%EA%B9%80%EB%AF%BC%EC%88%98
-
 엔비디아 쿠다 통합메모리 없이 세계 최고 그래프 연산 혁신
인공지능 분야에서 지식 체계나 데이터베이스를 그래프로 저장하고 활용하는 사례가 급증하지만, 일반적으로 복잡도가 높은 그래프 연산은 GPU 메모리의 제한으로 인해 매우 작은 규모의 그래프 등 비교적 단순한 연산만 처리할 수 있다는 한계가 있다. 우리 연구진이 25대의 컴퓨터로 2,000초가 걸리던 연산을 한 대의 GPU 컴퓨터로 처리할 수 있는 세계 최고 성능의 연산 프레임워크를 개발하는데 성공했다.
우리 대학 전산학부 김민수 교수 연구팀이 한정된 크기의 메모리를 지닌 GPU를 이용해 1조 간선 규모의 초대규모 그래프에 대해 다양한 연산을 고속으로 처리할 수 있는 스케줄러 및 메모리 관리 기술들을 갖춘 일반 연산 프레임워크(일명 GFlux, 지플럭스)를 개발했다고 27일 밝혔다.
연구팀이 개발한 지플럭스 프레임워크는 그래프 연산을 GPU에 최적화된 단위 작업인 ‘지테스크(GTask)’로 나누고, 이를 효율적으로 GPU에 배분 및 처리하는 특수한 스케줄링 기법을 핵심 기술로 한다. 그래프를 GPU 처리에 최적화된 자체 개발 압축 포맷인 HGF로 변환해 SSD와 같은 저장장치에 저장 및 관리한다.
기존 표준 포맷인 CSR로 저장할 경우, 1조 간선 규모의 그래프 크기가 9테라바이트(TB)에 이르지만, HGF 포맷을 활용하면 이 크기를 4.6테라바이트(TB)로 절반 가까이 줄일 수 있다. 또한 GPU에서는 메모리 정렬 문제로 그간 사용되지 않았던 3바이트의 주소 체계를 최초로 활용, GPU 메모리 사용량을 약 25% 절감했다.
또한, 엔비디아(NVIDIA) 쿠다(CUDA)의 통합 메모리(Unified Memory)에 전혀 의존하지 않고, 메모리 부족으로 인한 연산 실패를 방지할 수 있도록 메인 메모리와 GPU 메모리를 통합적으로 관리하는 GTask 전용 메모리 관리 기술을 주요 핵심 기술로 포함하고 있다.
김민수 교수 연구팀은 삼각형 개수 세기*와 같은 고난도 그래프 연산을 통해 지플럭스 기술의 성능을 검증했다.
*삼각형 개수 세기: 그래프에서 서로 연결된 세 개의 정점이 이루는 삼각형 형태의 관계를 모두 찾고 개수를 세는 연산으로 데이터 분석 및 인공지능에서 널리 활용됨
약 700억 간선 규모의 그래프를 대상으로 한 실험에서, 기존의 최고 성능 기술은 고속 네트워크로 연결된 컴퓨터 25대를 이용해 약 2,000초가 걸리던 삼각형 개수 세기 연산을 지플럭스는 GPU가 장착된 단일 컴퓨터만으로 약 두배 빠른 1,184초 만에 처리하는 데 성공했다.
이는 단일 컴퓨터로 삼각형 개수 세기 연산을 성공적으로 처리한 현재까지 알려진 최대 규모의 그래프다.
김민수 교수는 “최근 그래프 RAG(검색증강생성), 지식 그래프, 그래프 벡터 색인 등 대규모 그래프에 대한 고속 연산 처리 기술의 중요성이 점점 커지고 있다”며, “지플럭스 기술이 이러한 문제를 효과적으로 해결할 것으로 기대한다”고 말했다.
이번 연구에는 전산학부 오세연, 윤희용 박사과정이 각각 제 1, 2 저자로, 김 교수가 창업한 그래프 딥테크 기업인 (주)그래파이 소속 한동형 연구원이 제3 저자로, 김 교수가 교신저자로 참여했고. 연구 결과는 IEEE 주최 국제데이터공학학술대회(ICDE, International Conference on Data Engineering)에서 지난 5월 22일에 발표됐다.
※ 논문제목: GFlux: A fast GPU-based out-of-memory multi-hop query processing framework for trillion-edge graphs
※ DOI: https://doi.ieeecomputersociety.org/10.1109/ICDE65448.2025.00075
한편, 이번 연구는 과기정통부 IITP SW스타랩과 한국연구재단 중견과제의 지원을 받아 수행됐다.
2025.05.27 조회수 1750
엔비디아 쿠다 통합메모리 없이 세계 최고 그래프 연산 혁신
인공지능 분야에서 지식 체계나 데이터베이스를 그래프로 저장하고 활용하는 사례가 급증하지만, 일반적으로 복잡도가 높은 그래프 연산은 GPU 메모리의 제한으로 인해 매우 작은 규모의 그래프 등 비교적 단순한 연산만 처리할 수 있다는 한계가 있다. 우리 연구진이 25대의 컴퓨터로 2,000초가 걸리던 연산을 한 대의 GPU 컴퓨터로 처리할 수 있는 세계 최고 성능의 연산 프레임워크를 개발하는데 성공했다.
우리 대학 전산학부 김민수 교수 연구팀이 한정된 크기의 메모리를 지닌 GPU를 이용해 1조 간선 규모의 초대규모 그래프에 대해 다양한 연산을 고속으로 처리할 수 있는 스케줄러 및 메모리 관리 기술들을 갖춘 일반 연산 프레임워크(일명 GFlux, 지플럭스)를 개발했다고 27일 밝혔다.
연구팀이 개발한 지플럭스 프레임워크는 그래프 연산을 GPU에 최적화된 단위 작업인 ‘지테스크(GTask)’로 나누고, 이를 효율적으로 GPU에 배분 및 처리하는 특수한 스케줄링 기법을 핵심 기술로 한다. 그래프를 GPU 처리에 최적화된 자체 개발 압축 포맷인 HGF로 변환해 SSD와 같은 저장장치에 저장 및 관리한다.
기존 표준 포맷인 CSR로 저장할 경우, 1조 간선 규모의 그래프 크기가 9테라바이트(TB)에 이르지만, HGF 포맷을 활용하면 이 크기를 4.6테라바이트(TB)로 절반 가까이 줄일 수 있다. 또한 GPU에서는 메모리 정렬 문제로 그간 사용되지 않았던 3바이트의 주소 체계를 최초로 활용, GPU 메모리 사용량을 약 25% 절감했다.
또한, 엔비디아(NVIDIA) 쿠다(CUDA)의 통합 메모리(Unified Memory)에 전혀 의존하지 않고, 메모리 부족으로 인한 연산 실패를 방지할 수 있도록 메인 메모리와 GPU 메모리를 통합적으로 관리하는 GTask 전용 메모리 관리 기술을 주요 핵심 기술로 포함하고 있다.
김민수 교수 연구팀은 삼각형 개수 세기*와 같은 고난도 그래프 연산을 통해 지플럭스 기술의 성능을 검증했다.
*삼각형 개수 세기: 그래프에서 서로 연결된 세 개의 정점이 이루는 삼각형 형태의 관계를 모두 찾고 개수를 세는 연산으로 데이터 분석 및 인공지능에서 널리 활용됨
약 700억 간선 규모의 그래프를 대상으로 한 실험에서, 기존의 최고 성능 기술은 고속 네트워크로 연결된 컴퓨터 25대를 이용해 약 2,000초가 걸리던 삼각형 개수 세기 연산을 지플럭스는 GPU가 장착된 단일 컴퓨터만으로 약 두배 빠른 1,184초 만에 처리하는 데 성공했다.
