%EB%B9%85%EB%8D%B0%EC%9D%B4%ED%84%B0
-
 이재길 교수 연구팀 연구성과 Microsoft Research 블로그 게재
<이재길 교수, 송환준 박사과정>
우리대학 이재길 교수(산업및시스템공학과 지식서비스공학대학원)와 송환준 박사과정 학생의 최신 빅데이터 연구결과가 최근 Microsoft Research 블로그에 실렸다. Microsoft Research는 매 분기 자사의 지원을 받은 연구과제 중에서 대표적인 성과를 선정해 자사 블로그에 게시하고 있는데 이번에는 이재길 교수 연구팀의 연구결과가 그 중 하나로 선정된 것이다.
이교수 연구팀은 이번 연구를 통해 전통적인 데이터 군집화 알고리즘인 k-메도이드의 분산 병렬처리 알고리즘을 개발했다. 그동안 빅데이터의 처리 속도를 높이기 위해 결과 정확도를 다소 희생하는 것이 일반적인 관례였으나 이 교수팀은 이번 연구를 통해 정확도를 거의 잃지 않고 현존하는 타 알고리즘보다 높은 성능을 달성했다고 밝혔다.
이번 연구결과는 지난 8월 열린 데이터 마이닝 분야 최고 학술대회인 ACM KDD 2017에서 발표된바 있다. 이 교수는 "추가적인 군집화 알고리즘의 연구도 마무리해 아파치 스파크 오픈소스 플랫폼에 연 성과를 탑재시킬 것"이라고 향후 계획을 밝혔다.
블로그 게시물 : https://www.microsoft.com/en-us/research/lab/microsoft-research-asia/articles/using-microsoft-azure-research-tool-scalable-data-mining-2/
2017.10.16 조회수 13808
이재길 교수 연구팀 연구성과 Microsoft Research 블로그 게재
<이재길 교수, 송환준 박사과정>
우리대학 이재길 교수(산업및시스템공학과 지식서비스공학대학원)와 송환준 박사과정 학생의 최신 빅데이터 연구결과가 최근 Microsoft Research 블로그에 실렸다. Microsoft Research는 매 분기 자사의 지원을 받은 연구과제 중에서 대표적인 성과를 선정해 자사 블로그에 게시하고 있는데 이번에는 이재길 교수 연구팀의 연구결과가 그 중 하나로 선정된 것이다.
이교수 연구팀은 이번 연구를 통해 전통적인 데이터 군집화 알고리즘인 k-메도이드의 분산 병렬처리 알고리즘을 개발했다. 그동안 빅데이터의 처리 속도를 높이기 위해 결과 정확도를 다소 희생하는 것이 일반적인 관례였으나 이 교수팀은 이번 연구를 통해 정확도를 거의 잃지 않고 현존하는 타 알고리즘보다 높은 성능을 달성했다고 밝혔다.
이번 연구결과는 지난 8월 열린 데이터 마이닝 분야 최고 학술대회인 ACM KDD 2017에서 발표된바 있다. 이 교수는 "추가적인 군집화 알고리즘의 연구도 마무리해 아파치 스파크 오픈소스 플랫폼에 연 성과를 탑재시킬 것"이라고 향후 계획을 밝혔다.
블로그 게시물 : https://www.microsoft.com/en-us/research/lab/microsoft-research-asia/articles/using-microsoft-azure-research-tool-scalable-data-mining-2/
2017.10.16 조회수 13808 -
 빅데이터를 통해 고전음악 창작의 원리 밝혀
박 주 용 교수
우리 대학 문화기술대학원(CT) 박주용 교수 연구팀이 빅데이터를 이용해 서양 고전음악의 창작, 협력, 확산의 원리를 밝히는 데 성공했다.
문화기술대학원 박도흠 학생(박사과정)이 1 저자로 참여하고 미국 텍사스대 연구팀과 공동으로 진행한 이번 연구는 해외 저널인 EPJ 데이터 사이언스 4월 29일자 하이라이트 논문에 선정됐다.
연구팀은 ArkivMusic과 올 뮤직 가이드(All Music Guide)라는 세계 최대 음반 정보 사이트를 첨단 데이터와 모델링 방법을 사용해 분석했다.
연구팀은 고전음악 작곡가들의 시대와 스타일이 어떤 패턴을 이루는지 탐구해, 수 백 년의 차이가 있는 음악가들 사이에서도 긴밀한 네트워크가 존재함을 발견했다. 특히 소비자들의 음악적 취향이 고전음악 성장에 어떤 영향을 끼쳤는지 규명했다.
연구진은 미래의 고전음악 시장은 유명 작곡가들에게 집중되는 동시에 끊임없이 유입되는 새로운 음악가들로 인해 다양성이 유지되는 양면성을 갖게 될 것이라고 예측했다. 또한 이런 방식의 연구가 음악 뿐 아니라 미술과 문학 연구까지 확장될 것으로 예상했다.
박 교수는 “새로운 방식으로 문화의 원리를 밝히는 최신 연구의 일환이다”며 “문화에 과학적 방법론을 입힌 융합연구능력의 좋은 예시가 될 것”이라고 말했다.
붙임 : 연구 개요, 그림 설명
□ 연구 개요
* 빅데이터 출처: 아카이브뮤직(ArkivMusic)과 올 뮤직 가이드(All Music Guide)라는 빅데이터 소스를 사용했다. 아카이브뮤직은 서양 클래식 음반(CD)에 관한 세계 최대 정보를 제공하고 올 뮤직 가이드는 음악가들의 인적 정보를 제공하는 사이트이다. 여기서 약 64,000장의 클래식 음반과 그 음반에 음악이 수록된 14,000명의 작곡가 데이터를 사용했고, 이는 현재 ‘문화’의 빅데이터 연구로서는 세계 최대급 규모이다.
