%EC%9D%98%EC%82%AC%EA%B2%B0%EC%A0%95
-
 기업 의사결정을 거대언어모델로 최초 해결
기업 내외의 상황에 따라 끊임없이 새롭게 결정해야 하는 기업 의사결정 문제는 지난 수십 년간 기업들이 전문적인 데이터 분석팀과 고가의 상용 데이터베이스 솔루션들을 통해 해결해 왔는데, 우리 연구진이 최초로 거대언어모델을 이용하여 풀어내어 화제다.
우리 대학 전산학부 김민수 교수 연구팀이 의사결정 문제, 기업 데이터베이스, 비즈니스 규칙 집합 세 가지가 주어졌을 때 거대언어모델을 이용해 의사결정에 필요한 정보를 데이터베이스로부터 찾고, 비즈니스 규칙에 부합하는 최적의 의사결정을 도출할 수 있는 기술(일명 계획 RAG, PlanRAG)을 개발했다고 19일 밝혔다.
거대언어모델은 매우 방대한 데이터를 학습했기 때문에 학습에 사용된 바 없는 데이터를 바탕으로 답변할 때나 오래전 데이터를 바탕으로 답변하는 등 문제점들이 지적되었다. 이런 문제들을 해결하기 위해 거대언어모델이 학습된 내용만으로 답변하는 것 대신, 데이터베이스를 검색해 답변을 생성하는 검색 증강 생성(Retrieval-Augmented Generation; 이하 RAG) 기술이 최근 각광받고 있다.
그러나, 사용자의 질문이 복잡할 경우 다양한 검색 결과를 바탕으로 추가 정보를 다시 검색하여 적절한 답변을 생성할 때까지 반복하는 반복적 RAG(IterativeRAG)라는 기술이 개발됐으며, 이는 현재까지 개발된 가장 최신의 기술이다.
연구팀은 기업 의사결정 문제가 GPT-3.5 터보에서 반복적 RAG 기술을 사용하더라도 정답률이 10% 미만에 이르는 고난도 문제임을 보이고, 이를 해결하기 위해 반복적 RAG 기술을 한층 더 발전시킨 계획 RAG(PlanRAG)라는 기술을 개발했다.
계획 RAG(PlanRAG)는 기존의 RAG 기술들과 다르게 주어진 의사결정 문제, 데이터베이스, 비즈니스 규칙을 바탕으로 어떤 데이터 분석이 필요한지에 대한 거시적 차원의 계획(plan)을 먼저 생성한 후, 그 계획에 따라 반복적 RAG를 이용해 미시적 차원의 분석을 수행한다.
이는 마치 기업의 의사결정권자가 어떤 데이터 분석이 필요한지 계획을 세우면, 그 계획에 따라 데이터 분석팀이 데이터베이스 솔루션들을 이용해 분석하는 형태와 유사하며, 다만 이러한 과정을 모두 사람이 아닌 거대언어모델이 수행하는 것이 커다란 차이점이다. 계획 RAG 기술은 계획에 따른 데이터 분석 결과로 적절한 답변을 도출하지 못하면, 다시 계획을 수립하고 데이터 분석을 수행하는 과정을 반복한다.
김민수 교수는 “지금까지 거대언어모델 기반으로 의사결정 문제를 푼 연구가 없었던 관계로, 기업 의사결정 성능을 평가할 수 있는 의사결정 질의응답(DQA) 벤치마크를 새롭게 만들었다. 그리고 해당 벤치마크에서 GPT-4.0을 사용할 때 종래의 반복적 RAG에 비해 계획 RAG가 의사결정 정답률을 최대 32.5% 개선함을 보였다. 이를 통해 기업들이 복잡한 비즈니스 상황에서 최적의 의사결정을 사람이 아닌 거대언어모델을 이용하여 내리는데 적용되기를 기대한다”고 말했다.