이는 단일 컴퓨터로 삼각형 개수 세기 연산을 성공적으로 처리한 현재까지 알려진 최대 규모의 그래프다.
김민수 교수는 “최근 그래프 RAG(검색증강생성), 지식 그래프, 그래프 벡터 색인 등 대규모 그래프에 대한 고속 연산 처리 기술의 중요성이 점점 커지고 있다”며, “지플럭스 기술이 이러한 문제를 효과적으로 해결할 것으로 기대한다”고 말했다.
이번 연구에는 전산학부 오세연, 윤희용 박사과정이 각각 제 1, 2 저자로, 김 교수가 창업한 그래프 딥테크 기업인 (주)그래파이 소속 한동형 연구원이 제3 저자로, 김 교수가 교신저자로 참여했고. 연구 결과는 IEEE 주최 국제데이터공학학술대회(ICDE, International Conference on Data Engineering)에서 지난 5월 22일에 발표됐다.
※ 논문제목: GFlux: A fast GPU-based out-of-memory multi-hop query processing framework for trillion-edge graphs
※ DOI: https://doi.ieeecomputersociety.org/10.1109/ICDE65448.2025.00075
한편, 이번 연구는 과기정통부 IITP SW스타랩과 한국연구재단 중견과제의 지원을 받아 수행됐다.
2025.05.27 조회수 1750 -
 기업 의사결정을 거대언어모델로 최초 해결
기업 내외의 상황에 따라 끊임없이 새롭게 결정해야 하는 기업 의사결정 문제는 지난 수십 년간 기업들이 전문적인 데이터 분석팀과 고가의 상용 데이터베이스 솔루션들을 통해 해결해 왔는데, 우리 연구진이 최초로 거대언어모델을 이용하여 풀어내어 화제다.
우리 대학 전산학부 김민수 교수 연구팀이 의사결정 문제, 기업 데이터베이스, 비즈니스 규칙 집합 세 가지가 주어졌을 때 거대언어모델을 이용해 의사결정에 필요한 정보를 데이터베이스로부터 찾고, 비즈니스 규칙에 부합하는 최적의 의사결정을 도출할 수 있는 기술(일명 계획 RAG, PlanRAG)을 개발했다고 19일 밝혔다.
거대언어모델은 매우 방대한 데이터를 학습했기 때문에 학습에 사용된 바 없는 데이터를 바탕으로 답변할 때나 오래전 데이터를 바탕으로 답변하는 등 문제점들이 지적되었다. 이런 문제들을 해결하기 위해 거대언어모델이 학습된 내용만으로 답변하는 것 대신, 데이터베이스를 검색해 답변을 생성하는 검색 증강 생성(Retrieval-Augmented Generation; 이하 RAG) 기술이 최근 각광받고 있다.
그러나, 사용자의 질문이 복잡할 경우 다양한 검색 결과를 바탕으로 추가 정보를 다시 검색하여 적절한 답변을 생성할 때까지 반복하는 반복적 RAG(IterativeRAG)라는 기술이 개발됐으며, 이는 현재까지 개발된 가장 최신의 기술이다.
연구팀은 기업 의사결정 문제가 GPT-3.5 터보에서 반복적 RAG 기술을 사용하더라도 정답률이 10% 미만에 이르는 고난도 문제임을 보이고, 이를 해결하기 위해 반복적 RAG 기술을 한층 더 발전시킨 계획 RAG(PlanRAG)라는 기술을 개발했다.
계획 RAG(PlanRAG)는 기존의 RAG 기술들과 다르게 주어진 의사결정 문제, 데이터베이스, 비즈니스 규칙을 바탕으로 어떤 데이터 분석이 필요한지에 대한 거시적 차원의 계획(plan)을 먼저 생성한 후, 그 계획에 따라 반복적 RAG를 이용해 미시적 차원의 분석을 수행한다.
이는 마치 기업의 의사결정권자가 어떤 데이터 분석이 필요한지 계획을 세우면, 그 계획에 따라 데이터 분석팀이 데이터베이스 솔루션들을 이용해 분석하는 형태와 유사하며, 다만 이러한 과정을 모두 사람이 아닌 거대언어모델이 수행하는 것이 커다란 차이점이다. 계획 RAG 기술은 계획에 따른 데이터 분석 결과로 적절한 답변을 도출하지 못하면, 다시 계획을 수립하고 데이터 분석을 수행하는 과정을 반복한다.
김민수 교수는 “지금까지 거대언어모델 기반으로 의사결정 문제를 푼 연구가 없었던 관계로, 기업 의사결정 성능을 평가할 수 있는 의사결정 질의응답(DQA) 벤치마크를 새롭게 만들었다. 그리고 해당 벤치마크에서 GPT-4.0을 사용할 때 종래의 반복적 RAG에 비해 계획 RAG가 의사결정 정답률을 최대 32.5% 개선함을 보였다. 이를 통해 기업들이 복잡한 비즈니스 상황에서 최적의 의사결정을 사람이 아닌 거대언어모델을 이용하여 내리는데 적용되기를 기대한다”고 말했다.
이번 연구에는 김 교수의 제자인 이명화 박사과정과 안선호 석사과정이 공동 제1 저자로, 김 교수가 교신 저자로 참여했으며, 연구 결과는 자연어처리 분야 최고 학회(top conference)인 ‘NAACL’ 에 지난 6월 17일 발표됐다. (논문 제목: PlanRAG: A Plan-then-Retrieval Augmented Generation for Generative Large Language Models as Decision Makers)
한편, 이번 연구는 과기정통부 IITP SW스타랩 및 ITRC 사업, 한국연구재단 선도연구센터인 암흑데이터 극한 활용 연구센터의 지원을 받아 수행됐다.
2024.06.19 조회수 5373
기업 의사결정을 거대언어모델로 최초 해결
기업 내외의 상황에 따라 끊임없이 새롭게 결정해야 하는 기업 의사결정 문제는 지난 수십 년간 기업들이 전문적인 데이터 분석팀과 고가의 상용 데이터베이스 솔루션들을 통해 해결해 왔는데, 우리 연구진이 최초로 거대언어모델을 이용하여 풀어내어 화제다.
우리 대학 전산학부 김민수 교수 연구팀이 의사결정 문제, 기업 데이터베이스, 비즈니스 규칙 집합 세 가지가 주어졌을 때 거대언어모델을 이용해 의사결정에 필요한 정보를 데이터베이스로부터 찾고, 비즈니스 규칙에 부합하는 최적의 의사결정을 도출할 수 있는 기술(일명 계획 RAG, PlanRAG)을 개발했다고 19일 밝혔다.
거대언어모델은 매우 방대한 데이터를 학습했기 때문에 학습에 사용된 바 없는 데이터를 바탕으로 답변할 때나 오래전 데이터를 바탕으로 답변하는 등 문제점들이 지적되었다. 이런 문제들을 해결하기 위해 거대언어모델이 학습된 내용만으로 답변하는 것 대신, 데이터베이스를 검색해 답변을 생성하는 검색 증강 생성(Retrieval-Augmented Generation; 이하 RAG) 기술이 최근 각광받고 있다.
그러나, 사용자의 질문이 복잡할 경우 다양한 검색 결과를 바탕으로 추가 정보를 다시 검색하여 적절한 답변을 생성할 때까지 반복하는 반복적 RAG(IterativeRAG)라는 기술이 개발됐으며, 이는 현재까지 개발된 가장 최신의 기술이다.
연구팀은 기업 의사결정 문제가 GPT-3.5 터보에서 반복적 RAG 기술을 사용하더라도 정답률이 10% 미만에 이르는 고난도 문제임을 보이고, 이를 해결하기 위해 반복적 RAG 기술을 한층 더 발전시킨 계획 RAG(PlanRAG)라는 기술을 개발했다.