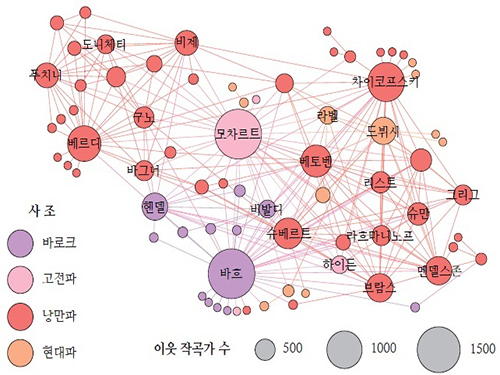
* 연구방법론: 서양 클래식 음악과 같은 문화의 중요한 특징 중의 하나는 그 창작자(작곡가 등)가 개인으로 동떨어져 존재하는 것이 아니라 다른 창작자들과 영향을 주고받으며 새로운 스타일이 등장하고 발전 한다는 것이다. 그러므로 창작자들이 맺고 있는 소통 및 연관성의 관계를 이해하는 것은 문화 창조의 원리, 역사와 미래를 이해하는 데 있어 매우 중요하다고 할 수 있다. 이를 위해 “CD--작곡가들의 빅데이터”로부터 작곡자들이 이루고 네트워크를 연구하였다. (그림 1) 즉, CD에 함께 등재된 작곡가들이 연결돼있는 것이다. 그림 1은 이 네트워크의 핵심적인 일부를 표현한 것으로 하단의 요한 세바스찬 바흐는 모차르트와, 차이코프스키는 드뷔시와 함께 CD에 등장한 적이 있음을 알게 해준다. 이러한 네트워크로부터 유의미한 패턴을 찾아 네트워크의 발전 원리와 미래를 연구하는 것을 네트워크 과학이라고 하는데, 현재 SNS와 사회과학, 인터넷 등의 연구에 사용되고 있다. ‘복잡계 네트워크 과학’ 이라고도 한다.
* 연구결과:
이 네트워크는 중세/르네상스(1500년대 이전) 작곡자로부터 2000년대 현존하는 작곡자까지 500년이 넘는 서양 클래식 음악의 역사를 담고 있으면서도, 작곡자와 작곡자간의 평균 거리는 3.5명에 불과한 좁은 세상을 이루고 있다. 직접 연결되지 않는 작곡가들끼리도 평균적으로 3-4명만 건너뛰면 연결이 돼 서로 가깝게 연관되어 있다는 것을 알 수 있다.
이 네트워크 안에서 각 작곡가들이 차지하는 비중은 작곡가에 따라 매우 상이하다는 것도 중요한 특징이다. 예를 들어, 요한 세바스찬 바흐는 (J. S. Bach) 이 1,551명의 각기 다른 작곡가와 연결돼있고, 모차르트는 (W. A. Mozart) 1086명의 다른 작곡가와 연결돼있는데 이는 작곡가 전체 평균 숫자인 15명의 수십, 수 백 배에 달한다. 바흐와 베토벤 같은 유명 작곡가들이 전체 작곡가 네트워크에서 얼마나 큰 비중을 차지하는지 수치적으로 명확히 보여줌으로써 영향력을 구체적으로 이해할 수 있는 것이다. (그림 1에서 작곡자들의 크기로 표현)
이 네트워크에서 연결되어있다는 것은 음반 레이블에서 CD를 발매할 때 함께 묶어서 냈다는 뜻이므로 스타일, 주제, 기법 등에 기반한 음악적 유사성을 뜻하는 것으로 볼 수 있다. 컴퓨터 알고리즘을 이용해 순전히 네트워크 구조로부터 서로 긴밀하게 연결된 작곡가들의 집단을 유추한 뒤 기존 클래식 음악사 연구에서 사용되는 사조 구분과 교차 검증을 햇다. (그림 2). 여기에서는 CD 빅데이터에 기반한 네트워크가 서양 클래식 음악의 발전사를 잘 보여주고 있다는 것을 알 수 있는데, 낭만파(1800년대)와 현대파(1900년대)를 잇는 프랑스의 작곡가 드뷔시(Debussy)의 중간적인 위치, 현대파의 유럽 및 남미파(드뷔시, 라벨, 피아졸라)-미국파(레너드 번스틴, 애론 코플랜드) 분리 등을 관찰할 수가 있다.
CD의 발매일자에 따른 네트워크의 과거 발전 모습을 분석함으로써 미래의 추세 또한 예측 가능하다. 미래의 네트워크는 유명 작곡가들에게 상대적으로 더욱 더 집중되는 모습을 가질 것으로 예상된다. 그러나 기술의 발전에 따른 CD 발매의 용이성에 힘입어 작곡가의 숫자 또한 꾸준히 늘어나는 것으로 관찰돼, 소수에 집중되는 측면과 다양성의 양면을 지닐 것으로 예상된다.
* 의의: 창작자가 서로 깊게 연관되어있는 문화의 발전 원리는 그 분야의 구성원 전체를 동시에 보는 것이 필요하므로, 이와 같은 빅데이터의 연구로 풀어내기에 매우 적합하다. 또한 다른 문화 분야 (회화, 문학 등) 로의 확장도 가능해 문화 분야 간 연관성 혹은 문화 전체의 발전의 원리를 연구할 수도 있을 것이다.
□ 그림 설명
그림 1. CD-작곡가들의 빅데이터
그림 2. 빅데이터와 사조구분 방법으로 교차 검증한 모식도
2015.05.06 조회수 16522
빅데이터를 통해 고전음악 창작의 원리 밝혀
박 주 용 교수
우리 대학 문화기술대학원(CT) 박주용 교수 연구팀이 빅데이터를 이용해 서양 고전음악의 창작, 협력, 확산의 원리를 밝히는 데 성공했다.
문화기술대학원 박도흠 학생(박사과정)이 1 저자로 참여하고 미국 텍사스대 연구팀과 공동으로 진행한 이번 연구는 해외 저널인 EPJ 데이터 사이언스 4월 29일자 하이라이트 논문에 선정됐다.
연구팀은 ArkivMusic과 올 뮤직 가이드(All Music Guide)라는 세계 최대 음반 정보 사이트를 첨단 데이터와 모델링 방법을 사용해 분석했다.
연구팀은 고전음악 작곡가들의 시대와 스타일이 어떤 패턴을 이루는지 탐구해, 수 백 년의 차이가 있는 음악가들 사이에서도 긴밀한 네트워크가 존재함을 발견했다. 특히 소비자들의 음악적 취향이 고전음악 성장에 어떤 영향을 끼쳤는지 규명했다.
연구진은 미래의 고전음악 시장은 유명 작곡가들에게 집중되는 동시에 끊임없이 유입되는 새로운 음악가들로 인해 다양성이 유지되는 양면성을 갖게 될 것이라고 예측했다. 또한 이런 방식의 연구가 음악 뿐 아니라 미술과 문학 연구까지 확장될 것으로 예상했다.
박 교수는 “새로운 방식으로 문화의 원리를 밝히는 최신 연구의 일환이다”며 “문화에 과학적 방법론을 입힌 융합연구능력의 좋은 예시가 될 것”이라고 말했다.