이번 연구에는 김 교수의 제자인 이명화 박사과정과 안선호 석사과정이 공동 제1 저자로, 김 교수가 교신 저자로 참여했으며, 연구 결과는 자연어처리 분야 최고 학회(top conference)인 ‘NAACL’ 에 지난 6월 17일 발표됐다. (논문 제목: PlanRAG: A Plan-then-Retrieval Augmented Generation for Generative Large Language Models as Decision Makers)
한편, 이번 연구는 과기정통부 IITP SW스타랩 및 ITRC 사업, 한국연구재단 선도연구센터인 암흑데이터 극한 활용 연구센터의 지원을 받아 수행됐다.
2024.06.19 조회수 5421
기업 의사결정을 거대언어모델로 최초 해결
기업 내외의 상황에 따라 끊임없이 새롭게 결정해야 하는 기업 의사결정 문제는 지난 수십 년간 기업들이 전문적인 데이터 분석팀과 고가의 상용 데이터베이스 솔루션들을 통해 해결해 왔는데, 우리 연구진이 최초로 거대언어모델을 이용하여 풀어내어 화제다.
우리 대학 전산학부 김민수 교수 연구팀이 의사결정 문제, 기업 데이터베이스, 비즈니스 규칙 집합 세 가지가 주어졌을 때 거대언어모델을 이용해 의사결정에 필요한 정보를 데이터베이스로부터 찾고, 비즈니스 규칙에 부합하는 최적의 의사결정을 도출할 수 있는 기술(일명 계획 RAG, PlanRAG)을 개발했다고 19일 밝혔다.
거대언어모델은 매우 방대한 데이터를 학습했기 때문에 학습에 사용된 바 없는 데이터를 바탕으로 답변할 때나 오래전 데이터를 바탕으로 답변하는 등 문제점들이 지적되었다. 이런 문제들을 해결하기 위해 거대언어모델이 학습된 내용만으로 답변하는 것 대신, 데이터베이스를 검색해 답변을 생성하는 검색 증강 생성(Retrieval-Augmented Generation; 이하 RAG) 기술이 최근 각광받고 있다.
그러나, 사용자의 질문이 복잡할 경우 다양한 검색 결과를 바탕으로 추가 정보를 다시 검색하여 적절한 답변을 생성할 때까지 반복하는 반복적 RAG(IterativeRAG)라는 기술이 개발됐으며, 이는 현재까지 개발된 가장 최신의 기술이다.
연구팀은 기업 의사결정 문제가 GPT-3.5 터보에서 반복적 RAG 기술을 사용하더라도 정답률이 10% 미만에 이르는 고난도 문제임을 보이고, 이를 해결하기 위해 반복적 RAG 기술을 한층 더 발전시킨 계획 RAG(PlanRAG)라는 기술을 개발했다.
계획 RAG(PlanRAG)는 기존의 RAG 기술들과 다르게 주어진 의사결정 문제, 데이터베이스, 비즈니스 규칙을 바탕으로 어떤 데이터 분석이 필요한지에 대한 거시적 차원의 계획(plan)을 먼저 생성한 후, 그 계획에 따라 반복적 RAG를 이용해 미시적 차원의 분석을 수행한다.
이는 마치 기업의 의사결정권자가 어떤 데이터 분석이 필요한지 계획을 세우면, 그 계획에 따라 데이터 분석팀이 데이터베이스 솔루션들을 이용해 분석하는 형태와 유사하며, 다만 이러한 과정을 모두 사람이 아닌 거대언어모델이 수행하는 것이 커다란 차이점이다. 계획 RAG 기술은 계획에 따른 데이터 분석 결과로 적절한 답변을 도출하지 못하면, 다시 계획을 수립하고 데이터 분석을 수행하는 과정을 반복한다.
김민수 교수는 “지금까지 거대언어모델 기반으로 의사결정 문제를 푼 연구가 없었던 관계로, 기업 의사결정 성능을 평가할 수 있는 의사결정 질의응답(DQA) 벤치마크를 새롭게 만들었다. 그리고 해당 벤치마크에서 GPT-4.0을 사용할 때 종래의 반복적 RAG에 비해 계획 RAG가 의사결정 정답률을 최대 32.5% 개선함을 보였다. 이를 통해 기업들이 복잡한 비즈니스 상황에서 최적의 의사결정을 사람이 아닌 거대언어모델을 이용하여 내리는데 적용되기를 기대한다”고 말했다.
