%EC%82%B0%EC%97%85%EB%B0%8F%EC%8B%9C%EC%8A%A4%ED%85%9C%EA%B3%B5%ED%95%99%EA%B3%BC
-
 대형언어모델로 42% 향상된 추천 기술 연구 개발
최근 소셜 미디어, 전자 상거래 플랫폼 등에서 소비자의 만족도를 높이는 다양한 추천서비스를 제공하고 있다. 그 중에서도 상품의 제목 및 설명과 같은 텍스트를 주입하여 상품 추천을 제공하는 대형언어모델(Large Language Model, LLM) 기반 기술이 각광을 받고 있다. 한국 연구진이 이런 대형언어모델 기반 추천 기술의 기존 한계를 극복하고 빠르고 최상의 추천을 해주는 시스템을 개발하여 화제다.
우리 대학 산업및시스템공학과 박찬영 교수 연구팀이 네이버와 공동연구를 통해 협업 필터링(Collaborative filtering) 기반 추천 모델이 학습한 사용자의 선호에 대한 정보를 추출하고 이를 상품의 텍스트와 함께 대형언어모델에 주입해 상품 추천의 높은 정확도를 달성할 수 있는 새로운 대형언어모델 기반 추천시스템 기술을 개발했다고 17일 밝혔다.
이번 연구는 기존 연구에 비해 학습 속도에서 253% 향상, 추론 속도에서 171% 향상, 상품 추천에서 평균 12%의 성능 향상을 이뤄냈다. 특히, 사용자의 소비 이력이 제한된 퓨샷(Few-shot) 상품* 추천에서 평균 20%의 성능 향상, 다중-도메인(Cross-domain) 상품 추천**에서 42%의 성능 향상을 이뤄냈다.
*퓨샷 상품: 사용자의 소비 이력이 풍부하지 않은 상품.
**다중-도메인 상품 추천: 타 도메인에서 학습된 모델을 활용하여 추가학습없이 현재 도메인에서 추천을 수행. 예를 들어, 의류 도메인에 추천 모델을 학습한 뒤, 도서 도메인에서 추천을 수행하는 상황을 일컫는다.
기존 대형언어모델을 활용한 추천 기술들은 사용자가 소비한 상품 이름들을 단순히 텍스트 형태로 나열해 대형언어모델에 주입하는 방식으로 추천을 진행했다. 예를 들어 ‘사용자가 영화 극한직업, 범죄도시1, 범죄도시2를 보았을 때 다음으로 시청할 영화는 무엇인가?’라고 대형언어모델에 질문하는 방식이었다.
이에 반해, 연구팀이 착안한 점은 상품 제목 및 설명과 같은 텍스트뿐 아니라 협업 필터링 지식, 즉, 사용자와 비슷한 상품을 소비한 다른 사용자들에 대한 정보가 정확한 상품 추천에 중요한 역할을 한다는 점이었다. 하지만, 이러한 정보를 단순히 텍스트화하기에는 한계가 존재한다. 이에 따라, 연구팀은 미리 학습된 협업 필터링 기반 추천 모델로부터 사용자의 선호에 대한 정보를 추출하고 이를 대형언어모델이 이해할 수 있도록 변환하는 경량화된 신경망을 도입했다.
연구팀이 개발한 기술의 특징으로는 대형언어모델의 추가적인 학습이 필요하지 않다는 점이다. 기존 연구들은 상품 추천을 목적으로 학습되지 않은 대형언어모델이 상품 추천이 가능하게 하도록 대형언어모델을 파인튜닝(Fine-tuning)* 하는 방법을 사용했다. 하지만, 이는 학습과 추론에 드는 시간을 급격히 증가시키므로 실제 서비스에서 대형언어모델을 추천에 활용하는 것에 큰 걸림돌이 된다. 이에 반해, 연구팀은 대형언어모델의 직접적인 학습 대신 경량화된 신경망의 학습을 통해 대형언어모델이 사용자의 선호를 이해할 수 있도록 했고, 이에 따라 기존 연구보다 빠른 학습 및 추론 속도를 달성했다.
*파인튜닝: 사전 학습된 대규모 언어모델을 특정 작업이나 데이터셋에 맞게 최적화하는 과정.
연구팀을 지도한 박찬영 교수는 “제안한 기술은 대형언어모델을 추천 문제에 해결하려는 기존 연구들이 간과한 사용자-상품 상호작용 정보를 전통적인 협업 필터링 모델에서 추출해 대형언어모델에 전달하는 새로운 방법으로 이는 대화형 추천 시스템이나 개인화 상품 정보 생성 등 다양한 고도화된 추천 서비스를 등장시킬 수 있을 것이며, 추천 도메인에 국한되지 않고 이미지, 텍스트, 사용자-상품 상호작용 정보를 모두 사용하는 진정한 멀티모달 추천 방법론으로 나아갈 수 있을 것”이라고 말했다.
우리 대학 산업및시스템공학과 김세인 박사과정 학생과 전산학부 강홍석 학사과정(졸) 학생이 공동 제1 저자, 네이버의 김동현 박사, 양민철 박사가 공동 저자, KAIST 산업및시스템공학과의 박찬영 교수가 교신저자로 참여한 이번 연구는 데이터마이닝 최고권위 국제학술대회인 ‘국제 데이터 마이닝 학회 ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD 2024)’에서 올 8월 발표할 예정이다. (논문명: Large Language Models meet Collaborative Filtering: An Efficient All-round LLM-based Recommender System).
한편 이번 연구는 네이버 및 정부(과학기술정보통신부)의 재원으로 한국연구재단의 지원을 받아 수행됐다. (NRF-2022M3J6A1063021, RS-2024-00335098)
2024.07.17 조회수 5762
대형언어모델로 42% 향상된 추천 기술 연구 개발
최근 소셜 미디어, 전자 상거래 플랫폼 등에서 소비자의 만족도를 높이는 다양한 추천서비스를 제공하고 있다. 그 중에서도 상품의 제목 및 설명과 같은 텍스트를 주입하여 상품 추천을 제공하는 대형언어모델(Large Language Model, LLM) 기반 기술이 각광을 받고 있다. 한국 연구진이 이런 대형언어모델 기반 추천 기술의 기존 한계를 극복하고 빠르고 최상의 추천을 해주는 시스템을 개발하여 화제다.
우리 대학 산업및시스템공학과 박찬영 교수 연구팀이 네이버와 공동연구를 통해 협업 필터링(Collaborative filtering) 기반 추천 모델이 학습한 사용자의 선호에 대한 정보를 추출하고 이를 상품의 텍스트와 함께 대형언어모델에 주입해 상품 추천의 높은 정확도를 달성할 수 있는 새로운 대형언어모델 기반 추천시스템 기술을 개발했다고 17일 밝혔다.
이번 연구는 기존 연구에 비해 학습 속도에서 253% 향상, 추론 속도에서 171% 향상, 상품 추천에서 평균 12%의 성능 향상을 이뤄냈다. 특히, 사용자의 소비 이력이 제한된 퓨샷(Few-shot) 상품* 추천에서 평균 20%의 성능 향상, 다중-도메인(Cross-domain) 상품 추천**에서 42%의 성능 향상을 이뤄냈다.
*퓨샷 상품: 사용자의 소비 이력이 풍부하지 않은 상품.
**다중-도메인 상품 추천: 타 도메인에서 학습된 모델을 활용하여 추가학습없이 현재 도메인에서 추천을 수행. 예를 들어, 의류 도메인에 추천 모델을 학습한 뒤, 도서 도메인에서 추천을 수행하는 상황을 일컫는다.
기존 대형언어모델을 활용한 추천 기술들은 사용자가 소비한 상품 이름들을 단순히 텍스트 형태로 나열해 대형언어모델에 주입하는 방식으로 추천을 진행했다. 예를 들어 ‘사용자가 영화 극한직업, 범죄도시1, 범죄도시2를 보았을 때 다음으로 시청할 영화는 무엇인가?’라고 대형언어모델에 질문하는 방식이었다.
이에 반해, 연구팀이 착안한 점은 상품 제목 및 설명과 같은 텍스트뿐 아니라 협업 필터링 지식, 즉, 사용자와 비슷한 상품을 소비한 다른 사용자들에 대한 정보가 정확한 상품 추천에 중요한 역할을 한다는 점이었다. 하지만, 이러한 정보를 단순히 텍스트화하기에는 한계가 존재한다. 이에 따라, 연구팀은 미리 학습된 협업 필터링 기반 추천 모델로부터 사용자의 선호에 대한 정보를 추출하고 이를 대형언어모델이 이해할 수 있도록 변환하는 경량화된 신경망을 도입했다.
연구팀이 개발한 기술의 특징으로는 대형언어모델의 추가적인 학습이 필요하지 않다는 점이다. 기존 연구들은 상품 추천을 목적으로 학습되지 않은 대형언어모델이 상품 추천이 가능하게 하도록 대형언어모델을 파인튜닝(Fine-tuning)* 하는 방법을 사용했다. 하지만, 이는 학습과 추론에 드는 시간을 급격히 증가시키므로 실제 서비스에서 대형언어모델을 추천에 활용하는 것에 큰 걸림돌이 된다. 이에 반해, 연구팀은 대형언어모델의 직접적인 학습 대신 경량화된 신경망의 학습을 통해 대형언어모델이 사용자의 선호를 이해할 수 있도록 했고, 이에 따라 기존 연구보다 빠른 학습 및 추론 속도를 달성했다.
*파인튜닝: 사전 학습된 대규모 언어모델을 특정 작업이나 데이터셋에 맞게 최적화하는 과정.