붙임 : 연구 개요, 그림 설명
□ 연구 개요
* 빅데이터 출처: 아카이브뮤직(ArkivMusic)과 올 뮤직 가이드(All Music Guide)라는 빅데이터 소스를 사용했다. 아카이브뮤직은 서양 클래식 음반(CD)에 관한 세계 최대 정보를 제공하고 올 뮤직 가이드는 음악가들의 인적 정보를 제공하는 사이트이다. 여기서 약 64,000장의 클래식 음반과 그 음반에 음악이 수록된 14,000명의 작곡가 데이터를 사용했고, 이는 현재 ‘문화’의 빅데이터 연구로서는 세계 최대급 규모이다.
* 연구방법론: 서양 클래식 음악과 같은 문화의 중요한 특징 중의 하나는 그 창작자(작곡가 등)가 개인으로 동떨어져 존재하는 것이 아니라 다른 창작자들과 영향을 주고받으며 새로운 스타일이 등장하고 발전 한다는 것이다. 그러므로 창작자들이 맺고 있는 소통 및 연관성의 관계를 이해하는 것은 문화 창조의 원리, 역사와 미래를 이해하는 데 있어 매우 중요하다고 할 수 있다. 이를 위해 “CD--작곡가들의 빅데이터”로부터 작곡자들이 이루고 네트워크를 연구하였다. (그림 1) 즉, CD에 함께 등재된 작곡가들이 연결돼있는 것이다. 그림 1은 이 네트워크의 핵심적인 일부를 표현한 것으로 하단의 요한 세바스찬 바흐는 모차르트와, 차이코프스키는 드뷔시와 함께 CD에 등장한 적이 있음을 알게 해준다. 이러한 네트워크로부터 유의미한 패턴을 찾아 네트워크의 발전 원리와 미래를 연구하는 것을 네트워크 과학이라고 하는데, 현재 SNS와 사회과학, 인터넷 등의 연구에 사용되고 있다. ‘복잡계 네트워크 과학’ 이라고도 한다.
* 연구결과:
이 네트워크는 중세/르네상스(1500년대 이전) 작곡자로부터 2000년대 현존하는 작곡자까지 500년이 넘는 서양 클래식 음악의 역사를 담고 있으면서도, 작곡자와 작곡자간의 평균 거리는 3.5명에 불과한 좁은 세상을 이루고 있다. 직접 연결되지 않는 작곡가들끼리도 평균적으로 3-4명만 건너뛰면 연결이 돼 서로 가깝게 연관되어 있다는 것을 알 수 있다.
이 네트워크 안에서 각 작곡가들이 차지하는 비중은 작곡가에 따라 매우 상이하다는 것도 중요한 특징이다. 예를 들어, 요한 세바스찬 바흐는 (J. S. Bach) 이 1,551명의 각기 다른 작곡가와 연결돼있고, 모차르트는 (W. A. Mozart) 1086명의 다른 작곡가와 연결돼있는데 이는 작곡가 전체 평균 숫자인 15명의 수십, 수 백 배에 달한다. 바흐와 베토벤 같은 유명 작곡가들이 전체 작곡가 네트워크에서 얼마나 큰 비중을 차지하는지 수치적으로 명확히 보여줌으로써 영향력을 구체적으로 이해할 수 있는 것이다. (그림 1에서 작곡자들의 크기로 표현)
이 네트워크에서 연결되어있다는 것은 음반 레이블에서 CD를 발매할 때 함께 묶어서 냈다는 뜻이므로 스타일, 주제, 기법 등에 기반한 음악적 유사성을 뜻하는 것으로 볼 수 있다. 컴퓨터 알고리즘을 이용해 순전히 네트워크 구조로부터 서로 긴밀하게 연결된 작곡가들의 집단을 유추한 뒤 기존 클래식 음악사 연구에서 사용되는 사조 구분과 교차 검증을 햇다. (그림 2). 여기에서는 CD 빅데이터에 기반한 네트워크가 서양 클래식 음악의 발전사를 잘 보여주고 있다는 것을 알 수 있는데, 낭만파(1800년대)와 현대파(1900년대)를 잇는 프랑스의 작곡가 드뷔시(Debussy)의 중간적인 위치, 현대파의 유럽 및 남미파(드뷔시, 라벨, 피아졸라)-미국파(레너드 번스틴, 애론 코플랜드) 분리 등을 관찰할 수가 있다.
CD의 발매일자에 따른 네트워크의 과거 발전 모습을 분석함으로써 미래의 추세 또한 예측 가능하다. 미래의 네트워크는 유명 작곡가들에게 상대적으로 더욱 더 집중되는 모습을 가질 것으로 예상된다. 그러나 기술의 발전에 따른 CD 발매의 용이성에 힘입어 작곡가의 숫자 또한 꾸준히 늘어나는 것으로 관찰돼, 소수에 집중되는 측면과 다양성의 양면을 지닐 것으로 예상된다.
* 의의: 창작자가 서로 깊게 연관되어있는 문화의 발전 원리는 그 분야의 구성원 전체를 동시에 보는 것이 필요하므로, 이와 같은 빅데이터의 연구로 풀어내기에 매우 적합하다. 또한 다른 문화 분야 (회화, 문학 등) 로의 확장도 가능해 문화 분야 간 연관성 혹은 문화 전체의 발전의 원리를 연구할 수도 있을 것이다.
□ 그림 설명
그림 1. CD-작곡가들의 빅데이터
그림 2. 빅데이터와 사조구분 방법으로 교차 검증한 모식도
2015.05.06 조회수 16522 -
 다빈치가 르네상스 이후에 태어났다면 모나리자를 어떻게 그렸을까
우리 학교 물리학과 정하웅 교수와 한양대학교 응용물리학과 손승우 교수는 중세부터 사실주의까지 약 1000년에 걸친 서양화 1만 여점의 빅데이터를 복잡계 이론으로 분석해 서양 미술의 변천사를 밝혀냈다. 또 이를 바탕으로 르네상스 시대의 대표 작품인 모나리자를 시대별로 재구성했다.
연구결과는 세계적인 과학저널 네이처(Nature)가 발행하는 ‘사이언티픽 리포트(Scientific Reports)’ 11일자 온라인판에 실렸으며 리서치 하이라이트로 선정되어 네이처 홈페이지 메인 화면에 소개되기도 했다.
