%EC%A0%84%EC%82%B0%ED%95%99%EB%B6%80
-
 가짜 분유는 이제 스마트폰으로 손쉽게 찾아낸다
가짜 분유 파문은 현재까지도 지속적으로 발생하고 있으며 수만 명의 영유아의 생명을 위협하는 심각한 전세계적 문제다. 하지만 이러한 가짜 분유의 진위 여부를 쉽게 확인하는 것은 거의 불가능에 가깝다. 공동연구진은 스마트폰을 활용해 위조 분유를 빠르고 정확하게 탐지하는 시스템을 개발해서 화제가 되고 있다.
우리 대학 전산학부 한준 교수 연구팀이 연세대, POSTECH, 싱가포르국립대와 공동연구를 통해서 스마트폰을 이용한 가짜 분유 탐지 기술을 개발했다고 2일 밝혔다.
한준 교수 연구팀은 스마트폰에 탑재된 일반 카메라만을 사용해 위조 분말을 탐지하는 ‘파우듀(PowDew)’ 시스템을 개발했다. 연구팀이 최초 개발한 이 시스템은 분말 식품의 성분 및 제조 과정 등에 따라 결정되는 고유한 물리적 성질(습윤성 및 다공성 등)과 액체류와의 상호작용을 이용했다.
이 시스템을 활용하면 소비자가 본인의 스마트폰 카메라로 분유 가루 위에 떨어진 물방울의 움직임을 관측해 손쉽게 분유의 진위를 확인할 수 있다고 전했다. 또한 연구팀은 실험을 통해 6개의 서로 다른 분유 브랜드에 대해 최대 96.1%의 높은 정확도로 위조 분유를 탐지할 수 있음을 확인했다.
나아가 이 기술의 응용 분야는 향후 분유 뿐만 아니라 다양한 식품 및 의약품군으로 확장될 수 있을 것으로 기대된다. 소비자뿐만 아니라 유통사 및 정부 기관의 손쉬운 진위 확인도 가능하게 하여 효율적이고 안전한 제품 유통을 가능하게 할 수 있다.
한준 교수는 “이 기술이 소비자들이 쉽게 사용할 수 있는 검사 도구가 되어 시장에 유통되는 위조 분말 식품을 줄이는 데 크게 기여할 것”이라며 “다양한 분야로의 확장을 통해 위조 제품 문제 해결에 앞장서겠다”고 말했다.
연구팀은 해당 연구의 중요성과 혁신성을 인정받아 모바일 컴퓨팅 분야 최고 권위 국제 학술대회인 ‘ACM 모비시스(ACM MobiSys)’에서 2024 최우수논문상(Best Paper Award)을 수상했다.
(논문명: PowDew: Detecting Counterfeit Powdered Food Products using a Commodity Smartphone)
한편 이번 연구는 한국연구재단 중견연구자지원사업의 지원을 받아 수행됐다.
2024.08.02 조회수 6260
가짜 분유는 이제 스마트폰으로 손쉽게 찾아낸다
가짜 분유 파문은 현재까지도 지속적으로 발생하고 있으며 수만 명의 영유아의 생명을 위협하는 심각한 전세계적 문제다. 하지만 이러한 가짜 분유의 진위 여부를 쉽게 확인하는 것은 거의 불가능에 가깝다. 공동연구진은 스마트폰을 활용해 위조 분유를 빠르고 정확하게 탐지하는 시스템을 개발해서 화제가 되고 있다.
우리 대학 전산학부 한준 교수 연구팀이 연세대, POSTECH, 싱가포르국립대와 공동연구를 통해서 스마트폰을 이용한 가짜 분유 탐지 기술을 개발했다고 2일 밝혔다.
한준 교수 연구팀은 스마트폰에 탑재된 일반 카메라만을 사용해 위조 분말을 탐지하는 ‘파우듀(PowDew)’ 시스템을 개발했다. 연구팀이 최초 개발한 이 시스템은 분말 식품의 성분 및 제조 과정 등에 따라 결정되는 고유한 물리적 성질(습윤성 및 다공성 등)과 액체류와의 상호작용을 이용했다.
이 시스템을 활용하면 소비자가 본인의 스마트폰 카메라로 분유 가루 위에 떨어진 물방울의 움직임을 관측해 손쉽게 분유의 진위를 확인할 수 있다고 전했다. 또한 연구팀은 실험을 통해 6개의 서로 다른 분유 브랜드에 대해 최대 96.1%의 높은 정확도로 위조 분유를 탐지할 수 있음을 확인했다.
나아가 이 기술의 응용 분야는 향후 분유 뿐만 아니라 다양한 식품 및 의약품군으로 확장될 수 있을 것으로 기대된다. 소비자뿐만 아니라 유통사 및 정부 기관의 손쉬운 진위 확인도 가능하게 하여 효율적이고 안전한 제품 유통을 가능하게 할 수 있다.
한준 교수는 “이 기술이 소비자들이 쉽게 사용할 수 있는 검사 도구가 되어 시장에 유통되는 위조 분말 식품을 줄이는 데 크게 기여할 것”이라며 “다양한 분야로의 확장을 통해 위조 제품 문제 해결에 앞장서겠다”고 말했다.
연구팀은 해당 연구의 중요성과 혁신성을 인정받아 모바일 컴퓨팅 분야 최고 권위 국제 학술대회인 ‘ACM 모비시스(ACM MobiSys)’에서 2024 최우수논문상(Best Paper Award)을 수상했다.
(논문명: PowDew: Detecting Counterfeit Powdered Food Products using a Commodity Smartphone)
한편 이번 연구는 한국연구재단 중견연구자지원사업의 지원을 받아 수행됐다.
2024.08.02 조회수 6260 -
 로봇 등 온디바이스 인공지능 실현 가능
자율주행차, 로봇 등 온디바이스 자율 시스템 환경에서 클라우드의 원격 컴퓨팅 자원 없이 기기 자체에 내장된 인공지능 칩을 활용한 온디바이스 자원만으로 적응형 AI를 실현하는 기술이 개발됐다.
우리 대학 전산학부 박종세 교수 연구팀이 지난 6월 29일부터 7월 3일까지 아르헨티나 부에노스아이레스에서 열린 ‘2024 국제 컴퓨터구조 심포지엄(International Symposium on Computer Architecture, ISCA 2024)’에서 최우수 연구 기록물상(Distinguished Artifact Award)을 수상했다고 1일 밝혔다.
* 논문명: 자율 시스템의 비디오 분석을 위한 연속학습 가속화 기법(DaCapo: Accelerating Continuous Learning in Autonomous Systems for Video Analytics)
국제 컴퓨터 구조 심포지움(ISCA)은 컴퓨터 아키텍처 분야에서 최고 권위를 자랑하는 국제 학회로 올해는 423편의 논문이 제출됐으며 그중 83편 만이 채택됐다. (채택률 19.6%). 최우수 연구 기록물 상은 학회에서 주어지는 특별한 상 중 하나로, 제출 논문 중 연구 기록물의 혁신성, 활용 가능성, 영향력을 고려해 선정된다.
이번 수상 연구는 적응형 AI의 기반 기술인 ‘연속 학습’ 가속을 위한 NPU(신경망처리장치) 구조 및 온디바이스 소프트웨어 시스템을 최초 개발한 점, 향후 온디바이스 AI 시스템 연구의 지속적인 발전을 위해 오픈소스로 공개한 코드, 데이터 등의 완성도 측면에서 높은 평가를 받았다.
연구 결과는 소프트웨어 중심 자동차(SDV; Software-Defined Vehicles), 소프트웨어 중심 로봇(SDR; Software-Defined Robots)으로 대표되는 미래 모빌리티 환경에서 온디바이스 AI 시스템을 구축하는 등 다양한 분야에 활용될 수 있을 것으로 기대된다.
상을 받은 전산학부 박종세 교수는 “이번 연구를 통해 온디바이스 자원만으로 적응형 AI를 실현할 수 있다는 것을 입증하게 되어 매우 기쁘고 이 성과는 학생들의 헌신적인 노력과 구글 및 메타 연구자들과의 긴밀한 협력 덕분이다”라며, “앞으로도 온디바이스 AI를 위한 하드웨어와 소프트웨어 연구를 지속해 나갈 것이다”라고 소감을 전했다.
이번 연구는 우리 대학 전산학부 김윤성, 오창훈, 황진우, 김원웅, 오성룡, 이유빈 학생들과 메타(Meta)의 하딕 샤르마(Hardik Sharma) 박사, 구글 딥마인드(Google Deepmind)의 아미르 야즈단바크시(Amir Yazdanbakhsh) 박사, 전산학부 박종세 교수가 참여했다.
한편 이번 연구는 한국연구재단 우수신진연구자지원사업, 정보통신기획평가원(IITP), 대학ICT연구센터(ITRC), 인공지능대학원지원사업, 인공지능반도체대학원지원사업의 지원을 받아 수행됐다.
2024.08.01 조회수 6699
로봇 등 온디바이스 인공지능 실현 가능
자율주행차, 로봇 등 온디바이스 자율 시스템 환경에서 클라우드의 원격 컴퓨팅 자원 없이 기기 자체에 내장된 인공지능 칩을 활용한 온디바이스 자원만으로 적응형 AI를 실현하는 기술이 개발됐다.
우리 대학 전산학부 박종세 교수 연구팀이 지난 6월 29일부터 7월 3일까지 아르헨티나 부에노스아이레스에서 열린 ‘2024 국제 컴퓨터구조 심포지엄(International Symposium on Computer Architecture, ISCA 2024)’에서 최우수 연구 기록물상(Distinguished Artifact Award)을 수상했다고 1일 밝혔다.
* 논문명: 자율 시스템의 비디오 분석을 위한 연속학습 가속화 기법(DaCapo: Accelerating Continuous Learning in Autonomous Systems for Video Analytics)
국제 컴퓨터 구조 심포지움(ISCA)은 컴퓨터 아키텍처 분야에서 최고 권위를 자랑하는 국제 학회로 올해는 423편의 논문이 제출됐으며 그중 83편 만이 채택됐다. (채택률 19.6%). 최우수 연구 기록물 상은 학회에서 주어지는 특별한 상 중 하나로, 제출 논문 중 연구 기록물의 혁신성, 활용 가능성, 영향력을 고려해 선정된다.
이번 수상 연구는 적응형 AI의 기반 기술인 ‘연속 학습’ 가속을 위한 NPU(신경망처리장치) 구조 및 온디바이스 소프트웨어 시스템을 최초 개발한 점, 향후 온디바이스 AI 시스템 연구의 지속적인 발전을 위해 오픈소스로 공개한 코드, 데이터 등의 완성도 측면에서 높은 평가를 받았다.
연구 결과는 소프트웨어 중심 자동차(SDV; Software-Defined Vehicles), 소프트웨어 중심 로봇(SDR; Software-Defined Robots)으로 대표되는 미래 모빌리티 환경에서 온디바이스 AI 시스템을 구축하는 등 다양한 분야에 활용될 수 있을 것으로 기대된다.
상을 받은 전산학부 박종세 교수는 “이번 연구를 통해 온디바이스 자원만으로 적응형 AI를 실현할 수 있다는 것을 입증하게 되어 매우 기쁘고 이 성과는 학생들의 헌신적인 노력과 구글 및 메타 연구자들과의 긴밀한 협력 덕분이다”라며, “앞으로도 온디바이스 AI를 위한 하드웨어와 소프트웨어 연구를 지속해 나갈 것이다”라고 소감을 전했다.