계획 RAG(PlanRAG)는 기존의 RAG 기술들과 다르게 주어진 의사결정 문제, 데이터베이스, 비즈니스 규칙을 바탕으로 어떤 데이터 분석이 필요한지에 대한 거시적 차원의 계획(plan)을 먼저 생성한 후, 그 계획에 따라 반복적 RAG를 이용해 미시적 차원의 분석을 수행한다.
이는 마치 기업의 의사결정권자가 어떤 데이터 분석이 필요한지 계획을 세우면, 그 계획에 따라 데이터 분석팀이 데이터베이스 솔루션들을 이용해 분석하는 형태와 유사하며, 다만 이러한 과정을 모두 사람이 아닌 거대언어모델이 수행하는 것이 커다란 차이점이다. 계획 RAG 기술은 계획에 따른 데이터 분석 결과로 적절한 답변을 도출하지 못하면, 다시 계획을 수립하고 데이터 분석을 수행하는 과정을 반복한다.
김민수 교수는 “지금까지 거대언어모델 기반으로 의사결정 문제를 푼 연구가 없었던 관계로, 기업 의사결정 성능을 평가할 수 있는 의사결정 질의응답(DQA) 벤치마크를 새롭게 만들었다. 그리고 해당 벤치마크에서 GPT-4.0을 사용할 때 종래의 반복적 RAG에 비해 계획 RAG가 의사결정 정답률을 최대 32.5% 개선함을 보였다. 이를 통해 기업들이 복잡한 비즈니스 상황에서 최적의 의사결정을 사람이 아닌 거대언어모델을 이용하여 내리는데 적용되기를 기대한다”고 말했다.
이번 연구에는 김 교수의 제자인 이명화 박사과정과 안선호 석사과정이 공동 제1 저자로, 김 교수가 교신 저자로 참여했으며, 연구 결과는 자연어처리 분야 최고 학회(top conference)인 ‘NAACL’ 에 지난 6월 17일 발표됐다. (논문 제목: PlanRAG: A Plan-then-Retrieval Augmented Generation for Generative Large Language Models as Decision Makers)
한편, 이번 연구는 과기정통부 IITP SW스타랩 및 ITRC 사업, 한국연구재단 선도연구센터인 암흑데이터 극한 활용 연구센터의 지원을 받아 수행됐다.
2024.06.19 조회수 5373 -
 GPU에서 대규모 출력데이터 난제 해결
국내 연구진이 인공지능(AI) 등에 널리 사용되는 그래픽 연산 장치(이하 GPU)에서 메모리 크기의 한계로 인해 초병렬 연산*의 결과로 대규모 출력 데이터가 발생할 때 이를 잘 처리하지 못하던 난제를 해결했다. 이 기술을 통해 향후 가정에서 사용하는 메모리 크기가 작은 GPU로도 생성형 AI 등 고난이도 연산이 대규모 출력을 필요한 경우 이를 빠르게 수행할 수 있다.
*초병렬 연산: GPU를 이용하여 수 십 만에서 수 백 만 개의 작은 연산들을 동시에 수행하는 연산을 의미
우리 대학은 전산학부 김민수 교수 연구팀이 한정된 크기의 메모리를 지닌 GPU를 이용해 수십, 수백 만개 이상의 스레드들로 초병렬 연산을 하면서 수 테라바이트의 큰 출력 데이터*를 발생시킬 경우에도 메모리 에러를 발생시키지 않고 해당 출력 데이터를 메인 메모리로 고속으로 전송 및 저장할 수 있는 데이터 처리 기술(일명 INFINEL)을 개발했다고 7일 밝혔다.
*출력데이터: 데이터 분석 결과 또는 인공지능에 의한 생성 결과물에 해당하는 데이터
최근 AI의 활용이 급속히 증가하면서 지식 그래프와 같이 정점과 간선으로 이루어진 그래프 구조의 데이터의 구축과 사용도 점점 증가하고 있는데, 그래프 구조의 데이터에 대해 난이도가 높은 초병렬 연산을 수행할 경우 그 출력 결과가 매우 크고, 각 스레드의 출력 크기를 예측하기 어렵다는 문제점이 발생한다.
또한, GPU는 근본적으로 CPU와 달리 메모리 관리 기능이 매우 제한적이기 때문에 예측할 수 없는 대규모의 데이터를 유연하게 관리하기 어렵다는 문제가 있다. 이러한 이유로 지금까지는 GPU를 활용해 ‘삼각형 나열’과 같은 난이도가 높은 그래프 초병렬 연산을 수행할 수 없었다.
김 교수팀은 이를 근본적으로 해결하는 INFINEL 기술을 개발했다. 해당 기술은 GPU 메모리의 일부 공간을 수백 만개 이상의 청크(chunk)라 불리는 매우 작은 크기의 단위들로 나누고 관리하면서, 초병렬 연산 내용이 담긴 GPU 커널(kernel) 프로그램을 실행하면서 각 스레드가 메모리 충돌 없이 빠르게 자신이 필요한 청크 메모리들을 할당받아 자신의 출력 데이터를 저장할 수 있도록 한다.
또한, GPU 메모리가 가득 차도 무중단 방식으로 초병렬 연산과 결과 출력 및 저장을 지속할 수 있도록 한다. 따라서 이 기술을 사용하면 가정에서 사용하는 메모리 크기가 작은 GPU로도 수 테라 바이트 이상의 출력 데이터가 발생하는 고난이도 연산을 빠르게 수행할 수 있다.
김민수 교수 연구팀은 INFINEL 기술의 성능을 다양한 실험 환경과 데이터 셋을 통해 검증했으며, 종래의 최고 성능 동적 메모리 관리자 기술에 비해 약 55배, 커널을 2번 실행하는 2단계 기술에 비해 약 32배 연산 성능을 향상함을 보였다.
교신저자로 참여한 우리 대학 전산학부 김민수 교수는 “생성형 AI나 메타버스 시대에는 GPU 컴퓨팅의 대규모 출력 데이터를 빠르게 처리할 수 있는 기술이 중요해질 것으로 예상되며, INFINEL 기술이 그 일부 역할을 할 수 있을 것”이라고 말했다.
이번 연구에는 김 교수의 제자인 박성우 박사과정이 제1 저자로, 김 교수가 창업한 그래프 딥테크 기업인 (주)그래파이 소속의 오세연 연구원이 제 2 저자로, 김 교수가 교신 저자로 참여하였으며, 국제 학술지 ‘PPoPP’에 3월 4일자 발표됐다. (INFINEL: An efficient GPU-based processing method for unpredictable large output graph queries)
한편, 이번 연구는 과기정통부 IITP SW스타랩 및 ITRC 사업, 한국연구재단 선도연구센터인 암흑데이터 극한 활용 연구센터의 지원을 받아 수행됐다.
2024.03.07 조회수 6736
GPU에서 대규모 출력데이터 난제 해결
국내 연구진이 인공지능(AI) 등에 널리 사용되는 그래픽 연산 장치(이하 GPU)에서 메모리 크기의 한계로 인해 초병렬 연산*의 결과로 대규모 출력 데이터가 발생할 때 이를 잘 처리하지 못하던 난제를 해결했다. 이 기술을 통해 향후 가정에서 사용하는 메모리 크기가 작은 GPU로도 생성형 AI 등 고난이도 연산이 대규모 출력을 필요한 경우 이를 빠르게 수행할 수 있다.