이번 연구에는 김 교수의 제자인 이명화 박사과정과 안선호 석사과정이 공동 제1 저자로, 김 교수가 교신 저자로 참여했으며, 연구 결과는 자연어처리 분야 최고 학회(top conference)인 ‘NAACL’ 에 지난 6월 17일 발표됐다. (논문 제목: PlanRAG: A Plan-then-Retrieval Augmented Generation for Generative Large Language Models as Decision Makers)
한편, 이번 연구는 과기정통부 IITP SW스타랩 및 ITRC 사업, 한국연구재단 선도연구센터인 암흑데이터 극한 활용 연구센터의 지원을 받아 수행됐다.
2024.06.19 조회수 5421 -
 세계 최고 수준의 딥러닝 의사결정 설명기술 개발
우리 대학 김재철AI대학원 최재식 교수(㈜인이지 대표이사) 연구팀이 인공지능 딥러닝의 의사결정에 큰 영향을 미치는 입력 변수의 기여도를 계산하는 세계 최고 수준의 기술을 개발했다고 23일 밝혔다.
최근 딥러닝 모델은 문서 자동 번역이나 자율 주행 등 실생활에 널리 보급되고 활용되는 추세 및 발전에도 불구하고 비선형적이고 복잡한 모델의 구조와 고차원의 입력 데이터로 인해 정확한 모델 예측의 근거를 제시하기 어렵다. 이처럼 부족한 설명성은 딥러닝이 국방, 의료, 금융과 같이 의사결정에 대한 근거가 필요한 중요한 작업에 대한 적용을 어렵게 한다. 따라서 적용 분야의 확장을 위해 딥러닝의 부족한 설명성은 반드시 해결해야 할 문제다.
최교수 연구팀은 딥러닝 모델이 국소적인 입력 공간에서 보이는 입력 데이터와 예측 사이의 관계를 기반으로, 입력 데이터의 특징 중 모델 예측의 기여도가 높은 특징만을 점진적으로 추출해나가는 알고리즘과 그 과정에서의 입력과 예측 사이의 관계를 종합하는 방법을 고안해 모델의 예측 과정에 기여하는 입력 특징의 정확한 기여도를 계산했다. 해당 기술은 모델 구조에 대한 의존성이 없어 다양한 기존 학습 모델에서도 적용이 가능하며, 딥러닝 예측 모델의 판단 근거를 제공함으로써 신뢰도를 높여 딥러닝 모델의 활용성에도 크게 기여할 것으로 기대된다.
㈜인이지의 전기영 연구원, 우리 대학 김재철AI대학원의 정해동 연구원이 공동 제1 저자로 참여한 이번 연구는 오는 12월 1일, 국제 학술대회 `신경정보처리학회(Neural Information Processing Systems, NeurIPS) 2022'에서 발표될 예정이다.
모델의 예측에 대한 입력 특징의 기여도를 계산하는 문제는 해석이 불가능한 딥러닝 모델의 작동 방식을 설명하는 직관적인 방법 중 하나다. 특히, 이미지 데이터를 다루는 문제에서는 모델의 예측 과정에 많이 기여한 부분을 강조하는 방식으로 시각화해 설명을 제공한다.
딥러닝 예측 모델의 입력 기여도를 정확하게 계산하기 위해서 모델의 경사도를 이용하거나, 입력 섭동(행동을 다스림)을 이용하는 등의 연구가 활발히 진행되고 있다. 그러나 경사도를 이용한 방식의 경우 결과물에 잡음이 많아 신뢰성을 확보하기 어렵고, 입력 섭동을 이용하는 경우 모든 경우의 섭동을 시도해야 하지만 너무 많은 연산을 요구하기 때문에, 근사치를 추정한 결과만을 얻을 수 있다.