최근 빅데이터가 관심을 받으면서 과학자들은 예술·인문학 자료를 전산화해 분석하려는 시도가 많이 있다. 이 같은 자료는 방대하고 복잡해서 다루기가 쉽지 않다. 연구자들은 빅데이터에서 질서를 찾기 위해 복잡계(Complex Systems) 과학 방법론을 이용하며 이를 ‘데이터 과학’이라고 한다.
그동안 회화에 사용된 물감의 구성 성분, 연대측정, 회화의 진위여부를 정량적으로 판별하는 방법 등에 관한 연구결과는 꾸준히 있었다. 하지만 서양 미술사 전반을 아우르는 대규모 분석에는 데이터가 충분하지 않았다.
연구팀은 헝가리 부다페스트 물리학 컴퓨터 네트워킹 연구센터(Computer Networking Centre of the Wigner Research Centre for Physics)에서 운영하는 온라인 갤러리에서 중세부터 19세기까지 디지털 형태의 서양회화 1만여 점을 모은 데이터를 기반으로 서양 미술을 객관적으로 분석할 수 있었다.
연구팀은 물리학에서 사용하는 상관 함수를 온라인 갤러리에서 취합된 서양 미술의 빅데이터에 적용해 분석한 결과 시간이 흐를수록 명암대비 효과가 점점 높아지는 경향이 있다는 사실을 밝혀냈다.
연구팀은 여기서 사용한 상관 함수를 잭슨 폴록의 드립 페인팅에 적용한 결과, 공간적인 명암대비 효과가 거의 없어 무작위로 만든 그림에 상당히 가깝다는 것을 분석해내기도 했다.
이와 함께 이 기간 동안 서양미술은 그림 속 물체의 윤곽선이 모호해지다 낭만주의 시대 무렵 다시 뚜렷해지는 변화가 있었다.
아울러 중세 시대에는 색상을 다양하게 사용하지 않았고 정치 및 종교적인 이유로 특정 염료만을 선호했다. 같은 이유로 당시에는 색을 직접 혼합하지 않고 오직 덧칠로만 다양한 색을 표현했다. 즉, 연구팀은 염료와 채색 방식으로 인한 중세 시대 색상 표현의 한계와 그 이후 변화를 분석해냈다.
정하웅 교수는 “물질세계의 복잡성에 대한 연구는 자연과학에서 오래된 주요 관심사였지만, 예술 및 인문사회분야와 관련한 체계적인 복잡성 연구는 인터넷 대중화 이후의 일”이라며 “이번 연구는 물질세계의 복잡성을 다루던 방법으로 인류의 귀중한 문화유산인 회화에서 숨은 복잡성을 찾아 구체적인 숫자로 제시했다는데 의의가 있다”고 말했다.
손승우 교수는 “학문 사이의 통섭은 이제 융·복합이라는 키워드로 우리 사회에 자리매김하고 있다”며 “학문간 더욱 활발한 대화를 통해 미술 분야를 넘어 예술 및 인문사회 분야에 숨겨진 복잡성을 더욱 폭넓게 이해하는 것이 필요하다”고 설명했다.
미래창조과학부와 한국연구재단이 추진하는 중견연구자지원사업의 지원으로 수행한 이번 연구는 KAIST와 한양대 교수진의 지도아래 KAIST 물리학과 김영호(28) 박사과정 학생이 주도했다.
동영상 링크 http://youtu.be/SFo0h1EU2aw
[자료 그림] 중세 회화와 드립 페인팅 비교: a은 중세 회화로 구성한 밝기 표면, b은 잭슨 폴록의 드립 페인팅 작품으로 구성한 밝기 표면이다. 각 픽셀의 밝기를 픽셀 위치의 높이로 두어 표면을 구성하고 각 밝기 표면에서 거리에 따른 평균 밝기차이 상관함수를 구했다. c와 d에서 빨간색 점은 그림에서 거리에 따른 평균 밝기차이 상관함수, 파란색 점은 그림을 무작위로 섞어서 만든 이미지에서 거리에 따른 평균 밝기차이 상관함수이다. 중세 회화와 다르게 잭슨 폴록의 드립 페인팅은 무작위로 섞어서 만든 이미지와 거리에 따른 평균 밝기차이 상관함수가 거의 차이가 없다. © 2014 The Polock-Krasner Foundation/ARS, NY - SACK, Seoul
1. 르네상스 시대의 대표 작품인 모나리자를 시대별 스타일에 맞게 재구성
2. 각 그림으로 표면을 구성하고 명암 대비 기법의 강도를 측정하는 짧은 영상. 선별한 그림을 중심으로 명암 대비 기법의 강도가 시대에 따라 증가하는 경향을 영상에서 확인할 수 있다.
3. 회화에서 밝기 표면을 구성하는 방법
4. 네이처 홈페이지(12월 11일)
2014.12.15 조회수 16940
다빈치가 르네상스 이후에 태어났다면 모나리자를 어떻게 그렸을까
우리 학교 물리학과 정하웅 교수와 한양대학교 응용물리학과 손승우 교수는 중세부터 사실주의까지 약 1000년에 걸친 서양화 1만 여점의 빅데이터를 복잡계 이론으로 분석해 서양 미술의 변천사를 밝혀냈다. 또 이를 바탕으로 르네상스 시대의 대표 작품인 모나리자를 시대별로 재구성했다.
연구결과는 세계적인 과학저널 네이처(Nature)가 발행하는 ‘사이언티픽 리포트(Scientific Reports)’ 11일자 온라인판에 실렸으며 리서치 하이라이트로 선정되어 네이처 홈페이지 메인 화면에 소개되기도 했다.
최근 빅데이터가 관심을 받으면서 과학자들은 예술·인문학 자료를 전산화해 분석하려는 시도가 많이 있다. 이 같은 자료는 방대하고 복잡해서 다루기가 쉽지 않다. 연구자들은 빅데이터에서 질서를 찾기 위해 복잡계(Complex Systems) 과학 방법론을 이용하며 이를 ‘데이터 과학’이라고 한다.
그동안 회화에 사용된 물감의 구성 성분, 연대측정, 회화의 진위여부를 정량적으로 판별하는 방법 등에 관한 연구결과는 꾸준히 있었다. 하지만 서양 미술사 전반을 아우르는 대규모 분석에는 데이터가 충분하지 않았다.
연구팀은 헝가리 부다페스트 물리학 컴퓨터 네트워킹 연구센터(Computer Networking Centre of the Wigner Research Centre for Physics)에서 운영하는 온라인 갤러리에서 중세부터 19세기까지 디지털 형태의 서양회화 1만여 점을 모은 데이터를 기반으로 서양 미술을 객관적으로 분석할 수 있었다.