*초병렬 연산: GPU를 이용하여 수 십 만에서 수 백 만 개의 작은 연산들을 동시에 수행하는 연산을 의미
우리 대학은 전산학부 김민수 교수 연구팀이 한정된 크기의 메모리를 지닌 GPU를 이용해 수십, 수백 만개 이상의 스레드들로 초병렬 연산을 하면서 수 테라바이트의 큰 출력 데이터*를 발생시킬 경우에도 메모리 에러를 발생시키지 않고 해당 출력 데이터를 메인 메모리로 고속으로 전송 및 저장할 수 있는 데이터 처리 기술(일명 INFINEL)을 개발했다고 7일 밝혔다.
*출력데이터: 데이터 분석 결과 또는 인공지능에 의한 생성 결과물에 해당하는 데이터
최근 AI의 활용이 급속히 증가하면서 지식 그래프와 같이 정점과 간선으로 이루어진 그래프 구조의 데이터의 구축과 사용도 점점 증가하고 있는데, 그래프 구조의 데이터에 대해 난이도가 높은 초병렬 연산을 수행할 경우 그 출력 결과가 매우 크고, 각 스레드의 출력 크기를 예측하기 어렵다는 문제점이 발생한다.
또한, GPU는 근본적으로 CPU와 달리 메모리 관리 기능이 매우 제한적이기 때문에 예측할 수 없는 대규모의 데이터를 유연하게 관리하기 어렵다는 문제가 있다. 이러한 이유로 지금까지는 GPU를 활용해 ‘삼각형 나열’과 같은 난이도가 높은 그래프 초병렬 연산을 수행할 수 없었다.
김 교수팀은 이를 근본적으로 해결하는 INFINEL 기술을 개발했다. 해당 기술은 GPU 메모리의 일부 공간을 수백 만개 이상의 청크(chunk)라 불리는 매우 작은 크기의 단위들로 나누고 관리하면서, 초병렬 연산 내용이 담긴 GPU 커널(kernel) 프로그램을 실행하면서 각 스레드가 메모리 충돌 없이 빠르게 자신이 필요한 청크 메모리들을 할당받아 자신의 출력 데이터를 저장할 수 있도록 한다.
또한, GPU 메모리가 가득 차도 무중단 방식으로 초병렬 연산과 결과 출력 및 저장을 지속할 수 있도록 한다. 따라서 이 기술을 사용하면 가정에서 사용하는 메모리 크기가 작은 GPU로도 수 테라 바이트 이상의 출력 데이터가 발생하는 고난이도 연산을 빠르게 수행할 수 있다.
김민수 교수 연구팀은 INFINEL 기술의 성능을 다양한 실험 환경과 데이터 셋을 통해 검증했으며, 종래의 최고 성능 동적 메모리 관리자 기술에 비해 약 55배, 커널을 2번 실행하는 2단계 기술에 비해 약 32배 연산 성능을 향상함을 보였다.
교신저자로 참여한 우리 대학 전산학부 김민수 교수는 “생성형 AI나 메타버스 시대에는 GPU 컴퓨팅의 대규모 출력 데이터를 빠르게 처리할 수 있는 기술이 중요해질 것으로 예상되며, INFINEL 기술이 그 일부 역할을 할 수 있을 것”이라고 말했다.
이번 연구에는 김 교수의 제자인 박성우 박사과정이 제1 저자로, 김 교수가 창업한 그래프 딥테크 기업인 (주)그래파이 소속의 오세연 연구원이 제 2 저자로, 김 교수가 교신 저자로 참여하였으며, 국제 학술지 ‘PPoPP’에 3월 4일자 발표됐다. (INFINEL: An efficient GPU-based processing method for unpredictable large output graph queries)
한편, 이번 연구는 과기정통부 IITP SW스타랩 및 ITRC 사업, 한국연구재단 선도연구센터인 암흑데이터 극한 활용 연구센터의 지원을 받아 수행됐다.
2024.03.07 조회수 6736 -
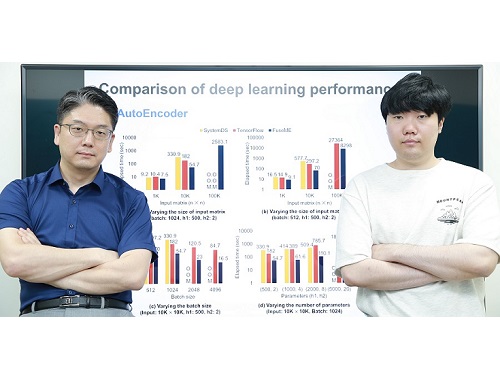 초대규모 인공지능 모델 처리하기 위한 세계 최고 성능의 기계학습 시스템 기술 개발
우리 연구진이 오늘날 인공지능 딥러닝 모델들을 처리하기 위해 필수적으로 사용되는 기계학습 시스템을 세계 최고 수준의 성능으로 끌어올렸다.
우리 대학 전산학부 김민수 교수 연구팀이 딥러닝 모델을 비롯한 기계학습 모델을 학습하거나 추론하기 위해 필수적으로 사용되는 기계학습 시스템의 성능을 대폭 높일 수 있는 세계 최고 수준의 행렬 연산자 융합 기술(일명 FuseME)을 개발했다고 20일 밝혔다.
오늘날 광범위한 산업 분야들에서 사용되고 있는 딥러닝 모델들은 대부분 구글 텐서플로우(TensorFlow)나 IBM 시스템DS와 같은 기계학습 시스템을 이용해 처리되는데, 딥러닝 모델의 규모가 점점 더 커지고, 그 모델에 사용되는 데이터의 규모가 점점 더 커짐에 따라, 이들을 원활히 처리할 수 있는 고성능 기계학습 시스템에 대한 중요성도 점점 더 커지고 있다.
일반적으로 딥러닝 모델은 행렬 곱셈, 행렬 합, 행렬 집계 등의 많은 행렬 연산자들로 구성된 방향성 비순환 그래프(Directed Acyclic Graph; 이하 DAG) 형태의 질의 계획으로 표현돼 기계학습 시스템에 의해 처리된다. 모델과 데이터의 규모가 클 때는 일반적으로 DAG 질의 계획은 수많은 컴퓨터로 구성된 클러스터에서 처리된다. 클러스터의 사양에 비해 모델과 데이터의 규모가 커지면 처리에 실패하거나 시간이 오래 걸리는 근본적인 문제가 있었다.
지금까지는 더 큰 규모의 모델이나 데이터를 처리하기 위해 단순히 컴퓨터 클러스터의 규모를 증가시키는 방식을 주로 사용했다. 그러나, 김 교수팀은 DAG 질의 계획을 구성하는 각 행렬 연산자로부터 생성되는 일종의 `중간 데이터'를 메모리에 저장하거나 네트워크 통신을 통해 다른 컴퓨터로 전송하는 것이 문제의 원인임에 착안해, 중간 데이터를 저장하지 않거나 다른 컴퓨터로 전송하지 않도록 여러 행렬 연산자들을 하나의 연산자로 융합(fusion)하는 세계 최고 성능의 융합 기술인 FuseME(Fused Matrix Engine)을 개발해 문제를 해결했다.
현재까지의 기계학습 시스템들은 낮은 수준의 연산자 융합 기술만을 사용하고 있었다. 가장 복잡한 행렬 연산자인 행렬 곱을 제외한 나머지 연산자들만 융합해 성능이 별로 개선되지 않거나, 전체 DAG 질의 계획을 단순히 하나의 연산자처럼 실행해 메모리 부족으로 처리에 실패하는 한계를 지니고 있었다.
