-
 초대규모 인공지능 모델 처리하기 위한 세계 최고 성능의 기계학습 시스템 기술 개발
우리 연구진이 오늘날 인공지능 딥러닝 모델들을 처리하기 위해 필수적으로 사용되는 기계학습 시스템을 세계 최고 수준의 성능으로 끌어올렸다.
우리 대학 전산학부 김민수 교수 연구팀이 딥러닝 모델을 비롯한 기계학습 모델을 학습하거나 추론하기 위해 필수적으로 사용되는 기계학습 시스템의 성능을 대폭 높일 수 있는 세계 최고 수준의 행렬 연산자 융합 기술(일명 FuseME)을 개발했다고 20일 밝혔다.
오늘날 광범위한 산업 분야들에서 사용되고 있는 딥러닝 모델들은 대부분 구글 텐서플로우(TensorFlow)나 IBM 시스템DS와 같은 기계학습 시스템을 이용해 처리되는데, 딥러닝 모델의 규모가 점점 더 커지고, 그 모델에 사용되는 데이터의 규모가 점점 더 커짐에 따라, 이들을 원활히 처리할 수 있는 고성능 기계학습 시스템에 대한 중요성도 점점 더 커지고 있다.
일반적으로 딥러닝 모델은 행렬 곱셈, 행렬 합, 행렬 집계 등의 많은 행렬 연산자들로 구성된 방향성 비순환 그래프(Directed Acyclic Graph; 이하 DAG) 형태의 질의 계획으로 표현돼 기계학습 시스템에 의해 처리된다. 모델과 데이터의 규모가 클 때는 일반적으로 DAG 질의 계획은 수많은 컴퓨터로 구성된 클러스터에서 처리된다. 클러스터의 사양에 비해 모델과 데이터의 규모가 커지면 처리에 실패하거나 시간이 오래 걸리는 근본적인 문제가 있었다.
지금까지는 더 큰 규모의 모델이나 데이터를 처리하기 위해 단순히 컴퓨터 클러스터의 규모를 증가시키는 방식을 주로 사용했다. 그러나, 김 교수팀은 DAG 질의 계획을 구성하는 각 행렬 연산자로부터 생성되는 일종의 `중간 데이터'를 메모리에 저장하거나 네트워크 통신을 통해 다른 컴퓨터로 전송하는 것이 문제의 원인임에 착안해, 중간 데이터를 저장하지 않거나 다른 컴퓨터로 전송하지 않도록 여러 행렬 연산자들을 하나의 연산자로 융합(fusion)하는 세계 최고 성능의 융합 기술인 FuseME(Fused Matrix Engine)을 개발해 문제를 해결했다.
현재까지의 기계학습 시스템들은 낮은 수준의 연산자 융합 기술만을 사용하고 있었다. 가장 복잡한 행렬 연산자인 행렬 곱을 제외한 나머지 연산자들만 융합해 성능이 별로 개선되지 않거나, 전체 DAG 질의 계획을 단순히 하나의 연산자처럼 실행해 메모리 부족으로 처리에 실패하는 한계를 지니고 있었다.
김 교수팀이 개발한 FuseME 기술은 수십 개 이상의 행렬 연산자들로 구성되는 DAG 질의 계획에서 어떤 연산자들끼리 서로 융합하는 것이 더 우수한 성능을 내는지 비용 기반으로 판별해 그룹으로 묶고, 클러스터의 사양, 네트워크 통신 속도, 입력 데이터 크기 등을 모두 고려해 각 융합 연산자 그룹을 메모리 부족으로 처리에 실패하지 않으면서 이론적으로 최적 성능을 낼 수 있는 CFO(Cuboid-based Fused Operator)라 불리는 연산자로 융합함으로써 한계를 극복했다. 이때, 행렬 곱 연산자까지 포함해 연산자들을 융합하는 것이 핵심이다.
