일 발표됐다.
※논문명 : Enhancing Creative Generation on Stable Diffusion-based Models
※DOI: https://doi.org/10.48550/arXiv.2503.23538
한편 이번 연구는 KAIST-네이버 초창의적 AI 연구센터, 과학기술정보통신부의 재원으로 정보통신기획평가원의 지원을 받은 혁신성장동력프로젝트 설명가능인공지능, AI 연구거점 프로젝트, 점차 강화되고 있는 윤리 정책에 발맞춰 유연하게 진화하는 인공지능 기술 개발 연구 및 KAIST 인공지능 대학원 프로그램과제의 지원을 받았고 방위사업청과 국방과학연구소의 지원으로 KAIST 미래 국방 인공지능 특화연구센터에서 수행됐다.
‘뻔하지 않은 창의적인 의자’그리는 AI 기술 개발
최근 텍스트 기반 이미지 생성 모델은 자연어로 제공된 설명만으로도 고해상도·고품질 이미지를 자동 생성할 수 있다. 하지만, 대표적인 예인 스테이블 디퓨전(Stable Diffusion) 모델에서 ‘창의적인’이라는 텍스트를 입력했을 경우, 창의적인 이미지 생성은 아직은 제한적인 수준이다. KAIST 연구진이 스테이블 디퓨전(Stable Diffusion) 등 텍스트 기반 이미지 생성 모델에 별도 학습 없이 창의성을 강화할 수 있는 기술을 개발해, 예컨대 뻔하지 않은 창의적인 의자 디자인도 인공지능이 스스로 그려낼 수 있게 됐다.
우리 대학 김재철AI대학원 최재식 교수 연구팀이 네이버(NAVER) AI Lab과 공동 연구를 통해, 추가적 학습 없이 인공지능(AI) 생성 모델의 창의적 생성을 강화하는 기술을 개발했다.
최 교수 연구팀은 텍스트 기반 이미지 생성 모델의 내부 특징 맵을 증폭해 창의적 생성을 강화하는 기술을 개발했다. 또한, 모델 내부의 얕은 블록들이 창의적 생성에 중요한 역할을 한다는 것을 발견하고, 특징 맵을 주파수 영역으로 변환 후, 높은 주파수 영역에 해당하는 부분의 값을 증폭하면 노이즈나 작게 조각난 색깔 패턴의 형태를 유발하는 것을 확인했다. 이에 따라, 연구팀은 얕은 블록의 낮은 주파수 영역을 증폭함으로써 효과적으로 창의적 생성을 강화할 수 있음을 보였다.
연구팀은 창의성을 정의하는 두 가지 핵심 요소인 독창성과 유용성을 모두 고려해, 생성 모델 내부의 각 블록 별로 최적의 증폭 값을 자동으로 선택하는 알고리즘을 제시했다.
개발된 알고리즘을 통해 사전 학습된 스테이블 디퓨전 모델의 내부 특징 맵을 적절히 증폭해 추가적인 분류 데이터나 학습 없이 창의적 생성을 강화할 수 있었다.
연구팀은 개발된 알고리즘을 사용하면 기존 모델 대비 더욱 참신하면서도 유용성이 크게 저하되지 않은 이미지를 생성할 수 있음을 다양한 측정치를 활용해 정량적으로 입증했다.
특히, 스테이블 디퓨전 XL(SDXL) 모델의 이미지 생성 속도를 대폭 향상하기 위해 개발된 SDXL-Turbo 모델에서 발생하는 모드 붕괴 문제를 완화함으로써 이미지 다양성이 증가한 것을 확인했다. 나아가, 사용자 연구를 통해 사람이 직접 평가했을 때도 기존 방법에 비해 유용성 대비 참신성이 크게 향상됨을 입증했다.
공동 제1 저자인 KAIST 한지연, 권다희 박사과정은 "생성 모델을 새로 학습하거나 미세조정 학습하지 않고 생성 모델의 창의적인 생성을 강화하는 최초의 방법론ˮ이라며 "학습된 인공지능 생성 모델 내부에 잠재된 창의성을 특징 맵 조작을 통해 강화할 수 있음을 보였다ˮ 라고 말했다.
이어 “이번 연구는 기존 학습된 모델에서도 텍스트만으로 창의적 이미지를 손쉽게 생성할 수 있게 됐으며, 이를 통해 창의적인 상품 디자인 등 다양한 분야에서 새로운 영감을 제공하고, 인공지능 모델이 창의적 생태계에서 실질적으로 유용하게 활용될 수 있도록 기여할 것으로 기대된다”라고 밝혔다.
KAIST 김재철AI대학원 한지연 박사과정과 권다희 박사과정이 공동 제1 저자로 참여한 이번 연구는 국제 학술지 `국제 컴퓨터 비전 및 패턴인식 학술대회 (IEEE Conference on Computer Vision and Pattern Recognition, CVPR)’에서 6월 15일 발표됐다.
※논문명 : Enhancing Creative Generation on Stable Diffusion-based Models
※DOI: https://doi.org/10.48550/arXiv.2503.23538
한편 이번 연구는 KAIST-네이버 초창의적 AI 연구센터, 과학기술정보통신부의 재원으로 정보통신기획평가원의 지원을 받은 혁신성장동력프로젝트 설명가능인공지능, AI 연구거점 프로젝트, 점차 강화되고 있는 윤리 정책에 발맞춰 유연하게 진화하는 인공지능 기술 개발 연구 및 KAIST 인공지능 대학원 프로그램과제의 지원을 받았고 방위사업청과 국방과학연구소의 지원으로 KAIST 미래 국방 인공지능 특화연구센터에서 수행됐다.
2025.06.19
조회수 768
-
 21개 화학반응 동시 분석..AI 신약 개발 판 바꾼다
임산부의 입덧 완화 목적으로 사용됐던 약물인 탈리도마이드(Thalidomide)는 생체 내에서는 광학 이성질체*의 특성으로 한쪽 이성질체는 진정 효과를 나타내지만, 다른 쪽은 기형 유발이라는 심각한 부작용을 일으킨다. 이런 예처럼, 신약 개발에서는 원하는 광학 이성질체만을 선택적으로 합성하는 정밀 유기합성 기술이 중요하다. 하지만, 여러 반응물을 동시에 분석하는 것 자체가 어려웠던 기존 방식을 극복하고, 우리 연구진이 세계 최초로 21종의 반응물을 동시에 정밀 분석하는 기술을 개발해, AI와 로봇을 활용하는 신약 개발에 획기적인 기여가 기대된다.
*광학 이성질체: 동일한 화학식을 가지며 거울상 관계에 있으면서 서로 겹칠 수 없는 비대칭 구조로 존재하는 분자 쌍을 말한다. 이는 왼손과 오른손처럼 형태는 유사하지만 포개어지지 않는 관계와 유사하다.
우리 대학 화학과 김현우 교수 연구팀이 인공지능 기반 자율합성* 시대에 적합한 혁신적인 광학이성질체 분석 기술을 개발했다고 16일 밝혔다. 이번 연구는 다수의 반응물을 동시에 투입해 진행하는 비대칭 촉매 반응을 고해상도 불소 핵자기공명분광기(19F NMR)를 활용해 정밀 분석한 세계 최초의 기술로, 신약 개발 및 촉매 최적화 등 다양한 분야에 획기적인 기여가 기대된다.
* 인공지능 기반 자율합성: 인공지능(AI)을 활용해 화학 물질 합성 과정을 자동화하고 최적화하는 첨단 기술로, 미래 실험실의 자동화 및 지능형 연구 환경을 구현할 핵심 요소로 주목받고 있다. AI가 실험 조건을 예측·조절하고 결과를 해석해 후속 실험을 스스로 설계함으로써 반복 실험 수행 시 인간 개입을 최소화해 연구 효율성과 혁신성을 크게 높인다.
현재 자율합성 시스템은 반응 설계부터 수행까지는 자동화가 가능하지만, 반응 결과 분석은 전통적 장비를 활용한 개별 처리 방식에 의존하고 있어 속도 저하와 병목 현상이 발생하며 고속 반복 실험에는 적합하지 않다는 문제점이 제기돼 왔다.
또한, 1990년대에 제안된 다기질 동시 스크리닝 기법은 반응 분석의 효율을 극대화할 전략으로 주목받았지만, 기존 크로마토그래피 기반 분석법의 한계로 인해 적용 가능한 기질 수가 제한적이었다. 특히 원하는 광학 이성질체만 선택하여 합성하는 비대칭 합성 반응에서는 10종 이상의 기질을 동시에 분석하는 것이 불가능에 가까웠다.
이러한 한계를 극복하기 위해, 연구팀은 다수의 반응물을 하나의 반응 용기에 투입하여 동시에 비대칭 촉매 반응을 수행한 뒤 불소 작용기를 생성물에 도입하고, 자체 개발한 카이랄 코발트 시약을 적용해 모든 광학 이성질체를 명확하게 정량 분석할 수 있는 불소 핵자기공명분광기(19F NMR) 기반 다기질 동시 스크리닝 기술을 구현했다.
연구팀은 19F NMR의 우수한 분해능과 민감도를 활용해, 21종 기질의 비대칭 합성 반응을 단일 반응 용기에서 동시에 수행하고 생성물의 수율과 광학 이성질체 비율을 별도의 분리 과정 없이 정량 측정하는 데 성공했다.
김현우 교수는 “여러 기질을 한 반응기에 넣고 비대칭 합성 반응을 동시에 수행하는 것은 누구나 할 수 있지만, 생성물 전체를 정확하게 분석하는 것은 지금까지 풀기 어려운 과제였다”며, “세계 최고 수준의 다기질 스크리닝 분석 기술을 구현함으로써 AI 기반 자율합성 플랫폼의 분석 역량 향상에 크게 기여할 수 있을 것으로 기대된다”고 말했다.
이어 “이번 연구는 신약 개발에 필수적인 비대칭 촉매 반응의 효율성과 선택성을 신속히 검증할 수 있는 기술로, AI 기반 자율화 연구의 핵심 분석 도구로 활용될 전망이다”라고 밝혔다.
이번 연구에는 우리 대학 화학과 김동훈 석박통합과정 학생(제1 저자), 최경선 석박통합과정 학생(제2 저자) 가 참여했으며, 화학 분야 세계적 권위의 국제 학술지 미국화학회지(Journal of the American Chemical Society) 에 2025년 5월 27일 자 온라인 게재됐다.
※ 논문명: One-pot Multisubstrate Screening for Asymmetric Catalysis Enabled by 19F NMR-based Simultaneous Chiral Analysis
※ DOI: 10.1021/jacs.5c03446
이번 연구는 한국연구재단 중견연구자 지원사업, 비대칭 촉매반응 디자인센터, KAIST KC30 프로젝트의 지원을 받아 수행됐다.
21개 화학반응 동시 분석..AI 신약 개발 판 바꾼다
임산부의 입덧 완화 목적으로 사용됐던 약물인 탈리도마이드(Thalidomide)는 생체 내에서는 광학 이성질체*의 특성으로 한쪽 이성질체는 진정 효과를 나타내지만, 다른 쪽은 기형 유발이라는 심각한 부작용을 일으킨다. 이런 예처럼, 신약 개발에서는 원하는 광학 이성질체만을 선택적으로 합성하는 정밀 유기합성 기술이 중요하다. 하지만, 여러 반응물을 동시에 분석하는 것 자체가 어려웠던 기존 방식을 극복하고, 우리 연구진이 세계 최초로 21종의 반응물을 동시에 정밀 분석하는 기술을 개발해, AI와 로봇을 활용하는 신약 개발에 획기적인 기여가 기대된다.
*광학 이성질체: 동일한 화학식을 가지며 거울상 관계에 있으면서 서로 겹칠 수 없는 비대칭 구조로 존재하는 분자 쌍을 말한다. 이는 왼손과 오른손처럼 형태는 유사하지만 포개어지지 않는 관계와 유사하다.