연구팀을 지도한 박찬영 교수는 “제안한 기술은 대형언어모델을 추천 문제에 해결하려는 기존 연구들이 간과한 사용자-상품 상호작용 정보를 전통적인 협업 필터링 모델에서 추출해 대형언어모델에 전달하는 새로운 방법으로 이는 대화형 추천 시스템이나 개인화 상품 정보 생성 등 다양한 고도화된 추천 서비스를 등장시킬 수 있을 것이며, 추천 도메인에 국한되지 않고 이미지, 텍스트, 사용자-상품 상호작용 정보를 모두 사용하는 진정한 멀티모달 추천 방법론으로 나아갈 수 있을 것”이라고 말했다.
우리 대학 산업및시스템공학과 김세인 박사과정 학생과 전산학부 강홍석 학사과정(졸) 학생이 공동 제1 저자, 네이버의 김동현 박사, 양민철 박사가 공동 저자, KAIST 산업및시스템공학과의 박찬영 교수가 교신저자로 참여한 이번 연구는 데이터마이닝 최고권위 국제학술대회인 ‘국제 데이터 마이닝 학회 ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD 2024)’에서 올 8월 발표할 예정이다. (논문명: Large Language Models meet Collaborative Filtering: An Efficient All-round LLM-based Recommender System).
한편 이번 연구는 네이버 및 정부(과학기술정보통신부)의 재원으로 한국연구재단의 지원을 받아 수행됐다. (NRF-2022M3J6A1063021, RS-2024-00335098)
2024.07.17 조회수 5762 -
 약물 부작용 및 용해도 예측 그래프 신경망 기술 개발
최근 화학, 생명과학 등 다양한 기초과학 분야의 문제를 해결하기 위해 그래프 신경망 (Graph Neural Network) 기술이 널리 활용되고 있다. 그 중에서도 특히 두 물질의 상호작용에 의해 발생하는 물리적 성질을 예측하는 것은 다양한 화학, 소재 및 의학 분야에서 각광을 받고 있다. 예를 들어, 어떠한 약물 (Drug)이 용매 (Solvent)에 얼마나 잘 용해되는지 정확히 예측하고, 동시에 여러 가지 약물을 투여하는 다중약물요법 (Polypharmacy)의 부작용을 예측하는 것이 신약 개발 등에 매우 중요하다.
우리 대학 산업및시스템공학과 박찬영 교수 연구팀이 한국화학연구원(원장 이영국)과 공동연구를 통해 물질 내의 중요한 하부 구조(Substructure)를 탐지하여 두 물질의 상호작용에 의해 발생하는 물리적 성질 예측의 높은 정확도를 달성할 수 있는 새로운 그래프 신경망 기법을 개발했다고 18일 밝혔다.
기존 연구에서는 두 분자 쌍이 있을 때, 각 분자내에 존재하는 원자들 사이의 상호 작용만을 고려해 그래프 신경망 모델을 학습하였다. 예를 들어 특정 발색체의 물(H2O)에 대한 용해도를 예측하고자 할 때, 발색체 내의 각 원자들에 대해 물 분자의 원자들 (즉, H, O)이 갖는 영향력을 고려하는 것이다. 연구팀이 이에 반해, 연구팀이 착안한 점은 분자 구조의 화학적 특성을 결정하는 데 있어서 원자뿐만 아니라 작용기(Functional group)와 같은 분자내 하부 구조들이 중요한 역할을 한다는 점이었다. 예를 들어, 알코올이나 예를 들어, 알코올이나 포도당과 같이 하이드록실기 (Hydroxyl group)를 포함하는 분자들은 일반적으로 물에 대한 용해도가 높은 것으로 알려져 있다. 즉, 하이드록실기라는 작용기가 물에 대한 용해도를 결정하는데 중요한 역할을 한다는 것이다.
연구팀은 분자의 특성을 결정하는데 큰 영향을 끼치는 하부 구조를 추론하는 기술을 분자내의 중요한 정보를 최대한 압축하여 보존하는 ‘정보 병목 이론’과, 분자 내의 어떤 하부 구조가 분자의 고유한 특성을 결정 짓는데 큰 역할을 했는지 대한 인과 관계를 추론하는 ‘인과 추론 모형’을 활용하여 개발했다. 이를 통해 분자의 고유한 특성에 가장 큰 영향을 미치는 하부 구조를 찾아내었다. 또한 분자 간 관계를 추론하는 문제에서는 상대방 분자에 따라 대상 분자의 중요한 하부 구조가 달라질 수 있다는 점을 착안하여 물질 간 관계를 예측하는 모델을 제안했다.
이번 새로운 그래프 신경망 기법을 의학에 적용하여 정보 병목 현상을 기반으로 한 연구는 기존 연구에 비해 약물 용해도 예측에서 11%의 성능 향상, 다중약물요법 부작용 예측에서 4%의 정확도 향상을 이뤄냈다. 또한, 인과 추론 모형을 기반으로 한 연구는 약물 용해도 예측에서 17%의 성능 향상, 약물 부작용 예측에서 2%의 정확도 향상을 이뤄냈다.
박찬영 교수팀은 정보 병목 이론을 기반으로 중요한 하부 구조를 탐지해 분자 구조 관계의 높은 예측 정확도를 달성할 수 있는 그래프 신경망 모델을 개발해 기계학습 분야 최고권위 국제학술대회 ‘국제 기계 학습 학회 International Conference on Machine Learning (ICML 2023)’에서 올 7월 발표할 예정이다. (논문명: Conditional Graph Information Bottleneck for Molecular Relational Learning). 또한 인과 추론 모형을 기반으로 중요한 하부 구조를 탐지해 분포 변화에도 모델의 성능이 강건하게 유지되는 그래프 신경망 모델을 개발해 데이터마이닝 최고권위 국제학술 대회 ‘국제 데이터 마이닝 학회 ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD 2023)’에서 올 8월에 발표할 예정이다. (논문명: Shift-Robust Molecular Relational Learning with Causal Substructure). 두 연구 모두 KAIST 산업및시스템공학과 대학원에 재학 중인 이남경 박사과정 학생이 제1 저자, 화학연구원의 나경석 연구원이 공동 저자, 우리 대학 산업및시스템공학과의 박찬영 교수가 교신저자로 참여했다.
두 연구의 제1 저자인 이남경 박사과정은 “제안한 기술은 분자의 성질을 결정하는 데 있어 큰 영향을 미치는 하부 구조가 존재한다는 화학적 지식에 기반해 그래프 신경망을 학습할 수 있는 새로운 방법”이라면서 “상대편 분자를 고려해 대상 분자의 중요한 구조를 찾는 방법론은 이미지-텍스트 멀티 모달 학습 방법에서도 적용될 수 있어, 심층 학습 전반적인 성능 개선에 기여할 수 있다”고 밝혔다.
연구팀을 지도한 박찬영 교수도 “제안한 기술은 화학과 생명과학을 포함한 다양한 분야에서 새로운 물질을 발견하는데 널리 사용될 것으로 기대하며, 특히 환경 친화적인 소재 개발, 질병 치료를 위한 신약 발굴 등에 있어서 본 기술의 가치가 더욱 부각될 것으로 보인다”라고 밝혔다.
한편 이번 연구는 정보통신기획평가원의 지원을 받은 사람중심 인공지능 핵심원천기술개발 사업과 한국화학연구원 기본사업 (KK2351-10)의 지원을 받아 수행됐다.
2023.07.18 조회수 9761
약물 부작용 및 용해도 예측 그래프 신경망 기술 개발
최근 화학, 생명과학 등 다양한 기초과학 분야의 문제를 해결하기 위해 그래프 신경망 (Graph Neural Network) 기술이 널리 활용되고 있다. 그 중에서도 특히 두 물질의 상호작용에 의해 발생하는 물리적 성질을 예측하는 것은 다양한 화학, 소재 및 의학 분야에서 각광을 받고 있다. 예를 들어, 어떠한 약물 (Drug)이 용매 (Solvent)에 얼마나 잘 용해되는지 정확히 예측하고, 동시에 여러 가지 약물을 투여하는 다중약물요법 (Polypharmacy)의 부작용을 예측하는 것이 신약 개발 등에 매우 중요하다.
우리 대학 산업및시스템공학과 박찬영 교수 연구팀이 한국화학연구원(원장 이영국)과 공동연구를 통해 물질 내의 중요한 하부 구조(Substructure)를 탐지하여 두 물질의 상호작용에 의해 발생하는 물리적 성질 예측의 높은 정확도를 달성할 수 있는 새로운 그래프 신경망 기법을 개발했다고 18일 밝혔다.
기존 연구에서는 두 분자 쌍이 있을 때, 각 분자내에 존재하는 원자들 사이의 상호 작용만을 고려해 그래프 신경망 모델을 학습하였다. 예를 들어 특정 발색체의 물(H2O)에 대한 용해도를 예측하고자 할 때, 발색체 내의 각 원자들에 대해 물 분자의 원자들 (즉, H, O)이 갖는 영향력을 고려하는 것이다. 연구팀이 이에 반해, 연구팀이 착안한 점은 분자 구조의 화학적 특성을 결정하는 데 있어서 원자뿐만 아니라 작용기(Functional group)와 같은 분자내 하부 구조들이 중요한 역할을 한다는 점이었다. 예를 들어, 알코올이나 예를 들어, 알코올이나 포도당과 같이 하이드록실기 (Hydroxyl group)를 포함하는 분자들은 일반적으로 물에 대한 용해도가 높은 것으로 알려져 있다. 즉, 하이드록실기라는 작용기가 물에 대한 용해도를 결정하는데 중요한 역할을 한다는 것이다.