연구팀은 이러한 문제 해결을 위해 입력 데이터의 특징 중에서 모델의 예측과 연관성이 적은 특징을 점진적으로 제거해나가는 증류 알고리즘을 개발했다. 증류 알고리즘은 딥러닝 모델이 국소적으로 보이는 입력 데이터와 예측 사이의 관계에 기반해 상대적으로 예측에 기여도가 적은 특징을 선별 및 제거하며, 이러한 과정의 반복을 통해 증류된 입력 데이터에는 기여도가 높은 특징만 남게 된다. 또한, 해당 과정을 통해 얻게 되는 변형된 데이터에 대한 국소적 입력 기여도를 종합해 신뢰도 높은 최종 입력 기여도를 산출한다.
연구팀의 이러한 입력 기여도 측정 기술은 산업공정 최적화 프로젝트에 적용해 딥러닝 모델이 예측 결과를 도출하기 위해서 어떤 입력 특징에 주목하는지 찾을 수 있었다. 또한 딥러닝 모델의 구조에 상관없이 적용할 수 있는 이 기술을 바탕으로 복잡한 공정 내부의 다양한 예측변수 간 상관관계를 정확하게 분석하고 예측함으로써 공정 최적화(에너지 절감, 품질향상, 생산량 증가)의 효과를 도출할 수 있었다.
연구팀은 잘 알려진 이미지 분류 모델인 VGG-16, ResNet-18, Inception-v3 모델에서 개발 기술이 입력 기여도를 계산하는 데에 효과가 있음을 확인했다. 해당 기술은 구글(Google)이 보유하고 텐서플로우 설명가능 인공지능(TensorFlow Explainable AI) 툴 키트에 적용된 것으로 알려진 입력 기여도 측정 기술(Guided Integrated Gradient) 대비 LeRF/MoRF 점수가 각각 최대 0.436/0.020 개선됨을 보였다. 특히, 입력 기여도의 시각화를 비교했을 때, 기존 방식 대비 잡음이 적고, 주요 객체와 잘 정렬됐으며, 선명한 결과를 보였다. 연구팀은 여러 가지 모델 구조에 대해 신뢰도 높은 입력 기여도 계산 성능을 보임으로써, 개발 기술의 유효성과 확장성을 보였다.
연구팀이 개발한 딥러닝 모델의 입력 기여도 측정 기술은 이미지 외에도 다양한 예측 모델에 적용돼 모델의 예측에 대한 신뢰성을 높일 것으로 기대된다.
전기영 연구원은 "딥러닝 모델의 국소 지역에서 계산된 입력 기여도를 기반으로 상대적인 중요도가 낮은 입력을 점진적으로 제거하며, 이러한 과정에서 축적된 입력 기여도를 종합해 더욱 정확한 설명을 제공할 수 있음을 보였다ˮ라며 "딥러닝 모델에 대해 신뢰도 높은 설명을 제공하기 위해서는 입력 데이터를 적절히 변형한 상황에서도 모델 예측과 관련도가 높은 입력 특성에 주목해야 한다ˮ라고 말했다.
이번 연구는 2022년도 과학기술정보통신부의 재원으로 정보통신기획평가원의 지원을 받은 사람 중심 AI강국 실현을 위한 차세대 인공지능 핵심원천기술개발 사용자 맞춤형 플로그앤플레이 방식의 설명가능성 제공, 한국과학기술원 인공지능 대학원 프로그램, 인공지능 공정성 AIDEP 및 국방과학연구소의 지원을 받은 설명 가능 인공지능 프로젝트 및 인이지의 지원으로 수행됐다.
2022.11.23 조회수 11274
세계 최고 수준의 딥러닝 의사결정 설명기술 개발
우리 대학 김재철AI대학원 최재식 교수(㈜인이지 대표이사) 연구팀이 인공지능 딥러닝의 의사결정에 큰 영향을 미치는 입력 변수의 기여도를 계산하는 세계 최고 수준의 기술을 개발했다고 23일 밝혔다.