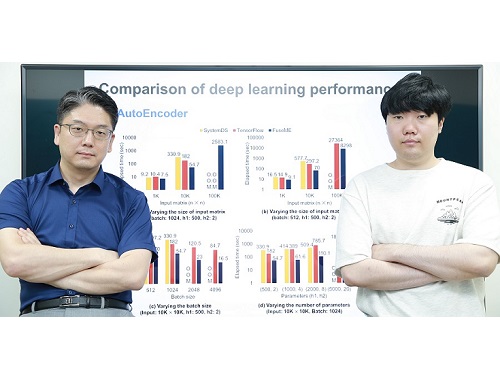
김민수 교수 연구팀은 FuseME 기술을 종래 최고 기술로 알려진 구글의 텐서플로우나 IBM의 시스템DS와 비교 평가한 결과, 딥러닝 모델의 처리 속도를 최대 8.8배 향상하고, 텐서플로우나 시스템DS가 처리할 수 없는 훨씬 더 큰 규모의 모델 및 데이터를 처리하는 데 성공함을 보였다. 또한, FuseME의 CFO 융합 연산자는 종래의 최고 수준 융합 연산자와 비교해 처리 속도를 최대 238배 향상시키고, 네트워크 통신 비용을 최대 64배 감소시키는 사실을 확인했다.
김 교수팀은 이미 지난 2019년에 초대규모 행렬 곱 연산에 대해 종래 세계 최고 기술이었던 IBM 시스템ML과 슈퍼컴퓨팅 분야의 스칼라팩(ScaLAPACK) 대비 성능과 처리 규모를 훨씬 향상시킨 DistME라는 기술을 개발해 데이터베이스 분야 최고 국제학술대회 중 하나인 ACM SIGMOD에서 발표한 바 있다. 이번 FuseME 기술은 연산자 융합이 가능하도록 DistME를 한층 더 발전시킨 것으로, 해당 분야를 세계 최고 수준의 기술력을 바탕으로 지속적으로 선도하는 쾌거를 보여준 것이다.
교신저자로 참여한 김민수 교수는 "연구팀이 개발한 새로운 기술은 딥러닝 등 기계학습 모델의 처리 규모와 성능을 획기적으로 높일 수 있어 산업적 측면에서 파급 효과가 매우 클 것으로 기대한다ˮ 라고 말했다.
이번 연구에는 김 교수의 제자이자 현재 GraphAI(그래파이) 스타트업의 공동 창업자인 한동형 박사가 제1 저자로, 김 교수가 교신저자로 참여했으며 지난 16일 미국 필라델피아에서 열린 데이터베이스 분야 최고 국제학술대회 중 하나인 ACM SIGMOD에서 발표됐다. (논문명 : FuseME: Distributed Matrix Computation Engine based on Cuboid-based Fused Operator and Plan Generation).
한편, 이번 연구는 한국연구재단 선도연구센터 사업 및 중견연구자 지원사업, 과기정통부 IITP SW스타랩 사업의 지원을 받아 수행됐다.
초대규모 인공지능 모델 처리하기 위한 세계 최고 성능의 기계학습 시스템 기술 개발
우리 연구진이 오늘날 인공지능 딥러닝 모델들을 처리하기 위해 필수적으로 사용되는 기계학습 시스템을 세계 최고 수준의 성능으로 끌어올렸다.
우리 대학 전산학부 김민수 교수 연구팀이 딥러닝 모델을 비롯한 기계학습 모델을 학습하거나 추론하기 위해 필수적으로 사용되는 기계학습 시스템의 성능을 대폭 높일 수 있는 세계 최고 수준의 행렬 연산자 융합 기술(일명 FuseME)을 개발했다고 20일 밝혔다.
오늘날 광범위한 산업 분야들에서 사용되고 있는 딥러닝 모델들은 대부분 구글 텐서플로우(TensorFlow)나 IBM 시스템DS와 같은 기계학습 시스템을 이용해 처리되는데, 딥러닝 모델의 규모가 점점 더 커지고, 그 모델에 사용되는 데이터의 규모가 점점 더 커짐에 따라, 이들을 원활히 처리할 수 있는 고성능 기계학습 시스템에 대한 중요성도 점점 더 커지고 있다.