연구팀은 물리학에서 사용하는 상관 함수를 온라인 갤러리에서 취합된 서양 미술의 빅데이터에 적용해 분석한 결과 시간이 흐를수록 명암대비 효과가 점점 높아지는 경향이 있다는 사실을 밝혀냈다.
연구팀은 여기서 사용한 상관 함수를 잭슨 폴록의 드립 페인팅에 적용한 결과, 공간적인 명암대비 효과가 거의 없어 무작위로 만든 그림에 상당히 가깝다는 것을 분석해내기도 했다.
이와 함께 이 기간 동안 서양미술은 그림 속 물체의 윤곽선이 모호해지다 낭만주의 시대 무렵 다시 뚜렷해지는 변화가 있었다.
아울러 중세 시대에는 색상을 다양하게 사용하지 않았고 정치 및 종교적인 이유로 특정 염료만을 선호했다. 같은 이유로 당시에는 색을 직접 혼합하지 않고 오직 덧칠로만 다양한 색을 표현했다. 즉, 연구팀은 염료와 채색 방식으로 인한 중세 시대 색상 표현의 한계와 그 이후 변화를 분석해냈다.
정하웅 교수는 “물질세계의 복잡성에 대한 연구는 자연과학에서 오래된 주요 관심사였지만, 예술 및 인문사회분야와 관련한 체계적인 복잡성 연구는 인터넷 대중화 이후의 일”이라며 “이번 연구는 물질세계의 복잡성을 다루던 방법으로 인류의 귀중한 문화유산인 회화에서 숨은 복잡성을 찾아 구체적인 숫자로 제시했다는데 의의가 있다”고 말했다.
손승우 교수는 “학문 사이의 통섭은 이제 융·복합이라는 키워드로 우리 사회에 자리매김하고 있다”며 “학문간 더욱 활발한 대화를 통해 미술 분야를 넘어 예술 및 인문사회 분야에 숨겨진 복잡성을 더욱 폭넓게 이해하는 것이 필요하다”고 설명했다.
미래창조과학부와 한국연구재단이 추진하는 중견연구자지원사업의 지원으로 수행한 이번 연구는 KAIST와 한양대 교수진의 지도아래 KAIST 물리학과 김영호(28) 박사과정 학생이 주도했다.
동영상 링크 http://youtu.be/SFo0h1EU2aw
[자료 그림] 중세 회화와 드립 페인팅 비교: a은 중세 회화로 구성한 밝기 표면, b은 잭슨 폴록의 드립 페인팅 작품으로 구성한 밝기 표면이다. 각 픽셀의 밝기를 픽셀 위치의 높이로 두어 표면을 구성하고 각 밝기 표면에서 거리에 따른 평균 밝기차이 상관함수를 구했다. c와 d에서 빨간색 점은 그림에서 거리에 따른 평균 밝기차이 상관함수, 파란색 점은 그림을 무작위로 섞어서 만든 이미지에서 거리에 따른 평균 밝기차이 상관함수이다. 중세 회화와 다르게 잭슨 폴록의 드립 페인팅은 무작위로 섞어서 만든 이미지와 거리에 따른 평균 밝기차이 상관함수가 거의 차이가 없다. © 2014 The Polock-Krasner Foundation/ARS, NY - SACK, Seoul
1. 르네상스 시대의 대표 작품인 모나리자를 시대별 스타일에 맞게 재구성
2. 각 그림으로 표면을 구성하고 명암 대비 기법의 강도를 측정하는 짧은 영상. 선별한 그림을 중심으로 명암 대비 기법의 강도가 시대에 따라 증가하는 경향을 영상에서 확인할 수 있다.
3. 회화에서 밝기 표면을 구성하는 방법
4. 네이처 홈페이지(12월 11일)
2014.12.15 조회수 16940 -
 특정 1~2개 앱 많이 쓰면 스마트폰 중독될 가능성 높아
우리 학교 지식서비스공학과 이의진 교수 연구팀은 개인의 스마트폰 사용기록을 분석해 스마트폰 중독 행동패턴을 발견하고 중독 위험에 있는 사람을 자동으로 분류하는 시스템을 개발했다.
이 교수는 95명의 대학생을 한국정보화진흥원의 성인 스마트폰 중독 자가진단 척도를 바탕으로 중독 위험군(36명)과 비위험군(59명)으로 나눴다.
연구팀은 사용자 스마트폰의 전원, 화면, 배터리 상태, 앱 실행, 인터넷 이용, 전화 및 문자메시지 등 총 5만 시간 이상의 사용기록을 수집했다.
연구결과 위험군은 특정 1~2개 앱을 매우 한정적으로 사용했다. 대표적인 앱은 모바일 메신저(카카오톡 등)와 SNS(페이스북 등) 이었다.
알림 기능도 중독 행동과 밀접한 관련이 있었다. 카카오톡 메시지, SNS 댓글 등 알림기능을 설정했을 때 스마트폰 사용시간은 위험군이 하루 평균 38분 더 길었다. 알림메시지가 자기조절력이 낮은 위험군에게 외부 자극이 되어 더욱 빈번한 스마트폰 사용을 야기한 것이다.
위험군의 하루 평균 사용 시간은 4시간 13분으로, 3시간 27분으로 나타난 비위험군에 비해 약 46분 길었다. 특히 오전 6시에서 정오 사이와 오후 6시부터 자정사이에 사용량 차이가 두드러졌다. 사용횟수는 위험군이 11.4회 많았다.
이 교수는 이번에 수집한 자료를 기반으로 사용자를 위험군과 비위험군으로 자동으로 판별하는 시스템을 개발, 80%이상의 정확도를 보였다. 앞으로 스마트폰 중독 현상에 대한 행동을 조기에 발견하고 적절한 조치를 취할 수 있도록 보다 효과적인 서비스를 제공할 수 있을 것으로 기대 된다.
이의진 교수는 이번 연구에 대해 “기존 설문조사를 통한 자기보고기반 스마트폰 중독 분석은 실시간 데이터 확보가 어렵고 입력한 데이터가 정확하지 않을 수 있지만 실제 수집한 자료를 데이터 사이언스 기법과 퍼스널 빅데이터 분석으로 한계점을 극복했다”며 “스마트폰의 과도한 사용을 중재하는 앱을 개발 중”이라고 밝혔다.
지난 4월 말 캐나다 토론토에서 열린 디지털 분야 세계 최대 학술대회인 국제HCI학술대회(ACM SIGCHI CHI)에 출판된 이번 연구는 지식서비스공학과 권가진 교수, 전산학과 송준화 교수, 연세대학교 심리학과 정경미 교수, 마이크로소프트 연구소 코지 야타니 박사(Koji Yatani)가 참여했다.