연구팀은 분자의 특성을 결정하는데 큰 영향을 끼치는 하부 구조를 추론하는 기술을 분자내의 중요한 정보를 최대한 압축하여 보존하는 ‘정보 병목 이론’과, 분자 내의 어떤 하부 구조가 분자의 고유한 특성을 결정 짓는데 큰 역할을 했는지 대한 인과 관계를 추론하는 ‘인과 추론 모형’을 활용하여 개발했다. 이를 통해 분자의 고유한 특성에 가장 큰 영향을 미치는 하부 구조를 찾아내었다. 또한 분자 간 관계를 추론하는 문제에서는 상대방 분자에 따라 대상 분자의 중요한 하부 구조가 달라질 수 있다는 점을 착안하여 물질 간 관계를 예측하는 모델을 제안했다.
이번 새로운 그래프 신경망 기법을 의학에 적용하여 정보 병목 현상을 기반으로 한 연구는 기존 연구에 비해 약물 용해도 예측에서 11%의 성능 향상, 다중약물요법 부작용 예측에서 4%의 정확도 향상을 이뤄냈다. 또한, 인과 추론 모형을 기반으로 한 연구는 약물 용해도 예측에서 17%의 성능 향상, 약물 부작용 예측에서 2%의 정확도 향상을 이뤄냈다.
박찬영 교수팀은 정보 병목 이론을 기반으로 중요한 하부 구조를 탐지해 분자 구조 관계의 높은 예측 정확도를 달성할 수 있는 그래프 신경망 모델을 개발해 기계학습 분야 최고권위 국제학술대회 ‘국제 기계 학습 학회 International Conference on Machine Learning (ICML 2023)’에서 올 7월 발표할 예정이다. (논문명: Conditional Graph Information Bottleneck for Molecular Relational Learning). 또한 인과 추론 모형을 기반으로 중요한 하부 구조를 탐지해 분포 변화에도 모델의 성능이 강건하게 유지되는 그래프 신경망 모델을 개발해 데이터마이닝 최고권위 국제학술 대회 ‘국제 데이터 마이닝 학회 ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD 2023)’에서 올 8월에 발표할 예정이다. (논문명: Shift-Robust Molecular Relational Learning with Causal Substructure). 두 연구 모두 KAIST 산업및시스템공학과 대학원에 재학 중인 이남경 박사과정 학생이 제1 저자, 화학연구원의 나경석 연구원이 공동 저자, 우리 대학 산업및시스템공학과의 박찬영 교수가 교신저자로 참여했다.
두 연구의 제1 저자인 이남경 박사과정은 “제안한 기술은 분자의 성질을 결정하는 데 있어 큰 영향을 미치는 하부 구조가 존재한다는 화학적 지식에 기반해 그래프 신경망을 학습할 수 있는 새로운 방법”이라면서 “상대편 분자를 고려해 대상 분자의 중요한 구조를 찾는 방법론은 이미지-텍스트 멀티 모달 학습 방법에서도 적용될 수 있어, 심층 학습 전반적인 성능 개선에 기여할 수 있다”고 밝혔다.
연구팀을 지도한 박찬영 교수도 “제안한 기술은 화학과 생명과학을 포함한 다양한 분야에서 새로운 물질을 발견하는데 널리 사용될 것으로 기대하며, 특히 환경 친화적인 소재 개발, 질병 치료를 위한 신약 발굴 등에 있어서 본 기술의 가치가 더욱 부각될 것으로 보인다”라고 밝혔다.
한편 이번 연구는 정보통신기획평가원의 지원을 받은 사람중심 인공지능 핵심원천기술개발 사업과 한국화학연구원 기본사업 (KK2351-10)의 지원을 받아 수행됐다.
2023.07.18 조회수 9761 -
 레이블 없이 훈련 가능한 그래프 신경망 모델 기술 개발
최근 다양한 분야 (소셜 네트워크 분석, 추천시스템 등)에서 그래프 데이터 (그림 1) 의 중요성이 대두되고 있으며, 이에 따라 그래프 신경망(Graph Neural Network) 기술을 활용한 서비스가 급속히 증가하고 있다. 서비스 구축을 위해서는 심층 학습 모델을 훈련해야 하며, 이를 위해서는 충분한 훈련 데이터를 준비해야 한다. 특히 훈련 데이터에 정답지를 만드는 레이블링(labeling) 과정이 필요한데 (예를 들어, 소셜 네트워크의 특정 사용자에 `20대'라는 레이블을 부여하는 행위), 이 과정은 일반적으로 수작업으로 진행되므로 노동력과 시간이 소요된다. 따라서 그래프 신경망 모델 훈련 시 데이터가 충분하지 않은 상황을 효과적으로 타개하는 방법의 필요성이 대두되고 있다.
우리 대학 산업및시스템공학과 박찬영 교수 연구팀이 데이터의 레이블이 없는 상황에서도 높은 예측 정확도를 달성할 수 있는 새로운 그래프 신경망 모델 훈련 기술을 개발했다고 25일 밝혔다.
정점의 레이블이 없는 상황에서 그래프 신경망 모델의 훈련은 데이터 증강을 통해 생성된 정점들의 공통된 특성을 학습하는 과정으로 볼 수 있다. 하지만 이러한 정점의 공통된 특성을 학습하는 과정에서, 기존 훈련 방법은 표상 공간에서 자신을 제외한 다른 정점들과의 유사도가 작아지도록 훈련을 한다. 하지만 그래프 데이터가 정점들 사이의 관계를 나타내는 데이터 구조라는 점을 고려했을 때, 이런 일차원적인 방법론은 정점 간의 관계를 정확히 반영하지 못하게 된다.
박 교수팀이 개발한 기술은 그래프 신경망 모델에서 정점들 사이의 관계를 보존해 정점의 레이블이 없는 상황에서 모델을 훈련시켜 높은 예측 정확도를 달성할 수 있게 해준다.
KAIST 산업및시스템공학과 이남경 석사과정이 제1 저자, 현동민 박사, 이준석 석사과정 학생이 제2, 제3 저자로 참여한 이번 연구는 최고권위 국제학술대회 `정보지식관리 콘퍼런스(CIKM) 2022'에서 올 10월 발표될 예정이다. (논문명: Relational Self-Supervised Learning on Graphs)
기존 연구에서는 정점의 레이블이 없는 상황에서 정점에 대한 표상을 훈련하기 위해 표상 공간 내에서 자기 자신을 제외한 다른 정점들과의 유사도가 작아지도록 훈련을 한다. 예를 들어서, 소셜 네트워크에 A, B, C 라는 사용자가 존재할 때, A, B와 C가 표상 공간에서 서로 간의 유사도가 모두 작아지도록 모델을 훈련하는 것이다. 이때 박 교수팀이 착안한 점은 그래프 데이터가 정점 간의 관계를 나타내는 데이터이므로 정점 간의 관계를 포착하도록 정점의 표상을 훈련할 필요가 있다는 점이었다.
즉, A, B와 C 서로 간의 유사도가 모두 작아지게 하는 훈련 메커니즘과는 달리, 실제 그래프상에서는 이들이 연관이 있을 수 있다는 점이다. 따라서 A, B와 C 사이의 관계를 긍정/부정의 이진 분류를 통해 표상 공간에서 유사도가 작아지도록 훈련을 하는 것이 아닌, 이들의 관계를 정의해 그 관계를 보존하도록 학습하는 모델을 연구팀은 개발했다(그림 2). 연구팀은 정점 간의 관계를 기반으로 정점의 표상을 훈련함으로써, 기존 연구가 갖는 엄격한 규제들을 완화해 그래프 데이터를 더 유연하게 모델링했다.
연구팀은 이 학습 방법론을 `관계 보존 학습'이라고 명명했으며, 그래프 데이터 분석의 주요 문제(정점 분류, 간선 예측)에 적용했다(그림 3). 그 결과 최신 연구 방법론과 비교했을 때, 정점 분류 문제에서 최대 3% 예측 정확도를 향상했고, 간선 예측 문제에서 6%의 성능 향상, 다중 연결 네트워크 (Multiplex network)의 정점 분류 문제에서 3%의 성능 향상을 보였다.
제1 저자인 이남경 석사과정은 "이번 기술은 데이터의 레이블이 부재한 상황에서도 그래프 신경망을 학습할 수 있는 새로운 방법ˮ 이라면서 "그래프 기반의 데이터뿐만이 아닌 이미지 텍스트 음성 데이터 등에 폭넓게 적용될 수 있어, 심층 학습 전반적인 성능 개선에 기여할 수 있다ˮ고 밝혔다.
연구팀을 지도한 박찬영 교수도 "이번 기술은 그래프 데이터상에 레이블이 부재한 상황에서 표상 학습 모델을 훈련하는 기존 모델들의 단점들을 `관계 보존`이라는 개념을 통해 보완해 새로운 학습 패러다임을 제시하여 학계에 큰 파급효과를 낼 수 있다ˮ라고 말했다.
한편, 이번 연구는 과학기술정보통신부 재원으로 정보통신기획평가원의 지원을 받아 사람중심인공지능핵심원천기술개발 과제로 개발한 연구성과 결과물(No. 2022-0-00157, 강건하고 공정하며 확장 가능한 데이터 중심의 연속 학습)이다.
2022.10.25 조회수 8370
레이블 없이 훈련 가능한 그래프 신경망 모델 기술 개발
최근 다양한 분야 (소셜 네트워크 분석, 추천시스템 등)에서 그래프 데이터 (그림 1) 의 중요성이 대두되고 있으며, 이에 따라 그래프 신경망(Graph Neural Network) 기술을 활용한 서비스가 급속히 증가하고 있다. 서비스 구축을 위해서는 심층 학습 모델을 훈련해야 하며, 이를 위해서는 충분한 훈련 데이터를 준비해야 한다. 특히 훈련 데이터에 정답지를 만드는 레이블링(labeling) 과정이 필요한데 (예를 들어, 소셜 네트워크의 특정 사용자에 `20대'라는 레이블을 부여하는 행위), 이 과정은 일반적으로 수작업으로 진행되므로 노동력과 시간이 소요된다. 따라서 그래프 신경망 모델 훈련 시 데이터가 충분하지 않은 상황을 효과적으로 타개하는 방법의 필요성이 대두되고 있다.