일반적으로 딥러닝 모델은 행렬 곱셈, 행렬 합, 행렬 집계 등의 많은 행렬 연산자들로 구성된 방향성 비순환 그래프(Directed Acyclic Graph; 이하 DAG) 형태의 질의 계획으로 표현돼 기계학습 시스템에 의해 처리된다. 모델과 데이터의 규모가 클 때는 일반적으로 DAG 질의 계획은 수많은 컴퓨터로 구성된 클러스터에서 처리된다. 클러스터의 사양에 비해 모델과 데이터의 규모가 커지면 처리에 실패하거나 시간이 오래 걸리는 근본적인 문제가 있었다.
지금까지는 더 큰 규모의 모델이나 데이터를 처리하기 위해 단순히 컴퓨터 클러스터의 규모를 증가시키는 방식을 주로 사용했다. 그러나, 김 교수팀은 DAG 질의 계획을 구성하는 각 행렬 연산자로부터 생성되는 일종의 `중간 데이터'를 메모리에 저장하거나 네트워크 통신을 통해 다른 컴퓨터로 전송하는 것이 문제의 원인임에 착안해, 중간 데이터를 저장하지 않거나 다른 컴퓨터로 전송하지 않도록 여러 행렬 연산자들을 하나의 연산자로 융합(fusion)하는 세계 최고 성능의 융합 기술인 FuseME(Fused Matrix Engine)을 개발해 문제를 해결했다.
현재까지의 기계학습 시스템들은 낮은 수준의 연산자 융합 기술만을 사용하고 있었다. 가장 복잡한 행렬 연산자인 행렬 곱을 제외한 나머지 연산자들만 융합해 성능이 별로 개선되지 않거나, 전체 DAG 질의 계획을 단순히 하나의 연산자처럼 실행해 메모리 부족으로 처리에 실패하는 한계를 지니고 있었다.
김 교수팀이 개발한 FuseME 기술은 수십 개 이상의 행렬 연산자들로 구성되는 DAG 질의 계획에서 어떤 연산자들끼리 서로 융합하는 것이 더 우수한 성능을 내는지 비용 기반으로 판별해 그룹으로 묶고, 클러스터의 사양, 네트워크 통신 속도, 입력 데이터 크기 등을 모두 고려해 각 융합 연산자 그룹을 메모리 부족으로 처리에 실패하지 않으면서 이론적으로 최적 성능을 낼 수 있는 CFO(Cuboid-based Fused Operator)라 불리는 연산자로 융합함으로써 한계를 극복했다. 이때, 행렬 곱 연산자까지 포함해 연산자들을 융합하는 것이 핵심이다.
김민수 교수 연구팀은 FuseME 기술을 종래 최고 기술로 알려진 구글의 텐서플로우나 IBM의 시스템DS와 비교 평가한 결과, 딥러닝 모델의 처리 속도를 최대 8.8배 향상하고, 텐서플로우나 시스템DS가 처리할 수 없는 훨씬 더 큰 규모의 모델 및 데이터를 처리하는 데 성공함을 보였다. 또한, FuseME의 CFO 융합 연산자는 종래의 최고 수준 융합 연산자와 비교해 처리 속도를 최대 238배 향상시키고, 네트워크 통신 비용을 최대 64배 감소시키는 사실을 확인했다.
김 교수팀은 이미 지난 2019년에 초대규모 행렬 곱 연산에 대해 종래 세계 최고 기술이었던 IBM 시스템ML과 슈퍼컴퓨팅 분야의 스칼라팩(ScaLAPACK) 대비 성능과 처리 규모를 훨씬 향상시킨 DistME라는 기술을 개발해 데이터베이스 분야 최고 국제학술대회 중 하나인 ACM SIGMOD에서 발표한 바 있다. 이번 FuseME 기술은 연산자 융합이 가능하도록 DistME를 한층 더 발전시킨 것으로, 해당 분야를 세계 최고 수준의 기술력을 바탕으로 지속적으로 선도하는 쾌거를 보여준 것이다.
교신저자로 참여한 김민수 교수는 "연구팀이 개발한 새로운 기술은 딥러닝 등 기계학습 모델의 처리 규모와 성능을 획기적으로 높일 수 있어 산업적 측면에서 파급 효과가 매우 클 것으로 기대한다ˮ 라고 말했다.