최근 딥러닝 모델은 문서 자동 번역이나 자율 주행 등 실생활에 널리 보급되고 활용되는 추세 및 발전에도 불구하고 비선형적이고 복잡한 모델의 구조와 고차원의 입력 데이터로 인해 정확한 모델 예측의 근거를 제시하기 어렵다. 이처럼 부족한 설명성은 딥러닝이 국방, 의료, 금융과 같이 의사결정에 대한 근거가 필요한 중요한 작업에 대한 적용을 어렵게 한다. 따라서 적용 분야의 확장을 위해 딥러닝의 부족한 설명성은 반드시 해결해야 할 문제다.
최교수 연구팀은 딥러닝 모델이 국소적인 입력 공간에서 보이는 입력 데이터와 예측 사이의 관계를 기반으로, 입력 데이터의 특징 중 모델 예측의 기여도가 높은 특징만을 점진적으로 추출해나가는 알고리즘과 그 과정에서의 입력과 예측 사이의 관계를 종합하는 방법을 고안해 모델의 예측 과정에 기여하는 입력 특징의 정확한 기여도를 계산했다. 해당 기술은 모델 구조에 대한 의존성이 없어 다양한 기존 학습 모델에서도 적용이 가능하며, 딥러닝 예측 모델의 판단 근거를 제공함으로써 신뢰도를 높여 딥러닝 모델의 활용성에도 크게 기여할 것으로 기대된다.
㈜인이지의 전기영 연구원, 우리 대학 김재철AI대학원의 정해동 연구원이 공동 제1 저자로 참여한 이번 연구는 오는 12월 1일, 국제 학술대회 `신경정보처리학회(Neural Information Processing Systems, NeurIPS) 2022'에서 발표될 예정이다.
모델의 예측에 대한 입력 특징의 기여도를 계산하는 문제는 해석이 불가능한 딥러닝 모델의 작동 방식을 설명하는 직관적인 방법 중 하나다. 특히, 이미지 데이터를 다루는 문제에서는 모델의 예측 과정에 많이 기여한 부분을 강조하는 방식으로 시각화해 설명을 제공한다.
딥러닝 예측 모델의 입력 기여도를 정확하게 계산하기 위해서 모델의 경사도를 이용하거나, 입력 섭동(행동을 다스림)을 이용하는 등의 연구가 활발히 진행되고 있다. 그러나 경사도를 이용한 방식의 경우 결과물에 잡음이 많아 신뢰성을 확보하기 어렵고, 입력 섭동을 이용하는 경우 모든 경우의 섭동을 시도해야 하지만 너무 많은 연산을 요구하기 때문에, 근사치를 추정한 결과만을 얻을 수 있다.
연구팀은 이러한 문제 해결을 위해 입력 데이터의 특징 중에서 모델의 예측과 연관성이 적은 특징을 점진적으로 제거해나가는 증류 알고리즘을 개발했다. 증류 알고리즘은 딥러닝 모델이 국소적으로 보이는 입력 데이터와 예측 사이의 관계에 기반해 상대적으로 예측에 기여도가 적은 특징을 선별 및 제거하며, 이러한 과정의 반복을 통해 증류된 입력 데이터에는 기여도가 높은 특징만 남게 된다. 또한, 해당 과정을 통해 얻게 되는 변형된 데이터에 대한 국소적 입력 기여도를 종합해 신뢰도 높은 최종 입력 기여도를 산출한다.
연구팀의 이러한 입력 기여도 측정 기술은 산업공정 최적화 프로젝트에 적용해 딥러닝 모델이 예측 결과를 도출하기 위해서 어떤 입력 특징에 주목하는지 찾을 수 있었다. 또한 딥러닝 모델의 구조에 상관없이 적용할 수 있는 이 기술을 바탕으로 복잡한 공정 내부의 다양한 예측변수 간 상관관계를 정확하게 분석하고 예측함으로써 공정 최적화(에너지 절감, 품질향상, 생산량 증가)의 효과를 도출할 수 있었다.