이번 연구는 우리 대학 전산학부 김윤성, 오창훈, 황진우, 김원웅, 오성룡, 이유빈 학생들과 메타(Meta)의 하딕 샤르마(Hardik Sharma) 박사, 구글 딥마인드(Google Deepmind)의 아미르 야즈단바크시(Amir Yazdanbakhsh) 박사, 전산학부 박종세 교수가 참여했다.
한편 이번 연구는 한국연구재단 우수신진연구자지원사업, 정보통신기획평가원(IITP), 대학ICT연구센터(ITRC), 인공지능대학원지원사업, 인공지능반도체대학원지원사업의 지원을 받아 수행됐다.
2024.08.01 조회수 6699 -
 혐오 발언 탐지의 문화적 차이 해결, NAACL 2024에서 Resource Award 수상
전산학부 Users & Information Lab. 연구실의 오혜연 교수와 제1저자 석사과정 이나연(오혜연 교수 지도 학생)의 연구가 지난 6월 16일부터 21일까지 멕시코시티에서 열린 '2024 Annual Conference of the North American Chapter of the Association for Computational Linguistics' (NAACL 2024) 국제 학회에서 '교차 문화적 데이터셋 구축을 통한 영어 혐오 발언 어노테이션의 문화 간 차이와 영향 분석(Exploring Cross-Cultural Differences in English Hate Speech Annotations: From Dataset Construction to Analysis)'에 관한 논문으로 '리소스 어워드(Resource Award)'를 수상했다.
NAACL은 자연어처리 분야에서 최고 권위를 자랑하는 국제 학회로, 올해는 2,434편의 논문이 제출되었으며 그 중 565편만이 채택되었다 (채택률 23.2%).
Resource Award는 학회에서 주어지는 특별한 상 중 하나로, 제출 논문 중 혁신성, 활용 가능성, 영향력, 품질을 고려하여 선정된다.
이번 수상 연구는 교차 문화적 영어 혐오 발언 데이터셋을 구축하고, 문화 간 어노테이션 차이와 대형 언어 모델의 편향성을 분석하여 영어 혐오 발언 분류기의 문화적 민감성을 향상시키는 데 기여했다는점에서 높은 평가를 받았다.
이번 연구에는 KAIST 전산학부의 이나연, 정찬이, 명준호, 진지호 학생들과 Cardiff University의 Jose Camacho-Collados 교수, KAIST 전산학부의 김주호 교수, 오혜연 교수가 참여하였다. 본 연구는 미국, 호주, 영국, 싱가포르, 남아프리카 공화국의 5개 영어권 국가에서 수집된 데이터와 어노테이션을 기반으로 하여, 각국의 문화적 배경이 혐오 발언 어노테이션에 미치는 영향을 분석했다. 이를 통해 문화적 배경이 혐오 발언 인식에 미치는 중요한 차이를 밝혀냈으며, 특히 서구권 국가와 다른 문화적 맥락을 가진 국가 간의 어노테이션 차이가 두드러짐을 보였다.
오혜연 교수와 이나연 학생은 "이번 연구를 통해 혐오 발언 탐지에 있어 문화적 차이의 중요성을 밝힐 수 있어 기쁩니다. 연구팀의 노력 덕분에 이러한 성과를 얻을 수 있었으며, 앞으로도 자연어처리 분야에서 문화적 다양성을 고려한 연구를 지속해 나가겠습니다."라고 소감을 전했다.
이번 수상은 KAIST 연구팀의 혁신적인 접근과 자연어처리 분야에서의 문화 간 연구의 중요성을 국제적으로 인정받은 결과이다. 이는 앞으로 관련 연구 발전에 큰 기여를 할 것으로 기대된다.
연구 결과는 혐오 발언 탐지 분야뿐만 아니라, 다문화 사회에서의 인공지능 윤리와 문화적 편향성 해소 등 다양한 분야에 활용될 수 있을 것으로 기대된다.
자세한 내용은 논문 링크(https://aclanthology.org/2024.naacl-long.236)에서 확인할 수 있다.
2024.07.16 조회수 4608
혐오 발언 탐지의 문화적 차이 해결, NAACL 2024에서 Resource Award 수상
전산학부 Users & Information Lab. 연구실의 오혜연 교수와 제1저자 석사과정 이나연(오혜연 교수 지도 학생)의 연구가 지난 6월 16일부터 21일까지 멕시코시티에서 열린 '2024 Annual Conference of the North American Chapter of the Association for Computational Linguistics' (NAACL 2024) 국제 학회에서 '교차 문화적 데이터셋 구축을 통한 영어 혐오 발언 어노테이션의 문화 간 차이와 영향 분석(Exploring Cross-Cultural Differences in English Hate Speech Annotations: From Dataset Construction to Analysis)'에 관한 논문으로 '리소스 어워드(Resource Award)'를 수상했다.
NAACL은 자연어처리 분야에서 최고 권위를 자랑하는 국제 학회로, 올해는 2,434편의 논문이 제출되었으며 그 중 565편만이 채택되었다 (채택률 23.2%).
Resource Award는 학회에서 주어지는 특별한 상 중 하나로, 제출 논문 중 혁신성, 활용 가능성, 영향력, 품질을 고려하여 선정된다.
이번 수상 연구는 교차 문화적 영어 혐오 발언 데이터셋을 구축하고, 문화 간 어노테이션 차이와 대형 언어 모델의 편향성을 분석하여 영어 혐오 발언 분류기의 문화적 민감성을 향상시키는 데 기여했다는점에서 높은 평가를 받았다.
이번 연구에는 KAIST 전산학부의 이나연, 정찬이, 명준호, 진지호 학생들과 Cardiff University의 Jose Camacho-Collados 교수, KAIST 전산학부의 김주호 교수, 오혜연 교수가 참여하였다. 본 연구는 미국, 호주, 영국, 싱가포르, 남아프리카 공화국의 5개 영어권 국가에서 수집된 데이터와 어노테이션을 기반으로 하여, 각국의 문화적 배경이 혐오 발언 어노테이션에 미치는 영향을 분석했다. 이를 통해 문화적 배경이 혐오 발언 인식에 미치는 중요한 차이를 밝혀냈으며, 특히 서구권 국가와 다른 문화적 맥락을 가진 국가 간의 어노테이션 차이가 두드러짐을 보였다.
오혜연 교수와 이나연 학생은 "이번 연구를 통해 혐오 발언 탐지에 있어 문화적 차이의 중요성을 밝힐 수 있어 기쁩니다. 연구팀의 노력 덕분에 이러한 성과를 얻을 수 있었으며, 앞으로도 자연어처리 분야에서 문화적 다양성을 고려한 연구를 지속해 나가겠습니다."라고 소감을 전했다.
이번 수상은 KAIST 연구팀의 혁신적인 접근과 자연어처리 분야에서의 문화 간 연구의 중요성을 국제적으로 인정받은 결과이다. 이는 앞으로 관련 연구 발전에 큰 기여를 할 것으로 기대된다.
연구 결과는 혐오 발언 탐지 분야뿐만 아니라, 다문화 사회에서의 인공지능 윤리와 문화적 편향성 해소 등 다양한 분야에 활용될 수 있을 것으로 기대된다.
자세한 내용은 논문 링크(https://aclanthology.org/2024.naacl-long.236)에서 확인할 수 있다.
2024.07.16 조회수 4608 -
 세계 최대 컴퓨터학회에서 처음 5편 논문 발표
세계 최대 컴퓨터 학회에서 주간한 학술대회(PLDI)에서 2012년에 한국에서 처음 논문을 발표한 이래, KAIST 연구진이 처음으로 3편 이상의 논문을 발표하여 화제다.
우리 대학 전산학부 강지훈 교수, 류석영 교수 연구팀이 프로그래밍 언어 분야 최고 권위 학술대회인 PLDI에서 올해 발표될 89편의 논문 중 6.7%인 5편의 논문을 발표했다고 3일 밝혔다.
PLDI(Programming Language Design and Implementation)는 세계 최대 컴퓨터 학회인 ACM(Association for Computing Machinery)이 주관하는 학술대회로, 지난 45년간 전산학 전체에 깊은 영향을 미치는 중요한 논문이 다수 발표된 유서 깊은 학술대회다. 프로그래밍 언어와 컴파일러 등 소프트웨어 전반의 기초가 되는 핵심 기술을 발표하고 있다.
이번 학회에 발표되는 5개의 논문은 아래와 같다.
1) 멀티코어 컴퓨팅 시스템에서 동작하는 고성능 병렬 자료구조가 사용을 마친 메모리를 수집하기 위해 다양한 기법을 제안 2) 멀티코어 컴퓨팅 시스템에서 성능을 높이기 위해 운영체제, 데이터베이스 등 고성능 시스템 소프트웨어의 안전성을 현실적으로 증명할 수 있는 토대 마련 3) 시스템 반도체의 논리적인 청사진이라 할 수 있는 RTL(register-transfer level) 설계 및 검증비용을 획기적으로 줄일 수 있는 프로그래밍 언어 개발 4) 빠르지만 안정성이 취약한 C 언어로 작성된 프로그램을 더 안전한 러스트(Rust) 언어로 작성된 프로그램으로 자동 변환하는 연구 5) 산업계에서 가장 널리 사용하는 자바스크립트 프로그래밍 언어의 공식 개발 과정에 적용한 기술(https://www.kaist.ac.kr/news/html/news/?mode=V&mng_no=36610)을 기반으로 웹어셈블리 언어에 특화한 연구
강지훈 교수는 “5편의 논문은 각각 학생들이 오랫동안 정성껏 연구한 결과를 담아 뛰어난 독창성과 실용성을 동시에 갖춘 우수한 논문들”이라면서 “이 논문들이 앞으로 지속적으로 프로그래밍 언어와 인접 전산학 분야, 그리고 더 나아가서 산업계에 깊은 영향을 미칠 수 있도록 후속 연구에 정진할 것”이라고 포부를 밝혔다.
류석영 교수는 “반도체, 운영체제, 클라우드 등 인프라부터 사용자에게 제공하는 서비스까지 모두를 아우르는 풀 스택 소프트웨어를 안전하고 올바르게 동작하도록 설계하고 개발하는 세계적인 기술을 선보인 결과”라며, “소프트웨어가 이끄는 세상에서 더 안전하고 올바르게 동작하는 소프트웨어를 사용할 수 있기를 기대한다”고 말했다.
5편의 논문은 한국 시각으로 6월 21일에 PACMPL(Proceedings of the ACM on Programming Languages) 저널에 게재됐고 6월 25일부터 27일 사이에 진행된 PLDI 2024 학술대회에서 발표됐다.
(논문 제목: ① Concurrent Immediate Reference Counting, ② A Proof Recipe for Linearizability in Relaxed Memory Separation Logic, ③ Modular Hardware Design of Pipelined Circuits with Hazards, ④ Don't Write, but Return: Replacing Output Parameters with Algebraic Data Types in C-to-Rust Translation, ⑤ Bringing the WebAssembly Standard up to Speed with SpecTac)
한편 이번 연구는 한국연구재단 선도연구센터, 중견연구자지원사업 및 우수신진연구자지원사업, 정보통신기획평가원(IITP), 삼성전자 미래기술육성센터의 지원을 받아 수행됐다.
2024.07.03 조회수 5589
세계 최대 컴퓨터학회에서 처음 5편 논문 발표
세계 최대 컴퓨터 학회에서 주간한 학술대회(PLDI)에서 2012년에 한국에서 처음 논문을 발표한 이래, KAIST 연구진이 처음으로 3편 이상의 논문을 발표하여 화제다.
우리 대학 전산학부 강지훈 교수, 류석영 교수 연구팀이 프로그래밍 언어 분야 최고 권위 학술대회인 PLDI에서 올해 발표될 89편의 논문 중 6.7%인 5편의 논문을 발표했다고 3일 밝혔다.