이번 연구에는 김 교수의 제자이자 현재 GraphAI(그래파이) 스타트업의 공동 창업자인 한동형 박사가 제1 저자로, 김 교수가 교신저자로 참여했으며 지난 16일 미국 필라델피아에서 열린 데이터베이스 분야 최고 국제학술대회 중 하나인 ACM SIGMOD에서 발표됐다. (논문명 : FuseME: Distributed Matrix Computation Engine based on Cuboid-based Fused Operator and Plan Generation).
한편, 이번 연구는 한국연구재단 선도연구센터 사업 및 중견연구자 지원사업, 과기정통부 IITP SW스타랩 사업의 지원을 받아 수행됐다.
2022.06.20
조회수 7453
-
 세계 최고 성능을 지닌 데이터베이스 관리 시스템(DBMS) 기술 개발
우리 연구진이 방대한 정보를 저장하고 목적에 맞게 검색, 관리할 수 있는 시스템을 통칭하는 데이터베이스관리시스템(DBMS, DataBase Management System)을 세계 최고 수준의 성능으로 끌어올렸다.
우리 대학 전산학부 김민수 교수 연구팀이 데이터베이스 질의 언어 SQL(Structured Query Language, 구조화 질의어) 처리 성능을 대폭 높인 세계 최고 수준의 DBMS 기술을 개발했다.
김 교수 연구팀은 데이터 처리를 위해 산업 표준으로 사용되는 SQL 질의를 기존 DBMS와는 전혀 다른 방법으로 처리함으로써 성능을 기존 옴니사이(OmniSci) DBMS 대비 최대 88배나 높인 신기술을 개발했다. 김 교수팀이 개발한 이 기술은 오라클·마이크로소프트 SQL서버·IBM DB2 등 타 DBMS에도 적용할 수 있어 고성능 SQL 질의 처리가 필요한 다양한 곳에 폭넓게 적용될 수 있을 것으로 기대된다.
대부분의 DBMS는 SQL 질의를 처리할 때 내부적으로 데이터 테이블들을 `왼쪽 깊은 이진 트리(left-deep binary tree)' 형태로 배치해 처리하는 방법을 사용한다. 지난 수십 년간 상용화돼 온 대부분의 DBMS는 데이터 테이블들의 배치 가능한 가지 수가 기하급수적으로 많기 때문에 이를 `왼쪽 깊은 이진 트리' 형태로 배치해 SQL 질의를 처리해 왔다.
임의의 두 테이블이 기본 키(primary key, PK)와 외래 키(foreign key, FK)라 불리는 관계로 결합(조인 연산)하는 경우에는 이러한 방법으로 SQL 질의를 효과적으로 처리할 수 있다. 여기서 기본 키는 각 데이터 행(row)을 유일하게 식별할 수 있는 열(column)이고, 외래 키는 그렇지 않은 열이다.
지난 수십 년간 산업에서 사용되는 DB의 구조가 점점 복잡해지면서 두 테이블은 PK-FK 관계가 아닌 FK-FK 관계, 즉 외래 키와 외래 키의 관계로 결합하는 복잡한 형태의 SQL 질의들이 많아지고 있다. 실제 DBMS의 성능을 측정하는 산업 표준 벤치마크인 TPC-DS에서 전체 벤치마크의 26%가 이런 복잡한 SQL 질의들로 구성돼 있고 기계학습(머신러닝), 생물 정보학 등 다양한 분야들서도 이러한 복잡한 SQL 질의 사용이 점차 증가하는 추세다.
이전에 나온 DBMS들은 두 테이블이 주로 PK-FK 관계로 결합한다는 가정하에 개발됐기 때문에 FK-FK 결합이 필요한 복잡한 SQL 질의를 매우 느리거나 심지어 처리하지 못하는 실패를 거듭해왔다.