연구팀은 잘 알려진 이미지 분류 모델인 VGG-16, ResNet-18, Inception-v3 모델에서 개발 기술이 입력 기여도를 계산하는 데에 효과가 있음을 확인했다. 해당 기술은 구글(Google)이 보유하고 텐서플로우 설명가능 인공지능(TensorFlow Explainable AI) 툴 키트에 적용된 것으로 알려진 입력 기여도 측정 기술(Guided Integrated Gradient) 대비 LeRF/MoRF 점수가 각각 최대 0.436/0.020 개선됨을 보였다. 특히, 입력 기여도의 시각화를 비교했을 때, 기존 방식 대비 잡음이 적고, 주요 객체와 잘 정렬됐으며, 선명한 결과를 보였다. 연구팀은 여러 가지 모델 구조에 대해 신뢰도 높은 입력 기여도 계산 성능을 보임으로써, 개발 기술의 유효성과 확장성을 보였다.
연구팀이 개발한 딥러닝 모델의 입력 기여도 측정 기술은 이미지 외에도 다양한 예측 모델에 적용돼 모델의 예측에 대한 신뢰성을 높일 것으로 기대된다.
전기영 연구원은 "딥러닝 모델의 국소 지역에서 계산된 입력 기여도를 기반으로 상대적인 중요도가 낮은 입력을 점진적으로 제거하며, 이러한 과정에서 축적된 입력 기여도를 종합해 더욱 정확한 설명을 제공할 수 있음을 보였다ˮ라며 "딥러닝 모델에 대해 신뢰도 높은 설명을 제공하기 위해서는 입력 데이터를 적절히 변형한 상황에서도 모델 예측과 관련도가 높은 입력 특성에 주목해야 한다ˮ라고 말했다.
이번 연구는 2022년도 과학기술정보통신부의 재원으로 정보통신기획평가원의 지원을 받은 사람 중심 AI강국 실현을 위한 차세대 인공지능 핵심원천기술개발 사용자 맞춤형 플로그앤플레이 방식의 설명가능성 제공, 한국과학기술원 인공지능 대학원 프로그램, 인공지능 공정성 AIDEP 및 국방과학연구소의 지원을 받은 설명 가능 인공지능 프로젝트 및 인이지의 지원으로 수행됐다.
2022.11.23 조회수 11274 -
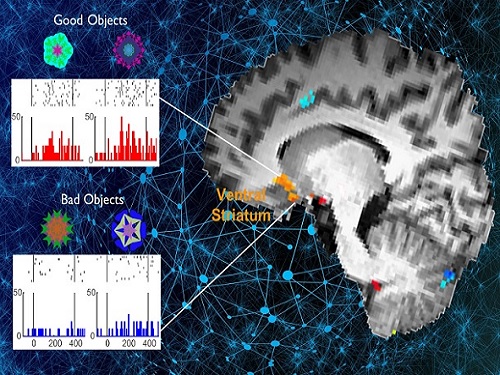 이수현 교수팀, 뇌 복부선조영역의 새로운 기억관련 기능 규명
우리 대학 바이오및뇌공학과 이수현 교수 연구팀과 서울대학교 생명과학부 김형 교수 연구팀이 공동연구를 통해 복부선조영역(ventral striatum)에서 습관행동을 제어하는데 필요한 장기기억이 자동적으로 인출된다는 사실을 밝혔다. 이러한 복부선조영역의 기능을 그 영역과 회로별로 규명하는 것은 인간에게 직접 적용할 수 있는 뇌질환 치료방법 개발과 뇌영역 맞춤형 치료의 이론적 기반이 될 수 있다.
뇌의 복부선조영역은 새로운 가치학습에 중요하며, 중독행동과 조현병 관련 행동에도 연관된 것으로 알려져 왔지만 이러한 행동에 기반이 될 수 있는 기억정보를 처리하고 있는지에 대해서는 불분명했다.