우리 대학 화학과 김현우 교수 연구팀이 인공지능 기반 자율합성* 시대에 적합한 혁신적인 광학이성질체 분석 기술을 개발했다고 16일 밝혔다. 이번 연구는 다수의 반응물을 동시에 투입해 진행하는 비대칭 촉매 반응을 고해상도 불소 핵자기공명분광기(19F NMR)를 활용해 정밀 분석한 세계 최초의 기술로, 신약 개발 및 촉매 최적화 등 다양한 분야에 획기적인 기여가 기대된다.
* 인공지능 기반 자율합성: 인공지능(AI)을 활용해 화학 물질 합성 과정을 자동화하고 최적화하는 첨단 기술로, 미래 실험실의 자동화 및 지능형 연구 환경을 구현할 핵심 요소로 주목받고 있다. AI가 실험 조건을 예측·조절하고 결과를 해석해 후속 실험을 스스로 설계함으로써 반복 실험 수행 시 인간 개입을 최소화해 연구 효율성과 혁신성을 크게 높인다.
현재 자율합성 시스템은 반응 설계부터 수행까지는 자동화가 가능하지만, 반응 결과 분석은 전통적 장비를 활용한 개별 처리 방식에 의존하고 있어 속도 저하와 병목 현상이 발생하며 고속 반복 실험에는 적합하지 않다는 문제점이 제기돼 왔다.
또한, 1990년대에 제안된 다기질 동시 스크리닝 기법은 반응 분석의 효율을 극대화할 전략으로 주목받았지만, 기존 크로마토그래피 기반 분석법의 한계로 인해 적용 가능한 기질 수가 제한적이었다. 특히 원하는 광학 이성질체만 선택하여 합성하는 비대칭 합성 반응에서는 10종 이상의 기질을 동시에 분석하는 것이 불가능에 가까웠다.
이러한 한계를 극복하기 위해, 연구팀은 다수의 반응물을 하나의 반응 용기에 투입하여 동시에 비대칭 촉매 반응을 수행한 뒤 불소 작용기를 생성물에 도입하고, 자체 개발한 카이랄 코발트 시약을 적용해 모든 광학 이성질체를 명확하게 정량 분석할 수 있는 불소 핵자기공명분광기(19F NMR) 기반 다기질 동시 스크리닝 기술을 구현했다.
연구팀은 19F NMR의 우수한 분해능과 민감도를 활용해, 21종 기질의 비대칭 합성 반응을 단일 반응 용기에서 동시에 수행하고 생성물의 수율과 광학 이성질체 비율을 별도의 분리 과정 없이 정량 측정하는 데 성공했다.
김현우 교수는 “여러 기질을 한 반응기에 넣고 비대칭 합성 반응을 동시에 수행하는 것은 누구나 할 수 있지만, 생성물 전체를 정확하게 분석하는 것은 지금까지 풀기 어려운 과제였다”며, “세계 최고 수준의 다기질 스크리닝 분석 기술을 구현함으로써 AI 기반 자율합성 플랫폼의 분석 역량 향상에 크게 기여할 수 있을 것으로 기대된다”고 말했다.
이어 “이번 연구는 신약 개발에 필수적인 비대칭 촉매 반응의 효율성과 선택성을 신속히 검증할 수 있는 기술로, AI 기반 자율화 연구의 핵심 분석 도구로 활용될 전망이다”라고 밝혔다.
이번 연구에는 우리 대학 화학과 김동훈 석박통합과정 학생(제1 저자), 최경선 석박통합과정 학생(제2 저자) 가 참여했으며, 화학 분야 세계적 권위의 국제 학술지 미국화학회지(Journal of the American Chemical Society) 에 2025년 5월 27일 자 온라인 게재됐다.
※ 논문명: One-pot Multisubstrate Screening for Asymmetric Catalysis Enabled by 19F NMR-based Simultaneous Chiral Analysis
※ DOI: 10.1021/jacs.5c03446
이번 연구는 한국연구재단 중견연구자 지원사업, 비대칭 촉매반응 디자인센터, KAIST KC30 프로젝트의 지원을 받아 수행됐다.
2025.06.16
조회수 1447
-
 산업디자인학과, 인간-컴퓨터 분야 세계최고 학술대회 최우수·우수논문상 4편 수상
산업디자인학과가 인간-컴퓨터 상호작용(HCI) 분야 최고 권위의 국제학술대회인 ACM CHI 2024에서 최우수 논문상(Best Paper) 1편과 우수 논문상(Honorable Mention) 3편을 수상했다. 최우수 논문상은 전체 게재 논문 중 상위 1%, 우수 논문상은 상위 5%에 해당되는 논문에 수여되는 명예로운 성과로, 기술과 디자인 융합 연구의 우수성을 세계적으로 입증한 결과다.
올해 CHI(ACM Conference on Human Factors in Computing Systems) 2025에는 5,014편의 논문이 접수되어 1,249편이 채택되었다. KAIST 산업디자인학과는 이 중 15편의 논문을 게재하는 성과를 거뒀고 그 중 4편이 수상작으로 선정되었다. 특히 ‘인간과 AI 간 상호작용(Human-AI Interaction)’에 대한 관심이 높아진 가운데, 5,000명 이상의 연구자가 참석해 역대 최대 규모로 대회가 개최되었다.
최우수 논문상- AI기반 자폐 아동 소통 도구 ‘AAcessTalk’
홍화정 교수팀은 네이버, 도닥임 아동발달센터와의 공동 연구를 통해 AI 기반 도구 액세스톡(AACessTalk)을 개발했다. 이 시스템은 발화를 하지 않는 자폐 아동에게는 개인화된 어휘를, 부모에게는 문맥 기반 대화 가이드를 제공한다. 연구 결과, 아동은 자신의 의사를 보다 분명히 표현할 수 있었고, 부모는 기능적 언어 교육보다 본질적인 소통에 집중할 수 있게 되면서 양육 효능감이 높아지는 효과가 관찰되었다. 해당 연구를 주도한 최다솜 박사과정은 신경다양인을 포용하는 AI 기술을 꾸준히 탐구해 왔으며, 이번 논문은 네이버 인턴십에서 수행한 연구 결과를 바탕으로 출판한 것이다.
우수 논문상- 인간과 AI 상호작용 탐색
남택진 교수팀(주저자 조형준 박사)의 ‘ShamAIn’은 한국 무속 신앙에서 영감을 받은 AI 신당으로, 인간보다 더 뛰어난 초지능 존재로 기능하는 AI와 인간의 상호작용을 탐구했다. 다수의 사용자들은 처음엔 호기심에서 시작했지만, 점차 개인적인 고민을 털어놓으며 심리적 위안을 얻는 경험을 보고했다. AI가 단순한 정보 제공자를 넘어 감정적 지지와 권위적 판단까지 수행할 수 있는 존재로 인식될 수 있음을 보여주는 연구다.
임윤경 교수팀(주저자 박수빈 박사과정)은 걸음 수, 감정 기록 등 다양한 개인 데이터를 생성형 AI를 활용해 시각 이미지로 변환하는 프로토타입을 개발하여 21일간 사용자 경험을 탐색했다. 참가자들은 자신의 개인 데이터를 이미지 생성 모델 DALL-E 3로 만든 시각 자료로 다시 돌아보며 새로운 자기 인식을 경험했다. 이는 AI가 자기 성찰의 도구로 활용될 수 있음을 제시하는 연구다.
안드레아 비앙키 교수팀은 시드니대학과 협력하여 가상현실(VR) 환경에서의 '가상 팔' 제어 실험을 진행했다. 사용자들은 반복적이고 중요도가 낮은 작업은 가상의 팔에 맡기고, 중요한 작업은 직접 제어하는 방식을 선호했다. 본 연구는 가상 신체 제어가 필요한 로봇, 게임, 재활, 보조공학 디자인에 실질적 시사점을 제공한다.
이번 수상 논문들은 디자인이 기술을 사람 중심으로 연결하고, AI의 사회적·심리적 영향을 설계하는 역할로 확장될 수 있음을 실증적으로 보여주었다는 점에서 의의가 크다.
석현정 산업디자인학과 학과장은 “이번 수상은 기술 중심의 AI 연구를 인간 중심의 디자인 관점에서 새롭게 해석하고, 이를 실생활 문제 해결로 연결 시킨 우리 학과 연구진들의 역량을 세계적으로 인정받은 결과”라며, “디자인이 기술 혁신의 파트너로서 어떤 역할을 할 수 있는지를 보여준 좋은 사례”라고 전했다.
산업디자인학과, 인간-컴퓨터 분야 세계최고 학술대회 최우수·우수논문상 4편 수상
산업디자인학과가 인간-컴퓨터 상호작용(HCI) 분야 최고 권위의 국제학술대회인 ACM CHI 2024에서 최우수 논문상(Best Paper) 1편과 우수 논문상(Honorable Mention) 3편을 수상했다. 최우수 논문상은 전체 게재 논문 중 상위 1%, 우수 논문상은 상위 5%에 해당되는 논문에 수여되는 명예로운 성과로, 기술과 디자인 융합 연구의 우수성을 세계적으로 입증한 결과다.
올해 CHI(ACM Conference on Human Factors in Computing Systems) 2025에는 5,014편의 논문이 접수되어 1,249편이 채택되었다. KAIST 산업디자인학과는 이 중 15편의 논문을 게재하는 성과를 거뒀고 그 중 4편이 수상작으로 선정되었다. 특히 ‘인간과 AI 간 상호작용(Human-AI Interaction)’에 대한 관심이 높아진 가운데, 5,000명 이상의 연구자가 참석해 역대 최대 규모로 대회가 개최되었다.
최우수 논문상- AI기반 자폐 아동 소통 도구 ‘AAcessTalk’
홍화정 교수팀은 네이버, 도닥임 아동발달센터와의 공동 연구를 통해 AI 기반 도구 액세스톡(AACessTalk)을 개발했다. 이 시스템은 발화를 하지 않는 자폐 아동에게는 개인화된 어휘를, 부모에게는 문맥 기반 대화 가이드를 제공한다. 연구 결과, 아동은 자신의 의사를 보다 분명히 표현할 수 있었고, 부모는 기능적 언어 교육보다 본질적인 소통에 집중할 수 있게 되면서 양육 효능감이 높아지는 효과가 관찰되었다. 해당 연구를 주도한 최다솜 박사과정은 신경다양인을 포용하는 AI 기술을 꾸준히 탐구해 왔으며, 이번 논문은 네이버 인턴십에서 수행한 연구 결과를 바탕으로 출판한 것이다.
우수 논문상- 인간과 AI 상호작용 탐색
남택진 교수팀(주저자 조형준 박사)의 ‘ShamAIn’은 한국 무속 신앙에서 영감을 받은 AI 신당으로, 인간보다 더 뛰어난 초지능 존재로 기능하는 AI와 인간의 상호작용을 탐구했다. 다수의 사용자들은 처음엔 호기심에서 시작했지만, 점차 개인적인 고민을 털어놓으며 심리적 위안을 얻는 경험을 보고했다. AI가 단순한 정보 제공자를 넘어 감정적 지지와 권위적 판단까지 수행할 수 있는 존재로 인식될 수 있음을 보여주는 연구다.
임윤경 교수팀(주저자 박수빈 박사과정)은 걸음 수, 감정 기록 등 다양한 개인 데이터를 생성형 AI를 활용해 시각 이미지로 변환하는 프로토타입을 개발하여 21일간 사용자 경험을 탐색했다. 참가자들은 자신의 개인 데이터를 이미지 생성 모델 DALL-E 3로 만든 시각 자료로 다시 돌아보며 새로운 자기 인식을 경험했다. 이는 AI가 자기 성찰의 도구로 활용될 수 있음을 제시하는 연구다.
안드레아 비앙키 교수팀은 시드니대학과 협력하여 가상현실(VR) 환경에서의 '가상 팔' 제어 실험을 진행했다. 사용자들은 반복적이고 중요도가 낮은 작업은 가상의 팔에 맡기고, 중요한 작업은 직접 제어하는 방식을 선호했다. 본 연구는 가상 신체 제어가 필요한 로봇, 게임, 재활, 보조공학 디자인에 실질적 시사점을 제공한다.