김 교수팀은 문제 해결을 위해 테이블들을 하나의 커다란 `왼쪽 깊은 이진 트리' 형태가 아닌 여러 개의 작은 `왼쪽 깊은 이진 트리'를 `n항 조인 연산자'로 묶는 형태로 배치해 처리하는 기술을 개발했다. 이때 각각의 `작은 이진 트리' 안에는 FK-FK 결합 관계가 발생하지 않도록 테이블들을 배치하는 것이 핵심이다.
각각의 `작은 이진 트리'의 처리 결과물을 `n항 조인 연산자'로 결합해 최종 결과물을 구하는 것도 난제로 꼽히는데 연구팀은 `최악-최적(worst-case optimal) 조인 알고리즘'이라는 방법으로 이 문제를 해결했다.
`최악-최적 조인 알고리즘'은 그래프 데이터를 처리할 때 이론적으로 가장 우수하다고 알려진 알고리즘이다. 김 교수 연구팀은 세계에서 가장 먼저 이 알고리즘을 SQL 질의 처리에 적용해 난제를 해결하는 데 성공했다.
김민수 교수 연구팀은 새로 개발한 DBMS 기술을 GPU 기반의 DBMS 개발업체인 미국 옴니사이(OmniSci)社 제품에 적용한 결과, OmniSci DBMS보다 성능이 최대 88배나 향상된 결과를 얻었다. 또 TPC-DS 벤치마크에서도 세계 최고 수준의 성능을 가진 기존의 상용 DBMS보다 5~20배나 더 빠른 사실을 확인했다. TPC-DS는 DBMS의 성능을 측정하기 위한 산업 표준의 최신 벤치마크이다.
교신저자로 참여한 김민수 교수는 "연구팀이 개발한 새로운 기술은 대부분의 DBMS에 적용할 수 있기 때문에 산업적 측면에서 파급 효과가 매우 클 것으로 기대한다ˮ 라고 말했다.
이번 연구에는 김 교수의 제자이자 미국 옴니사이(OmniSci)社에 재직 중인 남윤민 박사가 제1 저자로, 김 교수가 교신저자로 참여했으며 지난 18일 미국 오리건주 포틀랜드에서 열린 데이터베이스 분야 최고의 국제학술대회로 꼽히는 `시그모드(SIGMOD)'에서 발표됐다. (논문명 : SPRINTER: A Fast n-ary Join Query Processing Method for Complex OLAP Queries).
한편, 이 연구는 한국연구재단 선도연구센터 사업 및 중견연구자 지원사업, 과기정통부 IITP SW스타랩 사업의 지원을 받아 수행됐다.
세계 최고 성능을 지닌 데이터베이스 관리 시스템(DBMS) 기술 개발
우리 연구진이 방대한 정보를 저장하고 목적에 맞게 검색, 관리할 수 있는 시스템을 통칭하는 데이터베이스관리시스템(DBMS, DataBase Management System)을 세계 최고 수준의 성능으로 끌어올렸다.
우리 대학 전산학부 김민수 교수 연구팀이 데이터베이스 질의 언어 SQL(Structured Query Language, 구조화 질의어) 처리 성능을 대폭 높인 세계 최고 수준의 DBMS 기술을 개발했다.
김 교수 연구팀은 데이터 처리를 위해 산업 표준으로 사용되는 SQL 질의를 기존 DBMS와는 전혀 다른 방법으로 처리함으로써 성능을 기존 옴니사이(OmniSci) DBMS 대비 최대 88배나 높인 신기술을 개발했다. 김 교수팀이 개발한 이 기술은 오라클·마이크로소프트 SQL서버·IBM DB2 등 타 DBMS에도 적용할 수 있어 고성능 SQL 질의 처리가 필요한 다양한 곳에 폭넓게 적용될 수 있을 것으로 기대된다.
대부분의 DBMS는 SQL 질의를 처리할 때 내부적으로 데이터 테이블들을 `왼쪽 깊은 이진 트리(left-deep binary tree)' 형태로 배치해 처리하는 방법을 사용한다. 지난 수십 년간 상용화돼 온 대부분의 DBMS는 데이터 테이블들의 배치 가능한 가지 수가 기하급수적으로 많기 때문에 이를 `왼쪽 깊은 이진 트리' 형태로 배치해 SQL 질의를 처리해 왔다.