김 교수팀이 개발한 FuseME 기술은 수십 개 이상의 행렬 연산자들로 구성되는 DAG 질의 계획에서 어떤 연산자들끼리 서로 융합하는 것이 더 우수한 성능을 내는지 비용 기반으로 판별해 그룹으로 묶고, 클러스터의 사양, 네트워크 통신 속도, 입력 데이터 크기 등을 모두 고려해 각 융합 연산자 그룹을 메모리 부족으로 처리에 실패하지 않으면서 이론적으로 최적 성능을 낼 수 있는 CFO(Cuboid-based Fused Operator)라 불리는 연산자로 융합함으로써 한계를 극복했다. 이때, 행렬 곱 연산자까지 포함해 연산자들을 융합하는 것이 핵심이다.
김민수 교수 연구팀은 FuseME 기술을 종래 최고 기술로 알려진 구글의 텐서플로우나 IBM의 시스템DS와 비교 평가한 결과, 딥러닝 모델의 처리 속도를 최대 8.8배 향상하고, 텐서플로우나 시스템DS가 처리할 수 없는 훨씬 더 큰 규모의 모델 및 데이터를 처리하는 데 성공함을 보였다. 또한, FuseME의 CFO 융합 연산자는 종래의 최고 수준 융합 연산자와 비교해 처리 속도를 최대 238배 향상시키고, 네트워크 통신 비용을 최대 64배 감소시키는 사실을 확인했다.
김 교수팀은 이미 지난 2019년에 초대규모 행렬 곱 연산에 대해 종래 세계 최고 기술이었던 IBM 시스템ML과 슈퍼컴퓨팅 분야의 스칼라팩(ScaLAPACK) 대비 성능과 처리 규모를 훨씬 향상시킨 DistME라는 기술을 개발해 데이터베이스 분야 최고 국제학술대회 중 하나인 ACM SIGMOD에서 발표한 바 있다. 이번 FuseME 기술은 연산자 융합이 가능하도록 DistME를 한층 더 발전시킨 것으로, 해당 분야를 세계 최고 수준의 기술력을 바탕으로 지속적으로 선도하는 쾌거를 보여준 것이다.
교신저자로 참여한 김민수 교수는 "연구팀이 개발한 새로운 기술은 딥러닝 등 기계학습 모델의 처리 규모와 성능을 획기적으로 높일 수 있어 산업적 측면에서 파급 효과가 매우 클 것으로 기대한다ˮ 라고 말했다.
이번 연구에는 김 교수의 제자이자 현재 GraphAI(그래파이) 스타트업의 공동 창업자인 한동형 박사가 제1 저자로, 김 교수가 교신저자로 참여했으며 지난 16일 미국 필라델피아에서 열린 데이터베이스 분야 최고 국제학술대회 중 하나인 ACM SIGMOD에서 발표됐다. (논문명 : FuseME: Distributed Matrix Computation Engine based on Cuboid-based Fused Operator and Plan Generation).
한편, 이번 연구는 한국연구재단 선도연구센터 사업 및 중견연구자 지원사업, 과기정통부 IITP SW스타랩 사업의 지원을 받아 수행됐다.
2022.06.20 조회수 8787
초대규모 인공지능 모델 처리하기 위한 세계 최고 성능의 기계학습 시스템 기술 개발
우리 연구진이 오늘날 인공지능 딥러닝 모델들을 처리하기 위해 필수적으로 사용되는 기계학습 시스템을 세계 최고 수준의 성능으로 끌어올렸다.
우리 대학 전산학부 김민수 교수 연구팀이 딥러닝 모델을 비롯한 기계학습 모델을 학습하거나 추론하기 위해 필수적으로 사용되는 기계학습 시스템의 성능을 대폭 높일 수 있는 세계 최고 수준의 행렬 연산자 융합 기술(일명 FuseME)을 개발했다고 20일 밝혔다.
오늘날 광범위한 산업 분야들에서 사용되고 있는 딥러닝 모델들은 대부분 구글 텐서플로우(TensorFlow)나 IBM 시스템DS와 같은 기계학습 시스템을 이용해 처리되는데, 딥러닝 모델의 규모가 점점 더 커지고, 그 모델에 사용되는 데이터의 규모가 점점 더 커짐에 따라, 이들을 원활히 처리할 수 있는 고성능 기계학습 시스템에 대한 중요성도 점점 더 커지고 있다.
일반적으로 딥러닝 모델은 행렬 곱셈, 행렬 합, 행렬 집계 등의 많은 행렬 연산자들로 구성된 방향성 비순환 그래프(Directed Acyclic Graph; 이하 DAG) 형태의 질의 계획으로 표현돼 기계학습 시스템에 의해 처리된다. 모델과 데이터의 규모가 클 때는 일반적으로 DAG 질의 계획은 수많은 컴퓨터로 구성된 클러스터에서 처리된다. 클러스터의 사양에 비해 모델과 데이터의 규모가 커지면 처리에 실패하거나 시간이 오래 걸리는 근본적인 문제가 있었다.
지금까지는 더 큰 규모의 모델이나 데이터를 처리하기 위해 단순히 컴퓨터 클러스터의 규모를 증가시키는 방식을 주로 사용했다. 그러나, 김 교수팀은 DAG 질의 계획을 구성하는 각 행렬 연산자로부터 생성되는 일종의 `중간 데이터'를 메모리에 저장하거나 네트워크 통신을 통해 다른 컴퓨터로 전송하는 것이 문제의 원인임에 착안해, 중간 데이터를 저장하지 않거나 다른 컴퓨터로 전송하지 않도록 여러 행렬 연산자들을 하나의 연산자로 융합(fusion)하는 세계 최고 성능의 융합 기술인 FuseME(Fused Matrix Engine)을 개발해 문제를 해결했다.
현재까지의 기계학습 시스템들은 낮은 수준의 연산자 융합 기술만을 사용하고 있었다. 가장 복잡한 행렬 연산자인 행렬 곱을 제외한 나머지 연산자들만 융합해 성능이 별로 개선되지 않거나, 전체 DAG 질의 계획을 단순히 하나의 연산자처럼 실행해 메모리 부족으로 처리에 실패하는 한계를 지니고 있었다.
김 교수팀이 개발한 FuseME 기술은 수십 개 이상의 행렬 연산자들로 구성되는 DAG 질의 계획에서 어떤 연산자들끼리 서로 융합하는 것이 더 우수한 성능을 내는지 비용 기반으로 판별해 그룹으로 묶고, 클러스터의 사양, 네트워크 통신 속도, 입력 데이터 크기 등을 모두 고려해 각 융합 연산자 그룹을 메모리 부족으로 처리에 실패하지 않으면서 이론적으로 최적 성능을 낼 수 있는 CFO(Cuboid-based Fused Operator)라 불리는 연산자로 융합함으로써 한계를 극복했다. 이때, 행렬 곱 연산자까지 포함해 연산자들을 융합하는 것이 핵심이다.
김민수 교수 연구팀은 FuseME 기술을 종래 최고 기술로 알려진 구글의 텐서플로우나 IBM의 시스템DS와 비교 평가한 결과, 딥러닝 모델의 처리 속도를 최대 8.8배 향상하고, 텐서플로우나 시스템DS가 처리할 수 없는 훨씬 더 큰 규모의 모델 및 데이터를 처리하는 데 성공함을 보였다. 또한, FuseME의 CFO 융합 연산자는 종래의 최고 수준 융합 연산자와 비교해 처리 속도를 최대 238배 향상시키고, 네트워크 통신 비용을 최대 64배 감소시키는 사실을 확인했다.
김 교수팀은 이미 지난 2019년에 초대규모 행렬 곱 연산에 대해 종래 세계 최고 기술이었던 IBM 시스템ML과 슈퍼컴퓨팅 분야의 스칼라팩(ScaLAPACK) 대비 성능과 처리 규모를 훨씬 향상시킨 DistME라는 기술을 개발해 데이터베이스 분야 최고 국제학술대회 중 하나인 ACM SIGMOD에서 발표한 바 있다. 이번 FuseME 기술은 연산자 융합이 가능하도록 DistME를 한층 더 발전시킨 것으로, 해당 분야를 세계 최고 수준의 기술력을 바탕으로 지속적으로 선도하는 쾌거를 보여준 것이다.