그림 1. 실험에 참여한 95명 대학생의 스마트폰 사용시간(위) 및 사용횟수(아래). All: 전체 사용자, 위험군이 비위험군에 비해 평균 45.6분 정도 더 오래 쓰고, 평균 11.4회 더 자주 쓰는 것으로 나타남. 앱 카테고리별로 자세히 보면 모바일 메신저(예: 카카오톡), 웹, SNS(예: 페이스북) 등에서 대표적으로 차이가 나타났음.
그림 2. 하루 시간대별 스마트폰 사용 시간(위) 및 사용 횟수(아래). 오전 6~12시 사이 시간과 저녁 18~24시 사이 시간대에서 위험군과 비위험군의 차이가 두드러지게 나타났음.
2014.06.01 조회수 15900
특정 1~2개 앱 많이 쓰면 스마트폰 중독될 가능성 높아
우리 학교 지식서비스공학과 이의진 교수 연구팀은 개인의 스마트폰 사용기록을 분석해 스마트폰 중독 행동패턴을 발견하고 중독 위험에 있는 사람을 자동으로 분류하는 시스템을 개발했다.
이 교수는 95명의 대학생을 한국정보화진흥원의 성인 스마트폰 중독 자가진단 척도를 바탕으로 중독 위험군(36명)과 비위험군(59명)으로 나눴다.
연구팀은 사용자 스마트폰의 전원, 화면, 배터리 상태, 앱 실행, 인터넷 이용, 전화 및 문자메시지 등 총 5만 시간 이상의 사용기록을 수집했다.
연구결과 위험군은 특정 1~2개 앱을 매우 한정적으로 사용했다. 대표적인 앱은 모바일 메신저(카카오톡 등)와 SNS(페이스북 등) 이었다.
알림 기능도 중독 행동과 밀접한 관련이 있었다. 카카오톡 메시지, SNS 댓글 등 알림기능을 설정했을 때 스마트폰 사용시간은 위험군이 하루 평균 38분 더 길었다. 알림메시지가 자기조절력이 낮은 위험군에게 외부 자극이 되어 더욱 빈번한 스마트폰 사용을 야기한 것이다.
위험군의 하루 평균 사용 시간은 4시간 13분으로, 3시간 27분으로 나타난 비위험군에 비해 약 46분 길었다. 특히 오전 6시에서 정오 사이와 오후 6시부터 자정사이에 사용량 차이가 두드러졌다. 사용횟수는 위험군이 11.4회 많았다.
이 교수는 이번에 수집한 자료를 기반으로 사용자를 위험군과 비위험군으로 자동으로 판별하는 시스템을 개발, 80%이상의 정확도를 보였다. 앞으로 스마트폰 중독 현상에 대한 행동을 조기에 발견하고 적절한 조치를 취할 수 있도록 보다 효과적인 서비스를 제공할 수 있을 것으로 기대 된다.
이의진 교수는 이번 연구에 대해 “기존 설문조사를 통한 자기보고기반 스마트폰 중독 분석은 실시간 데이터 확보가 어렵고 입력한 데이터가 정확하지 않을 수 있지만 실제 수집한 자료를 데이터 사이언스 기법과 퍼스널 빅데이터 분석으로 한계점을 극복했다”며 “스마트폰의 과도한 사용을 중재하는 앱을 개발 중”이라고 밝혔다.
지난 4월 말 캐나다 토론토에서 열린 디지털 분야 세계 최대 학술대회인 국제HCI학술대회(ACM SIGCHI CHI)에 출판된 이번 연구는 지식서비스공학과 권가진 교수, 전산학과 송준화 교수, 연세대학교 심리학과 정경미 교수, 마이크로소프트 연구소 코지 야타니 박사(Koji Yatani)가 참여했다.
그림 1. 실험에 참여한 95명 대학생의 스마트폰 사용시간(위) 및 사용횟수(아래). All: 전체 사용자, 위험군이 비위험군에 비해 평균 45.6분 정도 더 오래 쓰고, 평균 11.4회 더 자주 쓰는 것으로 나타남. 앱 카테고리별로 자세히 보면 모바일 메신저(예: 카카오톡), 웹, SNS(예: 페이스북) 등에서 대표적으로 차이가 나타났음.
그림 2. 하루 시간대별 스마트폰 사용 시간(위) 및 사용 횟수(아래). 오전 6~12시 사이 시간과 저녁 18~24시 사이 시간대에서 위험군과 비위험군의 차이가 두드러지게 나타났음.
2014.06.01 조회수 15900 -
 SNS에서 떠도는 루머를 구분할 수 있을까?
권세정 박사과정 학생(좌)과 차미영 교수(우)
- “루머는 팔로워 수가 적은 사용자들을 중심으로 산발적으로 전파” -- 2006년 이후 발생한 100여개의 트위터 상 미국 루머 사례 조사 -
트위터, 페이스북 등 SNS상에서 떠도는 정보의 진위여부를 가릴 수 있을까?
우리 학교 문화기술대학원 차미영 교수 연구팀(제1저자 권세정 박사과정)은 서울대 정교민 교수 및 마이크로소프트 아시아 연구소의 Wei Chen, Yajun Wang 박사와 공동연구를 통해 트위터 내에서 광범위하게 전파되는 정보의 진위 여부를 90%까지 정확하게 구분해낼 수 있는 기술을 개발했다.
이번 연구를 통해 루머에 대해 SNS 데이터를 바탕으로 한 새로운 수리적 모델과 네트워크 구조 및 언어적 특징을 도출함은 물론, 향후 인터넷 루머의 특성과 규제에 도움이 되는 루머 구분 기술을 확보하는 계기가 될 것으로 기대된다.
SNS는 누구에게나 손쉽게 정보의 생산과 유통 및 전파 과정에 참여하는 긍정적인 기능을 한다. 하지만 역기능으로 검증되지 않은 정보가 빠르게 확산되어 개인·기업·국가에 해를 끼칠 수 있는 악성 루머의 발판을 마련하기도 한다. 따라서 인터넷 루머를 감지하고 확산을 방지하고자 하는 노력이 중요하다.