이에 연구팀은 기능적 자기공명뇌영상과 전기생리학적 뇌세포 활성측정법을 모두 이용해 과거에 학습한 물체를 의식적으로 인지하고 있지 않는 상황에서도 복부선조에서 과거에 배운 좋은 물체에 대한 장기기억정보가 활발하게 처리되고 있다는 사실을 밝혀냈다.
또한 자동적으로 인출된 좋은 물체에 대한 기억은 무의식적이며 자동적인 행동, 즉 습관행동을 제어하고, 이를 통해 동물이 장기기억을 기반으로 최대이익을 얻을 수 있는 자동적 의사결정(automatic decision-making) 과정에 사용된다는 실험적 증거를 제시했다.
바이오및뇌공학과 뇌인지공학프로그램 강준영 석박사통합과정 학생이 제1 저자로 참여한 이번 연구는 국제학술지 네이쳐 커뮤니케이션즈(Nature Communications)에 4월 8일(목) 게재됐다.
복부선조영역에서 기억의 자동적 인출과정을 이해함으로써 자동적 행동인 습관과 중독행동 제어의 이론적 기반을 다지고, 나아가 기억의 자동인출(automatic retrieval)과 연관된 현저성(salience) 이상으로 조현병을 이해할 수 있는 이론적 발판을 마련한 것에 이번 연구의 의의가 있다고 볼 수 있다.
이번 연구는 한국연구재단 뇌질환극복사업 및 개인기초연구지원사업 등의 지원을 받아 수행됐다.
2021.04.09 조회수 73420
이수현 교수팀, 뇌 복부선조영역의 새로운 기억관련 기능 규명
우리 대학 바이오및뇌공학과 이수현 교수 연구팀과 서울대학교 생명과학부 김형 교수 연구팀이 공동연구를 통해 복부선조영역(ventral striatum)에서 습관행동을 제어하는데 필요한 장기기억이 자동적으로 인출된다는 사실을 밝혔다. 이러한 복부선조영역의 기능을 그 영역과 회로별로 규명하는 것은 인간에게 직접 적용할 수 있는 뇌질환 치료방법 개발과 뇌영역 맞춤형 치료의 이론적 기반이 될 수 있다.
뇌의 복부선조영역은 새로운 가치학습에 중요하며, 중독행동과 조현병 관련 행동에도 연관된 것으로 알려져 왔지만 이러한 행동에 기반이 될 수 있는 기억정보를 처리하고 있는지에 대해서는 불분명했다.
이에 연구팀은 기능적 자기공명뇌영상과 전기생리학적 뇌세포 활성측정법을 모두 이용해 과거에 학습한 물체를 의식적으로 인지하고 있지 않는 상황에서도 복부선조에서 과거에 배운 좋은 물체에 대한 장기기억정보가 활발하게 처리되고 있다는 사실을 밝혀냈다.
또한 자동적으로 인출된 좋은 물체에 대한 기억은 무의식적이며 자동적인 행동, 즉 습관행동을 제어하고, 이를 통해 동물이 장기기억을 기반으로 최대이익을 얻을 수 있는 자동적 의사결정(automatic decision-making) 과정에 사용된다는 실험적 증거를 제시했다.
바이오및뇌공학과 뇌인지공학프로그램 강준영 석박사통합과정 학생이 제1 저자로 참여한 이번 연구는 국제학술지 네이쳐 커뮤니케이션즈(Nature Communications)에 4월 8일(목) 게재됐다.
복부선조영역에서 기억의 자동적 인출과정을 이해함으로써 자동적 행동인 습관과 중독행동 제어의 이론적 기반을 다지고, 나아가 기억의 자동인출(automatic retrieval)과 연관된 현저성(salience) 이상으로 조현병을 이해할 수 있는 이론적 발판을 마련한 것에 이번 연구의 의의가 있다고 볼 수 있다.
이번 연구는 한국연구재단 뇌질환극복사업 및 개인기초연구지원사업 등의 지원을 받아 수행됐다.
2021.04.09 조회수 73420