교신저자로 참여한 김민수 교수는 "연구팀이 개발한 새로운 기술은 딥러닝 등 기계학습 모델의 처리 규모와 성능을 획기적으로 높일 수 있어 산업적 측면에서 파급 효과가 매우 클 것으로 기대한다ˮ 라고 말했다.
이번 연구에는 김 교수의 제자이자 현재 GraphAI(그래파이) 스타트업의 공동 창업자인 한동형 박사가 제1 저자로, 김 교수가 교신저자로 참여했으며 지난 16일 미국 필라델피아에서 열린 데이터베이스 분야 최고 국제학술대회 중 하나인 ACM SIGMOD에서 발표됐다. (논문명 : FuseME: Distributed Matrix Computation Engine based on Cuboid-based Fused Operator and Plan Generation).
한편, 이번 연구는 한국연구재단 선도연구센터 사업 및 중견연구자 지원사업, 과기정통부 IITP SW스타랩 사업의 지원을 받아 수행됐다.
2022.06.20 조회수 8787 -
 초대규모 그래프 프로세싱 시뮬레이션 기술 개발
우리 대학 연구진이 오늘날 정보통신(IT) 분야에서 광범위하게 사용되는 그래프 타입의 데이터를 실제로 저장하지 않고도 알고리즘을 계산할 수 있는 `그래프 프로세싱 시뮬레이션'이라는 신개념 기술을 세계 최초로 개발하는 데 성공했다. 데이터를 저장할 필요가 없어 1조 개 간선의 초대규모 그래프도 PC 한 대로 처리가 가능하다.
우리 대학 전산학부 김민수 교수 연구팀은 1조 개 간선의 초대규모 그래프에 대해 데이터 저장 없이 알고리즘을 계산할 수 있는 신개념 기술을 세계 최초로 개발했다고 23일 밝혔다.
오늘날 웹, SNS, 인공지능, 블록체인 등의 광범위한 분야들에서 그래프 타입의 데이터에 대한 다양한 알고리즘들의 연구가 매우 중요하다. 그러나 그래프 데이터의 복잡성으로 인해 그 크기가 커질 때 막대한 규모의 컴퓨터 클러스터가 있어야만 알고리즘 계산이 가능하다는 문제가 있다.
김 교수 연구팀은 이를 근본적으로 해결하는 T-GPS(Trillion-scale Graph Processing Simulation)라는 기술을 개발했다. 이 T-GPS 기술은 그래프 데이터를 실제로 디스크에 저장하지 않고도 마치 그래프 데이터가 저장돼 있는 것처럼 알고리즘을 계산할 수 있고, 계산 결과도 실제 저장된 그래프에 대한 알고리즘 계산과 완전히 동일하다는 장점이 있다.
그래프 알고리즘은 그래프 처리 엔진 상에서 개발되고 실행된다. 이는 산업적으로 널리 사용되는 SQL 질의를 데이터베이스 관리 시스템(DBMS) 엔진 상에서 개발하고 실행하는 것과 유사한 방식이다.
지금까지는 그래프 알고리즘을 개발하기 위해 먼저 합성 그래프를 생성 및 저장한 후, 이를 다시 그래프 처리 엔진에서 메모리로 적재해 알고리즘을 계산하는 2단계 방법을 사용했다. 그래프 데이터는 그 복잡성으로 인해 전체를 메모리로 적재하는 것이 요구되며, 그래프의 규모가 커지면 대규모 컴퓨터 클러스터 장비가 있어야만 알고리즘을 개발하고 실행할 수 있다는 커다란 단점이 있었다.
김 교수팀은 합성 그래프와 그래프 처리 엔진 분야에서 국제 최고 권위의 학술대회에 매년 논문을 발표하는 등 세계 최고의 기술력을 보유하고 있으며, 그 기술들을 바탕으로 기존 2단계 방법의 문제를 해결했다.
그래프 데이터상에서 그래프 알고리즘이 계산을 위해 접근하는 부분을 짧은 순간 동안 실시간으로 생성해, 마치 그래프 데이터가 존재하는 것처럼 알고리즘을 계산하는 것이다. 이때 그래프 데이터를 아무렇게 실시간 생성하는 것이 아니라 합성 그래프 모델에 따라 생성하고 저장한 것과 동일하도록 실시간 생성하는 것이 핵심 기술 중 하나다.
또한, 그래프 처리 엔진이 실시간으로 생성되는 그래프를 실제 그래프처럼 인식하고 알고리즘을 완전히 동일하게 계산하도록 엔진을 수정한 것이 또 다른 핵심 기술이다.
김민수 교수 연구팀은 T-GPS 기술을 종래의 2단계 방법과 성능을 비교한 결과, 종래의 2단계 방법이 11대의 컴퓨터로 구성된 클러스터에서 10억 개 간선 규모의 그래프를 계산할 수 있었던 반면, T-GPS 기술은 1대의 컴퓨터에서 1조 개 간선 규모의 그래프를 계산할 수 있어 컴퓨터 자원 대비 10,000배 더 큰 규모의 데이터를 처리를 할 수 있음을 확인했다. 또한, 알고리즘 계산 시간도 최대 43배 더 빠름을 확인했다.
교신저자로 참여한 김민수 교수는 "오늘날 거의 모든 IT 분야에서 그래프 데이터를 활용하고 있는바, 연구팀이 개발한 새로운 기술은 그래프 알고리즘의 개발 규모와 효율을 획기적으로 높일 수 있어 산업적 측면에서 파급 효과가 매우 클 것으로 기대한다ˮ 라고 말했다.
이번 연구에는 김 교수의 제자이자 캐나다 워털루 대학에 박사후 연구원으로 재직 중인 박힘찬 박사가 제1 저자로, 김 교수가 교신저자로 참여했으며 지난 22일 그리스 차니아에서 온라인으로 열린 데이터베이스 분야 최고 국제학술대회 중 하나인 IEEE ICDE에서 발표됐다. (논문명 : Trillion-scale Graph Processing Simulation based on Top-Down Graph Upscaling).
한편, 이 연구는 한국연구재단 선도연구센터 사업 및 중견연구자 지원사업, 과기정통부 IITP SW스타랩 사업의 지원을 받아 수행됐다.
2021.04.23 조회수 26979
초대규모 그래프 프로세싱 시뮬레이션 기술 개발
우리 대학 연구진이 오늘날 정보통신(IT) 분야에서 광범위하게 사용되는 그래프 타입의 데이터를 실제로 저장하지 않고도 알고리즘을 계산할 수 있는 `그래프 프로세싱 시뮬레이션'이라는 신개념 기술을 세계 최초로 개발하는 데 성공했다. 데이터를 저장할 필요가 없어 1조 개 간선의 초대규모 그래프도 PC 한 대로 처리가 가능하다.
우리 대학 전산학부 김민수 교수 연구팀은 1조 개 간선의 초대규모 그래프에 대해 데이터 저장 없이 알고리즘을 계산할 수 있는 신개념 기술을 세계 최초로 개발했다고 23일 밝혔다.
오늘날 웹, SNS, 인공지능, 블록체인 등의 광범위한 분야들에서 그래프 타입의 데이터에 대한 다양한 알고리즘들의 연구가 매우 중요하다. 그러나 그래프 데이터의 복잡성으로 인해 그 크기가 커질 때 막대한 규모의 컴퓨터 클러스터가 있어야만 알고리즘 계산이 가능하다는 문제가 있다.