이번 수상 논문들은 디자인이 기술을 사람 중심으로 연결하고, AI의 사회적·심리적 영향을 설계하는 역할로 확장될 수 있음을 실증적으로 보여주었다는 점에서 의의가 크다.
석현정 산업디자인학과 학과장은 “이번 수상은 기술 중심의 AI 연구를 인간 중심의 디자인 관점에서 새롭게 해석하고, 이를 실생활 문제 해결로 연결 시킨 우리 학과 연구진들의 역량을 세계적으로 인정받은 결과”라며, “디자인이 기술 혁신의 파트너로서 어떤 역할을 할 수 있는지를 보여준 좋은 사례”라고 전했다.
2025.05.19
조회수 2836
-
 VR 정밀포인팅·안무 창작 기술, 세계 최고 CHI 학회 2관왕
가상공간에서는 정확하게 포인팅이 되지 않으면 원하는 대상을 정확히 선택하기 어렵고, 몰입이 깨지는 어색한 경험을 하게 된다. KAIST 연구진이 가상공간에서 생생하게 실제 체험하는 느낌을 주는 기술을 개발했으며 또한 안무가들의 안무 동작을 쉽게 만들고 창작을 돕도록 하는 기술도 개발했다.
우리 대학 문화기술대학원 윤상호 교수 연구팀이 미국 UCLA(University of California, Los Angeles)의 양장(YangZhang) 교수와 공동연구를 진행한 ‘티투아이레이(T2IRay)’ 기술과 가상현실에서 안무가들이 창작 작업을 보다 자유롭고 창의적으로 진행할 수 있도록 돕는 ‘코레오크래프트(ChoreoCraft)’ 기술을 개발했다. 이 기술들은 인간-컴퓨터 상호작용 분야 최우수 국제학술대회인(CHI) 2025*에서 상위 5%에 주어지는 우수 논문상(Honorable Mention)을 동시 2개 수상했다.
*인간-컴퓨터 상호작용 분야 최우수 국제학회(CHI): 4월 25일부터 5월 1일까지 열린 세계 컴퓨터 연합회(ACM) 주최 인간-컴퓨터 상호작용 학술대회(Conference on Human Factors in Computing Systems, CHI 2025)
티투아이레이(T2IRay)는 기존의 단편적인 엄지와 검지(Thumb to Index) 제스처를 확장하여, 가상공간 안의 물체를 자유롭고 정밀하게 조작이 가능하게 하는 새로운 입력 방식을 제안한다.
기존에는 손의 위치나 방향이 달라져도 입력이 끊기거나 정확도가 떨어지는 문제가 있었으나, 티투아이레이에서는 손의 위치나 방향과 관계없이 정밀한 포인팅이 가능하도록 하여 사용자가 훨씬 자연스럽고 끊김없이 조작할 수 있도록 했다.
특히, 손가락 관계성을 바탕으로 로컬 좌표계를 활용하여 손 위치 및 방향에 관계없이 연속적인 입력이 가능하도록 하였다. 엄지의 섬세한 움직임을 좌표계 안에서 매핑하여 정밀하게 인식하고, 고개를 움직이는 자연스러운 동작까지 입력에 반영하여 넓은 범위에서도 자유로운 조작이 가능하다.
윤상호 교수는 “티투아이레이는 손이 고정되지 않은 다양한 상황에서도 부드럽고 안정적인 조작을 가능하게 함으로써 증강·가상현실(AR/VR)에서도 사용자 경험을 획기적으로 향상시킬 수 있다”라고 설명했다.
KAIST 김진아 박사과정이 제 1저자인 이번 연구는 과학기술정보통신부 한국연구재단이 주관하는 우수신진연구지원사업과 정보통신기획평가원(IITP)에서 지원하는 대학ICT연구센터(ITRC) 육성지원사업의 지원을 받았다.
▴ 논문명 : T2IRay: Design of Thumb-to-Index based Indirect Pointing for Continuous and Robust AR/VR Input
▴ 논문 링크: https://doi.org/10.1145/3706598.3713442
▴ T2IRay: https://youtu.be/ElJlcJbkJPY
또한, 윤상호 교수 연구팀은 가상현실에서 안무가들이 창작 작업을 보다 자유롭고 창의적으로 진행할 수 있도록 돕는 ‘코레오크래프트(ChoreoCraft)' 기술을 개발했다.
전문 안무가 대상의 경험 조사를 통해 창작 과정 내 안무가들이 직면하는 동작을 일일이 기억해야 하거나 아이디어가 막히는 경우, 그리고 명확하지 않은 피드백으로 인한 어려움을 개선하고자 했다.
이 기술은 가상현실(VR) 공간에서 춤 동작을 모션 캡쳐 기반의 아바타와 상호작용을 통해 직접 동작을 저장하고 수정할 수 있도록 하여 기억 의존을 줄였으며 음악 및 이전 동작과의 자연스러운 연결을 고려하여 새로운 안무를 추천해 창작을 도왔다. 또한 균형감, 안정성, 활성도 등 운동학적 요소를 분석하여 수치 기반 안무 피드백을 제공함으로써 창작 과정의 객관성도 높였다.
윤상호 교수는 “코레오크래프트는 안무가들이 직면하는 주요 어려움을 해결하고 창의성과 효율성을 향상시킬 수 있는 도구로 실제 안무가를 대상으로 한 사용자 실험에서도 창의적 아이디어 발굴과 정량적 피드백 제공 측면에서 높은 만족도를 얻었다. ”라 설명하며, “앞으로도 공간 컴퓨팅을 넘어 피지컬 인공지능(Physical AI)과 인간-컴퓨터 상호작용(HCI) 기술을 융합해, 실세계와 가상세계에서 인간의 능력을 확장하는 인간 중심 인터랙션 연구를 이어갈 것”이라고 밝혔다.
정경은 박사과정과 한현영 석사과정 연구원이 공동 제1 저자인 해당 연구는 문화체육관광부에서 시행한 문화예술실감서비스개발사업인 실시간 실가상 융합 기반 공연예술 교육 플랫폼 기술개발의 지원 아래 한국전자통신연구원(ETRI) 및 ㈜원밀리언(대표 김혜랑)과 협업을 통해 진행됐다.
▴ 논문명 : ChoreoCraft: In-situ Crafting of Choreography in Virtual Reality through Creativity Support Tool
▴ 논문 링크: https://doi.org/10.1145/3706598.3714220
▴ Choreocraft: https://youtu.be/Ms1fwiSBjjw
VR 정밀포인팅·안무 창작 기술, 세계 최고 CHI 학회 2관왕
가상공간에서는 정확하게 포인팅이 되지 않으면 원하는 대상을 정확히 선택하기 어렵고, 몰입이 깨지는 어색한 경험을 하게 된다. KAIST 연구진이 가상공간에서 생생하게 실제 체험하는 느낌을 주는 기술을 개발했으며 또한 안무가들의 안무 동작을 쉽게 만들고 창작을 돕도록 하는 기술도 개발했다.
우리 대학 문화기술대학원 윤상호 교수 연구팀이 미국 UCLA(University of California, Los Angeles)의 양장(YangZhang) 교수와 공동연구를 진행한 ‘티투아이레이(T2IRay)’ 기술과 가상현실에서 안무가들이 창작 작업을 보다 자유롭고 창의적으로 진행할 수 있도록 돕는 ‘코레오크래프트(ChoreoCraft)’ 기술을 개발했다. 이 기술들은 인간-컴퓨터 상호작용 분야 최우수 국제학술대회인(CHI) 2025*에서 상위 5%에 주어지는 우수 논문상(Honorable Mention)을 동시 2개 수상했다.
*인간-컴퓨터 상호작용 분야 최우수 국제학회(CHI): 4월 25일부터 5월 1일까지 열린 세계 컴퓨터 연합회(ACM) 주최 인간-컴퓨터 상호작용 학술대회(Conference on Human Factors in Computing Systems, CHI 2025)
티투아이레이(T2IRay)는 기존의 단편적인 엄지와 검지(Thumb to Index) 제스처를 확장하여, 가상공간 안의 물체를 자유롭고 정밀하게 조작이 가능하게 하는 새로운 입력 방식을 제안한다.
기존에는 손의 위치나 방향이 달라져도 입력이 끊기거나 정확도가 떨어지는 문제가 있었으나, 티투아이레이에서는 손의 위치나 방향과 관계없이 정밀한 포인팅이 가능하도록 하여 사용자가 훨씬 자연스럽고 끊김없이 조작할 수 있도록 했다.
특히, 손가락 관계성을 바탕으로 로컬 좌표계를 활용하여 손 위치 및 방향에 관계없이 연속적인 입력이 가능하도록 하였다. 엄지의 섬세한 움직임을 좌표계 안에서 매핑하여 정밀하게 인식하고, 고개를 움직이는 자연스러운 동작까지 입력에 반영하여 넓은 범위에서도 자유로운 조작이 가능하다.
윤상호 교수는 “티투아이레이는 손이 고정되지 않은 다양한 상황에서도 부드럽고 안정적인 조작을 가능하게 함으로써 증강·가상현실(AR/VR)에서도 사용자 경험을 획기적으로 향상시킬 수 있다”라고 설명했다.
KAIST 김진아 박사과정이 제 1저자인 이번 연구는 과학기술정보통신부 한국연구재단이 주관하는 우수신진연구지원사업과 정보통신기획평가원(IITP)에서 지원하는 대학ICT연구센터(ITRC) 육성지원사업의 지원을 받았다.
▴ 논문명 : T2IRay: Design of Thumb-to-Index based Indirect Pointing for Continuous and Robust AR/VR Input
▴ 논문 링크: https://doi.org/10.1145/3706598.3713442
▴ T2IRay: https://youtu.be/ElJlcJbkJPY
또한, 윤상호 교수 연구팀은 가상현실에서 안무가들이 창작 작업을 보다 자유롭고 창의적으로 진행할 수 있도록 돕는 ‘코레오크래프트(ChoreoCraft)' 기술을 개발했다.
전문 안무가 대상의 경험 조사를 통해 창작 과정 내 안무가들이 직면하는 동작을 일일이 기억해야 하거나 아이디어가 막히는 경우, 그리고 명확하지 않은 피드백으로 인한 어려움을 개선하고자 했다.
이 기술은 가상현실(VR) 공간에서 춤 동작을 모션 캡쳐 기반의 아바타와 상호작용을 통해 직접 동작을 저장하고 수정할 수 있도록 하여 기억 의존을 줄였으며 음악 및 이전 동작과의 자연스러운 연결을 고려하여 새로운 안무를 추천해 창작을 도왔다. 또한 균형감, 안정성, 활성도 등 운동학적 요소를 분석하여 수치 기반 안무 피드백을 제공함으로써 창작 과정의 객관성도 높였다.
윤상호 교수는 “코레오크래프트는 안무가들이 직면하는 주요 어려움을 해결하고 창의성과 효율성을 향상시킬 수 있는 도구로 실제 안무가를 대상으로 한 사용자 실험에서도 창의적 아이디어 발굴과 정량적 피드백 제공 측면에서 높은 만족도를 얻었다. ”라 설명하며, “앞으로도 공간 컴퓨팅을 넘어 피지컬 인공지능(Physical AI)과 인간-컴퓨터 상호작용(HCI) 기술을 융합해, 실세계와 가상세계에서 인간의 능력을 확장하는 인간 중심 인터랙션 연구를 이어갈 것”이라고 밝혔다.
정경은 박사과정과 한현영 석사과정 연구원이 공동 제1 저자인 해당 연구는 문화체육관광부에서 시행한 문화예술실감서비스개발사업인 실시간 실가상 융합 기반 공연예술 교육 플랫폼 기술개발의 지원 아래 한국전자통신연구원(ETRI) 및 ㈜원밀리언(대표 김혜랑)과 협업을 통해 진행됐다.