PLDI(Programming Language Design and Implementation)는 세계 최대 컴퓨터 학회인 ACM(Association for Computing Machinery)이 주관하는 학술대회로, 지난 45년간 전산학 전체에 깊은 영향을 미치는 중요한 논문이 다수 발표된 유서 깊은 학술대회다. 프로그래밍 언어와 컴파일러 등 소프트웨어 전반의 기초가 되는 핵심 기술을 발표하고 있다.
이번 학회에 발표되는 5개의 논문은 아래와 같다.
1) 멀티코어 컴퓨팅 시스템에서 동작하는 고성능 병렬 자료구조가 사용을 마친 메모리를 수집하기 위해 다양한 기법을 제안 2) 멀티코어 컴퓨팅 시스템에서 성능을 높이기 위해 운영체제, 데이터베이스 등 고성능 시스템 소프트웨어의 안전성을 현실적으로 증명할 수 있는 토대 마련 3) 시스템 반도체의 논리적인 청사진이라 할 수 있는 RTL(register-transfer level) 설계 및 검증비용을 획기적으로 줄일 수 있는 프로그래밍 언어 개발 4) 빠르지만 안정성이 취약한 C 언어로 작성된 프로그램을 더 안전한 러스트(Rust) 언어로 작성된 프로그램으로 자동 변환하는 연구 5) 산업계에서 가장 널리 사용하는 자바스크립트 프로그래밍 언어의 공식 개발 과정에 적용한 기술(https://www.kaist.ac.kr/news/html/news/?mode=V&mng_no=36610)을 기반으로 웹어셈블리 언어에 특화한 연구
강지훈 교수는 “5편의 논문은 각각 학생들이 오랫동안 정성껏 연구한 결과를 담아 뛰어난 독창성과 실용성을 동시에 갖춘 우수한 논문들”이라면서 “이 논문들이 앞으로 지속적으로 프로그래밍 언어와 인접 전산학 분야, 그리고 더 나아가서 산업계에 깊은 영향을 미칠 수 있도록 후속 연구에 정진할 것”이라고 포부를 밝혔다.
류석영 교수는 “반도체, 운영체제, 클라우드 등 인프라부터 사용자에게 제공하는 서비스까지 모두를 아우르는 풀 스택 소프트웨어를 안전하고 올바르게 동작하도록 설계하고 개발하는 세계적인 기술을 선보인 결과”라며, “소프트웨어가 이끄는 세상에서 더 안전하고 올바르게 동작하는 소프트웨어를 사용할 수 있기를 기대한다”고 말했다.
5편의 논문은 한국 시각으로 6월 21일에 PACMPL(Proceedings of the ACM on Programming Languages) 저널에 게재됐고 6월 25일부터 27일 사이에 진행된 PLDI 2024 학술대회에서 발표됐다.
(논문 제목: ① Concurrent Immediate Reference Counting, ② A Proof Recipe for Linearizability in Relaxed Memory Separation Logic, ③ Modular Hardware Design of Pipelined Circuits with Hazards, ④ Don't Write, but Return: Replacing Output Parameters with Algebraic Data Types in C-to-Rust Translation, ⑤ Bringing the WebAssembly Standard up to Speed with SpecTac)
한편 이번 연구는 한국연구재단 선도연구센터, 중견연구자지원사업 및 우수신진연구자지원사업, 정보통신기획평가원(IITP), 삼성전자 미래기술육성센터의 지원을 받아 수행됐다.
2024.07.03 조회수 5589 -
 기업 의사결정을 거대언어모델로 최초 해결
기업 내외의 상황에 따라 끊임없이 새롭게 결정해야 하는 기업 의사결정 문제는 지난 수십 년간 기업들이 전문적인 데이터 분석팀과 고가의 상용 데이터베이스 솔루션들을 통해 해결해 왔는데, 우리 연구진이 최초로 거대언어모델을 이용하여 풀어내어 화제다.
우리 대학 전산학부 김민수 교수 연구팀이 의사결정 문제, 기업 데이터베이스, 비즈니스 규칙 집합 세 가지가 주어졌을 때 거대언어모델을 이용해 의사결정에 필요한 정보를 데이터베이스로부터 찾고, 비즈니스 규칙에 부합하는 최적의 의사결정을 도출할 수 있는 기술(일명 계획 RAG, PlanRAG)을 개발했다고 19일 밝혔다.
거대언어모델은 매우 방대한 데이터를 학습했기 때문에 학습에 사용된 바 없는 데이터를 바탕으로 답변할 때나 오래전 데이터를 바탕으로 답변하는 등 문제점들이 지적되었다. 이런 문제들을 해결하기 위해 거대언어모델이 학습된 내용만으로 답변하는 것 대신, 데이터베이스를 검색해 답변을 생성하는 검색 증강 생성(Retrieval-Augmented Generation; 이하 RAG) 기술이 최근 각광받고 있다.
그러나, 사용자의 질문이 복잡할 경우 다양한 검색 결과를 바탕으로 추가 정보를 다시 검색하여 적절한 답변을 생성할 때까지 반복하는 반복적 RAG(IterativeRAG)라는 기술이 개발됐으며, 이는 현재까지 개발된 가장 최신의 기술이다.
연구팀은 기업 의사결정 문제가 GPT-3.5 터보에서 반복적 RAG 기술을 사용하더라도 정답률이 10% 미만에 이르는 고난도 문제임을 보이고, 이를 해결하기 위해 반복적 RAG 기술을 한층 더 발전시킨 계획 RAG(PlanRAG)라는 기술을 개발했다.
계획 RAG(PlanRAG)는 기존의 RAG 기술들과 다르게 주어진 의사결정 문제, 데이터베이스, 비즈니스 규칙을 바탕으로 어떤 데이터 분석이 필요한지에 대한 거시적 차원의 계획(plan)을 먼저 생성한 후, 그 계획에 따라 반복적 RAG를 이용해 미시적 차원의 분석을 수행한다.
이는 마치 기업의 의사결정권자가 어떤 데이터 분석이 필요한지 계획을 세우면, 그 계획에 따라 데이터 분석팀이 데이터베이스 솔루션들을 이용해 분석하는 형태와 유사하며, 다만 이러한 과정을 모두 사람이 아닌 거대언어모델이 수행하는 것이 커다란 차이점이다. 계획 RAG 기술은 계획에 따른 데이터 분석 결과로 적절한 답변을 도출하지 못하면, 다시 계획을 수립하고 데이터 분석을 수행하는 과정을 반복한다.
김민수 교수는 “지금까지 거대언어모델 기반으로 의사결정 문제를 푼 연구가 없었던 관계로, 기업 의사결정 성능을 평가할 수 있는 의사결정 질의응답(DQA) 벤치마크를 새롭게 만들었다. 그리고 해당 벤치마크에서 GPT-4.0을 사용할 때 종래의 반복적 RAG에 비해 계획 RAG가 의사결정 정답률을 최대 32.5% 개선함을 보였다. 이를 통해 기업들이 복잡한 비즈니스 상황에서 최적의 의사결정을 사람이 아닌 거대언어모델을 이용하여 내리는데 적용되기를 기대한다”고 말했다.
이번 연구에는 김 교수의 제자인 이명화 박사과정과 안선호 석사과정이 공동 제1 저자로, 김 교수가 교신 저자로 참여했으며, 연구 결과는 자연어처리 분야 최고 학회(top conference)인 ‘NAACL’ 에 지난 6월 17일 발표됐다. (논문 제목: PlanRAG: A Plan-then-Retrieval Augmented Generation for Generative Large Language Models as Decision Makers)
한편, 이번 연구는 과기정통부 IITP SW스타랩 및 ITRC 사업, 한국연구재단 선도연구센터인 암흑데이터 극한 활용 연구센터의 지원을 받아 수행됐다.
2024.06.19 조회수 5352
기업 의사결정을 거대언어모델로 최초 해결
기업 내외의 상황에 따라 끊임없이 새롭게 결정해야 하는 기업 의사결정 문제는 지난 수십 년간 기업들이 전문적인 데이터 분석팀과 고가의 상용 데이터베이스 솔루션들을 통해 해결해 왔는데, 우리 연구진이 최초로 거대언어모델을 이용하여 풀어내어 화제다.
우리 대학 전산학부 김민수 교수 연구팀이 의사결정 문제, 기업 데이터베이스, 비즈니스 규칙 집합 세 가지가 주어졌을 때 거대언어모델을 이용해 의사결정에 필요한 정보를 데이터베이스로부터 찾고, 비즈니스 규칙에 부합하는 최적의 의사결정을 도출할 수 있는 기술(일명 계획 RAG, PlanRAG)을 개발했다고 19일 밝혔다.
거대언어모델은 매우 방대한 데이터를 학습했기 때문에 학습에 사용된 바 없는 데이터를 바탕으로 답변할 때나 오래전 데이터를 바탕으로 답변하는 등 문제점들이 지적되었다. 이런 문제들을 해결하기 위해 거대언어모델이 학습된 내용만으로 답변하는 것 대신, 데이터베이스를 검색해 답변을 생성하는 검색 증강 생성(Retrieval-Augmented Generation; 이하 RAG) 기술이 최근 각광받고 있다.
그러나, 사용자의 질문이 복잡할 경우 다양한 검색 결과를 바탕으로 추가 정보를 다시 검색하여 적절한 답변을 생성할 때까지 반복하는 반복적 RAG(IterativeRAG)라는 기술이 개발됐으며, 이는 현재까지 개발된 가장 최신의 기술이다.
연구팀은 기업 의사결정 문제가 GPT-3.5 터보에서 반복적 RAG 기술을 사용하더라도 정답률이 10% 미만에 이르는 고난도 문제임을 보이고, 이를 해결하기 위해 반복적 RAG 기술을 한층 더 발전시킨 계획 RAG(PlanRAG)라는 기술을 개발했다.
계획 RAG(PlanRAG)는 기존의 RAG 기술들과 다르게 주어진 의사결정 문제, 데이터베이스, 비즈니스 규칙을 바탕으로 어떤 데이터 분석이 필요한지에 대한 거시적 차원의 계획(plan)을 먼저 생성한 후, 그 계획에 따라 반복적 RAG를 이용해 미시적 차원의 분석을 수행한다.
이는 마치 기업의 의사결정권자가 어떤 데이터 분석이 필요한지 계획을 세우면, 그 계획에 따라 데이터 분석팀이 데이터베이스 솔루션들을 이용해 분석하는 형태와 유사하며, 다만 이러한 과정을 모두 사람이 아닌 거대언어모델이 수행하는 것이 커다란 차이점이다. 계획 RAG 기술은 계획에 따른 데이터 분석 결과로 적절한 답변을 도출하지 못하면, 다시 계획을 수립하고 데이터 분석을 수행하는 과정을 반복한다.
김민수 교수는 “지금까지 거대언어모델 기반으로 의사결정 문제를 푼 연구가 없었던 관계로, 기업 의사결정 성능을 평가할 수 있는 의사결정 질의응답(DQA) 벤치마크를 새롭게 만들었다. 그리고 해당 벤치마크에서 GPT-4.0을 사용할 때 종래의 반복적 RAG에 비해 계획 RAG가 의사결정 정답률을 최대 32.5% 개선함을 보였다. 이를 통해 기업들이 복잡한 비즈니스 상황에서 최적의 의사결정을 사람이 아닌 거대언어모델을 이용하여 내리는데 적용되기를 기대한다”고 말했다.