우리 대학 산업및시스템공학과 박찬영 교수 연구팀이 데이터의 레이블이 없는 상황에서도 높은 예측 정확도를 달성할 수 있는 새로운 그래프 신경망 모델 훈련 기술을 개발했다고 25일 밝혔다.
정점의 레이블이 없는 상황에서 그래프 신경망 모델의 훈련은 데이터 증강을 통해 생성된 정점들의 공통된 특성을 학습하는 과정으로 볼 수 있다. 하지만 이러한 정점의 공통된 특성을 학습하는 과정에서, 기존 훈련 방법은 표상 공간에서 자신을 제외한 다른 정점들과의 유사도가 작아지도록 훈련을 한다. 하지만 그래프 데이터가 정점들 사이의 관계를 나타내는 데이터 구조라는 점을 고려했을 때, 이런 일차원적인 방법론은 정점 간의 관계를 정확히 반영하지 못하게 된다.
박 교수팀이 개발한 기술은 그래프 신경망 모델에서 정점들 사이의 관계를 보존해 정점의 레이블이 없는 상황에서 모델을 훈련시켜 높은 예측 정확도를 달성할 수 있게 해준다.
KAIST 산업및시스템공학과 이남경 석사과정이 제1 저자, 현동민 박사, 이준석 석사과정 학생이 제2, 제3 저자로 참여한 이번 연구는 최고권위 국제학술대회 `정보지식관리 콘퍼런스(CIKM) 2022'에서 올 10월 발표될 예정이다. (논문명: Relational Self-Supervised Learning on Graphs)
기존 연구에서는 정점의 레이블이 없는 상황에서 정점에 대한 표상을 훈련하기 위해 표상 공간 내에서 자기 자신을 제외한 다른 정점들과의 유사도가 작아지도록 훈련을 한다. 예를 들어서, 소셜 네트워크에 A, B, C 라는 사용자가 존재할 때, A, B와 C가 표상 공간에서 서로 간의 유사도가 모두 작아지도록 모델을 훈련하는 것이다. 이때 박 교수팀이 착안한 점은 그래프 데이터가 정점 간의 관계를 나타내는 데이터이므로 정점 간의 관계를 포착하도록 정점의 표상을 훈련할 필요가 있다는 점이었다.
즉, A, B와 C 서로 간의 유사도가 모두 작아지게 하는 훈련 메커니즘과는 달리, 실제 그래프상에서는 이들이 연관이 있을 수 있다는 점이다. 따라서 A, B와 C 사이의 관계를 긍정/부정의 이진 분류를 통해 표상 공간에서 유사도가 작아지도록 훈련을 하는 것이 아닌, 이들의 관계를 정의해 그 관계를 보존하도록 학습하는 모델을 연구팀은 개발했다(그림 2). 연구팀은 정점 간의 관계를 기반으로 정점의 표상을 훈련함으로써, 기존 연구가 갖는 엄격한 규제들을 완화해 그래프 데이터를 더 유연하게 모델링했다.
연구팀은 이 학습 방법론을 `관계 보존 학습'이라고 명명했으며, 그래프 데이터 분석의 주요 문제(정점 분류, 간선 예측)에 적용했다(그림 3). 그 결과 최신 연구 방법론과 비교했을 때, 정점 분류 문제에서 최대 3% 예측 정확도를 향상했고, 간선 예측 문제에서 6%의 성능 향상, 다중 연결 네트워크 (Multiplex network)의 정점 분류 문제에서 3%의 성능 향상을 보였다.
제1 저자인 이남경 석사과정은 "이번 기술은 데이터의 레이블이 부재한 상황에서도 그래프 신경망을 학습할 수 있는 새로운 방법ˮ 이라면서 "그래프 기반의 데이터뿐만이 아닌 이미지 텍스트 음성 데이터 등에 폭넓게 적용될 수 있어, 심층 학습 전반적인 성능 개선에 기여할 수 있다ˮ고 밝혔다.
연구팀을 지도한 박찬영 교수도 "이번 기술은 그래프 데이터상에 레이블이 부재한 상황에서 표상 학습 모델을 훈련하는 기존 모델들의 단점들을 `관계 보존`이라는 개념을 통해 보완해 새로운 학습 패러다임을 제시하여 학계에 큰 파급효과를 낼 수 있다ˮ라고 말했다.
한편, 이번 연구는 과학기술정보통신부 재원으로 정보통신기획평가원의 지원을 받아 사람중심인공지능핵심원천기술개발 과제로 개발한 연구성과 결과물(No. 2022-0-00157, 강건하고 공정하며 확장 가능한 데이터 중심의 연속 학습)이다.
2022.10.25 조회수 8370 -
 코로나19 해외유입 확진자 수 예측 기술 개발
최근 전 세계적으로 코로나바이러스감염증-19(COVID-19) 확진자 수가 2,000만 명을 넘어선 가운데 최근 국내에서도 코로나19 확진자 수가 급증해 2차 대유행 조짐을 보이면서 정부는 8월 23일부터 전국 대상으로 사회적 거리두기 단계를 2단계로 격상해 시행 중이다.
중앙재난안전대책본부(중대본)에 따르면 국내 코로나 누적 확진자 수는 8월 23일 오전 0시 기준으로 총 1만7,399명이다. 이 중 해외유입 감염자 수는 2,716명(8월 22일 오전 0시 기준)으로 전체 확진자의 약 16%를 차지한다. 대륙별로 보면 아시아(중국 외), 미주, 유럽, 아프리카 순이다. 지난 14일 이후 국내 지역 발생 신규확진자 수가 급증하고 있지만 향후 해외유입 확진자 수의 확산추세 또한 결코 장담할 수 없는 상황이다.
이런 가운데 우리 연구진이 해외유입 확진자 수를 예측할 수 있는 관련 기술을 개발했다. 우리 대학 산업및시스템공학과 이재길 교수 연구팀이 코로나19 해외유입 확진자 수를 예측하는 빅데이터‧인공지능(AI) 기술을 개발했다고 19일 밝혔다.
이재길 교수 연구팀이 개발한 이 기술은 해외 각국의 확진자 수와 사망자 수, 해외 각국에서의 코로나19 관련 키워드 검색빈도와 한국으로의 일일 항공편 수, 그리고 해외 각국에서 한국으로의 로밍 고객 입국자 수 등 빅 데이터에 인공지능(AI) 기술을 적용해 향후 2주간의 해외유입 확진자 수를 예측한다.
코로나19 확진자 수가 급증할수록 해외유입에 의한 지역사회 확산의 위험성도 항상 뒤따르기 마련이다. 이에 따라 이재길 교수 연구팀이 개발한 정확한 해외유입 확진자 수 예측기술은 방역 시설 및 격리 시설 확충, 고위험 국가 입국자 관리 정책 등에 폭넓게 응용 및 적용될 수 있을 것으로 기대가 크다.
우리 대학 지식서비스공학대학원에 재학 중인 김민석 박사과정 학생이 제1 저자로, 강준혁, 김도영, 송환준, 민향숙, 남영은, 박동민 학생이 제2~제7 저자로 각각 참여한 이번 연구는 최고권위 국제 학술대회 'ACM KDD 2020'의 'AI for COVID-19' 세션에서 오는 24일 발표된다. (논문명 : Hi-COVIDNet: Deep Learning Approach to Predict Inbound COVID-19 Patients and Case Study in South Korea)
해외유입 확진자 수는 다양한 요인에 의해서 영향을 받는다. 일반적으로 해외 각국에서의 코로나19 위험도와 비례하며, 해외 각국에서 한국으로의 입국자 수와도 비례한다. 그러나 코로나19 위험도와 입국자 수를 실시간으로 알아내기에는 많은 제약이 따르므로 연구진은 쉽게 구할 수 있는 종류의 빅데이터를 기반으로 하는 인공지능(AI) 모델을 구축하는 데 성공했다.
연구진은 기본적으로 해외 각국의 코로나19 위험도를 산출할 때, 보고된 확진자 수와 사망자 수를 활용했다. 그러나 이러한 수치는 진단검사 수에 좌우되기 때문에 코로나19 관련 키워드 검색빈도를 같이 입력 데이터로 활용해 해당 국가의 코로나19 위험도를 실시간으로 산출했다.
이와 함께 실시간 입국자 수는 기밀정보로서 외부에 공개되지 않기 때문에 매일 제공되는 한국에 도착하는 항공편수와 로밍 고객 입국자 수를 통해 이를 유추해냈다. 로밍 고객 입국자 수 데이터는 KT로부터 제공 받았지만 KT 고객 입국자만을 포함한다는 한계를 일일 항공편수를 함께 고려함으로써 이 문제를 해소했다.
이밖에 해외유입 확진자 수 예측을 위해서는 국가 간의 지리적 연관성도 매우 중요하게 고려해야 한다. 어느 특정 국가의 코로나19 발병이 이웃 국가로 더 쉽게 전파되며, 국가 간의 교류도 거리에 따라 영향을 받기 때문이다. 연구팀은 이러한 문제해결을 위해 지리적 연관성을 학습하도록 국가-대륙으로 구성되는 지리적 계층구조에 따라 우선 각 대륙으로부터의 해외유입 확진자 수를 정확히 예측함으로써 궁극적으로 전체 해외유입 확진자 수를 정확히 예측하도록 하는 인공지능(AI) 모델을 설계했다. 연구팀은 이 인공지능 모델을 'Hi-COVIDNet'라고 이름 붙였다.