▴ 논문명 : ChoreoCraft: In-situ Crafting of Choreography in Virtual Reality through Creativity Support Tool
▴ 논문 링크: https://doi.org/10.1145/3706598.3714220
▴ Choreocraft: https://youtu.be/Ms1fwiSBjjw
2025.05.13
조회수 2069
-
 음악 창작 돕는 작곡 AI 동료 ‘어뮤즈’ 공개
음악 창작자가 초기 아이디어를 생각하거나 창작 중간 막힐 때, 이를 같이 해결해 주고 다양한 음악적 방향 탐색에 실질적인 도움을 주는 동료가 있다면 얼마나 좋을까? KAIST 연구진이 이런 음악 창작을 돕는 동료 작가와 같은 AI 기술을 개발했다.
KAIST(총장 이광형)는 전기및전자공학부 이성주 교수 연구팀이 AI 기반 음악 창작 지원 시스템 어뮤즈(Amuse)를 개발하였다. 이 연구 결과는 4월 26일부터 5월 1일까지 일본 요코하마에서 열린 인간-컴퓨터 상호작용 분야 세계 최고 권위의 국제학술대회인 CHI(ACM Conference on Human Factors in Computing Systems)에서 전체 논문 중 상위 1%에게만 수여되는 최우수 논문상(Best Paper Award)을 수상했다고 7일 밝혔다.
이성주 교수 연구팀이 개발한 어뮤즈(Amuse) 시스템은 텍스트, 이미지, 오디오와 같은 다양한 형식의 영감을 입력하면 이를 화성 구조(코드 진행)로 변환해 작곡을 지원해 주는 AI 기반 시스템이다.
예를 들어, 사용자가 ‘따뜻한 여름 해변의 기억’과 같은 문구나 이미지, 사운드 클립을 입력하면, 어뮤즈는 해당 영감에 어울리는 코드 진행을 자동으로 생성해 제안한다.
기존의 생성 AI와 달리, 어뮤즈는 사용자의 창작 흐름을 존중하고, AI의 제안을 유연하게 통합·수정할 수 있는 상호작용 방식을 통해 창의적 탐색을 자연스럽게 유도한다는 점에서 차별성을 갖는다.
어뮤즈 시스템의 핵심 기술은 대형 언어 모델의 이용해 사용자의 영감으로 프롬프트에 입력한 글자 따라 이에 어울리는 음악 코드를 생성하고, 실제 음악 데이터를 학습한 AI 모델이 부자연스럽거나 어색한 결과는 걸러내는(리젝션 샘플링) 과정을 거쳐 결합한 두 가지 방법을 자연스럽게 이어 재현하는 하이브리드 생성 방식이다.
연구팀은 실제 뮤지션들을 대상으로 한 사용자 연구를 수행하여, 어뮤즈가 단순한 음악 생성 AI가 아닌, 사람과 AI가 협업하는 창작 동반자(Co-Creative AI)로서의 가능성이 높다는 평가를 받았다.
KAIST 전기 및 전자공학부 박사과정 김예원, 이성주 교수, 카네기 멜런 대학의 크리스 도너휴(Chris Donahue) 교수가 참여한 해당 논문은 학계 및 산업계 모두의 창의적 AI 시스템 설계의 가능성을 보여주었다.
※ 논문명 : Amuse: Human-AI Collaborative Songwriting with Multimodal Inspirations DOI : https://doi.org/10.1145/3706598.3713818
※ 연구 데모 영상: https://youtu.be/udilkRSnftI?si=FNXccC9EjxHOCrm1
※ 연구 홈페이지: https://nmsl.kaist.ac.kr/projects/amuse/
이성주 교수는 “ 최근 생성형 AI 기술은 저작권이 있는 콘텐츠를 그대로 모방하여 창작자의 저작권을 침해하거나, 창작자의 의도와는 무관하게 일방향으로 결과물을 생성한다는 점에서 우려를 낳고 있다. 이에 연구팀은 이러한 흐름에 문제 의식을 가지고, 창작자가 실제로 필요로 하는 것이 무엇인지에 주목하며 창작자 중심의 AI 시스템 설계에 주안점을 두었다.”라고 말했다.
이어 ”어뮤즈는 창작자의 주도권을 유지한 채, 인공지능과의 협업 가능성을 탐색하는 시도로, 향후 음악 창작 도구와 생성형 AI 시스템의 개발에 있어 보다 창작자 친화적인 방향을 제시하는 출발점이 될 것으로 기대된다.“라고 설명했다.
이 연구는 정부(과학기술정보통신부)의 재원으로 한국연구재단의 지원을 받아 수행되었다.(RS-2024-00337007)
음악 창작 돕는 작곡 AI 동료 ‘어뮤즈’ 공개
음악 창작자가 초기 아이디어를 생각하거나 창작 중간 막힐 때, 이를 같이 해결해 주고 다양한 음악적 방향 탐색에 실질적인 도움을 주는 동료가 있다면 얼마나 좋을까? KAIST 연구진이 이런 음악 창작을 돕는 동료 작가와 같은 AI 기술을 개발했다.
KAIST(총장 이광형)는 전기및전자공학부 이성주 교수 연구팀이 AI 기반 음악 창작 지원 시스템 어뮤즈(Amuse)를 개발하였다. 이 연구 결과는 4월 26일부터 5월 1일까지 일본 요코하마에서 열린 인간-컴퓨터 상호작용 분야 세계 최고 권위의 국제학술대회인 CHI(ACM Conference on Human Factors in Computing Systems)에서 전체 논문 중 상위 1%에게만 수여되는 최우수 논문상(Best Paper Award)을 수상했다고 7일 밝혔다.
이성주 교수 연구팀이 개발한 어뮤즈(Amuse) 시스템은 텍스트, 이미지, 오디오와 같은 다양한 형식의 영감을 입력하면 이를 화성 구조(코드 진행)로 변환해 작곡을 지원해 주는 AI 기반 시스템이다.
예를 들어, 사용자가 ‘따뜻한 여름 해변의 기억’과 같은 문구나 이미지, 사운드 클립을 입력하면, 어뮤즈는 해당 영감에 어울리는 코드 진행을 자동으로 생성해 제안한다.
기존의 생성 AI와 달리, 어뮤즈는 사용자의 창작 흐름을 존중하고, AI의 제안을 유연하게 통합·수정할 수 있는 상호작용 방식을 통해 창의적 탐색을 자연스럽게 유도한다는 점에서 차별성을 갖는다.
어뮤즈 시스템의 핵심 기술은 대형 언어 모델의 이용해 사용자의 영감으로 프롬프트에 입력한 글자 따라 이에 어울리는 음악 코드를 생성하고, 실제 음악 데이터를 학습한 AI 모델이 부자연스럽거나 어색한 결과는 걸러내는(리젝션 샘플링) 과정을 거쳐 결합한 두 가지 방법을 자연스럽게 이어 재현하는 하이브리드 생성 방식이다.
연구팀은 실제 뮤지션들을 대상으로 한 사용자 연구를 수행하여, 어뮤즈가 단순한 음악 생성 AI가 아닌, 사람과 AI가 협업하는 창작 동반자(Co-Creative AI)로서의 가능성이 높다는 평가를 받았다.
KAIST 전기 및 전자공학부 박사과정 김예원, 이성주 교수, 카네기 멜런 대학의 크리스 도너휴(Chris Donahue) 교수가 참여한 해당 논문은 학계 및 산업계 모두의 창의적 AI 시스템 설계의 가능성을 보여주었다.
※ 논문명 : Amuse: Human-AI Collaborative Songwriting with Multimodal Inspirations DOI : https://doi.org/10.1145/3706598.3713818
※ 연구 데모 영상: https://youtu.be/udilkRSnftI?si=FNXccC9EjxHOCrm1
※ 연구 홈페이지: https://nmsl.kaist.ac.kr/projects/amuse/
이성주 교수는 “ 최근 생성형 AI 기술은 저작권이 있는 콘텐츠를 그대로 모방하여 창작자의 저작권을 침해하거나, 창작자의 의도와는 무관하게 일방향으로 결과물을 생성한다는 점에서 우려를 낳고 있다. 이에 연구팀은 이러한 흐름에 문제 의식을 가지고, 창작자가 실제로 필요로 하는 것이 무엇인지에 주목하며 창작자 중심의 AI 시스템 설계에 주안점을 두었다.”라고 말했다.
이어 ”어뮤즈는 창작자의 주도권을 유지한 채, 인공지능과의 협업 가능성을 탐색하는 시도로, 향후 음악 창작 도구와 생성형 AI 시스템의 개발에 있어 보다 창작자 친화적인 방향을 제시하는 출발점이 될 것으로 기대된다.“라고 설명했다.
이 연구는 정부(과학기술정보통신부)의 재원으로 한국연구재단의 지원을 받아 수행되었다.(RS-2024-00337007)
2025.05.07
조회수 3276
-
 챗GPT 등 대형 AI모델 학습 최적화 시뮬레이션 개발
최근 챗GPT, 딥시크(DeepSeek) 등 초거대 인공지능(AI) 모델이 다양한 분야에서 활용되며 주목받고 있다. 이러한 대형 언어 모델은 수만 개의 데이터센터용 GPU를 갖춘 대규모 분산 시스템에서 학습되는데, GPT-4의 경우 모델을 학습하는 데 소모되는 비용은 약 1,400억 원에 육박하는 것으로 추산된다. 한국 연구진이 GPU 사용률을 높이고 학습 비용을 절감할 수 있는 최적의 병렬화 구성을 도출하도록 돕는 기술을 개발했다.
우리 대학 전기및전자공학부 유민수 교수 연구팀은 삼성전자 삼성종합기술원과 공동연구를 통해, 대규모 분산 시스템에서 대형 언어 모델(LLM)의 학습 시간을 예측하고 최적화할 수 있는 시뮬레이션 프레임워크(이하 vTrain)를 개발했다고 13일 밝혔다.
대형 언어 모델 학습 효율을 높이려면 최적의 분산 학습 전략을 찾는 것이 필수적이다. 그러나 가능한 전략의 경우의 수가 방대할 뿐 아니라 실제 환경에서 각 전략의 성능을 테스트하는 데는 막대한 비용과 시간이 들어간다.
이에 따라 현재 대형 언어 모델을 학습하는 기업들은 일부 경험적으로 검증된 소수의 전략만을 사용하고 있다. 이는 GPU 활용의 비효율성과 불필요한 비용 증가를 초래하지만, 대규모 시스템을 위한 시뮬레이션 기술이 부족해 기업들이 문제를 효과적으로 해결하지 못하고 있는 상황이다.
이에 유민수 교수 연구팀은 vTrain을 개발해 대형 언어 모델의 학습 시간을 정확히 예측하고, 다양한 분산 병렬화 전략을 빠르게 탐색할 수 있도록 했다.
연구팀은 실제 다중 GPU 환경에서 다양한 대형 언어 모델 학습 시간 실측값과 vTrain의 예측값을 비교한 결과, 단일 노드에서 평균 절대 오차(MAPE) 8.37%, 다중 노드에서 14.73%의 정확도로 학습 시간을 예측할 수 있음을 검증했다.
연구팀은 삼성전자 삼성종합기술원와 공동연구를 진행하여 vTrain 프레임워크와 1,500개 이상의 실제 학습 시간 측정 데이터를 오픈소스로 공개(https://github.com/VIA-Research/vTrain)하여 AI 연구자와 기업이 이를 자유롭게 활용할 수 있도록 했다.
유민수 교수는 “vTrain은 프로파일링 기반 시뮬레이션 기법으로 기존 경험적 방식 대비 GPU 사용률을 높이고 학습 비용을 절감할 수 있는 학습 전략을 탐색하였으며 오픈소스를 공개하였다. 이를 통해 기업들은 초거대 인공지능 모델 학습 비용을 효율적으로 절감할 것이다”라고 말했다.