김 교수 연구팀은 이를 근본적으로 해결하는 T-GPS(Trillion-scale Graph Processing Simulation)라는 기술을 개발했다. 이 T-GPS 기술은 그래프 데이터를 실제로 디스크에 저장하지 않고도 마치 그래프 데이터가 저장돼 있는 것처럼 알고리즘을 계산할 수 있고, 계산 결과도 실제 저장된 그래프에 대한 알고리즘 계산과 완전히 동일하다는 장점이 있다.
그래프 알고리즘은 그래프 처리 엔진 상에서 개발되고 실행된다. 이는 산업적으로 널리 사용되는 SQL 질의를 데이터베이스 관리 시스템(DBMS) 엔진 상에서 개발하고 실행하는 것과 유사한 방식이다.
지금까지는 그래프 알고리즘을 개발하기 위해 먼저 합성 그래프를 생성 및 저장한 후, 이를 다시 그래프 처리 엔진에서 메모리로 적재해 알고리즘을 계산하는 2단계 방법을 사용했다. 그래프 데이터는 그 복잡성으로 인해 전체를 메모리로 적재하는 것이 요구되며, 그래프의 규모가 커지면 대규모 컴퓨터 클러스터 장비가 있어야만 알고리즘을 개발하고 실행할 수 있다는 커다란 단점이 있었다.
김 교수팀은 합성 그래프와 그래프 처리 엔진 분야에서 국제 최고 권위의 학술대회에 매년 논문을 발표하는 등 세계 최고의 기술력을 보유하고 있으며, 그 기술들을 바탕으로 기존 2단계 방법의 문제를 해결했다.
그래프 데이터상에서 그래프 알고리즘이 계산을 위해 접근하는 부분을 짧은 순간 동안 실시간으로 생성해, 마치 그래프 데이터가 존재하는 것처럼 알고리즘을 계산하는 것이다. 이때 그래프 데이터를 아무렇게 실시간 생성하는 것이 아니라 합성 그래프 모델에 따라 생성하고 저장한 것과 동일하도록 실시간 생성하는 것이 핵심 기술 중 하나다.
또한, 그래프 처리 엔진이 실시간으로 생성되는 그래프를 실제 그래프처럼 인식하고 알고리즘을 완전히 동일하게 계산하도록 엔진을 수정한 것이 또 다른 핵심 기술이다.
김민수 교수 연구팀은 T-GPS 기술을 종래의 2단계 방법과 성능을 비교한 결과, 종래의 2단계 방법이 11대의 컴퓨터로 구성된 클러스터에서 10억 개 간선 규모의 그래프를 계산할 수 있었던 반면, T-GPS 기술은 1대의 컴퓨터에서 1조 개 간선 규모의 그래프를 계산할 수 있어 컴퓨터 자원 대비 10,000배 더 큰 규모의 데이터를 처리를 할 수 있음을 확인했다. 또한, 알고리즘 계산 시간도 최대 43배 더 빠름을 확인했다.
교신저자로 참여한 김민수 교수는 "오늘날 거의 모든 IT 분야에서 그래프 데이터를 활용하고 있는바, 연구팀이 개발한 새로운 기술은 그래프 알고리즘의 개발 규모와 효율을 획기적으로 높일 수 있어 산업적 측면에서 파급 효과가 매우 클 것으로 기대한다ˮ 라고 말했다.
이번 연구에는 김 교수의 제자이자 캐나다 워털루 대학에 박사후 연구원으로 재직 중인 박힘찬 박사가 제1 저자로, 김 교수가 교신저자로 참여했으며 지난 22일 그리스 차니아에서 온라인으로 열린 데이터베이스 분야 최고 국제학술대회 중 하나인 IEEE ICDE에서 발표됐다. (논문명 : Trillion-scale Graph Processing Simulation based on Top-Down Graph Upscaling).
한편, 이 연구는 한국연구재단 선도연구센터 사업 및 중견연구자 지원사업, 과기정통부 IITP SW스타랩 사업의 지원을 받아 수행됐다.
2021.04.23 조회수 26979 -
 세계 최고 성능을 지닌 데이터베이스 관리 시스템(DBMS) 기술 개발
우리 연구진이 방대한 정보를 저장하고 목적에 맞게 검색, 관리할 수 있는 시스템을 통칭하는 데이터베이스관리시스템(DBMS, DataBase Management System)을 세계 최고 수준의 성능으로 끌어올렸다.
우리 대학 전산학부 김민수 교수 연구팀이 데이터베이스 질의 언어 SQL(Structured Query Language, 구조화 질의어) 처리 성능을 대폭 높인 세계 최고 수준의 DBMS 기술을 개발했다.
김 교수 연구팀은 데이터 처리를 위해 산업 표준으로 사용되는 SQL 질의를 기존 DBMS와는 전혀 다른 방법으로 처리함으로써 성능을 기존 옴니사이(OmniSci) DBMS 대비 최대 88배나 높인 신기술을 개발했다. 김 교수팀이 개발한 이 기술은 오라클·마이크로소프트 SQL서버·IBM DB2 등 타 DBMS에도 적용할 수 있어 고성능 SQL 질의 처리가 필요한 다양한 곳에 폭넓게 적용될 수 있을 것으로 기대된다.
대부분의 DBMS는 SQL 질의를 처리할 때 내부적으로 데이터 테이블들을 `왼쪽 깊은 이진 트리(left-deep binary tree)' 형태로 배치해 처리하는 방법을 사용한다. 지난 수십 년간 상용화돼 온 대부분의 DBMS는 데이터 테이블들의 배치 가능한 가지 수가 기하급수적으로 많기 때문에 이를 `왼쪽 깊은 이진 트리' 형태로 배치해 SQL 질의를 처리해 왔다.
임의의 두 테이블이 기본 키(primary key, PK)와 외래 키(foreign key, FK)라 불리는 관계로 결합(조인 연산)하는 경우에는 이러한 방법으로 SQL 질의를 효과적으로 처리할 수 있다. 여기서 기본 키는 각 데이터 행(row)을 유일하게 식별할 수 있는 열(column)이고, 외래 키는 그렇지 않은 열이다.
지난 수십 년간 산업에서 사용되는 DB의 구조가 점점 복잡해지면서 두 테이블은 PK-FK 관계가 아닌 FK-FK 관계, 즉 외래 키와 외래 키의 관계로 결합하는 복잡한 형태의 SQL 질의들이 많아지고 있다. 실제 DBMS의 성능을 측정하는 산업 표준 벤치마크인 TPC-DS에서 전체 벤치마크의 26%가 이런 복잡한 SQL 질의들로 구성돼 있고 기계학습(머신러닝), 생물 정보학 등 다양한 분야들서도 이러한 복잡한 SQL 질의 사용이 점차 증가하는 추세다.
이전에 나온 DBMS들은 두 테이블이 주로 PK-FK 관계로 결합한다는 가정하에 개발됐기 때문에 FK-FK 결합이 필요한 복잡한 SQL 질의를 매우 느리거나 심지어 처리하지 못하는 실패를 거듭해왔다.
김 교수팀은 문제 해결을 위해 테이블들을 하나의 커다란 `왼쪽 깊은 이진 트리' 형태가 아닌 여러 개의 작은 `왼쪽 깊은 이진 트리'를 `n항 조인 연산자'로 묶는 형태로 배치해 처리하는 기술을 개발했다. 이때 각각의 `작은 이진 트리' 안에는 FK-FK 결합 관계가 발생하지 않도록 테이블들을 배치하는 것이 핵심이다.