이번 연구에는 김 교수의 제자인 이명화 박사과정과 안선호 석사과정이 공동 제1 저자로, 김 교수가 교신 저자로 참여했으며, 연구 결과는 자연어처리 분야 최고 학회(top conference)인 ‘NAACL’ 에 지난 6월 17일 발표됐다. (논문 제목: PlanRAG: A Plan-then-Retrieval Augmented Generation for Generative Large Language Models as Decision Makers)
한편, 이번 연구는 과기정통부 IITP SW스타랩 및 ITRC 사업, 한국연구재단 선도연구센터인 암흑데이터 극한 활용 연구센터의 지원을 받아 수행됐다.
2024.06.19 조회수 5352 -
 자바스크립트 안정성을 책임지다
전 세계에서 가장 널리 사용되는 프로그래밍 언어 중 하나인 자바스크립트*는 컴퓨터 뿐 아니라 스마트폰, 스마트시계 등 다양한 기기에서 동작하기 때문에, 자바스크립트 실행기를 올바르게 구현하는 것이 매우 중요하다. 또한 프로그램 개발 및 배포 과정에서 사용되는 소프트웨어의 안정성 보장이 중요하다.
*자바스크립트: C나 Java와 같이 컴파일 후 사용해야하는 프로그래밍 언어와 달리 코드를 작성하고 바로 실행해 볼 수 있음
우리 대학 전산학부 류석영 교수 연구팀이 고려대 박지혁 교수와 공동연구를 통해 인간 친화적인 형태인 영어로 작성한 자연어 명세에서 컴퓨터에 친화적인 형태인 기계화 명세를 자동으로 추출해 이를 기반으로 자바스크립트 생태계 안정성을 보장하는 기술을 개발하는데 성공했다고 7일 밝혔다.
현재 자바스크립트는 2015년부터 매년 새로운 기능이 추가될 정도로 급성장에 따른 부작용으로 프로그램 실행 중 작동이 되지 않거나 개인 정보 유출 등 언어 생태계의 안정성을 보장하기가 상당히 어려운 상황이다.
연구팀은 이번 기술을 활용하여 크롬 및 엣지와 같은 웹 브라우저에 내장된 자바스크립트 엔진 및 코드 변환 도구에서 수많은 결함을 검출해 내는 데 성공했다. 또한, 자바스크립트용 정적 분석기*를 결함 없이 자동으로 생성하는 데 성공해, 기존 수동으로 개발돼오던 정적 분석기보다 우수한 안정성을 제공했다.
*정적 분석기: 주어진 프로그램을 실행하지 않고 자동으로 분석하는 도구
이러한 장점을 인정받아, 자바스크립트 언어의 명세를 관리하는 위원회에서는 자바스크립트에 새로운 기능을 추가할 때마다 이 기술을 필수적으로 사용하도록 했다. 이 기술은 자바스크립트 언어의 명세를 작성하는 도중에도 결함을 검출할 수 있어서, 자바스크립트 언어의 설계 초기 단계에서 발생할 수 있는 결함을 줄이는 효과를 보였다.
연구팀은 이번 연구를 통해 수년간 논문으로 발표한 결과물들을 산업계에서 널리 사용되는 자바스크립트에 성공적으로 적용, 자바스크립트뿐 아니라 다양한 프로그래밍 언어에도 적용할 수 있는 기틀을 마련했다. 연구팀은 이번 연구를 기반으로, 자바스크립트 후속 언어로 빠르게 성장하고 있는 웹어셈블리 언어에도 관련연구를 적용하고, 네트워크 소프트웨어용 프로그래밍 언어인 P4에 적용하는 연구를 코넬대학 연구팀과 공동으로 진행하고 있다.
연구팀은 모든 연구 결과물을 오픈 소스 SW로 개발해, 누구나 활용할 수 있도록 공개했다. 여러 기기가 스마트 기능을 갖게 되면서 개인 정보 유출 등 심각한 문제가 많이 발생하는 상황에서, 브라우저만 있으면 어느 기기에서나 동작하는 자바스크립트 코드가 올바르게 동작하도록 돕는 데 기여했다.
류석영 교수는 "10년이 넘는 동안 뚝심 있게 자바스크립트를 연구한 학생들의 노력이 만들어 낸 획기적인 기법”이라며, "더 많은 프로그래밍 언어에 적용해, 일상생활에서 더 안전하고 올바르게 동작하는 소프트웨어를 사용할 수 있기를 기대한다”고 말했다.
이번 연구는 컴퓨팅 분야 최고 학술지인 'Communications of the ACM' 2024년 5월호에 게재되고 온라인으로는 4월 24일 발표됐다.
(논문 제목: JavaScript Language Design and Implementation in Tandem,
https://cacm.acm.org/research/javascript-language-design-and-implementation-in-tandem/
https://www.youtube.com/watch?v=JGxc-KIUnQY)
한편 이번 연구는 한국연구재단 중견연구자지원사업 및 선도연구센터와 정보통신기획평가원(IITP), 삼성전자의 지원을 받아 수행됐다.
2024.05.07 조회수 7128
자바스크립트 안정성을 책임지다
전 세계에서 가장 널리 사용되는 프로그래밍 언어 중 하나인 자바스크립트*는 컴퓨터 뿐 아니라 스마트폰, 스마트시계 등 다양한 기기에서 동작하기 때문에, 자바스크립트 실행기를 올바르게 구현하는 것이 매우 중요하다. 또한 프로그램 개발 및 배포 과정에서 사용되는 소프트웨어의 안정성 보장이 중요하다.
*자바스크립트: C나 Java와 같이 컴파일 후 사용해야하는 프로그래밍 언어와 달리 코드를 작성하고 바로 실행해 볼 수 있음
우리 대학 전산학부 류석영 교수 연구팀이 고려대 박지혁 교수와 공동연구를 통해 인간 친화적인 형태인 영어로 작성한 자연어 명세에서 컴퓨터에 친화적인 형태인 기계화 명세를 자동으로 추출해 이를 기반으로 자바스크립트 생태계 안정성을 보장하는 기술을 개발하는데 성공했다고 7일 밝혔다.
현재 자바스크립트는 2015년부터 매년 새로운 기능이 추가될 정도로 급성장에 따른 부작용으로 프로그램 실행 중 작동이 되지 않거나 개인 정보 유출 등 언어 생태계의 안정성을 보장하기가 상당히 어려운 상황이다.
연구팀은 이번 기술을 활용하여 크롬 및 엣지와 같은 웹 브라우저에 내장된 자바스크립트 엔진 및 코드 변환 도구에서 수많은 결함을 검출해 내는 데 성공했다. 또한, 자바스크립트용 정적 분석기*를 결함 없이 자동으로 생성하는 데 성공해, 기존 수동으로 개발돼오던 정적 분석기보다 우수한 안정성을 제공했다.
*정적 분석기: 주어진 프로그램을 실행하지 않고 자동으로 분석하는 도구
이러한 장점을 인정받아, 자바스크립트 언어의 명세를 관리하는 위원회에서는 자바스크립트에 새로운 기능을 추가할 때마다 이 기술을 필수적으로 사용하도록 했다. 이 기술은 자바스크립트 언어의 명세를 작성하는 도중에도 결함을 검출할 수 있어서, 자바스크립트 언어의 설계 초기 단계에서 발생할 수 있는 결함을 줄이는 효과를 보였다.
연구팀은 이번 연구를 통해 수년간 논문으로 발표한 결과물들을 산업계에서 널리 사용되는 자바스크립트에 성공적으로 적용, 자바스크립트뿐 아니라 다양한 프로그래밍 언어에도 적용할 수 있는 기틀을 마련했다. 연구팀은 이번 연구를 기반으로, 자바스크립트 후속 언어로 빠르게 성장하고 있는 웹어셈블리 언어에도 관련연구를 적용하고, 네트워크 소프트웨어용 프로그래밍 언어인 P4에 적용하는 연구를 코넬대학 연구팀과 공동으로 진행하고 있다.
연구팀은 모든 연구 결과물을 오픈 소스 SW로 개발해, 누구나 활용할 수 있도록 공개했다. 여러 기기가 스마트 기능을 갖게 되면서 개인 정보 유출 등 심각한 문제가 많이 발생하는 상황에서, 브라우저만 있으면 어느 기기에서나 동작하는 자바스크립트 코드가 올바르게 동작하도록 돕는 데 기여했다.
류석영 교수는 "10년이 넘는 동안 뚝심 있게 자바스크립트를 연구한 학생들의 노력이 만들어 낸 획기적인 기법”이라며, "더 많은 프로그래밍 언어에 적용해, 일상생활에서 더 안전하고 올바르게 동작하는 소프트웨어를 사용할 수 있기를 기대한다”고 말했다.
이번 연구는 컴퓨팅 분야 최고 학술지인 'Communications of the ACM' 2024년 5월호에 게재되고 온라인으로는 4월 24일 발표됐다.
(논문 제목: JavaScript Language Design and Implementation in Tandem,
https://cacm.acm.org/research/javascript-language-design-and-implementation-in-tandem/
https://www.youtube.com/watch?v=JGxc-KIUnQY)
한편 이번 연구는 한국연구재단 중견연구자지원사업 및 선도연구센터와 정보통신기획평가원(IITP), 삼성전자의 지원을 받아 수행됐다.
2024.05.07 조회수 7128 -
 GPU에서 대규모 출력데이터 난제 해결
국내 연구진이 인공지능(AI) 등에 널리 사용되는 그래픽 연산 장치(이하 GPU)에서 메모리 크기의 한계로 인해 초병렬 연산*의 결과로 대규모 출력 데이터가 발생할 때 이를 잘 처리하지 못하던 난제를 해결했다. 이 기술을 통해 향후 가정에서 사용하는 메모리 크기가 작은 GPU로도 생성형 AI 등 고난이도 연산이 대규모 출력을 필요한 경우 이를 빠르게 수행할 수 있다.
*초병렬 연산: GPU를 이용하여 수 십 만에서 수 백 만 개의 작은 연산들을 동시에 수행하는 연산을 의미
우리 대학은 전산학부 김민수 교수 연구팀이 한정된 크기의 메모리를 지닌 GPU를 이용해 수십, 수백 만개 이상의 스레드들로 초병렬 연산을 하면서 수 테라바이트의 큰 출력 데이터*를 발생시킬 경우에도 메모리 에러를 발생시키지 않고 해당 출력 데이터를 메인 메모리로 고속으로 전송 및 저장할 수 있는 데이터 처리 기술(일명 INFINEL)을 개발했다고 7일 밝혔다.
*출력데이터: 데이터 분석 결과 또는 인공지능에 의한 생성 결과물에 해당하는 데이터
최근 AI의 활용이 급속히 증가하면서 지식 그래프와 같이 정점과 간선으로 이루어진 그래프 구조의 데이터의 구축과 사용도 점점 증가하고 있는데, 그래프 구조의 데이터에 대해 난이도가 높은 초병렬 연산을 수행할 경우 그 출력 결과가 매우 크고, 각 스레드의 출력 크기를 예측하기 어렵다는 문제점이 발생한다.
또한, GPU는 근본적으로 CPU와 달리 메모리 관리 기능이 매우 제한적이기 때문에 예측할 수 없는 대규모의 데이터를 유연하게 관리하기 어렵다는 문제가 있다. 이러한 이유로 지금까지는 GPU를 활용해 ‘삼각형 나열’과 같은 난이도가 높은 그래프 초병렬 연산을 수행할 수 없었다.
김 교수팀은 이를 근본적으로 해결하는 INFINEL 기술을 개발했다. 해당 기술은 GPU 메모리의 일부 공간을 수백 만개 이상의 청크(chunk)라 불리는 매우 작은 크기의 단위들로 나누고 관리하면서, 초병렬 연산 내용이 담긴 GPU 커널(kernel) 프로그램을 실행하면서 각 스레드가 메모리 충돌 없이 빠르게 자신이 필요한 청크 메모리들을 할당받아 자신의 출력 데이터를 저장할 수 있도록 한다.