이 연구 결과는 방제현 박사과정이 제1 저자로 참여하였고 컴퓨터 아키텍처 분야의 최우수 학술대회 중 하나인 미국 전기전자공학회(IEEE)·전산공학회(ACM) 공동 마이크로아키텍처 국제 학술대회(MICRO)에서 지난 11월 발표됐다. (논문제목: vTrain: A Simulation Framework for Evaluating Cost-Effective and Compute-Optimal Large Language Model Training, https://doi.org/10.1109/MICRO61859.2024.00021)
이번 연구는 정부(과학기술정보통신부)의 재원으로 한국연구재단, 정보통신기획평가원, 그리고 삼성전자의 지원을 받아 수행되었으며, 과학기술정보통신부 및 정보통신기획평가원의 SW컴퓨팅산업원천기술개발(SW스타랩) 사업으로 연구개발한 결과물이다.
챗GPT 등 대형 AI모델 학습 최적화 시뮬레이션 개발
최근 챗GPT, 딥시크(DeepSeek) 등 초거대 인공지능(AI) 모델이 다양한 분야에서 활용되며 주목받고 있다. 이러한 대형 언어 모델은 수만 개의 데이터센터용 GPU를 갖춘 대규모 분산 시스템에서 학습되는데, GPT-4의 경우 모델을 학습하는 데 소모되는 비용은 약 1,400억 원에 육박하는 것으로 추산된다. 한국 연구진이 GPU 사용률을 높이고 학습 비용을 절감할 수 있는 최적의 병렬화 구성을 도출하도록 돕는 기술을 개발했다.
우리 대학 전기및전자공학부 유민수 교수 연구팀은 삼성전자 삼성종합기술원과 공동연구를 통해, 대규모 분산 시스템에서 대형 언어 모델(LLM)의 학습 시간을 예측하고 최적화할 수 있는 시뮬레이션 프레임워크(이하 vTrain)를 개발했다고 13일 밝혔다.
대형 언어 모델 학습 효율을 높이려면 최적의 분산 학습 전략을 찾는 것이 필수적이다. 그러나 가능한 전략의 경우의 수가 방대할 뿐 아니라 실제 환경에서 각 전략의 성능을 테스트하는 데는 막대한 비용과 시간이 들어간다.
이에 따라 현재 대형 언어 모델을 학습하는 기업들은 일부 경험적으로 검증된 소수의 전략만을 사용하고 있다. 이는 GPU 활용의 비효율성과 불필요한 비용 증가를 초래하지만, 대규모 시스템을 위한 시뮬레이션 기술이 부족해 기업들이 문제를 효과적으로 해결하지 못하고 있는 상황이다.
이에 유민수 교수 연구팀은 vTrain을 개발해 대형 언어 모델의 학습 시간을 정확히 예측하고, 다양한 분산 병렬화 전략을 빠르게 탐색할 수 있도록 했다.
연구팀은 실제 다중 GPU 환경에서 다양한 대형 언어 모델 학습 시간 실측값과 vTrain의 예측값을 비교한 결과, 단일 노드에서 평균 절대 오차(MAPE) 8.37%, 다중 노드에서 14.73%의 정확도로 학습 시간을 예측할 수 있음을 검증했다.
연구팀은 삼성전자 삼성종합기술원와 공동연구를 진행하여 vTrain 프레임워크와 1,500개 이상의 실제 학습 시간 측정 데이터를 오픈소스로 공개(https://github.com/VIA-Research/vTrain)하여 AI 연구자와 기업이 이를 자유롭게 활용할 수 있도록 했다.
유민수 교수는 “vTrain은 프로파일링 기반 시뮬레이션 기법으로 기존 경험적 방식 대비 GPU 사용률을 높이고 학습 비용을 절감할 수 있는 학습 전략을 탐색하였으며 오픈소스를 공개하였다. 이를 통해 기업들은 초거대 인공지능 모델 학습 비용을 효율적으로 절감할 것이다”라고 말했다.
이 연구 결과는 방제현 박사과정이 제1 저자로 참여하였고 컴퓨터 아키텍처 분야의 최우수 학술대회 중 하나인 미국 전기전자공학회(IEEE)·전산공학회(ACM) 공동 마이크로아키텍처 국제 학술대회(MICRO)에서 지난 11월 발표됐다. (논문제목: vTrain: A Simulation Framework for Evaluating Cost-Effective and Compute-Optimal Large Language Model Training, https://doi.org/10.1109/MICRO61859.2024.00021)
이번 연구는 정부(과학기술정보통신부)의 재원으로 한국연구재단, 정보통신기획평가원, 그리고 삼성전자의 지원을 받아 수행되었으며, 과학기술정보통신부 및 정보통신기획평가원의 SW컴퓨팅산업원천기술개발(SW스타랩) 사업으로 연구개발한 결과물이다.
2025.03.13
조회수 3176
-
 감정노동 근로자 정신건강 살피는 AI 나왔다
감정노동이 필수적인 직무를 수행하는 상담원, 은행원 근로자들은 실제로 느끼는 감정과는 다른 감정을 표현해야 하는 상황에 자주 놓이게 된다. 이런 감정적 작업 부하에 장시간 노출되면 심각한 정신적, 심리적 문제뿐만 아니라 심혈관계 및 소화기계 질환 등 신체적 질병으로도 이어질 수 있어 이는 심각한 사회 문제로 여겨지고 있다. 한미 공동 연구진은 인공지능을 활용해서 근로자의 감정적 작업 부하를 자동으로 측정하고 실시간으로 모니터링할 수 있는 새로운 방법을 제시했다.
우리 대학 전산학부 이의진 교수 연구팀은 중앙대학교 박은지 교수팀, 미국 애크런 대학교의 감정노동 분야 세계적인 석학인 제임스 디펜도프 교수팀과 다학제 연구팀을 구성해 근로자들의 감정적 작업 부하를 실시간으로 추정해 심각한 정신적, 신체적 질병을 예방할 수 있는 인공지능 모델을 개발했다고 11일 밝혔다.
연구팀은 이번 연구를 통해 근로자가 감정적 작업 부하가 높은 상황과 그렇지 않은 상황을 87%의 정확도로 구분해 내는데 성공했다. 이 시스템은 기존의 설문이나 인터뷰 같은 주관적인 자기 보고 방식에 의존하지 않고도 감정적 작업 부하를 실시간으로 평가할 수 있어 근로자들의 정신건강 문제를 사전에 예방하고 효과적으로 관리할 수 있다는 장점이 있다. 또한, 이 시스템은 콜센터뿐만 아니라 고객 응대가 필요한 다양한 직종에 적용될 수 있어 감정 노동자들의 장기적인 정신건강 보호에 크게 기여할 것으로 기대된다.
기존 연구는 주로 사무실에서 컴퓨터를 사용해 서류 업무를 주로 다루는 직장인의 인지적 작업 부하(정보를 처리하고 의사결정을 내리는 데 필요한 정신적 노력)를 다뤘으며, 고객을 상대하는 감정 노동자들의 작업 부하를 추정하는 연구는 전무한 상황이었다.
감정 노동자들의 감정적 작업 부하는 고용주로부터 요구되는 정서 표현 규칙과 관련이 깊다. 특히 감정노동이 요구되는 상황에서는 자신의 실제 감정을 억제하고 친절한 응대를 해야 하기 때문에 대체적으로 근로자의 감정이나 심리적 상태가 표면적으로 드러나 있지 않다.
기존의 감정-탐지 인공지능 모델들은 주로 인간의 감정이 표정이나 목소리에 명백하게 드러나는 데이터를 활용해 모델을 학습해왔기 때문에 자신의 감정을 억제하고 친절한 응대를 강요받는 감정 노동자들의 내적인 감정적 작업 부하를 측정하는 것은 어려운 일로 여겨져 왔다.
모델 개발을 위해서는 현실을 충실히 반영한 고품질의 상담 시나리오 데이터셋 구축이 필수적어서 연구팀은 현업에 종사 중인 감정 노동자들을 대상으로 고객상담 데이터셋을 구축했다. 일반적인 콜센터 고객을 응대 시나리오를 개발하여 31명의 상담사로부터 음성, 행동, 생체신호 등 다중 모달 센서 데이터를 수집했다.
연구팀은 인공지능 모델 개발을 위해 고객과 상담사의 음성 데이터로부터 총 176개의 음성특징을 추출했다. 음성 신호 처리를 통해서 시간, 주파수, 음조 등 다양한 종류의 음성특징이 추출하며, 대화 내용은 고객의 개인정보 보호를 위하여 사용하지 않았다. 정서 표현 규칙으로 인한 상담사의 억제된 감정 상태를 추정하기 위하여 상담사로부터 수집된 생체신호로부터 추가적인 특징을 추출했다.
피부의 전기적 특성을 나타내는 피부 전도도(EDA, Electrodermal activity) 13개의 특징, 뇌의 전기적 활성도를 측정하는 뇌파(EEG, Electroencephalogram) 20개의 특징, 심전도(ECG, Electrocardiogram) 7개의 특징, 그 외 몸의 움직임, 체온 데이터로부터 12개의 특징을 추출했다. 총 228개의 특징을 추출해 9종의 인공지능 모델을 학습하여 성능 비교 평가를 수행했다.
결과적으로, 학습된 모델은 상담사가 감정적 작업 부하가 높은 상황과 그렇지 않은 상황을 87%의 정확도로 구분해 냈다. 흥미로운 점은 기존 감정-탐지 모델에서 대상의 목소리가 성능 향상에 기여하는 주요한 요인이었지만 본인의 감정을 억누르고 친절함을 유지해야 하는 감정노동의 상황에서는 상담사의 목소리가 포함될 경우 오히려 모델의 성능이 떨어지는 현상을 보였다는 것이다. 그 외에 고객의 목소리, 상담사의 피부 전도도 및 체온이 모델 성능 향상에 중요한 영향을 미치는 특징으로 밝혀졌다.
이의진 교수는 "감정적 작업 부하를 실시간으로 측정할 수 있는 기술을 통해 감정노동의 직무 환경 개선과 정신건강을 보호할 수 있다”며 "개발된 기술을 감정 노동자의 정신건강을 관리할 수 있는 모바일 앱과 연계하여 실증할 예정이다”고 말했다.
중앙대학교 박은지 교수(KAIST 전산학부 박사 졸업)가 제1 저자이며 유비쿼터스 컴퓨팅 분야 국제 최우수 학술지인 「Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies」 2024년 9월호에 게재됐다. 또한, 이 연구는 인간-컴퓨터 상호작용 분야의 최우수 학술대회인 ACM UbiComp 2024에서 발표됐다. (논문제목: Hide-and-seek: Detecting Workers’ Emotional Workload in Emotional Labor Contexts Using Multimodal Sensing, https://doi.org/10.1145/3678593)
이번 연구는 과학기술정보통신부 정보통신기획평가원 ICT융합산업혁신기술개발사업의 지원을 받아 수행됐다.
감정노동 근로자 정신건강 살피는 AI 나왔다
감정노동이 필수적인 직무를 수행하는 상담원, 은행원 근로자들은 실제로 느끼는 감정과는 다른 감정을 표현해야 하는 상황에 자주 놓이게 된다. 이런 감정적 작업 부하에 장시간 노출되면 심각한 정신적, 심리적 문제뿐만 아니라 심혈관계 및 소화기계 질환 등 신체적 질병으로도 이어질 수 있어 이는 심각한 사회 문제로 여겨지고 있다. 한미 공동 연구진은 인공지능을 활용해서 근로자의 감정적 작업 부하를 자동으로 측정하고 실시간으로 모니터링할 수 있는 새로운 방법을 제시했다.
우리 대학 전산학부 이의진 교수 연구팀은 중앙대학교 박은지 교수팀, 미국 애크런 대학교의 감정노동 분야 세계적인 석학인 제임스 디펜도프 교수팀과 다학제 연구팀을 구성해 근로자들의 감정적 작업 부하를 실시간으로 추정해 심각한 정신적, 신체적 질병을 예방할 수 있는 인공지능 모델을 개발했다고 11일 밝혔다.
연구팀은 이번 연구를 통해 근로자가 감정적 작업 부하가 높은 상황과 그렇지 않은 상황을 87%의 정확도로 구분해 내는데 성공했다. 이 시스템은 기존의 설문이나 인터뷰 같은 주관적인 자기 보고 방식에 의존하지 않고도 감정적 작업 부하를 실시간으로 평가할 수 있어 근로자들의 정신건강 문제를 사전에 예방하고 효과적으로 관리할 수 있다는 장점이 있다. 또한, 이 시스템은 콜센터뿐만 아니라 고객 응대가 필요한 다양한 직종에 적용될 수 있어 감정 노동자들의 장기적인 정신건강 보호에 크게 기여할 것으로 기대된다.