이후 연구팀은 약 한 달 반에 걸친 단기간의 훈련 데이터만으로 생성된 `Hi-COVIDNet'을 통해 향후 2주 동안의 해외유입 확진자 수를 예측한 결과, 이 모델이 기존의 시계열 데이터기반의 예측 기계학습이나 딥러닝 기반의 모델과 비교했을 때 최대 35% 더 높은 정확성을 지니고 있음을 확인했다.
제1 저자인 김민석 박사과정 학생은 "이번 연구는 최신 AI 기술을 코로나19 방역에 적용할 수 있음을 보여준 사례ˮ 라면서 "K-방역의 위상을 높이는데 기여할 것으로 기대한다ˮ 고 밝혔다.
이번 연구는 KAIST 글로벌전략연구소(소장 김정호)의 코로나19 AI 태스크포스팀의 지원을 받았고, KT(담당 변형균 상무)와 과학기술정보통신부(담당 김수정 서기관)의 '코로나19 확산예측 연구 얼라이언스'를 통해 로밍 데이터 세트를 지원받아 이뤄졌다.
2020.08.23 조회수 39048
코로나19 해외유입 확진자 수 예측 기술 개발
최근 전 세계적으로 코로나바이러스감염증-19(COVID-19) 확진자 수가 2,000만 명을 넘어선 가운데 최근 국내에서도 코로나19 확진자 수가 급증해 2차 대유행 조짐을 보이면서 정부는 8월 23일부터 전국 대상으로 사회적 거리두기 단계를 2단계로 격상해 시행 중이다.
중앙재난안전대책본부(중대본)에 따르면 국내 코로나 누적 확진자 수는 8월 23일 오전 0시 기준으로 총 1만7,399명이다. 이 중 해외유입 감염자 수는 2,716명(8월 22일 오전 0시 기준)으로 전체 확진자의 약 16%를 차지한다. 대륙별로 보면 아시아(중국 외), 미주, 유럽, 아프리카 순이다. 지난 14일 이후 국내 지역 발생 신규확진자 수가 급증하고 있지만 향후 해외유입 확진자 수의 확산추세 또한 결코 장담할 수 없는 상황이다.
이런 가운데 우리 연구진이 해외유입 확진자 수를 예측할 수 있는 관련 기술을 개발했다. 우리 대학 산업및시스템공학과 이재길 교수 연구팀이 코로나19 해외유입 확진자 수를 예측하는 빅데이터‧인공지능(AI) 기술을 개발했다고 19일 밝혔다.
이재길 교수 연구팀이 개발한 이 기술은 해외 각국의 확진자 수와 사망자 수, 해외 각국에서의 코로나19 관련 키워드 검색빈도와 한국으로의 일일 항공편 수, 그리고 해외 각국에서 한국으로의 로밍 고객 입국자 수 등 빅 데이터에 인공지능(AI) 기술을 적용해 향후 2주간의 해외유입 확진자 수를 예측한다.
코로나19 확진자 수가 급증할수록 해외유입에 의한 지역사회 확산의 위험성도 항상 뒤따르기 마련이다. 이에 따라 이재길 교수 연구팀이 개발한 정확한 해외유입 확진자 수 예측기술은 방역 시설 및 격리 시설 확충, 고위험 국가 입국자 관리 정책 등에 폭넓게 응용 및 적용될 수 있을 것으로 기대가 크다.
우리 대학 지식서비스공학대학원에 재학 중인 김민석 박사과정 학생이 제1 저자로, 강준혁, 김도영, 송환준, 민향숙, 남영은, 박동민 학생이 제2~제7 저자로 각각 참여한 이번 연구는 최고권위 국제 학술대회 'ACM KDD 2020'의 'AI for COVID-19' 세션에서 오는 24일 발표된다. (논문명 : Hi-COVIDNet: Deep Learning Approach to Predict Inbound COVID-19 Patients and Case Study in South Korea)
해외유입 확진자 수는 다양한 요인에 의해서 영향을 받는다. 일반적으로 해외 각국에서의 코로나19 위험도와 비례하며, 해외 각국에서 한국으로의 입국자 수와도 비례한다. 그러나 코로나19 위험도와 입국자 수를 실시간으로 알아내기에는 많은 제약이 따르므로 연구진은 쉽게 구할 수 있는 종류의 빅데이터를 기반으로 하는 인공지능(AI) 모델을 구축하는 데 성공했다.
연구진은 기본적으로 해외 각국의 코로나19 위험도를 산출할 때, 보고된 확진자 수와 사망자 수를 활용했다. 그러나 이러한 수치는 진단검사 수에 좌우되기 때문에 코로나19 관련 키워드 검색빈도를 같이 입력 데이터로 활용해 해당 국가의 코로나19 위험도를 실시간으로 산출했다.
이와 함께 실시간 입국자 수는 기밀정보로서 외부에 공개되지 않기 때문에 매일 제공되는 한국에 도착하는 항공편수와 로밍 고객 입국자 수를 통해 이를 유추해냈다. 로밍 고객 입국자 수 데이터는 KT로부터 제공 받았지만 KT 고객 입국자만을 포함한다는 한계를 일일 항공편수를 함께 고려함으로써 이 문제를 해소했다.
이밖에 해외유입 확진자 수 예측을 위해서는 국가 간의 지리적 연관성도 매우 중요하게 고려해야 한다. 어느 특정 국가의 코로나19 발병이 이웃 국가로 더 쉽게 전파되며, 국가 간의 교류도 거리에 따라 영향을 받기 때문이다. 연구팀은 이러한 문제해결을 위해 지리적 연관성을 학습하도록 국가-대륙으로 구성되는 지리적 계층구조에 따라 우선 각 대륙으로부터의 해외유입 확진자 수를 정확히 예측함으로써 궁극적으로 전체 해외유입 확진자 수를 정확히 예측하도록 하는 인공지능(AI) 모델을 설계했다. 연구팀은 이 인공지능 모델을 'Hi-COVIDNet'라고 이름 붙였다.
이후 연구팀은 약 한 달 반에 걸친 단기간의 훈련 데이터만으로 생성된 `Hi-COVIDNet'을 통해 향후 2주 동안의 해외유입 확진자 수를 예측한 결과, 이 모델이 기존의 시계열 데이터기반의 예측 기계학습이나 딥러닝 기반의 모델과 비교했을 때 최대 35% 더 높은 정확성을 지니고 있음을 확인했다.
제1 저자인 김민석 박사과정 학생은 "이번 연구는 최신 AI 기술을 코로나19 방역에 적용할 수 있음을 보여준 사례ˮ 라면서 "K-방역의 위상을 높이는데 기여할 것으로 기대한다ˮ 고 밝혔다.
이번 연구는 KAIST 글로벌전략연구소(소장 김정호)의 코로나19 AI 태스크포스팀의 지원을 받았고, KT(담당 변형균 상무)와 과학기술정보통신부(담당 김수정 서기관)의 '코로나19 확산예측 연구 얼라이언스'를 통해 로밍 데이터 세트를 지원받아 이뤄졌다.
2020.08.23 조회수 39048 -
 장영재 교수, 스마트 팩토리 교육 노하우 국내 IT 기업에 기술 이전
우리 대학 산업및시스템공학과 장영재 교수가 최근 레고 기반 '스마트 팩토리' 교육 노하우를 국내 제조 IT 전문기업 큐빅테크에 기술이전 했다.
그동안 현대중공업, LG전자, 한국타이어 등 기업과의 산학협력을 통한 기술 활용이나 이탈리아 밀란 폴리텍, 독일 하노버 대학 등 같은 교육기관 간에 기술 이전을 시행한 선례는 있으나 우리 대학의 창의 수업을 기업에 기술이전 한 사례로서는 최초다.
'제조 프로세스 혁신 (IE251)'은 산업및시스템공학과 학부생들의 필수 교과목 중 하나로 스마트팩토리의 모형을 레고로 만들어 학생들이 직접 설계, 제작해 시연까지 하는 것이 특징이다.
장영재 교수 연구팀은 스마트 팩토리의 기술적 바탕은 물론 국내 제조 현실을 반영해 실제로 응용할 수 있게 커리큘럼을 구성했다. 또한, 관련 하드웨어 및 소프트웨어도 함께 개발했으며 제조 수업에서 한 단계 나아가 학부 AI 과목에도 활용하고 있다.
장영재 교수의 연구 내용은 국제 학술지인 『Engineering Education Journal』 에도 게재되었으며 글로벌 소프트웨어 기업인 매스웍스(Mathworks) 교육혁신 Grant Award도 수상한 바 있다.
참고 동영상 바로 보기 => ( https://www.youtube.com/watch?v=_-s_pwGoqr4&feature=youtu.be )
2019.11.29 조회수 13627
장영재 교수, 스마트 팩토리 교육 노하우 국내 IT 기업에 기술 이전
우리 대학 산업및시스템공학과 장영재 교수가 최근 레고 기반 '스마트 팩토리' 교육 노하우를 국내 제조 IT 전문기업 큐빅테크에 기술이전 했다.
그동안 현대중공업, LG전자, 한국타이어 등 기업과의 산학협력을 통한 기술 활용이나 이탈리아 밀란 폴리텍, 독일 하노버 대학 등 같은 교육기관 간에 기술 이전을 시행한 선례는 있으나 우리 대학의 창의 수업을 기업에 기술이전 한 사례로서는 최초다.
'제조 프로세스 혁신 (IE251)'은 산업및시스템공학과 학부생들의 필수 교과목 중 하나로 스마트팩토리의 모형을 레고로 만들어 학생들이 직접 설계, 제작해 시연까지 하는 것이 특징이다.