또한, GPU 메모리가 가득 차도 무중단 방식으로 초병렬 연산과 결과 출력 및 저장을 지속할 수 있도록 한다. 따라서 이 기술을 사용하면 가정에서 사용하는 메모리 크기가 작은 GPU로도 수 테라 바이트 이상의 출력 데이터가 발생하는 고난이도 연산을 빠르게 수행할 수 있다.
김민수 교수 연구팀은 INFINEL 기술의 성능을 다양한 실험 환경과 데이터 셋을 통해 검증했으며, 종래의 최고 성능 동적 메모리 관리자 기술에 비해 약 55배, 커널을 2번 실행하는 2단계 기술에 비해 약 32배 연산 성능을 향상함을 보였다.
교신저자로 참여한 우리 대학 전산학부 김민수 교수는 “생성형 AI나 메타버스 시대에는 GPU 컴퓨팅의 대규모 출력 데이터를 빠르게 처리할 수 있는 기술이 중요해질 것으로 예상되며, INFINEL 기술이 그 일부 역할을 할 수 있을 것”이라고 말했다.
이번 연구에는 김 교수의 제자인 박성우 박사과정이 제1 저자로, 김 교수가 창업한 그래프 딥테크 기업인 (주)그래파이 소속의 오세연 연구원이 제 2 저자로, 김 교수가 교신 저자로 참여하였으며, 국제 학술지 ‘PPoPP’에 3월 4일자 발표됐다. (INFINEL: An efficient GPU-based processing method for unpredictable large output graph queries)
한편, 이번 연구는 과기정통부 IITP SW스타랩 및 ITRC 사업, 한국연구재단 선도연구센터인 암흑데이터 극한 활용 연구센터의 지원을 받아 수행됐다.
2024.03.07 조회수 6721
GPU에서 대규모 출력데이터 난제 해결
국내 연구진이 인공지능(AI) 등에 널리 사용되는 그래픽 연산 장치(이하 GPU)에서 메모리 크기의 한계로 인해 초병렬 연산*의 결과로 대규모 출력 데이터가 발생할 때 이를 잘 처리하지 못하던 난제를 해결했다. 이 기술을 통해 향후 가정에서 사용하는 메모리 크기가 작은 GPU로도 생성형 AI 등 고난이도 연산이 대규모 출력을 필요한 경우 이를 빠르게 수행할 수 있다.
*초병렬 연산: GPU를 이용하여 수 십 만에서 수 백 만 개의 작은 연산들을 동시에 수행하는 연산을 의미
우리 대학은 전산학부 김민수 교수 연구팀이 한정된 크기의 메모리를 지닌 GPU를 이용해 수십, 수백 만개 이상의 스레드들로 초병렬 연산을 하면서 수 테라바이트의 큰 출력 데이터*를 발생시킬 경우에도 메모리 에러를 발생시키지 않고 해당 출력 데이터를 메인 메모리로 고속으로 전송 및 저장할 수 있는 데이터 처리 기술(일명 INFINEL)을 개발했다고 7일 밝혔다.
*출력데이터: 데이터 분석 결과 또는 인공지능에 의한 생성 결과물에 해당하는 데이터
최근 AI의 활용이 급속히 증가하면서 지식 그래프와 같이 정점과 간선으로 이루어진 그래프 구조의 데이터의 구축과 사용도 점점 증가하고 있는데, 그래프 구조의 데이터에 대해 난이도가 높은 초병렬 연산을 수행할 경우 그 출력 결과가 매우 크고, 각 스레드의 출력 크기를 예측하기 어렵다는 문제점이 발생한다.
또한, GPU는 근본적으로 CPU와 달리 메모리 관리 기능이 매우 제한적이기 때문에 예측할 수 없는 대규모의 데이터를 유연하게 관리하기 어렵다는 문제가 있다. 이러한 이유로 지금까지는 GPU를 활용해 ‘삼각형 나열’과 같은 난이도가 높은 그래프 초병렬 연산을 수행할 수 없었다.
김 교수팀은 이를 근본적으로 해결하는 INFINEL 기술을 개발했다. 해당 기술은 GPU 메모리의 일부 공간을 수백 만개 이상의 청크(chunk)라 불리는 매우 작은 크기의 단위들로 나누고 관리하면서, 초병렬 연산 내용이 담긴 GPU 커널(kernel) 프로그램을 실행하면서 각 스레드가 메모리 충돌 없이 빠르게 자신이 필요한 청크 메모리들을 할당받아 자신의 출력 데이터를 저장할 수 있도록 한다.
또한, GPU 메모리가 가득 차도 무중단 방식으로 초병렬 연산과 결과 출력 및 저장을 지속할 수 있도록 한다. 따라서 이 기술을 사용하면 가정에서 사용하는 메모리 크기가 작은 GPU로도 수 테라 바이트 이상의 출력 데이터가 발생하는 고난이도 연산을 빠르게 수행할 수 있다.
김민수 교수 연구팀은 INFINEL 기술의 성능을 다양한 실험 환경과 데이터 셋을 통해 검증했으며, 종래의 최고 성능 동적 메모리 관리자 기술에 비해 약 55배, 커널을 2번 실행하는 2단계 기술에 비해 약 32배 연산 성능을 향상함을 보였다.
교신저자로 참여한 우리 대학 전산학부 김민수 교수는 “생성형 AI나 메타버스 시대에는 GPU 컴퓨팅의 대규모 출력 데이터를 빠르게 처리할 수 있는 기술이 중요해질 것으로 예상되며, INFINEL 기술이 그 일부 역할을 할 수 있을 것”이라고 말했다.
이번 연구에는 김 교수의 제자인 박성우 박사과정이 제1 저자로, 김 교수가 창업한 그래프 딥테크 기업인 (주)그래파이 소속의 오세연 연구원이 제 2 저자로, 김 교수가 교신 저자로 참여하였으며, 국제 학술지 ‘PPoPP’에 3월 4일자 발표됐다. (INFINEL: An efficient GPU-based processing method for unpredictable large output graph queries)
한편, 이번 연구는 과기정통부 IITP SW스타랩 및 ITRC 사업, 한국연구재단 선도연구센터인 암흑데이터 극한 활용 연구센터의 지원을 받아 수행됐다.
2024.03.07 조회수 6721 -
 구글딥마인드와 공동연구를 통해 인공지능으로 시각을 상상하다
‘노란 포도'나 `보라색 바나나'와 같이 본 적 없는 시각 개념을 이해하고 상상하는 인공지능 능력 구현이 가능해졌다.
우리 대학 전산학부 안성진 교수 연구팀이 구글 딥마인드 및 미국 럿거스 대학교와의 국제 공동 연구를 통해 시각적 지식을 체계적으로 조합해 새로운 개념을 이해하는 인공지능 새로운 모델과 프로그램을 수행하는 벤치마크를 개발했다고 30일 밝혔다.
인간은 `보라색 포도'와 `노란 바나나' 같은 개념을 학습하고, 이를 분리한 뒤 재조합해 `노란 포도'나 `보라색 바나나'와 같이 본 적 없는 개념을 상상하는 능력이 있다. 이런 능력은 체계적 일반화 혹은 조합적 일반화라고 불리며, 범용 인공지능을 구현하는 데 있어 핵심적인 요소로 여겨진다.
체계적 일반화 문제는 1988년 미국의 저명한 인지과학자 제리 포더(Jerry Fodor)와 제논 필리쉰(Zenon Pylyshyn)이 인공신경망이 이 문제를 해결할 수 없다고 주장한 이후, 35년 동안 인공지능 딥러닝 분야에서 큰 도전 과제로 남아 있다. 이 문제는 언어뿐만 아니라 시각 정보에서도 발생하지만, 지금까지는 주로 언어의 체계적 일반화에만 초점이 맞춰져 있었고, 시각 정보에 관한 연구는 상대적으로 부족했다.
안성진 교수가 이끄는 국제 공동 연구팀은 이러한 공백을 메우고자 시각 정보에 대한 체계적 일반화를 연구할 수 있는 벤치마크를 개발했다. 시각 정보는 언어와는 달리 명확한 `단어'나 `토큰'의 구조가 없어, 이 구조를 학습하고 체계적 일반화를 달성하는 것이 큰 도전이다.
연구를 주도한 안성진 교수는 “시각 정보의 체계적 일반화가 범용 인공지능을 달성하기 위해 필수적인 능력이며 이 연구를 통해 인공지능의 추론능력과 상상능력 관련 분야의 발전을 가속할 것으로 기대한다”고 말했다.
또한, 딥마인드의 책임 연구원으로 연구에 참여한 연구원이자 현재 스위스 로잔연방공과대학교(EPFL)의 찰라 걸셔(Caglar Gulcehre) 교수는 “체계적 일반화가 가능해지면 현재보다 훨씬 적은 데이터로 더 높은 성능을 낼 수 있게 될 것이다”라고 전했다.
이번 연구는 12월 10일부터 16일까지 미국 뉴올리언스에서 열리는 제37회 신경정보처리학회(NeurIPS)에서 발표될 예정이다.
관련논문: “Imagine the Unseen World: A Benchmark for Systematic Generalization in Visual World Models”, Yeongbin Kim, Gautam Singh, Junyeong Park, Caglar Gulcehre, Sungjin Ahn, NeurIPS 23
2023.11.30 조회수 7958
구글딥마인드와 공동연구를 통해 인공지능으로 시각을 상상하다
‘노란 포도'나 `보라색 바나나'와 같이 본 적 없는 시각 개념을 이해하고 상상하는 인공지능 능력 구현이 가능해졌다.
우리 대학 전산학부 안성진 교수 연구팀이 구글 딥마인드 및 미국 럿거스 대학교와의 국제 공동 연구를 통해 시각적 지식을 체계적으로 조합해 새로운 개념을 이해하는 인공지능 새로운 모델과 프로그램을 수행하는 벤치마크를 개발했다고 30일 밝혔다.
인간은 `보라색 포도'와 `노란 바나나' 같은 개념을 학습하고, 이를 분리한 뒤 재조합해 `노란 포도'나 `보라색 바나나'와 같이 본 적 없는 개념을 상상하는 능력이 있다. 이런 능력은 체계적 일반화 혹은 조합적 일반화라고 불리며, 범용 인공지능을 구현하는 데 있어 핵심적인 요소로 여겨진다.
체계적 일반화 문제는 1988년 미국의 저명한 인지과학자 제리 포더(Jerry Fodor)와 제논 필리쉰(Zenon Pylyshyn)이 인공신경망이 이 문제를 해결할 수 없다고 주장한 이후, 35년 동안 인공지능 딥러닝 분야에서 큰 도전 과제로 남아 있다. 이 문제는 언어뿐만 아니라 시각 정보에서도 발생하지만, 지금까지는 주로 언어의 체계적 일반화에만 초점이 맞춰져 있었고, 시각 정보에 관한 연구는 상대적으로 부족했다.
안성진 교수가 이끄는 국제 공동 연구팀은 이러한 공백을 메우고자 시각 정보에 대한 체계적 일반화를 연구할 수 있는 벤치마크를 개발했다. 시각 정보는 언어와는 달리 명확한 `단어'나 `토큰'의 구조가 없어, 이 구조를 학습하고 체계적 일반화를 달성하는 것이 큰 도전이다.
연구를 주도한 안성진 교수는 “시각 정보의 체계적 일반화가 범용 인공지능을 달성하기 위해 필수적인 능력이며 이 연구를 통해 인공지능의 추론능력과 상상능력 관련 분야의 발전을 가속할 것으로 기대한다”고 말했다.