차 교수 연구팀은 2006년에서 2009년 사이 미국 트위터에서 광범위하게 전파된 100개 이상의 사례를 조사해 루머의 특성을 분석했다. 수집된 자료는 정치·IT·건강·연예인 등 다양한 분야를 포함하며, 이러한 분석을 통해 90%의 정확도로 루머 여부를 판단할 수 있었다. 특히 특정 인물이나 기관의 비방이나 욕설이 포함된 루머의 경우 더욱 높은 정확도로 루머 여부의 판단이 가능했다. 연구팀은 일반 정보의 전파와는 확연히 다른 루머 전파의 특징을 크게 세 가지로 분류했다.
첫째, 루머는 일반 정보와는 달리 지속적으로 전파되는 경향을 보인다. 뉴스와 같은 일반 정보의 경우 한 번의 광범위한 전파 이후 미디어 내에서 거의 언급되지 않지만, 루머는 수년간의 긴 기간 동안 지속적으로 언급된다.
둘째, 루머의 전파는 서로 연관이 없는 임의 사용자들의 산발적인 참여해 이뤄진다. 일반 정보는 온라인 내의 친구관계를 통해 전파의 경로가 유추되는 반면 루머는 연결되지 않은 개개인의 참여로 이루어지는 특징을 보였다. 아울러 루머는 인지도가 낮은 사용자들로부터 시작돼 유명인에게로 전파된다. 이 현상은 연예인이나 정치인과 관련된 루머에서 자주 관찰됐다.
셋째, 루머는 일반 정보와 다른 언어적 특성을 보인다. 루머는 정보의 진위 여부를 의심·부정·유추하는 심리학적 과정과 연관된 단어(아니다, 사실일지는 모르겠지만, 확실치는 않지만, 내 생각에는, 잘 기억나진 않지만) 사용이 월등히 높다.
연구팀이 루머로 구분한 사례 중에는 미국 대선 당시 버락 오바마 대통령 후보가 무슬림이며 반기독교적 성향이 있고 미국 시민권을 부당 취득했다는 내용 등 그를 음해하는 정치적 루머도 포함됐다. 또 영화배우 니콜 키드먼이 성전환 수술을 했으며 그녀가 양성애자라고 언급한 사례 역시 연구팀의 기술을 통해 루머로 명백히 구분됐다.
차 교수는 “이 연구는 통계·수학적 모델은 물론 사회·심리학 이론의 융합 연구로 사회적으로 주목을 받는 루머의 특성을 풍부한 데이터를 통해 도출했다”며 “루머 전파 극초기에 해당 정보의 진위여부를 판별하는 것은 아직 어렵지만, 일정시간 경과 혹은 정보확산이 이루어질 경우 해당 빅데이터를 기반으로 하여 진위여부를 판단하는 것이 가능하다"고 밝혔다.
이번 연구결과는 지난해 12월 미국 텍사스주에서 열린 데이터마이닝 분야의 최고 학술대회인 IEEE 데이터마이닝 국제 회의(IEEE International Conference on Data Mining)에서 발표됐다. 또 해외 유명 과학 잡지인 New Scientist에 Bigfoot found? AI tool sifts fact from myth on Twitter 라는 제목으로 소개됐으며 Washington Post에도 Korean scientists create a tool that can help separate fact from fiction on Twitter의 기사명으로 소개됐다.
그림1. 각 주제 별로 관련 내용을 트위터 내에서 언급한 수(x축: 관찰일, y축:트윗수). 루머의 경우 일반적인 정보가 한 번의 광범위한 전파 후 거의 퍼지지 않는 것과 달리 지속적으로 언급되고 있음을 보여준다.
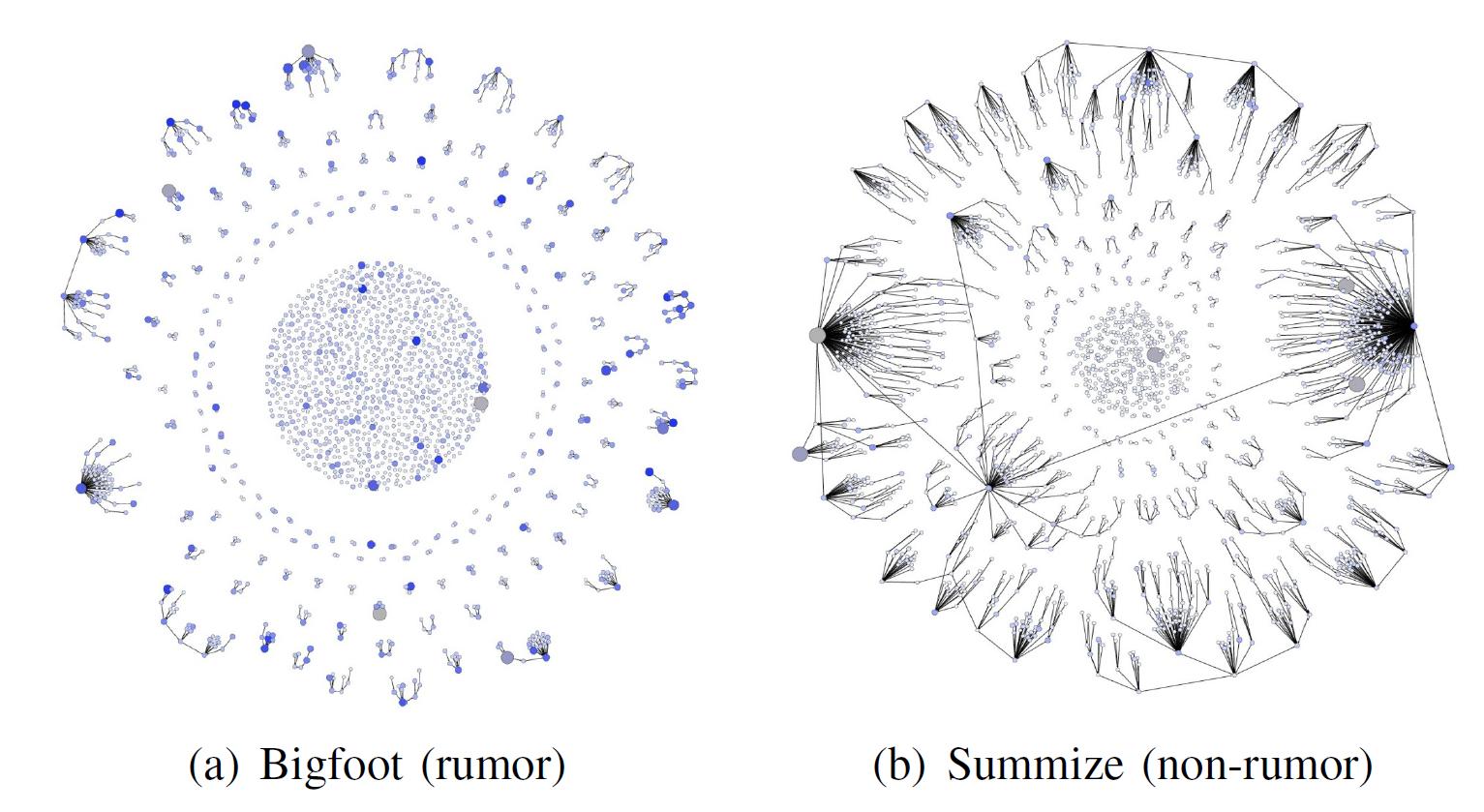
그림2. 트위터 내 사용자들 간 정보 전파를 네트워크의 형식으로 표현한 확산 네트워크. 각 점은 사용자를 의미하며, 선은 사용자들 간의 관계를 통한 정보 확산이 있었음을 의미한다.