장영재 교수 연구팀은 스마트 팩토리의 기술적 바탕은 물론 국내 제조 현실을 반영해 실제로 응용할 수 있게 커리큘럼을 구성했다. 또한, 관련 하드웨어 및 소프트웨어도 함께 개발했으며 제조 수업에서 한 단계 나아가 학부 AI 과목에도 활용하고 있다.
장영재 교수의 연구 내용은 국제 학술지인 『Engineering Education Journal』 에도 게재되었으며 글로벌 소프트웨어 기업인 매스웍스(Mathworks) 교육혁신 Grant Award도 수상한 바 있다.
참고 동영상 바로 보기 => ( https://www.youtube.com/watch?v=_-s_pwGoqr4&feature=youtu.be )
2019.11.29 조회수 13627 -
 김희영 교수, 반도체 기판 내 불량칩 탐지, 군집화 기술 개발
〈 이영민 박사과정, 김희영 교수, 김진호 석사 〉
우리 대학 산업및시스템공학과 김희영 교수 연구팀이 반도체 기판 내 여러 형태의 혼합된 불량 칩 패턴을 효과적으로 탐지하고 군집화하는 기술을 개발했다.
이번 연구 결과는 산업공학 분야 저명 국제 학술지 ‘IISE Transactions’ 2월호에 게재됐다. 특히 이 논문은 특집 기사(featured article)로 선정돼 ‘ISE(Industrial and Systems Engineering)’ 매거진 1월호에도 게재됐다.
반도체 기판 제조공정은 기판 표면에 집적회로를 형성하는 복잡한 일련의 공정을 통해 구성된다. 기판 가공이 끝나면 기판 내 각 칩의 불량 여부를 테스트하는 과정을 거친다.
이 때 불량칩은 공정 이상 원인에 따라 특정한 패턴(예 : 원, 링, 스크래치 등)을 보이며 분포한다고 알려져 있다. 불량칩의 분포 패턴을 분석하는 것은 공정 이상을 탐지하고 그 원인을 파악하는데 중요한 단서를 제공한다.
최근 반도체 제조 공정이 점점 복잡해짐에 따라 한 기판 안에 여러 형태의 불량칩 패턴이 혼재되는 사례가 증가하고 있다. 연구팀은 다수의 불량칩 패턴을 효과적으로 파악하기 위해 일정 패턴을 형성하고 있는 불량칩을 선택한 후 여러 개의 특정 패턴으로 군집화하는 방법을 제시했다.
연구팀은 무작위 분포가 아닌 특정 패턴을 형성하고 있는 불량칩을 효과적으로 탐지할 수 있는 CPF(connected-path filtering) 기술을 개발했다. CPF는 특히 스크래치 형태로 분포된 불량칩 탐지에 탁월한 성능 향상을 보였다.
탐지한 불량칩을 다수의 패턴별로 군집화하는 과정에서는 사전에 서로 다른 몇 개의 패턴이 혼재됐는지 알지 못한다는 점과 각 패턴이 복잡한 모양을 가진다는 점이 어려움으로 남아 있었다. 이를 해결하기 위해 연구팀은 무한 비선형 혼합 모형(infinite warped mixture model)을 이용함으로써 군집화 과정에서 데이터가 스스로 군집 수를 결정할 수 있도록 했다.
또한 복잡한 모양의 패턴을 바로 이용하는 대신 은닉 공간(latent space)에서의 단순한 모양의 패턴을 이용해 보다 효과적으로 군집화하는 데 성공했다.
연구팀은 SK 하이닉스의 실제 반도체 데이터를 활용해 제안된 방법을 검증함으로써 실제 반도체 제조 현장 문제를 효과적으로 해결할 수 있음을 확인했다.
이번 연구에 1저자로 참여한 김진호 석사졸업생은 SK 하이닉스의 수학 파견 인원으로 선발돼 석사과정 동안 2저자인 이영민 박사과정과 공동 연구를 수행했다. 김진호 졸업생은 현재 SK 하이닉스 수석 엔지니어로 근무하고 있으며 Alius TEST 기술팀을 이끌고 있다.
□ 그림 설명
그림1. CPF 적용 전, 후 결과
그림2. 여러형태의 혼합된 불량칩 패턴과 각 특정 패턴으로 군집화된 불량칩 패턴
2018.06.12 조회수 15354
김희영 교수, 반도체 기판 내 불량칩 탐지, 군집화 기술 개발
〈 이영민 박사과정, 김희영 교수, 김진호 석사 〉
우리 대학 산업및시스템공학과 김희영 교수 연구팀이 반도체 기판 내 여러 형태의 혼합된 불량 칩 패턴을 효과적으로 탐지하고 군집화하는 기술을 개발했다.
이번 연구 결과는 산업공학 분야 저명 국제 학술지 ‘IISE Transactions’ 2월호에 게재됐다. 특히 이 논문은 특집 기사(featured article)로 선정돼 ‘ISE(Industrial and Systems Engineering)’ 매거진 1월호에도 게재됐다.
반도체 기판 제조공정은 기판 표면에 집적회로를 형성하는 복잡한 일련의 공정을 통해 구성된다. 기판 가공이 끝나면 기판 내 각 칩의 불량 여부를 테스트하는 과정을 거친다.
이 때 불량칩은 공정 이상 원인에 따라 특정한 패턴(예 : 원, 링, 스크래치 등)을 보이며 분포한다고 알려져 있다. 불량칩의 분포 패턴을 분석하는 것은 공정 이상을 탐지하고 그 원인을 파악하는데 중요한 단서를 제공한다.
최근 반도체 제조 공정이 점점 복잡해짐에 따라 한 기판 안에 여러 형태의 불량칩 패턴이 혼재되는 사례가 증가하고 있다. 연구팀은 다수의 불량칩 패턴을 효과적으로 파악하기 위해 일정 패턴을 형성하고 있는 불량칩을 선택한 후 여러 개의 특정 패턴으로 군집화하는 방법을 제시했다.
연구팀은 무작위 분포가 아닌 특정 패턴을 형성하고 있는 불량칩을 효과적으로 탐지할 수 있는 CPF(connected-path filtering) 기술을 개발했다. CPF는 특히 스크래치 형태로 분포된 불량칩 탐지에 탁월한 성능 향상을 보였다.
탐지한 불량칩을 다수의 패턴별로 군집화하는 과정에서는 사전에 서로 다른 몇 개의 패턴이 혼재됐는지 알지 못한다는 점과 각 패턴이 복잡한 모양을 가진다는 점이 어려움으로 남아 있었다. 이를 해결하기 위해 연구팀은 무한 비선형 혼합 모형(infinite warped mixture model)을 이용함으로써 군집화 과정에서 데이터가 스스로 군집 수를 결정할 수 있도록 했다.
또한 복잡한 모양의 패턴을 바로 이용하는 대신 은닉 공간(latent space)에서의 단순한 모양의 패턴을 이용해 보다 효과적으로 군집화하는 데 성공했다.
연구팀은 SK 하이닉스의 실제 반도체 데이터를 활용해 제안된 방법을 검증함으로써 실제 반도체 제조 현장 문제를 효과적으로 해결할 수 있음을 확인했다.
이번 연구에 1저자로 참여한 김진호 석사졸업생은 SK 하이닉스의 수학 파견 인원으로 선발돼 석사과정 동안 2저자인 이영민 박사과정과 공동 연구를 수행했다. 김진호 졸업생은 현재 SK 하이닉스 수석 엔지니어로 근무하고 있으며 Alius TEST 기술팀을 이끌고 있다.
□ 그림 설명
그림1. CPF 적용 전, 후 결과
그림2. 여러형태의 혼합된 불량칩 패턴과 각 특정 패턴으로 군집화된 불량칩 패턴
2018.06.12 조회수 15354 -
 이재길 교수 연구팀 연구성과 Microsoft Research 블로그 게재
<이재길 교수, 송환준 박사과정>
우리대학 이재길 교수(산업및시스템공학과 지식서비스공학대학원)와 송환준 박사과정 학생의 최신 빅데이터 연구결과가 최근 Microsoft Research 블로그에 실렸다. Microsoft Research는 매 분기 자사의 지원을 받은 연구과제 중에서 대표적인 성과를 선정해 자사 블로그에 게시하고 있는데 이번에는 이재길 교수 연구팀의 연구결과가 그 중 하나로 선정된 것이다.
이교수 연구팀은 이번 연구를 통해 전통적인 데이터 군집화 알고리즘인 k-메도이드의 분산 병렬처리 알고리즘을 개발했다. 그동안 빅데이터의 처리 속도를 높이기 위해 결과 정확도를 다소 희생하는 것이 일반적인 관례였으나 이 교수팀은 이번 연구를 통해 정확도를 거의 잃지 않고 현존하는 타 알고리즘보다 높은 성능을 달성했다고 밝혔다.
이번 연구결과는 지난 8월 열린 데이터 마이닝 분야 최고 학술대회인 ACM KDD 2017에서 발표된바 있다. 이 교수는 "추가적인 군집화 알고리즘의 연구도 마무리해 아파치 스파크 오픈소스 플랫폼에 연 성과를 탑재시킬 것"이라고 향후 계획을 밝혔다.
블로그 게시물 : https://www.microsoft.com/en-us/research/lab/microsoft-research-asia/articles/using-microsoft-azure-research-tool-scalable-data-mining-2/
2017.10.16 조회수 13788
이재길 교수 연구팀 연구성과 Microsoft Research 블로그 게재
<이재길 교수, 송환준 박사과정>
우리대학 이재길 교수(산업및시스템공학과 지식서비스공학대학원)와 송환준 박사과정 학생의 최신 빅데이터 연구결과가 최근 Microsoft Research 블로그에 실렸다. Microsoft Research는 매 분기 자사의 지원을 받은 연구과제 중에서 대표적인 성과를 선정해 자사 블로그에 게시하고 있는데 이번에는 이재길 교수 연구팀의 연구결과가 그 중 하나로 선정된 것이다.