기존 연구는 주로 사무실에서 컴퓨터를 사용해 서류 업무를 주로 다루는 직장인의 인지적 작업 부하(정보를 처리하고 의사결정을 내리는 데 필요한 정신적 노력)를 다뤘으며, 고객을 상대하는 감정 노동자들의 작업 부하를 추정하는 연구는 전무한 상황이었다.
감정 노동자들의 감정적 작업 부하는 고용주로부터 요구되는 정서 표현 규칙과 관련이 깊다. 특히 감정노동이 요구되는 상황에서는 자신의 실제 감정을 억제하고 친절한 응대를 해야 하기 때문에 대체적으로 근로자의 감정이나 심리적 상태가 표면적으로 드러나 있지 않다.
기존의 감정-탐지 인공지능 모델들은 주로 인간의 감정이 표정이나 목소리에 명백하게 드러나는 데이터를 활용해 모델을 학습해왔기 때문에 자신의 감정을 억제하고 친절한 응대를 강요받는 감정 노동자들의 내적인 감정적 작업 부하를 측정하는 것은 어려운 일로 여겨져 왔다.
모델 개발을 위해서는 현실을 충실히 반영한 고품질의 상담 시나리오 데이터셋 구축이 필수적어서 연구팀은 현업에 종사 중인 감정 노동자들을 대상으로 고객상담 데이터셋을 구축했다. 일반적인 콜센터 고객을 응대 시나리오를 개발하여 31명의 상담사로부터 음성, 행동, 생체신호 등 다중 모달 센서 데이터를 수집했다.
연구팀은 인공지능 모델 개발을 위해 고객과 상담사의 음성 데이터로부터 총 176개의 음성특징을 추출했다. 음성 신호 처리를 통해서 시간, 주파수, 음조 등 다양한 종류의 음성특징이 추출하며, 대화 내용은 고객의 개인정보 보호를 위하여 사용하지 않았다. 정서 표현 규칙으로 인한 상담사의 억제된 감정 상태를 추정하기 위하여 상담사로부터 수집된 생체신호로부터 추가적인 특징을 추출했다.
피부의 전기적 특성을 나타내는 피부 전도도(EDA, Electrodermal activity) 13개의 특징, 뇌의 전기적 활성도를 측정하는 뇌파(EEG, Electroencephalogram) 20개의 특징, 심전도(ECG, Electrocardiogram) 7개의 특징, 그 외 몸의 움직임, 체온 데이터로부터 12개의 특징을 추출했다. 총 228개의 특징을 추출해 9종의 인공지능 모델을 학습하여 성능 비교 평가를 수행했다.
결과적으로, 학습된 모델은 상담사가 감정적 작업 부하가 높은 상황과 그렇지 않은 상황을 87%의 정확도로 구분해 냈다. 흥미로운 점은 기존 감정-탐지 모델에서 대상의 목소리가 성능 향상에 기여하는 주요한 요인이었지만 본인의 감정을 억누르고 친절함을 유지해야 하는 감정노동의 상황에서는 상담사의 목소리가 포함될 경우 오히려 모델의 성능이 떨어지는 현상을 보였다는 것이다. 그 외에 고객의 목소리, 상담사의 피부 전도도 및 체온이 모델 성능 향상에 중요한 영향을 미치는 특징으로 밝혀졌다.
이의진 교수는 "감정적 작업 부하를 실시간으로 측정할 수 있는 기술을 통해 감정노동의 직무 환경 개선과 정신건강을 보호할 수 있다”며 "개발된 기술을 감정 노동자의 정신건강을 관리할 수 있는 모바일 앱과 연계하여 실증할 예정이다”고 말했다.
중앙대학교 박은지 교수(KAIST 전산학부 박사 졸업)가 제1 저자이며 유비쿼터스 컴퓨팅 분야 국제 최우수 학술지인 「Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies」 2024년 9월호에 게재됐다. 또한, 이 연구는 인간-컴퓨터 상호작용 분야의 최우수 학술대회인 ACM UbiComp 2024에서 발표됐다. (논문제목: Hide-and-seek: Detecting Workers’ Emotional Workload in Emotional Labor Contexts Using Multimodal Sensing, https://doi.org/10.1145/3678593)
이번 연구는 과학기술정보통신부 정보통신기획평가원 ICT융합산업혁신기술개발사업의 지원을 받아 수행됐다.
2025.02.11
조회수 4681
-
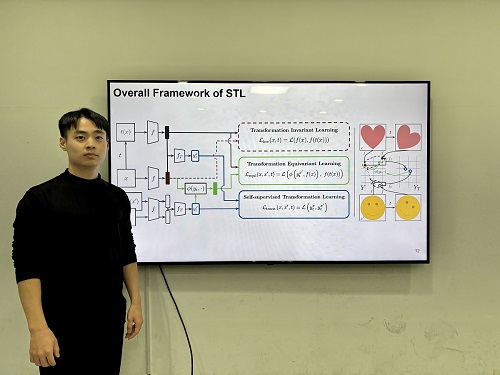 인간의 인지 방식과 유사한 AI 모델 개발
우리 연구진이 인간의 인지 방식을 모방해 이미지 변화를 이해하고, 시각적 일반화와 특정성을 동시에 확보하는 인공지능 기술을 개발했다. 이 기술은 의료 영상 분석, 자율주행, 로보틱스 등 다양한 분야에서 이미지를 이해하여 객체를 분류, 탐지하는 데 활용될 전망이다.
우리 대학 전기및전자공학부 김준모 교수 연구팀이 변환 레이블(transformational labels) 없이도 스스로 변환 민감 특징(transformation-sensitive features)을 학습할 수 있는 새로운 시각 인공지능 모델 STL(Self-supervised Transformation Learning)을 개발했다고 13일 밝혔다.
연구팀이 개발한 시각 인공지능 모델 STL은 스스로 이미지의 변환을 학습하여, 이미지 변환의 종류를 인간이 직접 알려주면서 학습하는 기존 방법들보다 높은 시각 정보 이해 능력을 보였다. 특히, 기존 방법론들을 통해 학습한 모델이 이해할 수 없는 세부적인 특징까지도 학습하여 기존 방법 대비 최대 42% 우수한 성능을 보여줬다.
컴퓨터 비전에서 이미지 변환을 통한 데이터 증강을 활용해 강건한 시각 표현을 학습하는 방식은 일반화 능력을 갖추는 데 효과적이지만, 변환에 따른 시각적 세부 사항을 무시하는 경향이 있어 범용 시각 인공지능 모델로서 한계가 있다.
연구팀이 제안한 STL은 변환 라벨 없이 변환 정보를 학습할 수 있도록 설계된 새로운 학습 기법으로, 라벨 없이 변환 민감 특징을 학습할 수 있다. 또한, 기존 학습 방법 대비 학습 복잡도를 유지한 채로 효율적인 최적화할 수 있는 방법을 제안했다.
실험 결과, STL은 정확하게 객체를 분류하고 탐지 실험에서 가장 낮은 오류율을 기록했다. 또한, STL이 생성한 표현 공간은 변환의 강도와 유형에 따라 명확히 군집화되어 변환 간 관계를 잘 반영하는 것으로 나타났다.
김준모 교수는 "이번에 개발한 STL은 복잡한 변환 패턴을 학습하고 이를 표현 공간에서 효과적으로 반영하는 능력을 통해 변환 민감 특징 학습의 새로운 가능성을 제시했다”며, "라벨 없이도 변환 정보를 학습할 수 있는 기술은 다양한 AI 응용 분야에서 핵심적인 역할을 할 것”이라고 말했다.
우리 대학 전기및전자공학부 유재명 박사과정이 제1 저자로 참여한 이번 연구는 최고 권위 국제 학술지 ‘신경정보처리시스템학회(NeurIPS) 2024’에서 올 12월 발표될 예정이다.(논문명: Self-supervised Transformation Learning for Equivariant Representations)
한편 이번 연구는 이 논문은 2024년도 정부(과학기술정보통신부)의 재원으로 정보통신기획평가원의 지원을 받아 수행된 연구 성과물(No.RS-2024-00439020, 지속가능한 실시간 멀티모달 인터렉티브 생성 AI 개발, SW스타랩) 이다.
인간의 인지 방식과 유사한 AI 모델 개발
우리 연구진이 인간의 인지 방식을 모방해 이미지 변화를 이해하고, 시각적 일반화와 특정성을 동시에 확보하는 인공지능 기술을 개발했다. 이 기술은 의료 영상 분석, 자율주행, 로보틱스 등 다양한 분야에서 이미지를 이해하여 객체를 분류, 탐지하는 데 활용될 전망이다.
우리 대학 전기및전자공학부 김준모 교수 연구팀이 변환 레이블(transformational labels) 없이도 스스로 변환 민감 특징(transformation-sensitive features)을 학습할 수 있는 새로운 시각 인공지능 모델 STL(Self-supervised Transformation Learning)을 개발했다고 13일 밝혔다.
연구팀이 개발한 시각 인공지능 모델 STL은 스스로 이미지의 변환을 학습하여, 이미지 변환의 종류를 인간이 직접 알려주면서 학습하는 기존 방법들보다 높은 시각 정보 이해 능력을 보였다. 특히, 기존 방법론들을 통해 학습한 모델이 이해할 수 없는 세부적인 특징까지도 학습하여 기존 방법 대비 최대 42% 우수한 성능을 보여줬다.
컴퓨터 비전에서 이미지 변환을 통한 데이터 증강을 활용해 강건한 시각 표현을 학습하는 방식은 일반화 능력을 갖추는 데 효과적이지만, 변환에 따른 시각적 세부 사항을 무시하는 경향이 있어 범용 시각 인공지능 모델로서 한계가 있다.
연구팀이 제안한 STL은 변환 라벨 없이 변환 정보를 학습할 수 있도록 설계된 새로운 학습 기법으로, 라벨 없이 변환 민감 특징을 학습할 수 있다. 또한, 기존 학습 방법 대비 학습 복잡도를 유지한 채로 효율적인 최적화할 수 있는 방법을 제안했다.
실험 결과, STL은 정확하게 객체를 분류하고 탐지 실험에서 가장 낮은 오류율을 기록했다. 또한, STL이 생성한 표현 공간은 변환의 강도와 유형에 따라 명확히 군집화되어 변환 간 관계를 잘 반영하는 것으로 나타났다.
김준모 교수는 "이번에 개발한 STL은 복잡한 변환 패턴을 학습하고 이를 표현 공간에서 효과적으로 반영하는 능력을 통해 변환 민감 특징 학습의 새로운 가능성을 제시했다”며, "라벨 없이도 변환 정보를 학습할 수 있는 기술은 다양한 AI 응용 분야에서 핵심적인 역할을 할 것”이라고 말했다.
우리 대학 전기및전자공학부 유재명 박사과정이 제1 저자로 참여한 이번 연구는 최고 권위 국제 학술지 ‘신경정보처리시스템학회(NeurIPS) 2024’에서 올 12월 발표될 예정이다.(논문명: Self-supervised Transformation Learning for Equivariant Representations)
한편 이번 연구는 이 논문은 2024년도 정부(과학기술정보통신부)의 재원으로 정보통신기획평가원의 지원을 받아 수행된 연구 성과물(No.RS-2024-00439020, 지속가능한 실시간 멀티모달 인터렉티브 생성 AI 개발, SW스타랩) 이다.