또한, 딥마인드의 책임 연구원으로 연구에 참여한 연구원이자 현재 스위스 로잔연방공과대학교(EPFL)의 찰라 걸셔(Caglar Gulcehre) 교수는 “체계적 일반화가 가능해지면 현재보다 훨씬 적은 데이터로 더 높은 성능을 낼 수 있게 될 것이다”라고 전했다.
이번 연구는 12월 10일부터 16일까지 미국 뉴올리언스에서 열리는 제37회 신경정보처리학회(NeurIPS)에서 발표될 예정이다.
관련논문: “Imagine the Unseen World: A Benchmark for Systematic Generalization in Visual World Models”, Yeongbin Kim, Gautam Singh, Junyeong Park, Caglar Gulcehre, Sungjin Ahn, NeurIPS 23
2023.11.30 조회수 7958 -
 인공지능으로 북한 등 경제지표 추정하다
유엔기구(UN)의 지속가능발전목표(SDGs)에 따르면 하루 2달러 이하로 생활하는 절대빈곤 인구가 7억 명에 달하지만 그 빈곤의 현황을 제대로 파악하기는 쉽지 않다. 전 세계 중 53개국은 지난 15년 동안 농업 관련 현황 조사를 하지 못했으며, 17개국은 인구 센서스(인구주택 총조사)조차 진행하지 못했다. 이러한 데이터 부족을 극복하려는 시도로, 누구나 웹에서 받아볼 수 있는 인공위성 영상을 활용해 경제 지표를 추정하는 기술이 주목받고 있다.
우리 대학 차미영-김지희 교수 연구팀이 기초과학연구원, 서강대, 홍콩과기대(HKUST), 싱가포르국립대(NUS)와 국제공동연구를 통해 주간 위성영상을 활용해 경제 상황을 분석하는 새로운 인공지능(AI) 기법을 개발했다고 21일 밝혔다. 연구팀이 주목한 것은 기존 통계자료를 기반으로 학습하는 일반적인 환경이 아닌, 기초 통계도 미비한 최빈국(最貧國)까지 모니터링할 수 있는 범용적인 모델이다.
연구팀은 유럽우주국(ESA)이 운용하며 무료로 공개하는 센티넬-2(Sentinel-2) 위성영상을 활용했다. 연구팀은 먼저 위성영상을 약 6제곱킬로미터(2.5×2.5㎢)의 작은 구역으로 세밀하게 분할한 후, 각 구역의 경제 지표를 건물, 도로, 녹지 등의 시각적 정보를 기반으로 AI 기법을 통해 수치화했다.
이번 연구 모델이 이전 연구와 차별화된 점은 기초 데이터가 부족한 지역에도 적용할 수 있게끔 인간이 제시하는 정보를 인공지능의 예측에 반영하는 `인간-기계 협업 알고리즘'에 있다. 즉, 인간이 위성영상을 보고 경제 활동의 많고 적음을 비교하면, 기계는 이러한 인간이 제공한 정보를 학습하여 각각의 영상자료에 경제 점수를 부여한다. 검증 결과, 기계학습만 사용했을 때보다 인간과 협업할 경우 성능이 월등히 우수했다.
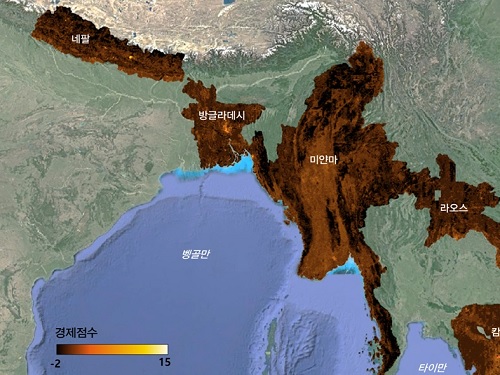
이번 연구를 통해 연구팀은 기존 통계자료가 부족한 지역까지 경제분석의 범위를 확장하고, 북한 및 아시아 5개국(네팔, 라오스, 미얀마, 방글라데시, 캄보디아)에도 같은 기술을 적용하여 세밀한 경제 지표 점수를 공개했다. (그림 1) 이 연구가 제시한 경제 지표는 기존의 인구밀도, 고용 수, 사업체 수 등의 사회경제지표와 높은 상관관계를 보였으며, 데이터가 부족한 저개발국가에 적용 가능함을 연구팀은 확인했다.
이러한 변화탐지를 북한에 적용한 결과, 대북 경제제재가 심화된 2016년과 2019년 사이에 북한 경제에서 세 가지 경향을 발견할 수 있었다. 첫째, 북한의 경제 발전은 평양과 대도시에 더욱 집중되어 도시와 농촌 간 격차가 심화됐다. 둘째, 경제제재와 달러 외환의 부족을 극복하기 위해 설치한 관광 경제개발구에서는 새로운 건물 건설 등 유의미한 변화가 위성영상 이미지와 연구의 경제 지표 점수 변화에서 드러났다. 셋째, 전통적인 공업 및 수출 경제개발구 유형에서는 반대로 변화가 미미한 것으로 확인됐다.
연구에 참여한 우리 대학 전산학부·IBS 데이터사이언스그룹 CI 차미영 교수는 "전산학, 경제학, 지리학이 융합된 이번 연구는 범지구적 차원의 빈곤 문제를 다룬다는 점에서 중요한 의미가 있으며, 이번에 개발한 인공지능 알고리즘을 앞으로 이산화탄소 배출량, 재해재난 피해 탐지, 기후 변화로 인한 영향 등 다양한 국제사회 문제에 적용해 볼 계획이다ˮ 라고 말했다.
이 연구에는 경제학자인 우리 대학 기술경영학부 김지희 교수, 서강대 경제학과 양현주 교수, 홍콩과기대 박상윤 교수도 함께 참여하였다. 이들은 “이 모델은 저비용으로 개발도상국의 경제 상황을 상세하게 확인할 수 있어 국제개발협력(ODA) 사업에 도움을 줄 수 있을 것으로 예상된다”며 “이번 연구가 선진국과 후진국 간의 데이터 격차를 줄이고 유엔과 국제사회의 공동목표인 지속가능한 발전을 달성하는 데 기여할 수 있기를 바란다ˮ고 밝혔다.
위성영상과 인공지능을 활용한 SDGs 지표의 개발과 이의 정책적 활용은 국제적인 주목을 받고 있는 기술 분야 중 하나이며 한국이 앞으로 주도권을 가지고 이끌 수 있는 연구 분야이다. 이에 연구팀은 개발한 모델 코드를 무료로 공개하며, 측정한 지표가 여러 국가의 정책 설계 및 평가에 유용하게 사용될 수 있도록 앞으로도 기술을 개선하고 매해 새롭게 업데이트되는 인공위성 영상에 적용하여 공개할 계획이다.
한편 이번 연구 결과는 전산학부 안동현 박사과정, 싱가포르 국립대 양재석 박사과정이 공동 1저자로 국제 학술지 네이처 출판 그룹의 `네이처 커뮤니케이션즈(Nature Communications)'에 지난 10월 26일 자 게재됐다. (논문명: A human-machine collaborative approach measures economic development using satellite imagery, 인간-기계 협업과 위성영상 분석에 기반한 경제 발전 측정).
논문링크: https://www.nature.com/articles/s41467-023-42122-8
2023.11.21 조회수 9138
인공지능으로 북한 등 경제지표 추정하다
유엔기구(UN)의 지속가능발전목표(SDGs)에 따르면 하루 2달러 이하로 생활하는 절대빈곤 인구가 7억 명에 달하지만 그 빈곤의 현황을 제대로 파악하기는 쉽지 않다. 전 세계 중 53개국은 지난 15년 동안 농업 관련 현황 조사를 하지 못했으며, 17개국은 인구 센서스(인구주택 총조사)조차 진행하지 못했다. 이러한 데이터 부족을 극복하려는 시도로, 누구나 웹에서 받아볼 수 있는 인공위성 영상을 활용해 경제 지표를 추정하는 기술이 주목받고 있다.
우리 대학 차미영-김지희 교수 연구팀이 기초과학연구원, 서강대, 홍콩과기대(HKUST), 싱가포르국립대(NUS)와 국제공동연구를 통해 주간 위성영상을 활용해 경제 상황을 분석하는 새로운 인공지능(AI) 기법을 개발했다고 21일 밝혔다. 연구팀이 주목한 것은 기존 통계자료를 기반으로 학습하는 일반적인 환경이 아닌, 기초 통계도 미비한 최빈국(最貧國)까지 모니터링할 수 있는 범용적인 모델이다.
연구팀은 유럽우주국(ESA)이 운용하며 무료로 공개하는 센티넬-2(Sentinel-2) 위성영상을 활용했다. 연구팀은 먼저 위성영상을 약 6제곱킬로미터(2.5×2.5㎢)의 작은 구역으로 세밀하게 분할한 후, 각 구역의 경제 지표를 건물, 도로, 녹지 등의 시각적 정보를 기반으로 AI 기법을 통해 수치화했다.
이번 연구 모델이 이전 연구와 차별화된 점은 기초 데이터가 부족한 지역에도 적용할 수 있게끔 인간이 제시하는 정보를 인공지능의 예측에 반영하는 `인간-기계 협업 알고리즘'에 있다. 즉, 인간이 위성영상을 보고 경제 활동의 많고 적음을 비교하면, 기계는 이러한 인간이 제공한 정보를 학습하여 각각의 영상자료에 경제 점수를 부여한다. 검증 결과, 기계학습만 사용했을 때보다 인간과 협업할 경우 성능이 월등히 우수했다.
이번 연구를 통해 연구팀은 기존 통계자료가 부족한 지역까지 경제분석의 범위를 확장하고, 북한 및 아시아 5개국(네팔, 라오스, 미얀마, 방글라데시, 캄보디아)에도 같은 기술을 적용하여 세밀한 경제 지표 점수를 공개했다. (그림 1) 이 연구가 제시한 경제 지표는 기존의 인구밀도, 고용 수, 사업체 수 등의 사회경제지표와 높은 상관관계를 보였으며, 데이터가 부족한 저개발국가에 적용 가능함을 연구팀은 확인했다.
이러한 변화탐지를 북한에 적용한 결과, 대북 경제제재가 심화된 2016년과 2019년 사이에 북한 경제에서 세 가지 경향을 발견할 수 있었다. 첫째, 북한의 경제 발전은 평양과 대도시에 더욱 집중되어 도시와 농촌 간 격차가 심화됐다. 둘째, 경제제재와 달러 외환의 부족을 극복하기 위해 설치한 관광 경제개발구에서는 새로운 건물 건설 등 유의미한 변화가 위성영상 이미지와 연구의 경제 지표 점수 변화에서 드러났다. 셋째, 전통적인 공업 및 수출 경제개발구 유형에서는 반대로 변화가 미미한 것으로 확인됐다.
연구에 참여한 우리 대학 전산학부·IBS 데이터사이언스그룹 CI 차미영 교수는 "전산학, 경제학, 지리학이 융합된 이번 연구는 범지구적 차원의 빈곤 문제를 다룬다는 점에서 중요한 의미가 있으며, 이번에 개발한 인공지능 알고리즘을 앞으로 이산화탄소 배출량, 재해재난 피해 탐지, 기후 변화로 인한 영향 등 다양한 국제사회 문제에 적용해 볼 계획이다ˮ 라고 말했다.
이 연구에는 경제학자인 우리 대학 기술경영학부 김지희 교수, 서강대 경제학과 양현주 교수, 홍콩과기대 박상윤 교수도 함께 참여하였다. 이들은 “이 모델은 저비용으로 개발도상국의 경제 상황을 상세하게 확인할 수 있어 국제개발협력(ODA) 사업에 도움을 줄 수 있을 것으로 예상된다”며 “이번 연구가 선진국과 후진국 간의 데이터 격차를 줄이고 유엔과 국제사회의 공동목표인 지속가능한 발전을 달성하는 데 기여할 수 있기를 바란다ˮ고 밝혔다.