이교수 연구팀은 이번 연구를 통해 전통적인 데이터 군집화 알고리즘인 k-메도이드의 분산 병렬처리 알고리즘을 개발했다. 그동안 빅데이터의 처리 속도를 높이기 위해 결과 정확도를 다소 희생하는 것이 일반적인 관례였으나 이 교수팀은 이번 연구를 통해 정확도를 거의 잃지 않고 현존하는 타 알고리즘보다 높은 성능을 달성했다고 밝혔다.
이번 연구결과는 지난 8월 열린 데이터 마이닝 분야 최고 학술대회인 ACM KDD 2017에서 발표된바 있다. 이 교수는 "추가적인 군집화 알고리즘의 연구도 마무리해 아파치 스파크 오픈소스 플랫폼에 연 성과를 탑재시킬 것"이라고 향후 계획을 밝혔다.
블로그 게시물 : https://www.microsoft.com/en-us/research/lab/microsoft-research-asia/articles/using-microsoft-azure-research-tool-scalable-data-mining-2/
2017.10.16 조회수 13788 -
 이의진 교수, 스마트폰으로 문서 촬영 시 발생하는 회전 오류 문제 해결
〈 이의진 교수(좌)와 오정민 박사과정(우) 〉
우리 대학 산업및시스템공학과 이의진 교수 연구팀이 스마트폰 카메라로 문서를 촬영할 때 자동으로 발생하는 불규칙적인 회전 오류 현상의 원인을 밝히고 해결책을 개발했다.
연구팀은 스마트폰의 방위 추적 알고리즘의 한계가 회전 오류의 원인임을 규명했다.
이번 연구 결과는 인간-컴퓨터 상호작용 학회의 국제 학술지인 ‘인터내셔널 저널 오브 휴먼 컴퓨터 스터디(International Journal of Human-Computer Studies)’ 4월 4일자 온라인 판에 게재됐고 8월호 저널에 게재될 예정이다.
스마트폰을 통해 책자, 문서 등을 촬영해 업무에 활용하는 것은 자연스러운 일상이 됐다. 하지만 촬영한 문서가 자동으로 90도 회전하는 현상으로 인해 불편을 겪는 사람들이 많다.
특히 여러 장의 사진을 찍었을 때 각기 다른 방향으로 회전돼 일일이 스마트폰을 돌리거나 파일을 편집해야 하는 현상이 발생한다.
스마트폰으로 문서를 촬영할 때는 대부분 스마트폰과 책상 위 문서가 평행 상태이다.
이 때 스마트폰을 회전시키면 스마트폰의 방위 추적 알고리즘이 작동하지 않는다. 방위 추적 알고리즘은 기본적으로 사용자가 스마트폰을 세워서 사용한다는 가정 하에 한 방향으로 가해지는 중력가속도를 측정해 현재 방위를 추정하는 방식으로 설계됐기 때문이다.
연구팀은 실험을 통해 오류 발생 수치를 측정했다. 실험 결과 문서를 가로로 촬영 시 방위 추적 오류가 93%의 높은 확률로 발생함을 확인했다.
일반 사용자는 오류의 원인을 파악하기 어렵다. 대부분의 카메라 앱은 셔터 버튼에 있는 카메라 모양의 아이콘 방향을 통해 실시간 방위를 표시하고 있지만 이러한 기능에 대해서도 사용자들은 인지하지 못한 것으로 파악됐다.
연구팀은 스마트폰의 모션센서 데이터를 활용해 문서 촬영 중에 방위를 정확하게 추적해 문제를 해결했다.
모션센서 데이터의 핵심 기술은 두 가지로 구분할 수 있다. 일반적으로 스마트폰으로 문서를 촬영할 때는 스마트폰이 지면과 평행을 이루기 때문에 스마트폰에 장착된 중력 가속도 센서를 관측해 이러한 문서 촬영 의도를 쉽게 알 수 있다.
두 번째로 문서 촬영 중에 발생하는 스마트폰 회전은 회전 각속도를 측정하는 센서를 활용해 추적할 수 있다. 카메라 앱 실행 후에 문서 촬영을 위해 스마트폰을 회전시키기 때문에 이를 측정해 회전각이 일정 임계치를 넘으면 방위를 변경하는 것으로 파악할 수 있고 이를 통해 방향을 알 수 있는 것이다.
또한 연구팀은 문서 촬영 시 촬영자 쪽으로 스마트폰이 미세하게 기울어지는 마이크로 틸트(micro-tilt) 현상을 발견했다.
이 현상으로 인해 스마트폰으로 가해지는 중력가속도가 스마트폰 측면으로 분산된다. 눈에는 잘 보이지 않을 정도로 작은 기울기지만 모션센서 데이터를 활용해 마이크로 틸트 행동 패턴의 기계학습 알고리즘을 훈련시킬 수 있다. 이를 통해 정확한 방위 추적이 가능하다.
연구 팀의 실험 결과에 따르면 모션센서 데이터를 활용한 방위 추적 방식의 정확도는 93%로 매우 높아 안드로이드 및 iOS등 상용 스마트폰에도 적용 가능하다.
이 기술들은 기존 방위 추적 알고리즘의 사각지대였던 수평 촬영 상황에서 작동하기 때문에 기존 방위 추적 알고리즘과 겹치는 부분 없이 상호 보완적으로 작동할 수 있다.
이 교수는 “스마트폰을 활용한 문서 촬영은 필수가 됐지만 회전 오류의 원인 규명과 해결책이 어려워 불편함이 많았다”며 “모션센서 데이터를 통해 촬영의 의도를 파악하고 자동으로 오류를 바로잡는 기술은 사용자의 불편을 해결하고 문서 촬영에 특화된 다양한 응용서비스 개발의 기초가 될 것이다”고 말했다.
미래창조과학부의 지원을 통해 수행된 이번 기술 중 국내 특허 2건이 등록이 완료됐고 미국 특허가 3월 1일에 수락됐다.
□ 그림 설명
그림1. 방위 오류 발생으로 인해 생기는 불편함
그림2. 평면촬영시 발생하는 방위 오류 상태
그림3. 자이로스코프를 활용한 스마트폰 회전 추적 모식도
그림4. 마이크로틸트현상
2017.06.27 조회수 16828
이의진 교수, 스마트폰으로 문서 촬영 시 발생하는 회전 오류 문제 해결
〈 이의진 교수(좌)와 오정민 박사과정(우) 〉
우리 대학 산업및시스템공학과 이의진 교수 연구팀이 스마트폰 카메라로 문서를 촬영할 때 자동으로 발생하는 불규칙적인 회전 오류 현상의 원인을 밝히고 해결책을 개발했다.
연구팀은 스마트폰의 방위 추적 알고리즘의 한계가 회전 오류의 원인임을 규명했다.
이번 연구 결과는 인간-컴퓨터 상호작용 학회의 국제 학술지인 ‘인터내셔널 저널 오브 휴먼 컴퓨터 스터디(International Journal of Human-Computer Studies)’ 4월 4일자 온라인 판에 게재됐고 8월호 저널에 게재될 예정이다.
스마트폰을 통해 책자, 문서 등을 촬영해 업무에 활용하는 것은 자연스러운 일상이 됐다. 하지만 촬영한 문서가 자동으로 90도 회전하는 현상으로 인해 불편을 겪는 사람들이 많다.
특히 여러 장의 사진을 찍었을 때 각기 다른 방향으로 회전돼 일일이 스마트폰을 돌리거나 파일을 편집해야 하는 현상이 발생한다.
스마트폰으로 문서를 촬영할 때는 대부분 스마트폰과 책상 위 문서가 평행 상태이다.
이 때 스마트폰을 회전시키면 스마트폰의 방위 추적 알고리즘이 작동하지 않는다. 방위 추적 알고리즘은 기본적으로 사용자가 스마트폰을 세워서 사용한다는 가정 하에 한 방향으로 가해지는 중력가속도를 측정해 현재 방위를 추정하는 방식으로 설계됐기 때문이다.
연구팀은 실험을 통해 오류 발생 수치를 측정했다. 실험 결과 문서를 가로로 촬영 시 방위 추적 오류가 93%의 높은 확률로 발생함을 확인했다.
일반 사용자는 오류의 원인을 파악하기 어렵다. 대부분의 카메라 앱은 셔터 버튼에 있는 카메라 모양의 아이콘 방향을 통해 실시간 방위를 표시하고 있지만 이러한 기능에 대해서도 사용자들은 인지하지 못한 것으로 파악됐다.
연구팀은 스마트폰의 모션센서 데이터를 활용해 문서 촬영 중에 방위를 정확하게 추적해 문제를 해결했다.
모션센서 데이터의 핵심 기술은 두 가지로 구분할 수 있다. 일반적으로 스마트폰으로 문서를 촬영할 때는 스마트폰이 지면과 평행을 이루기 때문에 스마트폰에 장착된 중력 가속도 센서를 관측해 이러한 문서 촬영 의도를 쉽게 알 수 있다.
두 번째로 문서 촬영 중에 발생하는 스마트폰 회전은 회전 각속도를 측정하는 센서를 활용해 추적할 수 있다. 카메라 앱 실행 후에 문서 촬영을 위해 스마트폰을 회전시키기 때문에 이를 측정해 회전각이 일정 임계치를 넘으면 방위를 변경하는 것으로 파악할 수 있고 이를 통해 방향을 알 수 있는 것이다.
또한 연구팀은 문서 촬영 시 촬영자 쪽으로 스마트폰이 미세하게 기울어지는 마이크로 틸트(micro-tilt) 현상을 발견했다.