각각의 `작은 이진 트리'의 처리 결과물을 `n항 조인 연산자'로 결합해 최종 결과물을 구하는 것도 난제로 꼽히는데 연구팀은 `최악-최적(worst-case optimal) 조인 알고리즘'이라는 방법으로 이 문제를 해결했다.
`최악-최적 조인 알고리즘'은 그래프 데이터를 처리할 때 이론적으로 가장 우수하다고 알려진 알고리즘이다. 김 교수 연구팀은 세계에서 가장 먼저 이 알고리즘을 SQL 질의 처리에 적용해 난제를 해결하는 데 성공했다.
김민수 교수 연구팀은 새로 개발한 DBMS 기술을 GPU 기반의 DBMS 개발업체인 미국 옴니사이(OmniSci)社 제품에 적용한 결과, OmniSci DBMS보다 성능이 최대 88배나 향상된 결과를 얻었다. 또 TPC-DS 벤치마크에서도 세계 최고 수준의 성능을 가진 기존의 상용 DBMS보다 5~20배나 더 빠른 사실을 확인했다. TPC-DS는 DBMS의 성능을 측정하기 위한 산업 표준의 최신 벤치마크이다.
교신저자로 참여한 김민수 교수는 "연구팀이 개발한 새로운 기술은 대부분의 DBMS에 적용할 수 있기 때문에 산업적 측면에서 파급 효과가 매우 클 것으로 기대한다ˮ 라고 말했다.
이번 연구에는 김 교수의 제자이자 미국 옴니사이(OmniSci)社에 재직 중인 남윤민 박사가 제1 저자로, 김 교수가 교신저자로 참여했으며 지난 18일 미국 오리건주 포틀랜드에서 열린 데이터베이스 분야 최고의 국제학술대회로 꼽히는 `시그모드(SIGMOD)'에서 발표됐다. (논문명 : SPRINTER: A Fast n-ary Join Query Processing Method for Complex OLAP Queries).
한편, 이 연구는 한국연구재단 선도연구센터 사업 및 중견연구자 지원사업, 과기정통부 IITP SW스타랩 사업의 지원을 받아 수행됐다.
2020.06.23 조회수 21432
세계 최고 성능을 지닌 데이터베이스 관리 시스템(DBMS) 기술 개발
우리 연구진이 방대한 정보를 저장하고 목적에 맞게 검색, 관리할 수 있는 시스템을 통칭하는 데이터베이스관리시스템(DBMS, DataBase Management System)을 세계 최고 수준의 성능으로 끌어올렸다.
우리 대학 전산학부 김민수 교수 연구팀이 데이터베이스 질의 언어 SQL(Structured Query Language, 구조화 질의어) 처리 성능을 대폭 높인 세계 최고 수준의 DBMS 기술을 개발했다.
김 교수 연구팀은 데이터 처리를 위해 산업 표준으로 사용되는 SQL 질의를 기존 DBMS와는 전혀 다른 방법으로 처리함으로써 성능을 기존 옴니사이(OmniSci) DBMS 대비 최대 88배나 높인 신기술을 개발했다. 김 교수팀이 개발한 이 기술은 오라클·마이크로소프트 SQL서버·IBM DB2 등 타 DBMS에도 적용할 수 있어 고성능 SQL 질의 처리가 필요한 다양한 곳에 폭넓게 적용될 수 있을 것으로 기대된다.
대부분의 DBMS는 SQL 질의를 처리할 때 내부적으로 데이터 테이블들을 `왼쪽 깊은 이진 트리(left-deep binary tree)' 형태로 배치해 처리하는 방법을 사용한다. 지난 수십 년간 상용화돼 온 대부분의 DBMS는 데이터 테이블들의 배치 가능한 가지 수가 기하급수적으로 많기 때문에 이를 `왼쪽 깊은 이진 트리' 형태로 배치해 SQL 질의를 처리해 왔다.
임의의 두 테이블이 기본 키(primary key, PK)와 외래 키(foreign key, FK)라 불리는 관계로 결합(조인 연산)하는 경우에는 이러한 방법으로 SQL 질의를 효과적으로 처리할 수 있다. 여기서 기본 키는 각 데이터 행(row)을 유일하게 식별할 수 있는 열(column)이고, 외래 키는 그렇지 않은 열이다.
지난 수십 년간 산업에서 사용되는 DB의 구조가 점점 복잡해지면서 두 테이블은 PK-FK 관계가 아닌 FK-FK 관계, 즉 외래 키와 외래 키의 관계로 결합하는 복잡한 형태의 SQL 질의들이 많아지고 있다. 실제 DBMS의 성능을 측정하는 산업 표준 벤치마크인 TPC-DS에서 전체 벤치마크의 26%가 이런 복잡한 SQL 질의들로 구성돼 있고 기계학습(머신러닝), 생물 정보학 등 다양한 분야들서도 이러한 복잡한 SQL 질의 사용이 점차 증가하는 추세다.
이전에 나온 DBMS들은 두 테이블이 주로 PK-FK 관계로 결합한다는 가정하에 개발됐기 때문에 FK-FK 결합이 필요한 복잡한 SQL 질의를 매우 느리거나 심지어 처리하지 못하는 실패를 거듭해왔다.
김 교수팀은 문제 해결을 위해 테이블들을 하나의 커다란 `왼쪽 깊은 이진 트리' 형태가 아닌 여러 개의 작은 `왼쪽 깊은 이진 트리'를 `n항 조인 연산자'로 묶는 형태로 배치해 처리하는 기술을 개발했다. 이때 각각의 `작은 이진 트리' 안에는 FK-FK 결합 관계가 발생하지 않도록 테이블들을 배치하는 것이 핵심이다.
각각의 `작은 이진 트리'의 처리 결과물을 `n항 조인 연산자'로 결합해 최종 결과물을 구하는 것도 난제로 꼽히는데 연구팀은 `최악-최적(worst-case optimal) 조인 알고리즘'이라는 방법으로 이 문제를 해결했다.
`최악-최적 조인 알고리즘'은 그래프 데이터를 처리할 때 이론적으로 가장 우수하다고 알려진 알고리즘이다. 김 교수 연구팀은 세계에서 가장 먼저 이 알고리즘을 SQL 질의 처리에 적용해 난제를 해결하는 데 성공했다.
김민수 교수 연구팀은 새로 개발한 DBMS 기술을 GPU 기반의 DBMS 개발업체인 미국 옴니사이(OmniSci)社 제품에 적용한 결과, OmniSci DBMS보다 성능이 최대 88배나 향상된 결과를 얻었다. 또 TPC-DS 벤치마크에서도 세계 최고 수준의 성능을 가진 기존의 상용 DBMS보다 5~20배나 더 빠른 사실을 확인했다. TPC-DS는 DBMS의 성능을 측정하기 위한 산업 표준의 최신 벤치마크이다.
교신저자로 참여한 김민수 교수는 "연구팀이 개발한 새로운 기술은 대부분의 DBMS에 적용할 수 있기 때문에 산업적 측면에서 파급 효과가 매우 클 것으로 기대한다ˮ 라고 말했다.
이번 연구에는 김 교수의 제자이자 미국 옴니사이(OmniSci)社에 재직 중인 남윤민 박사가 제1 저자로, 김 교수가 교신저자로 참여했으며 지난 18일 미국 오리건주 포틀랜드에서 열린 데이터베이스 분야 최고의 국제학술대회로 꼽히는 `시그모드(SIGMOD)'에서 발표됐다. (논문명 : SPRINTER: A Fast n-ary Join Query Processing Method for Complex OLAP Queries).
한편, 이 연구는 한국연구재단 선도연구센터 사업 및 중견연구자 지원사업, 과기정통부 IITP SW스타랩 사업의 지원을 받아 수행됐다.
2020.06.23 조회수 21432