위성영상과 인공지능을 활용한 SDGs 지표의 개발과 이의 정책적 활용은 국제적인 주목을 받고 있는 기술 분야 중 하나이며 한국이 앞으로 주도권을 가지고 이끌 수 있는 연구 분야이다. 이에 연구팀은 개발한 모델 코드를 무료로 공개하며, 측정한 지표가 여러 국가의 정책 설계 및 평가에 유용하게 사용될 수 있도록 앞으로도 기술을 개선하고 매해 새롭게 업데이트되는 인공위성 영상에 적용하여 공개할 계획이다.
한편 이번 연구 결과는 전산학부 안동현 박사과정, 싱가포르 국립대 양재석 박사과정이 공동 1저자로 국제 학술지 네이처 출판 그룹의 `네이처 커뮤니케이션즈(Nature Communications)'에 지난 10월 26일 자 게재됐다. (논문명: A human-machine collaborative approach measures economic development using satellite imagery, 인간-기계 협업과 위성영상 분석에 기반한 경제 발전 측정).
논문링크: https://www.nature.com/articles/s41467-023-42122-8
2023.11.21 조회수 9138 -
 트랜스포머 대체할 차세대 월드모델 기술 세계 최초 개발
우리 대학 전산학부 안성진 교수 연구팀이 미국 럿거스 대학교와 협력하여 트랜스포머 및 재귀신경망 기반의 월드모델을 대체할 차세대 에이전트 월드모델 기술을 세계 최초로 개발했다.
월드모델은 인간의 뇌가 현실 세계의 경험을 바탕으로 환경 모델을 구축하는 과정과 유사하다. 이러한 월드모델을 활용하는 인공지능은 특정 행동의 결과를 미리 시뮬레이션해보고 다양한 가설을 검증할 수 있어, 범용 인공지능의 핵심 구성 요소로 여겨진다.
특히, 로봇이나 자율주행 차량과 같은 인공지능 에이전트는 학습을 위해 여러 가지 행동을 시도해 보아야하는데, 이는 위험성과 고장 가능성을 높인다는 단점을 갖는다. 이에 반해, 월드모델을 갖춘 인공지능은 실세계 상호작용 없이도 상상모델 속에서 학습을 가능케 해 큰 이점을 제공한다.
그러나 월드모델은 자연어처리 등에서 큰 발전을 가능하게 한 트랜스포머와 S4와 같은 새로운 시퀀스 모델링 아키텍처의 적용에 한계가 있었다. 이로 인해, 대부분의 월드모델이 성능과 효율성 면에서 제약이 있는 고전적인 재귀적 신경망에 의존하고 있었고 안성진 교수팀은 작년 세계최초로 트랜스포머 기반의 월드모델을 개발하였으나 추론 계산속도나 메모리능력에서 여전히 개선할 문제를 갖고 있었다.
이러한 문제를 해결하기 위해, 안성진 교수가 이끄는 KAIST와 럿거스 대학교 공동연구팀은 재귀적 신경망과 트랜스포머 기반 월드모델의 단점을 극복한 새로운 월드모델의 개발에 성공했다. 연구팀은 S4 시퀀스 모델에 기반한 S4 World Model (S4WM)을 개발하여, 재귀적 신경망의 최대 단점인 병렬처리가 가능한 시퀀스 학습이 불가능하다는 문제를 해결하였다. 또한, 재귀적 신경망의 장점인 빠른 추론시간을 유지하도록 하여 느린 추론 시간을 제공하는 트랜스포머 기반 월드모델의 단점을 극복했다.
연구를 주도한 안성진 교수는 "병렬 학습과 빠른 추론이 가능한 에이전트 월드모델을 세계 최초로 개발했다ˮ며, 이는 "모델기반 강화학습 능력을 획기적으로 개선해 지능형 로봇, 자율주행 차량, 그리고 자율형 인공지능 에이전트 기술 전반에 비용절감과 성능 향상이 예상된다ˮ고 밝혔다.
이번 연구는 12월 10일부터 16일까지 미국 뉴올리언스에서 열리는 세계 최고 수준의 인공지능 학회인 제37회 신경정보처리학회(NeurIPS)에서 발표될 예정이다.
관련논문: “Facing off World Model Backbones: RNNs, Transformers, and S4”Fei Deng, Junyeong Park, Sungjin Ahn, NeurIPS 23, https://arxiv.org/abs/2307.02064
2023.11.09 조회수 6922
트랜스포머 대체할 차세대 월드모델 기술 세계 최초 개발
우리 대학 전산학부 안성진 교수 연구팀이 미국 럿거스 대학교와 협력하여 트랜스포머 및 재귀신경망 기반의 월드모델을 대체할 차세대 에이전트 월드모델 기술을 세계 최초로 개발했다.
월드모델은 인간의 뇌가 현실 세계의 경험을 바탕으로 환경 모델을 구축하는 과정과 유사하다. 이러한 월드모델을 활용하는 인공지능은 특정 행동의 결과를 미리 시뮬레이션해보고 다양한 가설을 검증할 수 있어, 범용 인공지능의 핵심 구성 요소로 여겨진다.
특히, 로봇이나 자율주행 차량과 같은 인공지능 에이전트는 학습을 위해 여러 가지 행동을 시도해 보아야하는데, 이는 위험성과 고장 가능성을 높인다는 단점을 갖는다. 이에 반해, 월드모델을 갖춘 인공지능은 실세계 상호작용 없이도 상상모델 속에서 학습을 가능케 해 큰 이점을 제공한다.
그러나 월드모델은 자연어처리 등에서 큰 발전을 가능하게 한 트랜스포머와 S4와 같은 새로운 시퀀스 모델링 아키텍처의 적용에 한계가 있었다. 이로 인해, 대부분의 월드모델이 성능과 효율성 면에서 제약이 있는 고전적인 재귀적 신경망에 의존하고 있었고 안성진 교수팀은 작년 세계최초로 트랜스포머 기반의 월드모델을 개발하였으나 추론 계산속도나 메모리능력에서 여전히 개선할 문제를 갖고 있었다.
이러한 문제를 해결하기 위해, 안성진 교수가 이끄는 KAIST와 럿거스 대학교 공동연구팀은 재귀적 신경망과 트랜스포머 기반 월드모델의 단점을 극복한 새로운 월드모델의 개발에 성공했다. 연구팀은 S4 시퀀스 모델에 기반한 S4 World Model (S4WM)을 개발하여, 재귀적 신경망의 최대 단점인 병렬처리가 가능한 시퀀스 학습이 불가능하다는 문제를 해결하였다. 또한, 재귀적 신경망의 장점인 빠른 추론시간을 유지하도록 하여 느린 추론 시간을 제공하는 트랜스포머 기반 월드모델의 단점을 극복했다.
연구를 주도한 안성진 교수는 "병렬 학습과 빠른 추론이 가능한 에이전트 월드모델을 세계 최초로 개발했다ˮ며, 이는 "모델기반 강화학습 능력을 획기적으로 개선해 지능형 로봇, 자율주행 차량, 그리고 자율형 인공지능 에이전트 기술 전반에 비용절감과 성능 향상이 예상된다ˮ고 밝혔다.
이번 연구는 12월 10일부터 16일까지 미국 뉴올리언스에서 열리는 세계 최고 수준의 인공지능 학회인 제37회 신경정보처리학회(NeurIPS)에서 발표될 예정이다.
관련논문: “Facing off World Model Backbones: RNNs, Transformers, and S4”Fei Deng, Junyeong Park, Sungjin Ahn, NeurIPS 23, https://arxiv.org/abs/2307.02064
2023.11.09 조회수 6922 -
 인공지능 챗봇 이미지 데이터 훈련 비용 최소화하다
최근 다양한 분야에서 인공지능 심층 학습(딥러닝) 기술을 활용한 서비스가 급속히 증가하고 있다. GPT와 같은 거대 언어 모델을 훈련하기 위해서는 수백 대의 GPU와 몇 주 이상의 시간이 필요하다고 알려져 있다. 따라서, 심층신경망 훈련 비용을 최소화하는 방법 개발이 요구되고 있다.
우리 대학 전산학부 이재길 교수 연구팀이 심층신경망 훈련 비용을 최소화할 수 있도록 훈련 데이터의 양을 줄이는 새로운 데이터 선택 기술을 개발했다고 2일 밝혔다.
일반적으로 대용량의 심층 학습용 훈련 데이터는 레이블 오류(예를 들어, 강아지 사진이 `고양이'라고 잘못 표기되어 있음)를 포함한다. 최신 인공지능 방법론인 재(再)레이블링(Re-labeling) 학습법은 훈련 도중 레이블 오류를 스스로 수정하면서 높은 심층신경망 성능을 달성하는데, 레이블 오류를 수정하기 위한 추가적인 과정들로 인해 훈련에 필요한 시간이 더욱 증가한다는 단점이 있다. 한편 막대한 훈련 시간을 줄이려는 방법으로 중복되거나 성능 향상에 도움이 되지 않는 데이터를 제거해 훈련 데이터의 크기를 줄이는 핵심 집합 선별(coreset selection) 방식이 큰 주목을 받고 있다. 그러나 기존 핵심 집합 선별 방식은 훈련 데이터에 레이블 오류가 없다고 가정한 표준 학습법을 위해 개발됐고, 재레이블링 학습법을 위한 핵심 집합 선별 방식에 관한 연구는 부족한 실정이다.
이재길 교수팀이 개발한 기술은 레이블 오류를 스스로 수정하는 최신 재레이블링 학습법을 위해 핵심 집합 선별을 수행하여 심층 학습 훈련 비용을 최소화할 수 있도록 해준다. 따라서, 레이블 오류가 포함된 현실적인 훈련 데이터를 지원하므로 실용성이 매우 높다.
또한 이 교수팀은 특정 데이터의 레이블 오류 수정 정확도가 해당 데이터의 이웃 데이터의 신뢰도와 높은 상관관계가 있음을 발견했다. 즉, 이웃 데이터의 신뢰도가 높으면 레이블 오류 수정 정확도가 커지는 경향이 있다. 이웃 데이터의 신뢰도는 심층신경망의 충분한 훈련 전에도 측정할 수 있으므로, 각 데이터의 레이블 수정 가능 여부를 예측할 수 있게 된다. 연구팀은 이러한 발견을 기반으로 전체 훈련 데이터의 총합 이웃 신뢰도를 최대화하는 데이터 부분 집합을 선별해 레이블 수정 정확도와 일반화 성능을 최대화하는 `재레이블링을 위한 핵심 집합 선별'을 제안했다. 총합 이웃 신뢰도를 최대화하는 부분 집합을 찾는 조합 최적화 문제의 효율적인 해법을 위해 총합 이웃 신뢰도를 가장 증가시키는 데이터를 차례차례 선택하는 탐욕 알고리즘(greedy algorithm)을 도입했다.
연구팀은 이미지 분류 문제에 대해 다양한 실세계의 훈련 데이터를 사용해 방법론을 검증했다. 그 결과, 레이블 오류가 없다는 가정에 따른 표준 학습법에서는 최대 9%, 재레이블링 학습법에서는 최대 21% 최종 예측 정확도가 기존 방법론에 비해 향상되었고, 모든 범위의 데이터 선별 비율에서 일관되게 최고 성능을 달성했다. 또한, 총합 이웃 신뢰도를 최대화한 효율적 탐욕 알고리즘을 통해 기존 방법론에 비해 획기적으로 시간을 줄이고 수백만 장의 이미지를 포함하는 초대용량 훈련 데이터에도 쉽게 확장될 수 있음을 확인했다.