임의의 두 테이블이 기본 키(primary key, PK)와 외래 키(foreign key, FK)라 불리는 관계로 결합(조인 연산)하는 경우에는 이러한 방법으로 SQL 질의를 효과적으로 처리할 수 있다. 여기서 기본 키는 각 데이터 행(row)을 유일하게 식별할 수 있는 열(column)이고, 외래 키는 그렇지 않은 열이다.
지난 수십 년간 산업에서 사용되는 DB의 구조가 점점 복잡해지면서 두 테이블은 PK-FK 관계가 아닌 FK-FK 관계, 즉 외래 키와 외래 키의 관계로 결합하는 복잡한 형태의 SQL 질의들이 많아지고 있다. 실제 DBMS의 성능을 측정하는 산업 표준 벤치마크인 TPC-DS에서 전체 벤치마크의 26%가 이런 복잡한 SQL 질의들로 구성돼 있고 기계학습(머신러닝), 생물 정보학 등 다양한 분야들서도 이러한 복잡한 SQL 질의 사용이 점차 증가하는 추세다.
이전에 나온 DBMS들은 두 테이블이 주로 PK-FK 관계로 결합한다는 가정하에 개발됐기 때문에 FK-FK 결합이 필요한 복잡한 SQL 질의를 매우 느리거나 심지어 처리하지 못하는 실패를 거듭해왔다.
김 교수팀은 문제 해결을 위해 테이블들을 하나의 커다란 `왼쪽 깊은 이진 트리' 형태가 아닌 여러 개의 작은 `왼쪽 깊은 이진 트리'를 `n항 조인 연산자'로 묶는 형태로 배치해 처리하는 기술을 개발했다. 이때 각각의 `작은 이진 트리' 안에는 FK-FK 결합 관계가 발생하지 않도록 테이블들을 배치하는 것이 핵심이다.
각각의 `작은 이진 트리'의 처리 결과물을 `n항 조인 연산자'로 결합해 최종 결과물을 구하는 것도 난제로 꼽히는데 연구팀은 `최악-최적(worst-case optimal) 조인 알고리즘'이라는 방법으로 이 문제를 해결했다.
`최악-최적 조인 알고리즘'은 그래프 데이터를 처리할 때 이론적으로 가장 우수하다고 알려진 알고리즘이다. 김 교수 연구팀은 세계에서 가장 먼저 이 알고리즘을 SQL 질의 처리에 적용해 난제를 해결하는 데 성공했다.
김민수 교수 연구팀은 새로 개발한 DBMS 기술을 GPU 기반의 DBMS 개발업체인 미국 옴니사이(OmniSci)社 제품에 적용한 결과, OmniSci DBMS보다 성능이 최대 88배나 향상된 결과를 얻었다. 또 TPC-DS 벤치마크에서도 세계 최고 수준의 성능을 가진 기존의 상용 DBMS보다 5~20배나 더 빠른 사실을 확인했다. TPC-DS는 DBMS의 성능을 측정하기 위한 산업 표준의 최신 벤치마크이다.
교신저자로 참여한 김민수 교수는 "연구팀이 개발한 새로운 기술은 대부분의 DBMS에 적용할 수 있기 때문에 산업적 측면에서 파급 효과가 매우 클 것으로 기대한다ˮ 라고 말했다.
이번 연구에는 김 교수의 제자이자 미국 옴니사이(OmniSci)社에 재직 중인 남윤민 박사가 제1 저자로, 김 교수가 교신저자로 참여했으며 지난 18일 미국 오리건주 포틀랜드에서 열린 데이터베이스 분야 최고의 국제학술대회로 꼽히는 `시그모드(SIGMOD)'에서 발표됐다. (논문명 : SPRINTER: A Fast n-ary Join Query Processing Method for Complex OLAP Queries).
한편, 이 연구는 한국연구재단 선도연구센터 사업 및 중견연구자 지원사업, 과기정통부 IITP SW스타랩 사업의 지원을 받아 수행됐다.
2020.06.23
조회수 20109