2024.12.15
조회수 4177
-
 ‘로봇스케치’ 도쿄 데뷔, 최우수 심사위원상 수상
VR 헤드셋을 쓴 디자이너(산업디자인학과 이준협 박사)가 태블릿과 펜으로 아무 것도 없는 가상 공간 속에서 유려한 입체 형태와 복잡한 관절 구조를 가지는 4족 거미 로봇을 단 몇 분 만에 그려서 완성했다. 디자이너가 컨트롤러를 조작하자 움직이던 거미 로봇이 일어나 2족 휴머노이드 로봇으로 자세를 수정하고 두 발을 짚고 걸음을 내딛기 시작했다. (2024 시그래프 아시아 리얼타임 라이브의 KAIST 로봇스케치 시연 장면)
우리 대학 12월 6일 도쿄 국제 포럼에서 열린 ‘시그래프 아시아 2024’의 하이라이트인 리얼타임 라이브(Real-Time Live!)에서 산업디자인학과 배석형 교수팀이 기계공학과 황보제민 교수팀과 협업하여 개발한 ‘로봇스케치(RobostSketch)’ 기술이 최우수 심사위원상(Jury’s Choice)을 수상했다고 9일 밝혔다.
‘시그래프 리얼타임 라이브’는 컴퓨터 그래픽스 및 상호작용 분야에서 ‘꿈의 무대’로 알려져 있다. 매년 전 세계에서 엄선된 10여 개의 혁신적인 기술만이 무대에 오른다.
모든 시연은 사전 녹화 없이 실시간으로 이루어지며, 6분이라는 제한된 시간 안에 기술의 독창성과 가능성을 선보여야 한다. KAIST의 로봇스케치는 이러한 무대에서 새로운 로봇 디자인 프로세스의 가능성을 보이며 큰 주목을 받았으며, 단 하나의 기술에만 수여되는 최우수 심사위원상을 수상했다.
로봇스케치는 단순히 외형과 구조를 시각적으로 표현하는 설계 도구를 넘어, 3D 스케칭에 생성형 AI와 몰입형 VR을 접목해 로봇 디자인의 개념을 새롭게 정의한 혁신적 기술이다.
디자이너는 VR 환경에서 태블릿과 펜을 사용해 복잡한 관절형 구조를 직관적으로 표현하고, 이를 실제 크기로 확인할 수 있다. 디자이너가 그린 로봇은 강화학습을 통해 현실 세계의 물리 법칙을 따르는 시뮬레이션 속에서 보행법과 움직임을 학습한다.
이를 통해 디자이너는 실제 세계에서 작동 가능한 로봇 디자인을 VR 공간 안에서 만들고, 로봇을 직접 움직이며 로봇이 가질 동작의 자연스러움과 안정성을 실시간으로 확인할 수 있다.
로봇스케치는 3D 스케칭 전문가인 산업디자인학과 배석형 교수 연구팀과 로봇 강화학습 전문가인 기계공학과 황보제민 교수 연구팀의 협업으로 완성됐다.
배석형 교수는 “기존 로봇 디자인의 한계를 극복하고, 로봇 디자이너가 상상하는 모든 것을 실시간으로 표현할 수 있는 도구를 만들고 싶었다”고 밝혔다.
이어 “로봇 디자인은 단순히 외형뿐 아니라 로봇의 움직임과 기능, 더 나아가 사용자와의 상호작용까지 모두 포함하는 과정이며 로봇 디자이너와 로봇 엔지니어의 원활한 소통을 촉진하고 현실 프로토타이핑에 소모되는 시간과 비용을 크게 줄일 수 있는 로봇스케치는 앞으로 로봇 개발과 제품화 과정에서 중요한 도구가 될 것”이라고 덧붙였다.
이 연구는 ‘DRB-KAIST 스케치더퓨처 연구센터’의 지원 아래 이루어진 결과로, 해당 센터는 3D 스케칭, AI, VR 기술을 결합해 전문가의 창의성과 생산성을 극대화하는 도구를 연구하며 첨단 기술과 디자인의 융합 가능성을 탐구하고 있다. 앞으로 로봇 디자인뿐 아니라 미래 산업 전반에서 고도화된 디자인 도구의 발전이 기대된다.
ACM SIGGRAPH Asia 2024 리얼타임 라이브 <로봇 스케치> 시연 영상: https://youtu.be/5wi53Z2_sAk
‘로봇스케치’ 도쿄 데뷔, 최우수 심사위원상 수상
VR 헤드셋을 쓴 디자이너(산업디자인학과 이준협 박사)가 태블릿과 펜으로 아무 것도 없는 가상 공간 속에서 유려한 입체 형태와 복잡한 관절 구조를 가지는 4족 거미 로봇을 단 몇 분 만에 그려서 완성했다. 디자이너가 컨트롤러를 조작하자 움직이던 거미 로봇이 일어나 2족 휴머노이드 로봇으로 자세를 수정하고 두 발을 짚고 걸음을 내딛기 시작했다. (2024 시그래프 아시아 리얼타임 라이브의 KAIST 로봇스케치 시연 장면)
우리 대학 12월 6일 도쿄 국제 포럼에서 열린 ‘시그래프 아시아 2024’의 하이라이트인 리얼타임 라이브(Real-Time Live!)에서 산업디자인학과 배석형 교수팀이 기계공학과 황보제민 교수팀과 협업하여 개발한 ‘로봇스케치(RobostSketch)’ 기술이 최우수 심사위원상(Jury’s Choice)을 수상했다고 9일 밝혔다.
‘시그래프 리얼타임 라이브’는 컴퓨터 그래픽스 및 상호작용 분야에서 ‘꿈의 무대’로 알려져 있다. 매년 전 세계에서 엄선된 10여 개의 혁신적인 기술만이 무대에 오른다.
모든 시연은 사전 녹화 없이 실시간으로 이루어지며, 6분이라는 제한된 시간 안에 기술의 독창성과 가능성을 선보여야 한다. KAIST의 로봇스케치는 이러한 무대에서 새로운 로봇 디자인 프로세스의 가능성을 보이며 큰 주목을 받았으며, 단 하나의 기술에만 수여되는 최우수 심사위원상을 수상했다.
로봇스케치는 단순히 외형과 구조를 시각적으로 표현하는 설계 도구를 넘어, 3D 스케칭에 생성형 AI와 몰입형 VR을 접목해 로봇 디자인의 개념을 새롭게 정의한 혁신적 기술이다.
디자이너는 VR 환경에서 태블릿과 펜을 사용해 복잡한 관절형 구조를 직관적으로 표현하고, 이를 실제 크기로 확인할 수 있다. 디자이너가 그린 로봇은 강화학습을 통해 현실 세계의 물리 법칙을 따르는 시뮬레이션 속에서 보행법과 움직임을 학습한다.
이를 통해 디자이너는 실제 세계에서 작동 가능한 로봇 디자인을 VR 공간 안에서 만들고, 로봇을 직접 움직이며 로봇이 가질 동작의 자연스러움과 안정성을 실시간으로 확인할 수 있다.
로봇스케치는 3D 스케칭 전문가인 산업디자인학과 배석형 교수 연구팀과 로봇 강화학습 전문가인 기계공학과 황보제민 교수 연구팀의 협업으로 완성됐다.
배석형 교수는 “기존 로봇 디자인의 한계를 극복하고, 로봇 디자이너가 상상하는 모든 것을 실시간으로 표현할 수 있는 도구를 만들고 싶었다”고 밝혔다.
이어 “로봇 디자인은 단순히 외형뿐 아니라 로봇의 움직임과 기능, 더 나아가 사용자와의 상호작용까지 모두 포함하는 과정이며 로봇 디자이너와 로봇 엔지니어의 원활한 소통을 촉진하고 현실 프로토타이핑에 소모되는 시간과 비용을 크게 줄일 수 있는 로봇스케치는 앞으로 로봇 개발과 제품화 과정에서 중요한 도구가 될 것”이라고 덧붙였다.
이 연구는 ‘DRB-KAIST 스케치더퓨처 연구센터’의 지원 아래 이루어진 결과로, 해당 센터는 3D 스케칭, AI, VR 기술을 결합해 전문가의 창의성과 생산성을 극대화하는 도구를 연구하며 첨단 기술과 디자인의 융합 가능성을 탐구하고 있다. 앞으로 로봇 디자인뿐 아니라 미래 산업 전반에서 고도화된 디자인 도구의 발전이 기대된다.
ACM SIGGRAPH Asia 2024 리얼타임 라이브 <로봇 스케치> 시연 영상: https://youtu.be/5wi53Z2_sAk
2024.12.09
조회수 5031
-
 인공지능 화학 학습으로 새로운 소재 개발 가능
새로운 물질을 설계하거나 물질의 물성을 예측하는 데 인공지능을 활용하기도 한다. 한미 공동 연구진이 기본 인공지능 모델보다 발전되어 화학 개념 학습을 하고 소재 예측, 새로운 물질 설계, 물질의 물성 예측에 더 높은 정확도를 제공하는 인공지능을 개발하는 데 성공했다.
우리 대학 화학과 이억균 명예교수와 김형준 교수 공동 연구팀이 창원대학교 생물학화학융합학부 김원준 교수, 미국 UC 머세드(Merced) 응용수학과의 김창호 교수 연구팀과 공동연구를 통해, 새로운 인공지능(AI) 기술인 ‘프로핏-넷(이하 PROFiT-Net)’을 개발하는 데 성공했다고 9일 밝혔다.
연구팀이 개발한 인공지능은 유전율, 밴드갭, 형성 에너지 등의 주요한 소재 물성 예측 정확도에 있어서 이번 기술은 기존 딥러닝 모델의 오차를 최소 10%, 최대 40% 줄일 수 있는 것으로 보여 주목받고 있다.
PROFiT-Net의 가장 큰 특징은 화학의 기본 개념을 학습해 예측 성능을 크게 높였다는 점이다. 최외각 전자 배치, 이온화 에너지, 전기 음성도와 같은 내용은 화학을 배울 때 가장 먼저 배우는 기본 개념 중 하나다.
기존 AI 모델과 달리, PROFiT-Net은 이러한 기본 화학적 속성과 이들 간의 상호작용을 직접적으로 학습함으로써 더욱 정밀한 예측을 할 수 있다. 이는 특히 새로운 물질을 설계하거나 물질의 물성을 예측하는 데 있어 더 높은 정확도를 제공하며, 화학 및 소재 과학 분야에서 크게 기여할 것으로 기대된다.
김형준 교수는 "AI 기술이 기초 화학 개념을 바탕으로 한층 더 발전할 수 있다는 가능성을 보여주었다ˮ고 말했으며 “추후 반도체 소재나 기능성 소재 개발과 같은 다양한 응용 분야에서 AI가 중요한 도구로 자리 잡을 수 있는 발판을 마련했다ˮ고 말했다.
이번 연구는 KAIST의 김세준 박사가 제1 저자로 참여하였고, 국제 학술지 `미국화학회지(Journal of the American Chemical Society)' 에 지난 9월 25일 字 게재됐다.
(논문명: PROFiT-Net: Property-networking deep learning model for materials, PROFiT-Net 링크: https://github.com/sejunkim6370/PROFiT-Net)
한편 이번 연구는 한국연구재단(NRF)의 나노·소재 기술개발(In-memory 컴퓨팅용 강유전체 개발을 위한 전주기 AI 기술)과 탑-티어 연구기관 간 협력 플랫폼 구축 및 공동연구 지원사업으로 진행됐다.
인공지능 화학 학습으로 새로운 소재 개발 가능
새로운 물질을 설계하거나 물질의 물성을 예측하는 데 인공지능을 활용하기도 한다. 한미 공동 연구진이 기본 인공지능 모델보다 발전되어 화학 개념 학습을 하고 소재 예측, 새로운 물질 설계, 물질의 물성 예측에 더 높은 정확도를 제공하는 인공지능을 개발하는 데 성공했다.
우리 대학 화학과 이억균 명예교수와 김형준 교수 공동 연구팀이 창원대학교 생물학화학융합학부 김원준 교수, 미국 UC 머세드(Merced) 응용수학과의 김창호 교수 연구팀과 공동연구를 통해, 새로운 인공지능(AI) 기술인 ‘프로핏-넷(이하 PROFiT-Net)’을 개발하는 데 성공했다고 9일 밝혔다.