제1 저자인 박동민 박사과정 학생은 "이번 기술은 오류를 포함한 데이터에 대한 최신 인공지능 방법론의 훈련 가속화를 위한 획기적인 방법ˮ 이라면서 "다양한 데이터 상황에서의 강건성이 검증됐기 때문에, 실생활의 기계 학습 문제에 폭넓게 적용될 수 있어 전반적인 심층 학습의 훈련 데이터 준비 비용 절감에 기여할 것ˮ 이라고 밝혔다.
연구팀을 지도한 이재길 교수도 "이 기술이 파이토치(PyTorch) 혹은 텐서플로우(TensorFlow)와 같은 기존의 심층 학습 라이브러리에 추가되면 기계 학습 및 심층 학습 학계에 큰 파급효과를 낼 수 있을 것이다ˮ고 말했다.
우리 대학 데이터사이언스대학원에 재학 중인 박동민 박사과정 학생이 제1 저자, 최설아 석사과정, 김도영 박사과정 학생이 제2, 제3 저자로 각각 참여한 이번 연구는 최고권위 국제학술대회 `신경정보처리시스템학회(NeurIPS) 2023'에서 올 12월 발표될 예정이다. (논문명 : Robust Data Pruning under Label Noise via Maximizing Re-labeling Accuracy)
한편, 이 기술은 과학기술정보통신부 재원으로 정보통신기획평가원의 지원을 받아 SW컴퓨팅산업원천기술개발사업 SW스타랩 과제로 개발한 연구성과 결과물(2020-0-00862, DB4DL: 딥러닝 지원 고사용성 및 고성능 분산 인메모리 DBMS 개발)이다.
2023.11.02 조회수 6531
인공지능 챗봇 이미지 데이터 훈련 비용 최소화하다
최근 다양한 분야에서 인공지능 심층 학습(딥러닝) 기술을 활용한 서비스가 급속히 증가하고 있다. GPT와 같은 거대 언어 모델을 훈련하기 위해서는 수백 대의 GPU와 몇 주 이상의 시간이 필요하다고 알려져 있다. 따라서, 심층신경망 훈련 비용을 최소화하는 방법 개발이 요구되고 있다.
우리 대학 전산학부 이재길 교수 연구팀이 심층신경망 훈련 비용을 최소화할 수 있도록 훈련 데이터의 양을 줄이는 새로운 데이터 선택 기술을 개발했다고 2일 밝혔다.
일반적으로 대용량의 심층 학습용 훈련 데이터는 레이블 오류(예를 들어, 강아지 사진이 `고양이'라고 잘못 표기되어 있음)를 포함한다. 최신 인공지능 방법론인 재(再)레이블링(Re-labeling) 학습법은 훈련 도중 레이블 오류를 스스로 수정하면서 높은 심층신경망 성능을 달성하는데, 레이블 오류를 수정하기 위한 추가적인 과정들로 인해 훈련에 필요한 시간이 더욱 증가한다는 단점이 있다. 한편 막대한 훈련 시간을 줄이려는 방법으로 중복되거나 성능 향상에 도움이 되지 않는 데이터를 제거해 훈련 데이터의 크기를 줄이는 핵심 집합 선별(coreset selection) 방식이 큰 주목을 받고 있다. 그러나 기존 핵심 집합 선별 방식은 훈련 데이터에 레이블 오류가 없다고 가정한 표준 학습법을 위해 개발됐고, 재레이블링 학습법을 위한 핵심 집합 선별 방식에 관한 연구는 부족한 실정이다.
이재길 교수팀이 개발한 기술은 레이블 오류를 스스로 수정하는 최신 재레이블링 학습법을 위해 핵심 집합 선별을 수행하여 심층 학습 훈련 비용을 최소화할 수 있도록 해준다. 따라서, 레이블 오류가 포함된 현실적인 훈련 데이터를 지원하므로 실용성이 매우 높다.
또한 이 교수팀은 특정 데이터의 레이블 오류 수정 정확도가 해당 데이터의 이웃 데이터의 신뢰도와 높은 상관관계가 있음을 발견했다. 즉, 이웃 데이터의 신뢰도가 높으면 레이블 오류 수정 정확도가 커지는 경향이 있다. 이웃 데이터의 신뢰도는 심층신경망의 충분한 훈련 전에도 측정할 수 있으므로, 각 데이터의 레이블 수정 가능 여부를 예측할 수 있게 된다. 연구팀은 이러한 발견을 기반으로 전체 훈련 데이터의 총합 이웃 신뢰도를 최대화하는 데이터 부분 집합을 선별해 레이블 수정 정확도와 일반화 성능을 최대화하는 `재레이블링을 위한 핵심 집합 선별'을 제안했다. 총합 이웃 신뢰도를 최대화하는 부분 집합을 찾는 조합 최적화 문제의 효율적인 해법을 위해 총합 이웃 신뢰도를 가장 증가시키는 데이터를 차례차례 선택하는 탐욕 알고리즘(greedy algorithm)을 도입했다.
연구팀은 이미지 분류 문제에 대해 다양한 실세계의 훈련 데이터를 사용해 방법론을 검증했다. 그 결과, 레이블 오류가 없다는 가정에 따른 표준 학습법에서는 최대 9%, 재레이블링 학습법에서는 최대 21% 최종 예측 정확도가 기존 방법론에 비해 향상되었고, 모든 범위의 데이터 선별 비율에서 일관되게 최고 성능을 달성했다. 또한, 총합 이웃 신뢰도를 최대화한 효율적 탐욕 알고리즘을 통해 기존 방법론에 비해 획기적으로 시간을 줄이고 수백만 장의 이미지를 포함하는 초대용량 훈련 데이터에도 쉽게 확장될 수 있음을 확인했다.
제1 저자인 박동민 박사과정 학생은 "이번 기술은 오류를 포함한 데이터에 대한 최신 인공지능 방법론의 훈련 가속화를 위한 획기적인 방법ˮ 이라면서 "다양한 데이터 상황에서의 강건성이 검증됐기 때문에, 실생활의 기계 학습 문제에 폭넓게 적용될 수 있어 전반적인 심층 학습의 훈련 데이터 준비 비용 절감에 기여할 것ˮ 이라고 밝혔다.
연구팀을 지도한 이재길 교수도 "이 기술이 파이토치(PyTorch) 혹은 텐서플로우(TensorFlow)와 같은 기존의 심층 학습 라이브러리에 추가되면 기계 학습 및 심층 학습 학계에 큰 파급효과를 낼 수 있을 것이다ˮ고 말했다.
우리 대학 데이터사이언스대학원에 재학 중인 박동민 박사과정 학생이 제1 저자, 최설아 석사과정, 김도영 박사과정 학생이 제2, 제3 저자로 각각 참여한 이번 연구는 최고권위 국제학술대회 `신경정보처리시스템학회(NeurIPS) 2023'에서 올 12월 발표될 예정이다. (논문명 : Robust Data Pruning under Label Noise via Maximizing Re-labeling Accuracy)
한편, 이 기술은 과학기술정보통신부 재원으로 정보통신기획평가원의 지원을 받아 SW컴퓨팅산업원천기술개발사업 SW스타랩 과제로 개발한 연구성과 결과물(2020-0-00862, DB4DL: 딥러닝 지원 고사용성 및 고성능 분산 인메모리 DBMS 개발)이다.
2023.11.02 조회수 6531 -
 전산학부 박종철 교수 연구팀, ACL2023 Outstanding Paper Award 수상
우리 대학 전산학부 박종철 교수 연구팀이 2023년 7월 9일~13일 토론토에서 열린 ACL 2023 에서 Outstanding Paper Award를 수상했다.
연구팀의 획기적인 논문인 “Question-Answering in a Low-resourced Language: Benchmark Dataset and Models for Tigrinya“는 저자원 언어이며 동아프리카의 에리트레아와 에티오피아에서 사용되는 티그리냐를 다룬다.
연구팀은 티그리냐 질문-답변 데이터셋을 세계 최초로 구축하고 티그리냐로 작성된 문서를 읽고 답할 수 있는 언어모델을 만들었다.
이 상은 학회에 제출한 연구 중 상위 1.5~2.5%에게만 주어지는 의미 있는 상이다.
이 연구팀은 티그리냐와 다른 동아프리카 언어들에 대한 사전학습 언어 모델과 언어 식별 방법에 대한 연구를 LREC2022와 EMNLP2021 등 저명한 NLP 학회에 소개한 경험이 있다.
본 연구의 첫 번째 저자인 Fitsum은 전산학부 NLP*CL 연구실의 박사과정 학생이다. 그의 연구는 현재 티그리냐 언어에 초점을 맞추고 있지만, 특정 언어를 넘어 연구의 지평을 확장하기 위해 노력하고 있다.
이 연구팀이 개발한 방법론, 데이터수집 방법, 어노테이션 툴, 그리고 모델은 언어 자원이 부족한 언어들에 대한 유용한 참고자료로 활용될 것으로 기대된다. 특히 이들의 연구는 최근 심각해 지고 있는 디지털 격차를 해소하기 위해 언어적으로 다양하고, 역사적으로 혜택을 받지 못했던 커뮤니티에 대등한 연구가 가능한 디지털 표현 방법을 제공하였다는 의미가 있다.
본 연구는 NLP*CL 연구실에서 ACL 2023을 통해 발표한 다섯 편의 Long Paper (세 편은 메인 학술대회, 두 편은 Findings) 중 하나이다.
2023.07.18 조회수 4085
전산학부 박종철 교수 연구팀, ACL2023 Outstanding Paper Award 수상
우리 대학 전산학부 박종철 교수 연구팀이 2023년 7월 9일~13일 토론토에서 열린 ACL 2023 에서 Outstanding Paper Award를 수상했다.
연구팀의 획기적인 논문인 “Question-Answering in a Low-resourced Language: Benchmark Dataset and Models for Tigrinya“는 저자원 언어이며 동아프리카의 에리트레아와 에티오피아에서 사용되는 티그리냐를 다룬다.
연구팀은 티그리냐 질문-답변 데이터셋을 세계 최초로 구축하고 티그리냐로 작성된 문서를 읽고 답할 수 있는 언어모델을 만들었다.
이 상은 학회에 제출한 연구 중 상위 1.5~2.5%에게만 주어지는 의미 있는 상이다.
이 연구팀은 티그리냐와 다른 동아프리카 언어들에 대한 사전학습 언어 모델과 언어 식별 방법에 대한 연구를 LREC2022와 EMNLP2021 등 저명한 NLP 학회에 소개한 경험이 있다.
본 연구의 첫 번째 저자인 Fitsum은 전산학부 NLP*CL 연구실의 박사과정 학생이다. 그의 연구는 현재 티그리냐 언어에 초점을 맞추고 있지만, 특정 언어를 넘어 연구의 지평을 확장하기 위해 노력하고 있다.
이 연구팀이 개발한 방법론, 데이터수집 방법, 어노테이션 툴, 그리고 모델은 언어 자원이 부족한 언어들에 대한 유용한 참고자료로 활용될 것으로 기대된다. 특히 이들의 연구는 최근 심각해 지고 있는 디지털 격차를 해소하기 위해 언어적으로 다양하고, 역사적으로 혜택을 받지 못했던 커뮤니티에 대등한 연구가 가능한 디지털 표현 방법을 제공하였다는 의미가 있다.
본 연구는 NLP*CL 연구실에서 ACL 2023을 통해 발표한 다섯 편의 Long Paper (세 편은 메인 학술대회, 두 편은 Findings) 중 하나이다.
2023.07.18 조회수 4085