이 현상으로 인해 스마트폰으로 가해지는 중력가속도가 스마트폰 측면으로 분산된다. 눈에는 잘 보이지 않을 정도로 작은 기울기지만 모션센서 데이터를 활용해 마이크로 틸트 행동 패턴의 기계학습 알고리즘을 훈련시킬 수 있다. 이를 통해 정확한 방위 추적이 가능하다.
연구 팀의 실험 결과에 따르면 모션센서 데이터를 활용한 방위 추적 방식의 정확도는 93%로 매우 높아 안드로이드 및 iOS등 상용 스마트폰에도 적용 가능하다.
이 기술들은 기존 방위 추적 알고리즘의 사각지대였던 수평 촬영 상황에서 작동하기 때문에 기존 방위 추적 알고리즘과 겹치는 부분 없이 상호 보완적으로 작동할 수 있다.
이 교수는 “스마트폰을 활용한 문서 촬영은 필수가 됐지만 회전 오류의 원인 규명과 해결책이 어려워 불편함이 많았다”며 “모션센서 데이터를 통해 촬영의 의도를 파악하고 자동으로 오류를 바로잡는 기술은 사용자의 불편을 해결하고 문서 촬영에 특화된 다양한 응용서비스 개발의 기초가 될 것이다”고 말했다.
미래창조과학부의 지원을 통해 수행된 이번 기술 중 국내 특허 2건이 등록이 완료됐고 미국 특허가 3월 1일에 수락됐다.
□ 그림 설명
그림1. 방위 오류 발생으로 인해 생기는 불편함
그림2. 평면촬영시 발생하는 방위 오류 상태
그림3. 자이로스코프를 활용한 스마트폰 회전 추적 모식도
그림4. 마이크로틸트현상
2017.06.27 조회수 16828 -
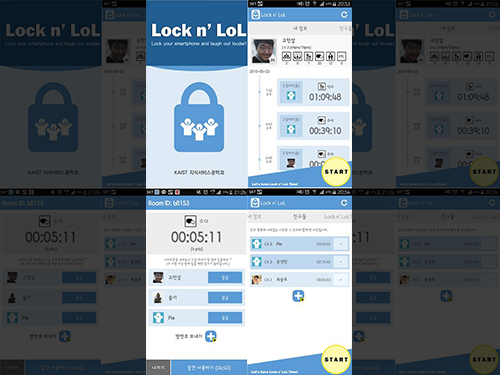 스마트폰 과다 사용 절제 가능 앱 개발
이 의 진 교수
스마트폰은 우리 일상에서 없어선 안 될 중요한 도구이다. 하지만 무분별하고 무절제한 사용으로 인해 회의, 모임, 각종 그룹 활동에 방해가 되는 사례가 많아지고 있다.
이러한 문제 해결을 위해 KAIST(총장 강성모) 지식서비스 공학과 이의진 교수 연구팀이 스마트폰 사용을 절제할 수 있는 ‘락앤롤(Lock n’LOL)’ 앱을 개발했다.
스마트폰의 과도한 사용 요인은 알림 메시지로 유발된 외부적 사용 요인과, 습관으로 인한 내부적 사용 요인 두 가지로 구분된다. 또한 단순 메시지 전송 외에도 사진 촬영, 정보 검색 등의 이유로 필요한 경우가 많아 스마트폰 사용 빈도를 줄이기 어려웠다.
연구팀은 이런 문제들은 감안해 스마트폰 사용을 공동으로 절제할 수 있는 그룹 중재 앱인 락앤롤을 개발했다.
락앤롤 앱은 ▲ 공동화면 잠금 및 알림 무음 기능 ▲ 잠깐 사용하기 기능▲ 근거리 사용자 탐지 및 알림 등 세 가지 주요 기능을 제공한다.
공동화면 잠금 및 알림 무음 기능은 그룹 스터디와 같은 단체 활동에 유용하다. 구성원들이 단체로 스마트폰을 잠금 모드로 바꿈으로써 그룹 활동이 원활하게 이뤄질 수 있도록 돕는다.
잠깐 사용하기 기능은 스마트폰 사용이 꼭 필요한 경우 제한된 시간에만 사용을 할 수 있는 기능이다. 한 시간에 5분 사용가능한 시간이 주어지고 추가 이용을 위해선 다른 사람의 허락을 받아야 한다.
마지막 근거리 사용자 탐지 기능은 근거리에 위치한 친구를 자동으로 탐지해 상호간 그룹 스마트폰 절제 수행을 추천하는 기능이다.
특히 근거리 사용자 탐지 기술은 GPS와 같은 위치 서비스가 없어도 와이파이 핫스팟 검색결과를 이용해 근거리에 위치한 친구를 찾아 그룹 절제를 실행할 수 있도록 돕는다.
연구팀은 개발된 앱을 기반으로 KAIST에서 지난 5월부터 25일 간 스마트폰 사용을 절제하는 ‘락앤롤 캠페인’을 진행했다. 캠페인 기간 동안 천 여 명의 학생이 참여해 누적 1만 시간 이상 스마트폰 사용을 절제한 것으로 조사됐다. 참여자들은 락앤롤을 통해 그룹 활동에 대한 방해가 줄고 효과적으로 집중할 수 있었다고 말했다.
이 교수는 “향후 사물인터넷 시대에서는 그룹 활동 방해와 같은 디지털 폐해가 더욱 심각해질 것이다”며 “우리 연구는 이러한 문제의 공학적 해결책을 제시했다는 의의가 있다”고 말했다.
향후 연구팀은 고도화된 상황인지 기술을 적용해 지능적인 사용 중재 서비스를 제공하는 후속 연구와, 청소년들의 스마트폰 사용 절제를 돕기 위한 가족 참여형 서비스 출시를 계획 중이다.
이번 연구는 KAIST 모바일 소프트웨어 플랫폼 연구 센터와 마이크로소프트 애저(Microsoft Azure)의 지원을 받아 진행됐다.
□ 사진 설명
사진 1. 스마트폰 사용 절제 어플리케이션 락앤롤앱 캡쳐화면
사진 2. 락앤롤 앱 누적사용자 및 누적절제시간 그래프
2015.07.29 조회수 11963
스마트폰 과다 사용 절제 가능 앱 개발
이 의 진 교수
스마트폰은 우리 일상에서 없어선 안 될 중요한 도구이다. 하지만 무분별하고 무절제한 사용으로 인해 회의, 모임, 각종 그룹 활동에 방해가 되는 사례가 많아지고 있다.
이러한 문제 해결을 위해 KAIST(총장 강성모) 지식서비스 공학과 이의진 교수 연구팀이 스마트폰 사용을 절제할 수 있는 ‘락앤롤(Lock n’LOL)’ 앱을 개발했다.
스마트폰의 과도한 사용 요인은 알림 메시지로 유발된 외부적 사용 요인과, 습관으로 인한 내부적 사용 요인 두 가지로 구분된다. 또한 단순 메시지 전송 외에도 사진 촬영, 정보 검색 등의 이유로 필요한 경우가 많아 스마트폰 사용 빈도를 줄이기 어려웠다.
연구팀은 이런 문제들은 감안해 스마트폰 사용을 공동으로 절제할 수 있는 그룹 중재 앱인 락앤롤을 개발했다.
락앤롤 앱은 ▲ 공동화면 잠금 및 알림 무음 기능 ▲ 잠깐 사용하기 기능▲ 근거리 사용자 탐지 및 알림 등 세 가지 주요 기능을 제공한다.
공동화면 잠금 및 알림 무음 기능은 그룹 스터디와 같은 단체 활동에 유용하다. 구성원들이 단체로 스마트폰을 잠금 모드로 바꿈으로써 그룹 활동이 원활하게 이뤄질 수 있도록 돕는다.
잠깐 사용하기 기능은 스마트폰 사용이 꼭 필요한 경우 제한된 시간에만 사용을 할 수 있는 기능이다. 한 시간에 5분 사용가능한 시간이 주어지고 추가 이용을 위해선 다른 사람의 허락을 받아야 한다.
마지막 근거리 사용자 탐지 기능은 근거리에 위치한 친구를 자동으로 탐지해 상호간 그룹 스마트폰 절제 수행을 추천하는 기능이다.
특히 근거리 사용자 탐지 기술은 GPS와 같은 위치 서비스가 없어도 와이파이 핫스팟 검색결과를 이용해 근거리에 위치한 친구를 찾아 그룹 절제를 실행할 수 있도록 돕는다.
연구팀은 개발된 앱을 기반으로 KAIST에서 지난 5월부터 25일 간 스마트폰 사용을 절제하는 ‘락앤롤 캠페인’을 진행했다. 캠페인 기간 동안 천 여 명의 학생이 참여해 누적 1만 시간 이상 스마트폰 사용을 절제한 것으로 조사됐다. 참여자들은 락앤롤을 통해 그룹 활동에 대한 방해가 줄고 효과적으로 집중할 수 있었다고 말했다.
이 교수는 “향후 사물인터넷 시대에서는 그룹 활동 방해와 같은 디지털 폐해가 더욱 심각해질 것이다”며 “우리 연구는 이러한 문제의 공학적 해결책을 제시했다는 의의가 있다”고 말했다.
향후 연구팀은 고도화된 상황인지 기술을 적용해 지능적인 사용 중재 서비스를 제공하는 후속 연구와, 청소년들의 스마트폰 사용 절제를 돕기 위한 가족 참여형 서비스 출시를 계획 중이다.
이번 연구는 KAIST 모바일 소프트웨어 플랫폼 연구 센터와 마이크로소프트 애저(Microsoft Azure)의 지원을 받아 진행됐다.
□ 사진 설명
사진 1. 스마트폰 사용 절제 어플리케이션 락앤롤앱 캡쳐화면
사진 2. 락앤롤 앱 누적사용자 및 누적절제시간 그래프
2015.07.29 조회수 11963