2014.01.09 조회수 23662
SNS에서 떠도는 루머를 구분할 수 있을까?
권세정 박사과정 학생(좌)과 차미영 교수(우)
- “루머는 팔로워 수가 적은 사용자들을 중심으로 산발적으로 전파” -- 2006년 이후 발생한 100여개의 트위터 상 미국 루머 사례 조사 -
트위터, 페이스북 등 SNS상에서 떠도는 정보의 진위여부를 가릴 수 있을까?
우리 학교 문화기술대학원 차미영 교수 연구팀(제1저자 권세정 박사과정)은 서울대 정교민 교수 및 마이크로소프트 아시아 연구소의 Wei Chen, Yajun Wang 박사와 공동연구를 통해 트위터 내에서 광범위하게 전파되는 정보의 진위 여부를 90%까지 정확하게 구분해낼 수 있는 기술을 개발했다.
이번 연구를 통해 루머에 대해 SNS 데이터를 바탕으로 한 새로운 수리적 모델과 네트워크 구조 및 언어적 특징을 도출함은 물론, 향후 인터넷 루머의 특성과 규제에 도움이 되는 루머 구분 기술을 확보하는 계기가 될 것으로 기대된다.
SNS는 누구에게나 손쉽게 정보의 생산과 유통 및 전파 과정에 참여하는 긍정적인 기능을 한다. 하지만 역기능으로 검증되지 않은 정보가 빠르게 확산되어 개인·기업·국가에 해를 끼칠 수 있는 악성 루머의 발판을 마련하기도 한다. 따라서 인터넷 루머를 감지하고 확산을 방지하고자 하는 노력이 중요하다.
차 교수 연구팀은 2006년에서 2009년 사이 미국 트위터에서 광범위하게 전파된 100개 이상의 사례를 조사해 루머의 특성을 분석했다. 수집된 자료는 정치·IT·건강·연예인 등 다양한 분야를 포함하며, 이러한 분석을 통해 90%의 정확도로 루머 여부를 판단할 수 있었다. 특히 특정 인물이나 기관의 비방이나 욕설이 포함된 루머의 경우 더욱 높은 정확도로 루머 여부의 판단이 가능했다. 연구팀은 일반 정보의 전파와는 확연히 다른 루머 전파의 특징을 크게 세 가지로 분류했다.
첫째, 루머는 일반 정보와는 달리 지속적으로 전파되는 경향을 보인다. 뉴스와 같은 일반 정보의 경우 한 번의 광범위한 전파 이후 미디어 내에서 거의 언급되지 않지만, 루머는 수년간의 긴 기간 동안 지속적으로 언급된다.
둘째, 루머의 전파는 서로 연관이 없는 임의 사용자들의 산발적인 참여해 이뤄진다. 일반 정보는 온라인 내의 친구관계를 통해 전파의 경로가 유추되는 반면 루머는 연결되지 않은 개개인의 참여로 이루어지는 특징을 보였다. 아울러 루머는 인지도가 낮은 사용자들로부터 시작돼 유명인에게로 전파된다. 이 현상은 연예인이나 정치인과 관련된 루머에서 자주 관찰됐다.
셋째, 루머는 일반 정보와 다른 언어적 특성을 보인다. 루머는 정보의 진위 여부를 의심·부정·유추하는 심리학적 과정과 연관된 단어(아니다, 사실일지는 모르겠지만, 확실치는 않지만, 내 생각에는, 잘 기억나진 않지만) 사용이 월등히 높다.
연구팀이 루머로 구분한 사례 중에는 미국 대선 당시 버락 오바마 대통령 후보가 무슬림이며 반기독교적 성향이 있고 미국 시민권을 부당 취득했다는 내용 등 그를 음해하는 정치적 루머도 포함됐다. 또 영화배우 니콜 키드먼이 성전환 수술을 했으며 그녀가 양성애자라고 언급한 사례 역시 연구팀의 기술을 통해 루머로 명백히 구분됐다.
차 교수는 “이 연구는 통계·수학적 모델은 물론 사회·심리학 이론의 융합 연구로 사회적으로 주목을 받는 루머의 특성을 풍부한 데이터를 통해 도출했다”며 “루머 전파 극초기에 해당 정보의 진위여부를 판별하는 것은 아직 어렵지만, 일정시간 경과 혹은 정보확산이 이루어질 경우 해당 빅데이터를 기반으로 하여 진위여부를 판단하는 것이 가능하다"고 밝혔다.
이번 연구결과는 지난해 12월 미국 텍사스주에서 열린 데이터마이닝 분야의 최고 학술대회인 IEEE 데이터마이닝 국제 회의(IEEE International Conference on Data Mining)에서 발표됐다. 또 해외 유명 과학 잡지인 New Scientist에 Bigfoot found? AI tool sifts fact from myth on Twitter 라는 제목으로 소개됐으며 Washington Post에도 Korean scientists create a tool that can help separate fact from fiction on Twitter의 기사명으로 소개됐다.
그림1. 각 주제 별로 관련 내용을 트위터 내에서 언급한 수(x축: 관찰일, y축:트윗수). 루머의 경우 일반적인 정보가 한 번의 광범위한 전파 후 거의 퍼지지 않는 것과 달리 지속적으로 언급되고 있음을 보여준다.
그림2. 트위터 내 사용자들 간 정보 전파를 네트워크의 형식으로 표현한 확산 네트워크. 각 점은 사용자를 의미하며, 선은 사용자들 간의 관계를 통한 정보 확산이 있었음을 의미한다.
2014.01.09 조회수 23662