연구팀이 개발한 인공지능은 유전율, 밴드갭, 형성 에너지 등의 주요한 소재 물성 예측 정확도에 있어서 이번 기술은 기존 딥러닝 모델의 오차를 최소 10%, 최대 40% 줄일 수 있는 것으로 보여 주목받고 있다.
PROFiT-Net의 가장 큰 특징은 화학의 기본 개념을 학습해 예측 성능을 크게 높였다는 점이다. 최외각 전자 배치, 이온화 에너지, 전기 음성도와 같은 내용은 화학을 배울 때 가장 먼저 배우는 기본 개념 중 하나다.
기존 AI 모델과 달리, PROFiT-Net은 이러한 기본 화학적 속성과 이들 간의 상호작용을 직접적으로 학습함으로써 더욱 정밀한 예측을 할 수 있다. 이는 특히 새로운 물질을 설계하거나 물질의 물성을 예측하는 데 있어 더 높은 정확도를 제공하며, 화학 및 소재 과학 분야에서 크게 기여할 것으로 기대된다.
김형준 교수는 "AI 기술이 기초 화학 개념을 바탕으로 한층 더 발전할 수 있다는 가능성을 보여주었다ˮ고 말했으며 “추후 반도체 소재나 기능성 소재 개발과 같은 다양한 응용 분야에서 AI가 중요한 도구로 자리 잡을 수 있는 발판을 마련했다ˮ고 말했다.
이번 연구는 KAIST의 김세준 박사가 제1 저자로 참여하였고, 국제 학술지 `미국화학회지(Journal of the American Chemical Society)' 에 지난 9월 25일 字 게재됐다.
(논문명: PROFiT-Net: Property-networking deep learning model for materials, PROFiT-Net 링크: https://github.com/sejunkim6370/PROFiT-Net)
한편 이번 연구는 한국연구재단(NRF)의 나노·소재 기술개발(In-memory 컴퓨팅용 강유전체 개발을 위한 전주기 AI 기술)과 탑-티어 연구기관 간 협력 플랫폼 구축 및 공동연구 지원사업으로 진행됐다.
2024.10.10
조회수 8270
-
 고비용 인프라 없이 AI 학습 가속화 가능
우리 대학 연구진이 고가의 데이터센터급 GPU나 고속 네트워크 없이도 AI 모델을 효율적으로 학습할 수 있는 기술을 개발했다. 이 기술을 통해 자원이 제한된 기업이나 연구자들이 AI 연구를 보다 효과적으로 수행할 수 있을 것으로 기대된다.
우리 대학 전기및전자공학부 한동수 교수 연구팀이 일반 소비자용 GPU를 활용해, 네트워크 대역폭이 제한된 분산 환경에서도 AI 모델 학습을 수십에서 수백 배 가속할 수 있는 기술을 개발했다고 19일 밝혔다.
기존에는 AI 모델을 학습하기 위해 개당 수천만 원에 달하는 고성능 서버용 GPU(엔비디아 H100) 여러 대와 이들을 연결하기 위한 400Gbps급 고속 네트워크를 가진 고가 인프라가 필요했다. 하지만 소수의 거대 IT 기업을 제외한 대부분의 기업과 연구자들은 비용 문제로 이러한 고가의 인프라를 도입하기 어려웠다.
한동수 교수 연구팀은 이러한 문제를 해결하기 위해 '스텔라트레인(StellaTrain)'이라는 분산 학습 프레임워크를 개발했다. 이 기술은 고성능 H100에 비해 10~20배 저렴한 소비자용 GPU를 활용해, 고속의 전용 네트워크 대신 대역폭이 수백에서 수천 배 낮은 일반 인터넷 환경에서도 효율적인 분산 학습을 가능하게 한다.
기존의 저가 GPU를 사용할 경우, 작은 GPU 메모리와 네트워크 속도 제한으로 인해 대규모 AI 모델 학습 시 속도가 수백 배 느려지는 한계가 있었다. 하지만 연구팀이 개발한 스텔라트레인 기술은 CPU와 GPU를 병렬로 활용해 학습 속도를 높이고, 네트워크 속도에 맞춰 데이터를 효율적으로 압축 및 전송하는 알고리즘을 적용해 고속 네트워크 없이도 여러 대의 저가 GPU를 이용해 빠른 학습을 가능하게 했다.
특히, 학습을 작업 단계별로 CPU와 GPU가 나누어 병렬적으로 처리할 수 있는 새로운 파이프라인 기술을 도입해 연산 자원의 효율을 극대화했다. 또한, 원거리 분산 환경에서도 GPU 연산 효율을 높이기 위해, AI 모델별 GPU 활용률을 실시간으로 모니터링해 모델이 학습하는 샘플의 개수(배치 크기)를 동적으로 결정하고, 변화하는 네트워크 대역폭에 맞추어 GPU 간의 데이터 전송을 효율화하는 기술을 개발했다.
연구 결과, 스텔라트레인 기술을 사용하면 기존의 데이터 병렬 학습에 비해 최대 104배 빠른 성능을 낼 수 있는 것으로 나타났다.
한동수 교수는 "이번 연구가 대규모 AI 모델 학습을 누구나 쉽게 접근할 수 있게 하는 데 큰 기여를 할 것"이라고 밝혔다. “앞으로도 저비용 환경에서도 대규모 AI 모델을 학습할 수 있는 기술 개발을 계속할 계획이다”라고 말했다.
이번 연구는 우리 대학 임휘준 박사, 예준철 박사과정 학생, UC 어바인의 산기타 압두 조시(Sangeetha Abdu Jyothi) 교수와 공동으로 진행됐으며, 연구 성과는 지난 8월 호주 시드니에서 열린 ACM SIGCOMM 2024에서 발표됐다.
한편, 한동수 교수 연구팀은 2024년 7월 GPU 메모리 한계를 극복해 소수의 GPU로 거대 언어 모델을 학습하는 새로운 기술도 발표했다. 해당 연구는 최신 거대 언어 모델의 기반이 되는 전문가 혼합형(Mixture of Expert) 모델을 제한된 메모리 환경에서도 효율적인 학습을 가능하게 한다.
이 결과 기존에 32~64개 GPU가 필요한 150억 파라미터 규모의 언어 모델을 단 4개의 GPU만으로도 학습할 수 있게 됐다. 이를 통해 학습의 필요한 최소 GPU 대수를 8배~16배 낮출 수 있게 됐다. 해당 논문은 KAIST 임휘준 박사와 김예찬 연구원이 참여했으며, 오스트리아 빈에서 열린 AI 분야 최고 권위 학회인 ICML에 발표됐다. 이러한 일련의 연구 결과는 자원이 제한된 환경에서도 대규모 AI 모델 학습이 가능하다는 점에서 중요한 의미를 가진다.
해당 연구는 과학기술정보통신부 한국연구재단이 주관하는 중견연구사업 (RS-2024-00340099), 정보통신기획평가원(IITP)이 주관하는 정보통신·방송 기술개발사업 및 표준개발지원사업 (RS-2024-00418784), 차세대통신클라우드리더십구축사업 (RS-2024-00123456), 삼성전자의 지원을 받아 수행됐다.
고비용 인프라 없이 AI 학습 가속화 가능
우리 대학 연구진이 고가의 데이터센터급 GPU나 고속 네트워크 없이도 AI 모델을 효율적으로 학습할 수 있는 기술을 개발했다. 이 기술을 통해 자원이 제한된 기업이나 연구자들이 AI 연구를 보다 효과적으로 수행할 수 있을 것으로 기대된다.
우리 대학 전기및전자공학부 한동수 교수 연구팀이 일반 소비자용 GPU를 활용해, 네트워크 대역폭이 제한된 분산 환경에서도 AI 모델 학습을 수십에서 수백 배 가속할 수 있는 기술을 개발했다고 19일 밝혔다.
기존에는 AI 모델을 학습하기 위해 개당 수천만 원에 달하는 고성능 서버용 GPU(엔비디아 H100) 여러 대와 이들을 연결하기 위한 400Gbps급 고속 네트워크를 가진 고가 인프라가 필요했다. 하지만 소수의 거대 IT 기업을 제외한 대부분의 기업과 연구자들은 비용 문제로 이러한 고가의 인프라를 도입하기 어려웠다.
한동수 교수 연구팀은 이러한 문제를 해결하기 위해 '스텔라트레인(StellaTrain)'이라는 분산 학습 프레임워크를 개발했다. 이 기술은 고성능 H100에 비해 10~20배 저렴한 소비자용 GPU를 활용해, 고속의 전용 네트워크 대신 대역폭이 수백에서 수천 배 낮은 일반 인터넷 환경에서도 효율적인 분산 학습을 가능하게 한다.
기존의 저가 GPU를 사용할 경우, 작은 GPU 메모리와 네트워크 속도 제한으로 인해 대규모 AI 모델 학습 시 속도가 수백 배 느려지는 한계가 있었다. 하지만 연구팀이 개발한 스텔라트레인 기술은 CPU와 GPU를 병렬로 활용해 학습 속도를 높이고, 네트워크 속도에 맞춰 데이터를 효율적으로 압축 및 전송하는 알고리즘을 적용해 고속 네트워크 없이도 여러 대의 저가 GPU를 이용해 빠른 학습을 가능하게 했다.
특히, 학습을 작업 단계별로 CPU와 GPU가 나누어 병렬적으로 처리할 수 있는 새로운 파이프라인 기술을 도입해 연산 자원의 효율을 극대화했다. 또한, 원거리 분산 환경에서도 GPU 연산 효율을 높이기 위해, AI 모델별 GPU 활용률을 실시간으로 모니터링해 모델이 학습하는 샘플의 개수(배치 크기)를 동적으로 결정하고, 변화하는 네트워크 대역폭에 맞추어 GPU 간의 데이터 전송을 효율화하는 기술을 개발했다.
연구 결과, 스텔라트레인 기술을 사용하면 기존의 데이터 병렬 학습에 비해 최대 104배 빠른 성능을 낼 수 있는 것으로 나타났다.
한동수 교수는 "이번 연구가 대규모 AI 모델 학습을 누구나 쉽게 접근할 수 있게 하는 데 큰 기여를 할 것"이라고 밝혔다. “앞으로도 저비용 환경에서도 대규모 AI 모델을 학습할 수 있는 기술 개발을 계속할 계획이다”라고 말했다.
이번 연구는 우리 대학 임휘준 박사, 예준철 박사과정 학생, UC 어바인의 산기타 압두 조시(Sangeetha Abdu Jyothi) 교수와 공동으로 진행됐으며, 연구 성과는 지난 8월 호주 시드니에서 열린 ACM SIGCOMM 2024에서 발표됐다.
한편, 한동수 교수 연구팀은 2024년 7월 GPU 메모리 한계를 극복해 소수의 GPU로 거대 언어 모델을 학습하는 새로운 기술도 발표했다. 해당 연구는 최신 거대 언어 모델의 기반이 되는 전문가 혼합형(Mixture of Expert) 모델을 제한된 메모리 환경에서도 효율적인 학습을 가능하게 한다.
이 결과 기존에 32~64개 GPU가 필요한 150억 파라미터 규모의 언어 모델을 단 4개의 GPU만으로도 학습할 수 있게 됐다. 이를 통해 학습의 필요한 최소 GPU 대수를 8배~16배 낮출 수 있게 됐다. 해당 논문은 KAIST 임휘준 박사와 김예찬 연구원이 참여했으며, 오스트리아 빈에서 열린 AI 분야 최고 권위 학회인 ICML에 발표됐다. 이러한 일련의 연구 결과는 자원이 제한된 환경에서도 대규모 AI 모델 학습이 가능하다는 점에서 중요한 의미를 가진다.
해당 연구는 과학기술정보통신부 한국연구재단이 주관하는 중견연구사업 (RS-2024-00340099), 정보통신기획평가원(IITP)이 주관하는 정보통신·방송 기술개발사업 및 표준개발지원사업 (RS-2024-00418784), 차세대통신클라우드리더십구축사업 (RS-2024-00123456), 삼성전자의 지원을 받아 수행됐다.
2024.09.19
조회수 5838